
物联系统边缘端人流统计方法研究
2022-03-27 11:02谭宏年时长伟
智能物联技术 2022年5期
谭宏年,时长伟
(1.克拉玛依职业技术学院 机械工程系,新疆 克拉玛依 834000;2.新特能源股份有限公司,新疆 乌鲁木齐 830000)
0 引言
在智能物联系统中,利用边缘端监控系统进行人流统计十分便捷。后台系统可实时准确获取边缘端推送的人流信息,对于日常以及突发情况下的人员管理是非常必要的。
基于视觉的人流量统计通常分为行人目标检测与跟踪两个部分。关于目标检测,传统的方法是人工提取目标特征点构建目标特征,然后利用分类算法进行分类并判断目标是否存在。典型的算法如Hog+SVM[1]、Haar+Adaboost[2],它们的不足之处主要是泛化能力较差、检测准确率不高以及运算资源消耗过多。近些年,随着深度学习技术的发展以及GPU(Graphics Processing Unit)并行计算能力的提高,涌现了一批基于目标检测的深度学习算法,如R-CNN 系列[3-5],SSD(Single Shot multibox Detec tor)[6]、RetinaNet[7]和YOLO 系列[8-10]。基于深度学习的目标检测算法能自动从行人图片数据集中学习更深层次的信息,泛化能力强,兼顾检测速度与识别准确度。如YOLO 算法已经更迭到YOLOv5,其模型权重大小分为s,m,l 和x,相应识别精确度以及时间复杂度也依次增高。其中,YOLOv5s 与YOLOv5m 模型参数量(Params)相对较少,浮点运算量(FLOPs)低,在算力有限的边缘计算领域应用最多。
当前,基于视觉的人流量统计方法的挑战主要是遮挡问题,尤其是在人群密度较大的场合,行人之间的遮挡难以避免。针对该问题,有不少学者开展了相关研究。如赵朵朵等[11]提出一种基于Deep SORT(Simple Online and Realtime Tracking)算法的人流统计方案,使用改进的YOLOv3 作为检测器,利用轻量级网络MobileNet[12]替换原有的DarkNet-53 网络,减少了参数量,提高了识别速度,但存在识别精确度降低的问题。朱行栋[13]提出一种单独基于YOLOv5 模型进行行人检测的方法,但存在只能检测行人无法进行更深层次的行人方向判断与跨线计数的问题。综上,本文利用轻量级深度学习模型YOLOv5s 作为检测器,基于检测的多目标跟踪(tracking-by-detection)算法Deep SORT[14]实现行人的实时跟踪,通过设置两个虚拟检测区域完成人流的方向检测与计数。
1 YOLOv5s 人流检测
在多目标跟踪算法中,检测器的好坏直接关系到目标跟踪结果的准确率,检测器的速率也会直接影响整个系统的实时性。为了兼顾识别准确率与实时性,也考虑到边缘设备的算力限制,本文选用YOLOv5s 模型作为人流检测的基础模型。
1.1 YOLOv5s 网络结构
YOLOv5 针对不同大小的网络的整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度。如图1 所示,YOLOv5s 的结构主要分为四个部分,即Input 输入端、Backbone 主干网络、Neck 网络和Prediction 预测端。输入端包含对图像的预处理、Mosaic 数据增强、自适应锚框计算,来适应不同大小的数据集。Backbone 主干网络通过卷积运算从图像中提取不同的层次特征,主要包含CSP(Cross Stage Partial)结构和SPP(Spatial Pyramid Pooling)结构。前者作用是减少冗余计算量和增强梯度,提高计算速度;后者可将图像不同层次的特征提取出来,提高检测精度。Neck 网络层结构和YOLOv4 相似,FPN(Feature Pyramid Networks)层自顶向下传递语义信息,PAN(Path Augmentation Network)层自底向上传递信息,从各个主干层对对应的检测层进行信息融合,进一步提高特征提取的能力。Prediction 预测端的主要作用是在大小不同的特征图上预测不同尺寸的目标。

图1 YOLOv5s 网络架构Figure 1 YOLOv5s Network Architecture
