
基于YOLOv5的无人机航拍改进目标检测算法Dy-YOLO
2024-01-15 08:41杨秀娟曾智勇
福建师范大学学报(自然科学版) 2024年1期
杨秀娟,曾智勇
(福建师范大学计算机与网络空间安全学院,福建 福州 350117)
近年来,计算机视觉技术发展迅猛,目标检测是计算机视觉中一个基本而重要的问题,主要用于对图像中的物体类别进行标识。随着深度学习技术的发展,配备遥感目标检测技术的无人机在城市监控、农业生产、人员救援、灾害管理等方面得到了广泛的应用。然而,无人机飞行高度的快速变化导致目标在图像中的尺度变化剧烈。同时,无人机捕获的图像中通常存在高密度的物体,并且这些物体之间可能会发生遮挡,增加了目标识别和定位的难度。此外,无人机拍摄的图像覆盖面积较大,包含复杂的地理元素,可能导致捕获的图像存在令人困惑的背景干扰。因此,提高无人机航拍图像中目标检测的精度和准确性仍然是一个挑战。
针对如何解决这些问题,目前已经有很多学者进行了大量的研究,例如在多尺度学习和特征融合方面,经典的多尺度学习网络结构是特征金字塔结构(feature pyramid network,FPN)[1],它通过自下而上的特征提取和特征融合,提高了网络的表征能力,然而多尺度学习会增加模型的参数数量,导致推理速度下降;YOLO-Drone[2]提出一个包含一个空间金字塔池(spatial pyramid pooling,SPP)和3个空洞金字塔池化(atrous spatial pyramid pooling,ASPP)的复杂特征聚合模块MSPP-FPN,改善了目标检测颈部阶段的特征聚合。有的学者则关注到小目标上下文信息整合不足的问题,例如Wang[3]等人提出了一个特征细化网络(feature refinement network,FRNet),它学习不同上下文中每个特征的位级上下文感知特征表示。FRNet由2个关键组件组成:信息提取单元(information extraction unit,IEU)负责捕获上下文信息和跨特征关系,以指导上下文感知特征细化;互补选择门(complementary selection gate,CSGate)则自适应地将IEU 中学习到的原始特征和互补特征与位级权重相结合。还有学者发现卷积神经网络结合Tramsfomer可以帮助提升检测效果,例如TPH-YOLOv5[4]将Transformer预测头(transformer prediction heads,TPH)引入到YOLOv5以提高网络的预测回归能力,同时使用自注意力机制提高对小目标的关注度。PETNet[5]则提出了一种先验增强Transformer(prior enhanced transformer,PET)和一对多特征融合机制(one-to-many feature fusion,OMFF)来嵌入YOLO网络,2个额外的检测头被添加到浅层特征映射中,PET被用于捕获增强的全局信息,以提高网络的表达能力,OMFF旨在融合多种类型的特征,以最大限度地减少小对象的信息丢失;有的学者则针对无人机图像中的遮挡问题提出改进方法,例如Li[6]等人提出了遮挡引导多任务网络(occlusion-guided multi-task network,OGMN),其包含遮挡估计模块(occlusion estimation module,OEM)来精确定位遮挡,用遮挡解耦头来取代常规检测头,通过2个多任务交互实现遮挡引导检测。