1.2 图像预处理
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。YOLOv5 算法涉及对图片自适应缩放的步骤为计算缩放比例、计算缩放后尺寸、计算黑边填充数值。其计算公式如式(1)所示:
式中:l1,w1——原始图像的长和宽;l2,w2——原始缩放尺寸的长和宽;l3,w3——自适应缩放尺寸的长和宽。
1.3 Mosaic 数据增强
Mosaic 数据增强参照了Cut Mix 数据增强方式,开始前每次读取4 张图片,然后依次对4 张图片进行翻转、缩放和色域变化等处理,再按照4 个方向摆好,组合为一张新的图片。这种随机机制丰富了检测物体的背景。因为在网络模型上,由于硬件资源的原因,不能够将batch_size 设置过大,通过Mosaic 方法就类似间接增大了batch_size,提高了硬件GPU 的使用效率。
1.4 CBAM 注意力机制
YOLOv5 算法将CBAM(Convolutional Block Attention Module)注意力模块嵌入到网络结构中,解决原始网络无注意力偏好的问题。如图2 所示,CBAM 一共包含2 个独立的子模块,通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spartial Attention Module,SAM),分别进行通道与空间维度上的注意力特征融合并对网络中间的特征图进行重构,强调重要特征,抑制一般特征,达到提升目标检测效果的目的。这样不仅能节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
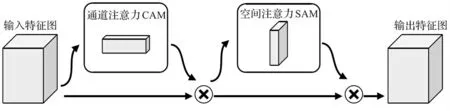
图2 CBAM 结构Figure 2 CBAM structure
YOLOv5s 网络中图像特征提取主要在主干网络中完成。因此,本文将CBAM 融合在Backbone 之后和Neck 网络的特征融合之前,可以起到承上启下的作用。
1.5 损失函数
目标检测任务的损失函数一般由Classification Loss(分类损失函数)和Bounding Box Regression Loss(回归损失函数)两部分构成。YOLOv5s 使用GIoU Loss 作为边界框回归损失函数,用以评判预测边界框(Predicted Box,PB)和真实边界框(Ground Truth,GT)的距离,如式(2)所示:
式中:IoU 表示预测边界框和真实边界框的交并比;Ac表示预测边界框和真实边界框同时包含的最小的矩形框的面积;u 表示预测边界框和真实边界框的并集;LGIoU为GIoU 损失。GIoU Loss 的优势是尺度不变性,即预测边界框和真实边界框的相似性与它们的空间尺度大小无关。
1.6 NMS 非极大值抑制
在目标检测的预测阶段,会输出许多候选的anchor box,其中有很多是明显重叠的预测边界框都围绕着同一个目标,这时候可以使用NMS(Non-Maximum Suppression)来合并同一目标的类似边界框,或者说是保留这些边界框中最好的一个。
NMS 非极大值抑制算法首先从所有候选框中选取置信度最高的预测边界框作为基准,然后将所有与基准边界框的IoU 超过预定阈值的其他边界框移除。再从所有候选框中选取置信度第二高的边界框作为一个基准,将所有与基准边界框的IoU 超过预定阈值的其他边界框移除。重复上述操作,直到所有预测框都被当做基准,即这时候没有一对边界框过于相似。
2 Deep SORT 多目标跟踪
多目标在线跟踪算法SORT 的核心是卡尔曼滤波和匈牙利算法,即把一群检测框和卡尔曼滤波预测得到的边界框做分配,让卡尔曼滤波预测得到的边界框找到和自己最匹配的检测框,达到追踪的效果。但是SORT 算法的缺陷是当物体发生遮挡的时候特别容易丢失ID。而Deep SORT 算法在SORT算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。
2.1 跟踪处理与状态估计
在Deep SORT 算法中,使用8 维状态空间描述目标的状态和在图像坐标系中的运动信息,如图3 所示:

图3 多维状态空间描述Figure 3 Description of multidimensional state space
其中:cx 和cy 分别表示目标中心点的横坐标和纵坐标,r 表示长宽比,h 表示高,剩下四个参数分别是它们的导数(对应前四个参数在图像像素中的相对速度)。在状态估计中,一般状态向量是由状态量跟它的导数构成的。在Deep SORT 算法中,卡尔曼滤波进行预测时采用最基本的线性匀速模型,即认为框的移动和框的尺寸、形变的变化是线性匀速变化的。
2.2 数据关联代价公式
Deep SORT 算法基于目标的运动信息和外观信息,使用匈牙利算法匹配预测框和跟踪框。对于运动信息,算法使用马氏距离描述卡尔曼滤波预测结果和YOLO 检测器输出结果的关联程度,如式(3)所示:
式中,dj和yi分别表示第j 个检测结果和第i个预测结果的状态向量,Si表示检测结果和平均跟踪结果之间协方差矩阵。但是Deep SORT 不仅看框与框之间的距离,还要看框内的表观特征,显然单纯用马氏距离度量框与框的接近度是远远不够的,依然不能解决目标遮挡后跟踪丢失的问题,所以Deep SORT 还引入了表观特征余弦距离度量,如式(4)所示:
当d2(i,j)小于指定的阈值,认为关联成功。
因此,Deep SORT 在数据关联中一共有两个代价,一个是马氏距离,一个是余弦距离,求解过程中要使两者都尽量小,即框也接近、特征也接近的话,就认为两个Bbox 中是同一个目标物体。综合马氏距离和表观余弦度量的代价公式如式(5)所示,使用线性加权方式进行求和。
2.3 级联匹配
长时间遮挡中,卡尔曼滤波的输出会发散,不确定性增加,而不确定性强的track(预测框)的马氏距离反而更容易竞争到detection 匹配。因此,需要按照遮挡时间n 从小到大给track 分配匹配的优先级。Tracks 分为确认态(confirmed)和不确认态(unconfirmed),新产生的Tracks 是不确认态的。不确认态的Tracks 必须要和检测框连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks 必须和检测框连续失配一定次数(默认30次),才会被删除,这样就很好解决了目标遮挡后跟踪丢失的问题。
3 YOLOv5s-DeepSORT 人流统计
人流统计模型的另一个重点是行人计数。本文通过设置两个虚拟区域来记录行人跟踪框中心点进入两个区域的先后来判断行人的方向并进行计数。这里涉及到的主要问题是如何判断一个点是否在某个多边形区域内。相应的方法有:
射线法:从判断点向某个统一方向作射线,根据交点个数的奇偶判断;
转角法:按照多边形顶点逆时针顺序,根据顶点和判断点连线的方向正负(设定角度逆时针为正)求和判断;
夹角和法:求判断点与所有边的夹角和,等于360°则在多边形内部;
面积和法:求判断点与多边形边组成的三角形面积和,等于多边形面积则点在多边形内。
上述方法中,面积和法涉及多个面积的计算,比较复杂;夹角和法以及转角法用到角度计算,会涉及反三角函数,计算开销比较大;而射线法主要涉及循环多边形的每条边进行求交运算,但大部分边可以通过简单坐标比对直接排除。因此本文选择射线法来判断行人跟踪框中心点是否在虚拟区域内。
如图4 所示,在随机点上作一条平行于x 轴的射线,方向是x 轴正方向,看这条射线与多边形区域的交点个数,如果是偶数,那么这个随机点不在该区域内,如果是奇数,则这个点在该区域内。
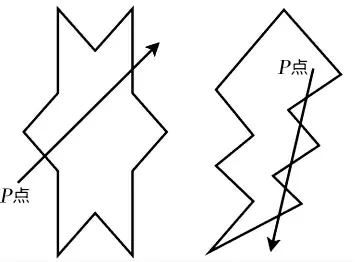
图4 射线判别法示意图Figure 4 Schematic diagram of ray discrimination method
如图5 所示,当行人跟踪框中心点在B 区域内时,查看当前跟踪框ID 号在A 区域是否有记录:若有记录,则下行人数加1;若没有记录,则记录当前跟踪框ID 号。当行人跟踪框中心点在A 区域内时,查看当前跟踪框ID 号是否在B 区域有记录:若有记录,上行人数加1;若没有记录,则记录当前跟踪框ID 号。
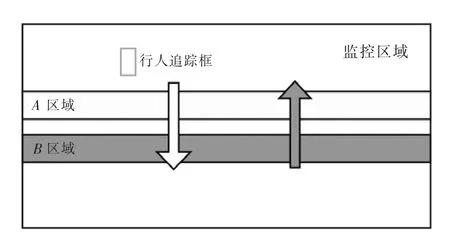