Ye[7]等人为了解决被遮挡物体特征不连续的问题设计了一种高效的卷积多头自注意力(convolutional multihead self-attention,CMHSA)算法,通过提取物体的上下文信息来提高被遮挡物体的识别能力。还有学者从预测框入手,例如提出一种归一化高斯距离(normalized wasserstein distance,NWD)[8]的新度量,将边界框建模为2D高斯分布,然后通过其对应的高斯分布计算边界框之间的相似性以解决小目标体位置偏差非常敏感的问题。文献[9]提出了一种改进加权框融合BF(improved weighted boxes fusion,IWBF)的无人机目标检测算法,通过用IWBF代替非极大值抑制(non-maximum suppression,NMS),可以充分利用预测盒信息,筛选出最优融合盒,减少多尺度目标的漏检和误检问题;还有学者从加快推理速度角度出发,例如QueryDet[10]采用了一种查询机制来加速目标检测器的推理速度,利用低分辨率特征预测粗略定位以引导高分辨率特征进行更精确的预测回归。受前人研究启发,本文则提出了一种基于YOLOv5的无人机场景的改进目标检测算法,在模型方法与结构上的贡献如下:
(1)在YOLOv5中引入SimOTA[11]动态标签分配方法,有效缓解基于(intersection over union,IoU)的匹配策略对于小目标敏感的问题。
(2)提出了一个基于YOLOv5改进的目标检测模型Dy-YOLO,在预测头(Head)前引入Dynamic Head[12]统一自注意力,从尺度、通道以及多任务3个角度提升了网络的目标定位能力。在颈部(Neck)使用轻量级上采样算子CARAFE[13],缓解最近邻上采样操作恢复细节信息能力较弱的问题,使特征重组时有较大的感受野聚合上下文信息,提升目标检测效果的同时提高模型鲁棒性。
(3)在主干(Backbone)设计了C3-DCN结构与Dynamic Head注意力结构首尾呼应,利用可变形卷积实现了自适应感受野和处理空间变形的能力,相互配合提高目标边界的准确性以及增强模型的表达能力。
1 相关工作
1.1 YOLOv5介绍
YOLOv5目标检测模型有s,m,l,x 4种尺寸规格,其网络结构相同但是对应不同的网络深度与宽度,较小的尺寸可以减少模型的存储需求和计算开销,深层网络则可提取更丰富特征。YOLOv5使用改进后的CSPDarknet53结构和空间金字塔快速池化(spatial pyramid pooling-fast,SPPF)模块作为主干网络,用于提取输入图像的特征;颈部是网络衔接部分,主要用来获取传递特征信息并进行融合。使用FPN-PAN结构,FPN结构是自顶向下结构,通过上采样和融合底层特征信息的方式得到预测特征图,PAN(path aggregation network)采用自低向上结构对FPN特征图进行融合补充的特征金字塔网络结构,以获得更丰富的语义信息,以及使用YOLO传统检测头用来预测目标的类别、位置和置信度。
1.2 标签分配方法
目标检测旨在从自然图像中定位和识别感兴趣的目标,它通常被称为通过联合优化目标分类和定位的多任务学习问题。分类任务的目的是学习集中在目标的关键或显著部分的判别特征,而定位任务的目的是精确定位整个目标及其边界。由于分类和定位学习机制的差异,2个任务学习到的特征的空间分布可能不同,当使用2个单独的分支进行预测时,会导致一定程度的错位。所以如何减少或者弥补分类与定位的信息差就显得非常重要,前期的标签分配策略大多是基于某种度量的手工分配策略,比如需要手动调整划分正负样本的超参数,提前设定anchor框等等。但是,从近些年的论文可以看出,研究实现标签自动化分配的方案越来越多,RetinaNet[14]根据anchor和目标的IoU确定正负样本,FCOS[15]根据目标中心区域和目标的尺度确定正负样本,ATSS[16]提出自适应训练样本选择的方法确定正负样本。OTA[17]创新性地从全局的角度重新审视了该问题,提出解决目标检测中的标签分配问题的新思路:将标签分配问题看作最优传输问题来处理。YOLOX中改进的SimOTA使用动态Top-k策略替代Sinkhorn-Knopp算法,缩短了OTA增加的训练时间,TOOD[18]则提出了(task-aligned head,T-head)和(task alignment learning,TAL)来解决分类和定位对不齐的问题,加强了2个任务的交互,提升检测器学习对齐与否的能力。
1.3 注意力机制
注意力机制可以看作是一个动态选择过程,通过学习权重或分配机制对特征进行自适应加权来实现,给予不同输入元素不同的重要性,这些权重或分配机制可以通过学习得到,也可以基于规则或先验知识设置。它是一种在有限的计算资源中使得整个网络更关注重点区域,降低对非关键区域的关注度,甚至过滤掉无关信息,就可以一定程度上缓解信息过载问题,使得网络提取到更多需要的特征信息,并提高任务处理的效率和准确性。注意力机制的核心在于让网络关注重点信息而忽略无关信息,其分类大致可以分为空间注意力机制、通道注意力机制和混合注意力机制等。空间注意力关注图像中的感兴趣区域,通过加权处理不同空间位置来聚焦于重要的区域,其代表方法有STN[19]等。通道注意力则关注的是不同通道之间的关系,不同通道包含的信息是不同的,对相应的任务的影响也是不同的,因而学习每个通道的重要程度,针对不同任务增强或抑制不同的通道从而达到提高任务准确度的效果,通道注意力机制中代表性方法有SENet[20]等。混合注意力机制则是混合了多种注意力机制的方法,其代表性方法有CBAM[21]等。注意力机制能够捕捉全局上下文信息,适应不同尺度的目标,并提高模型对目标的区分能力,然而,它也存在计算复杂度高、学习困难和特征表示不稳定等缺点。
1.4 上采样方法
上采样方法在目标检测中被广泛应用,用于将低分辨率特征图上采样到与输入图像相同的分辨率,以便更好地捕捉小目标或细节信息。双线性插值[22]是一种常用的上采样方法,它通过在输入特征图的像素之间进行插值来生成更高分辨率的特征图,并利用周围像素的权重来计算插值,从而平滑地增加特征图的尺寸。最近邻插值是一种简单的上采样方法,它将每个目标像素的值设置为最近邻原像素的值。虽然计算速度快,但它可能导致图像的锯齿状边缘效果和信息丢失。插值法通过像素点的空间位置来决定上采样核,并没有利用特征图的语义信息,而转置卷积[23]则与插值法不同,它不仅可以根据学习到的权重对低分辨率特征图进行插值,生成高分辨率的特征图,还可以学习到更复杂的上采样模式,但也容易导致图像的伪影和重叠现象,而且引入了大量的参数与计算。本文采用的CARAFE上采样算子主要分为2个模块(图1),一个是上采样核预测模块,用于生成用于重组计算的核上的权重,另一个是特征重组模块,用于将计算到的权重融于输入的特征图中,会根据输入特征来指导重组过程,同时整个算子比较轻量。

图1 CARAFE原理图Fig.1 CARAFE schematic diagram
2 Dy-YOLO算法
首先介绍Dy-YOLO模型结构,然后详细介绍各项改进措施。
2.1 Dy-YOLO模型