图5 双虚拟检测区设置Figure 5 Setting of dual virtual detection area
YOLOv5s-DeepSORT 人流统计系统采用YOLOv5s 模型作为基础检测器,精确快速完成对监控视频每一帧的处理,并将检测框信息传给下一级;Deep SORT 模块作为下一级,主要实现多目标行人的跟踪,为行人计数模块提供准确和拥有唯一编号的行人检测框。行人计数模块通过AB 虚拟区域完成上行以及下行人数的计数,整个人流统计流程如图6 所示。
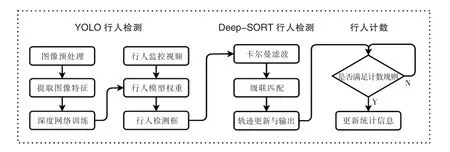
图6 YOLOv5s-DeepSORT 人流统计系统流程图Figure 6 Flow chart of YOLOv5s-DeepSORT flow statistics system
4 实验与分析
4.1 实验准备
实验配置环境:Windows 10 操作系统;内存为16G;GPU 为NVIDIA GeForce 1650;学习框架为PyTorch1.7.1,torchvision 0.8.2,CUDA10.2 和CUDNN7.6.5。
数据集使用INRIA 数据集。它是一组有标记的站立或行走的人的图片,其中训练集中有正样本614 张(包含1237 个标注行人),负样本1218 张;测试集中有正样本288 张(包含589 个标注行人),负样本453张,其中行人的类名定义为person。
4.2 评价指标
在目标检测中,一般使用召回率(Recall)、精准率(Precision)和综合前两者的平均精度均值mAP(mean Average Precision)对目标检测算法性能进行评价。所以,本文使用以上3 个指标作为模型评估指标,同时使用每秒帧数FPS(Frames Per Second)作为检测速度的评估指标。计算公式如(6)(7)(8)所示,其中TP(True Positive)表示正类判定为正类;FP(False Positive)表示负类判定为正类;FN(False Negative)表示正类判定为负类,k 表示类别,C 表示总类别数。
4.3 实验结果
本文运用YOLOv3、YOLOv4、YOLOv4-tiny 以及YOLOv5s 算法进行了比较实验,实验结果如表1 所示。

表1 不同算法精度与速度对比Table 1 Comparison of precision and speed of different algorithms
由表1 可知,YOLOv5s 算法在检测速度以及精度综合性能上相比其他算法有明显优势。
Deep SORT 追踪模块使用的是开源的行人重识别权重ckpt.t7,完成对上一级检测框的ID 分配与追踪。整个系统的实时运行图如图7 所示。可以看出,利用YOLOv5s-Deep SORT 算法的人流检测效果较好,距离较远的目标定位也十分准确,没有出现行人数量检测遗漏现象,检测速度能达到每秒32 帧以上,整体视频流畅。

图7 实时人流统计界面Figure 7 Real-time traffic statistics interface
5 结语
本文将基于深度学习的目标检测网络YOLOv5s 与多目标跟踪算法Deep SORT 融合起来,通过设置两个虚拟检测区域完成人流的方向检测与计数,实现了一种兼顾实时性与准确度的人流统计系统。经过测试,相比基于YOLOv3、YOLOv4以及YOLOv4-tiny 的目标检测网络的综合性能有明显提高,结合Deep SORT 多目标跟踪,特定环境下人流统计准确率最高接近100%。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
意林(2021年5期)2021-04-18
现代装饰(2020年4期)2020-05-20
扬子江(2019年1期)2019-03-08
中国生殖健康(2018年1期)2018-11-06
中国生殖健康(2018年1期)2018-11-06
证券法律评论(2018年0期)2018-08-31
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
海军医学杂志(2015年2期)2015-02-27