Dy-YOLO模型的网络结构如图2所示。在主干中的C3-DCN模块是类似C3结构设计的一个可变形卷积模块,这个模块在处理具有形变、遮挡或不规则形状的图像时表现更加有效,能够更好地捕捉目标在不同位置和尺度上的细节信息。在颈部采用轻量级上采样算子CARAFE来代替最邻近插值法,它能够有效利用特征图的语义信息,并且具有更大的感受野聚合上下文信息,计算速度也更快。此外,引入了Dynamic Head的统一注意力机制,结合传统的YOLO检测头,通过在尺度感知的特征层、空间感知的空间位置以及任务感知的输出通道内连贯地结合多头注意力机制。Dynamic Head注意力机制与主干中的C3-DCN模块效果互补,使得模型对于浅层、深层的特征信息的提取达到有效平衡,同时还能抑制背景信息迭代累积所带来的噪声,有效提高了模型对于航拍影像的检测能力。需要注意的是,图2中的Conv模块并非仅包含卷积操作,还包括归一化和激活函数的处理。而C3模块是一个用于特征提取的模块,它采用了ResNet的残差结构,内部的BottleNeck数量可以根据需要进行调节。
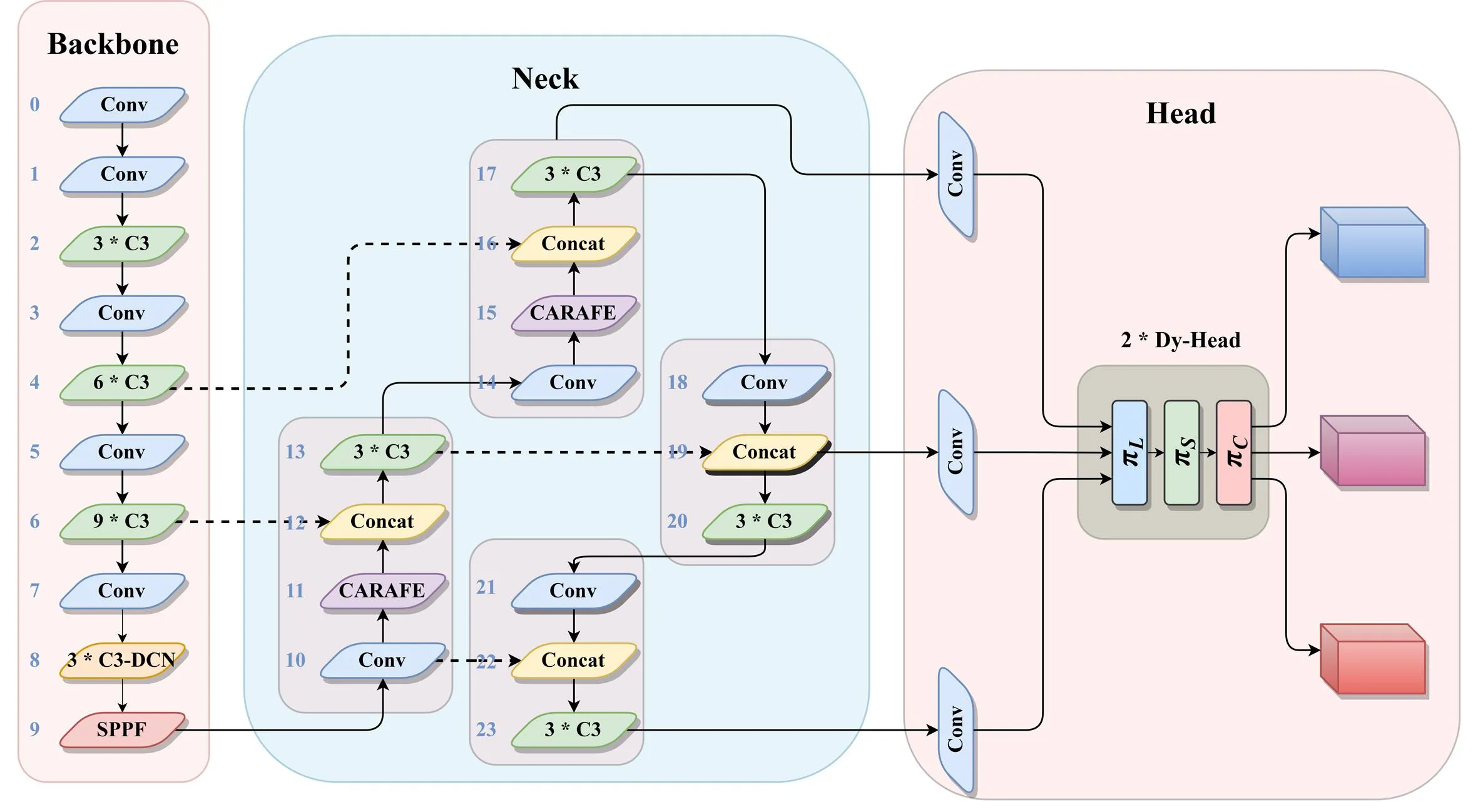
图2 Dy-YOLO网络结构Fig.2 Dy-YOLO network structure
2.2 Sim-OTA
YOLOv5使用的标签分配方法是基于IoU的匹配策略:该方法通过计算预测框与真实框之间的IoU值来确定它们的匹配程度,并根据设定的阈值将预测框分配给对应的真实框,但是IoU阈值的选择对结果非常敏感,特别影响对小目标的检测精度。而且在目标检测任务中,正样本通常比负样本数量少很多,这会导致训练过程中的样本不平衡问题,可能会影响模型的性能和训练稳定性,而在无人机航拍任务中,小目标样本数量占比较多,还伴随着大量的遮挡以及模糊,所以原先的标签分配方式不适合无人机航拍任务。因此本文采取YOLOX中提出的sim-OTA标签分配方法,它根据OTA标签分配方法改进,OTA是一种考虑全局最优的标签分配方法,它提出将标签分配问题当作最优传输问题,在GT和所有预测框之间计算运输成本,通过寻找一个合适的映射关系,使得运输成本最低。OTA通过Sinkhorn-Knopp算法求解cost矩阵,这会带来25% 的额外训练时间,sim-OTA则是将其简化为动态top-k策略,直接用k个最小cost值的候选框作为正样本以获得近似解,不仅减少了训练时间,而且避免了求解 Sinkhorn-Knopp算法中额外的超参数,sim-OTA的标签分配方式在本文中减少了负样本的影响,有效地提高了目标检测精度。sim-OTA首先计算成对匹配度,由每个预测GT对的成本或质量表示。例如,在Sim-OTA中,gi和预测框pj之间的成本计算如下:
(1)
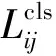
(2)
其中,Lcls代表分类损失,Lreg代表定位损失,Lobj代表目标存在损失,λ代表定位损失的平衡系数,即被分为正样本的Anchor Point数。
2.3 Dynamic Head
为了提高目标检测的准确性,越来越多的模型中加入注意力机制来让网络更加聚焦重点区域,然而大多数注意力机制普适性不强,有的注意力机制在引入以后,不仅大大增加了模型的计算复杂度以及参数量,而且检测效果不升反降。对于加入网络中不同位置的效果,还需要大量的实验测试,这对于资源有限的研究者无疑需要耗费大量时间及资源。Dynamic Head是微软提出的一种多重注意力机制统一物体检测头方法,通过在3个不同的角度(尺度感知、空间位置、多任务)分别运用注意力机制,在不增加计算量的情况下显著提升模型目标检测头的表达能力,这种新的实现方式,提供了一种可插拔特性,并提高了多种目标检测框架的性能。Dynamic Head结构如图3所示。

图3 Dynamic Head 网络结构Fig.3 Dynamic Head network structure
3个感知增强模块如图3所示,通过3个运用在不同位置的注意力即得到增强后的输出:
W(F)=πC(πS(πL(F)·F)·F)·F。
(3)
(1)尺度感知注意力πL:
(4)
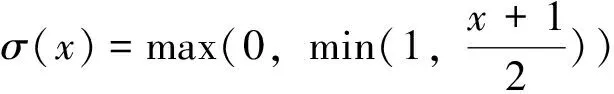
(2)空间感知注意力πS:
(5)
其中K是稀疏采样位置的数量,pk+△pk是通过自学空间偏移量 偏移的位置,以关注判别区域,而△mk是位置pk处的自学习重要性标量,两者都是从F的中值水平的输入特征中学习的。
(3)任务感知注意力πC:
πC(F)·F=max(α1(F)·FC+β1(F),α2(F)·FC+β2(F)),
(6)
其中,FC是第C个通道的特征切片,[α1,α2,β1,β2]T=θ(·)是学习控制激活阈值的超函数。θ(·)首先对维进行全局平均池化降维,然后使用2个全连接层和一个归一化层,最后应用shifted sigmoid函数对输出到[-1,1]。上述3种注意力机制是顺序应用的,它们的通道数一致,可以多次嵌套方程式(3)有效地将多个πL(F)、πS(F)和πC(F)块堆叠在一起,并且统一这3种注意力于检测头,而已知YOLOv5 Neck输出256,512,1024共3种不同通道数的特征图进入检测头,所以本文在Neck输出的3个特征图后接一层卷积,使3层特征图通道数一致,经过尺度感知注意力模块πL(F),特征图对前景物体的尺度差异更加敏感;进一步通过空间感知注意力模块πS(F)后,特征图变得更加稀疏,并专注于前景物体去辨别空间位置;最后通过任务感知注意力模块πC(F)后,特征映射根据不同下游任务的要求重新形成不同的激活。
2.4 C3-DCN
Dynamic Head中提到,主干中使用可变形卷积(deformable convolutional network,DCN)[24]可以与所提出的动态头部互补,传统的卷积采用固定尺寸的卷积核,在感受野内使用固定的权重进行特征提取,不能很好地适应几何形变,而可变形卷积通过引入额外的可学习参数来动态地调整感受野中不同位置的采样位置和权重,这使得可变形卷积能够在处理具有形变、遮挡或不规则形状的图像时更加有效。但是DCN的一大缺陷在于,其采样点经过偏移之后的新位置会超出我们理想中的采样位置,导致部分可变形卷积的卷积点可能是一些和物体内容不相关的部分;DCNv2[25]则针对偏移干扰问题引入了一种调制机制:
(7)
其中,△pp和△mp分别是第k个位置的可学习偏移量和调制标量。调制标量△mp位于[0,1]范围内,而△pp是一个范围不受约束的实数。由于p+pp+△pp是小数,因此在计算x(p+pp+△pp)时应用双线性插值,△pp和△mp都是通过应用于相同输入特征图的单独卷积层获得的。
DCNv2不仅让模型学习采样点的偏移,还要学习每个采样点的权重,这是减轻无关因素干扰的最重要的工作,提高了模型的表达能力和适应性。然而单纯地使用DCNv2效果不佳,于是在Dy-YOLO中,根据C3结构设计了C3-DCN模块(图4),并在第8层替换了C3,没有在Backbone全部替换的原因是:一方面,可变形卷积引入了额外的偏移以及调制参数,大量使用显然会增加模型复杂度以及训练难度;另一方面,在实验探索过程中,大量替换C3模块检测效果不升反降,合理使用C3-DCN模块可以在一定程度上缓解图像遮挡问题,在VisDrone数据集上,使得Dy-YOLO网络模型对具有高密度的被遮挡对象有更好的识别性能。

图4 C3-DCN网络结构Fig.4 C3-DCN network structure
3 实验与结果分析
3.1 数据集与实验设置
为了测试模型在无人机航空目标检测任务中的效果,选择VisDrone2019数据集,其由天津大学机器学习和数据挖掘实验室AISKYEYE团队收集,通过各种无人机摄像头捕获,覆盖范围十分广泛,标注了行人、人、汽车、面包车、公共汽车、卡车、货车、自行车、遮阳三轮车和三轮车10类样本。VisDrone2019官方数据集将样本分为训练集(6 471幅图像)、验证集(548幅图像)和测试集(3 190幅图像),其中测试集分为challege(1 580幅图像)和dev(1 610幅图像),共计260万个目标实例样本。本文所有的模型都使用TeslaA100 GPU进行训练,在训练阶段,使用YOLOv5m的预训练权重,因为Dy-YOLO和YOLOv5共享大部分网络结构,有很多权重可以从YOLOv5m转移到Dy-YOLO,通过使用这些权重可以节省大量的训练时间。训练参数如下:训练轮次设置为200,批处理尺寸大小设置为8,图片尺寸均为640×640像素,训练超参数为hyp.scratch-low.yaml文件的原始数据,采用SGD优化器。
3.2 评价指标
为了更准确地评估算法的性能,选取平均精度(average precision,AP)和均值平均精度(mean average precision,mAP)作为评价指标。AP 能够反映单个目标类别的检测性能,mAP 能够反映所有类别的综合检测性能。AP 由精确率(Precision)和召回率(Recall)计算得到,精确率和召回率由式(8)和(9)计算得到:
(8)
(9)
其中,TP 表示被预测为正例的正样本,FP 表示被预测为正例的负样本,FN表示被预测为负例的正样本。选定一个IoU阈值,AP的计算方式是对该IoU阈值下的不同类别的精确率-召回率曲线(PR曲线)进行积分,mAP则是对所有类别AP取平均值:

(10)
(11)
3.3 实验结果
为了验证 Dy-YOLO 模型的性能,本文选取了多种先进的无人机航拍图像目标检测模型进行对比分析。表 1 给出了各个模型在VisDrone2021测试集上在 IoU 阈值为0.50的mAP和AP。如表1所示,本文的方法比大多数方法检测效果更优,对比近年的针对小目标的检测器TPH-YOLOv5及检测mAP差距不到1%,但是TPH-YOLOv5是以YOLOv5的X模型、大尺寸以及多种训练方法得到测试结果,本文提出的Dy-YOLO以YOLOv5的M模型为基准,训练使用640×640像素的图片尺寸,整体达到轻量而高效,与基准模型YOLOv5结果进行对比,在mAP50上提升了7.1%,对比其他方法仍然保持了检测精度的优势。

表1 VisDrone测试数据集实验结果Tab.1 Experiment results in VisDrone test dataset %
表2中从上到下依次添加了本文改进的模块或方法,从消融实验结果可以看出,本文设计添加的组件对模型检测目标的准确度均有提升,首先实验添加的Sim-OTA动态标签方法整体提升最多,精度与准度都提升了6%,mAP50甚至提升了7.2%,说明基于IoU的标签分配方法对于小目标数据集损失比较大,证明加入Sim-OTA动态标签方法的有效性;C3-DCN+Dynamic Head结构加入虽然提升不多,但是可以看出它与Sim-OTA动态标签方法相结合提升了召回率,并且mAP50又提升了1.1%,说明了此结构与Sim-OTA标签方法配合能很好地使网络关注重点区域;最后把CARAFE替换Nearest上采样,精度和准度均有提升,mAP50提升了0.3%,在训练过程中也更快更稳定。

表2 VisDrone测试数据集消融实验结果Tab.2 Ablation results in VisDrone test dataset
对于C3-DCN在Backbone的位置本文也做了实验探索,结果如表3所示,选择从深层往浅层网络过渡,是因为网络随着深度增加往往会丢失很多浅层特征,而小目标的检测依赖浅层特征。替换第8层检测效果最好,替换第6和8层效果不增反减,把Backbone中C3全部替换虽然效果不及替换第8层,但是结果可以看出C3-DCN结构有利于提高召回率,规整的可变形卷积网络结构有利于提取特征。
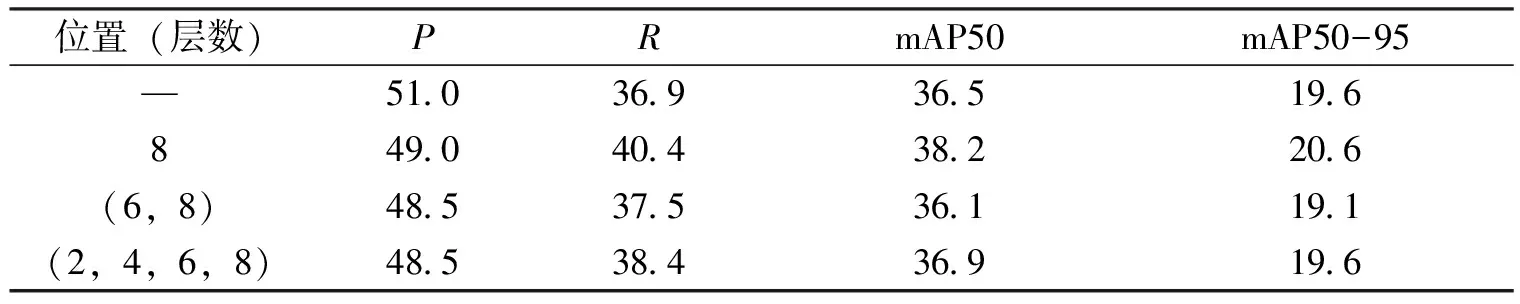
表3 VisDrone测试数据集上C3-DCN位置的消融实验结果 Tab.3 Ablation results of C3-DCN in VisDrone test dataset %
为验证本文提出的改进YOLOv5目标检测算法具有更好的目标检测能力,本文与YOLOv5(M)以及目前的先进目标检测算法进行各类检测效果对比实验。如表4所示,Dy-YOLO在检测行人(pedestrian)、人(people)和摩托车(motor)等小目标的效果上达到最优,对比基准模型YOLOv5,分别提升了7.3%、10.8%和12%,并且在检测车(car)等体型较大的目标上的效果也有所提升,提升了7.4%。
3.4 可视化分析
为了验证Dy-YOLO算法在实际场景中的检测效果,选取VisDrone2019测试集中多个复杂场景下的无人机航拍图像进行测试。检测结果如图5所示,在白天与黑夜场景中,对于分布密集的小目标,例如汽车、行人,摩托等目标样本,可以准确识别每个目标的确切位置;在背景复杂的情况下,该方法也能够排除例如树木、建筑等干扰物体的影响,正确地分类和定位目标。总的来说,本文方法在不同光照条件、背景、分布状况的实际场景中均展现出较好的检测效果,可以满足无人机航拍图像目标检测任务的需求。

图5 不同场景检测效果Fig.5 Detection effects in different scenarios
4 总结与展望
通过分析无人机航拍图像的特点,总结了无人机航拍目标检测遇到的困境,针对当下无人机航拍目标检测效果不太理想的问题,本文提出了一个基于YOLOv5的改进目标检测模型Dy-YOLO,通过引入Dynamic Head头部统一的注意力,从尺度、通道和多任务3个角度提升了目标定位能力。同时,通过引入SimOTA动态标签分配方法,提升了小目标的检测效果。此外,设计了可变形卷积结构C3-DCN与Dynamic Head首尾呼应,实现了自适应感受野和处理空间变形的能力,提升了目标边界的准确性和模型的表达能力,最后还采用了CARAFE上采样算子能够更好地聚合上下文信息并提高模型鲁棒性。这些改进方法为无人机航拍目标检测带来了显著的性能提升和新的研究思路。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
