
可搜索加密的安全性研究进展
2024-01-15 08:41纪里城张亦辰李继国
福建师范大学学报(自然科学版) 2024年1期
纪里城,张亦辰,李继国
(福建师范大学计算机与网络空间安全学院,福建 福州 350117)
随着互联网的发展和大数据时代的到来,生活中产生的数据量正在以前所未有的速度增长。产生的数据包含了大量的个人信息和敏感信息,如何保护数据的安全和隐私,成为一个亟待解决的问题[1-14]。为了保证数据的机密性,越来越多的公司和个人用户选择对数据进行加密,并将数据以密文形式存储在云端服务器,但是当用户需要寻找包含某个关键词的相关文件时,将会遇到如何在云端服务器的密文中进行搜索操作的难题。一种最简单的方法是将所有密文数据下载到本地进行解密,然后在明文上进行搜索,但是该方法不仅会因为大量不需要的数据而浪费庞大的网络开销和存储开销,而且用户也因为需要解密和搜索操作付出巨大的计算开销。另一种极端的方法是将密钥发给云端服务器,让云端服务器解密密文数据,并进行明文上的搜索操作。但是这种方法严重威胁到数据的安全和用户的个人隐私。可搜索加密是解决云计算环境下密文检索、保护用户数据安全与隐私的有效方法。可搜索加密按照搜索时使用的密码算法可分为两类:公钥可搜索加密(public key encryption with keyword search,PKES)和对称可搜索加密(searchable symmetric encryption,SSE)。在电子商务的背景环境下,将关键词进行加密来搜索信息可以进一步保护用户的安全和隐私,减少大量广告推送消息的植入。因此,可搜索加密具有广泛的应用前景。
本文分析了公钥可搜索加密和对称可搜索加密的国内外研究背景与现状,给出了公钥可搜索加密面临的挑战及解决思路与方法,梳理了对称可搜索加密方案的安全模型、攻击方法和防御方法,最后讨论了可搜索加密需进一步研究的问题和未来发展方向。
1 公钥可搜索加密
1.1 研究背景与现状
2004年,Boneh等[15]首次提出公钥可搜索加密概念,并构造了相应的公钥可搜索加密方案。该方案主要用于解决“多对一”的邮件过滤问题。在该问题中,多个发送者都希望向Alice发送电子邮件。电子邮件首先会发送到邮件网关,然后由邮件网关转发给Alice。Alice希望邮件网关根据电子邮件中的关键词将电子邮件发送到适当的设备,比如将带有“紧急”的关键词发送到Alice的手机上,以便Alice能够迅速查看。为了保护电子邮件的内容,发送者需使用Alice的公钥对电子邮件内容和关键词进行加密。但是,邮件网关无法直接看到关键词,从而无法作出路由和转发决策。公钥可搜索加密允许Alice将某个关键词的陷门发送给邮件网关,然后邮件网关可以使用陷门搜索包含该关键词的加密电子邮件,并将结果返回给Alice。上述方式既保护了电子邮件的隐私,又使邮件网关能够根据关键词作出智能的路由和转发决策。
早期的PKES方案[16-19]大多采用“多对一”的邮件过滤模型。之后,PKES方案[20-23]主要应用于“一对多”的多用户文件共享系统模型。该模型的执行过程如图1所示。数据拥有者的目的是共享一些文件,但需要防止服务器知道其中的敏感信息,希望只有授权的数据用户才能了解共享文件的内容。为了实现目标,数据拥有者首先需要从原始文件中提取一些关键词,然后使用一些特殊的加密算法对关键词进行加密,生成关键词密文。原始文件则通过对称加密算法生成加密文件。最后数据拥有者将加密文件和关键词密文一起上传给服务器。授权的数据用户如果希望获取共享文件的内容,则通过陷门生成算法将查询关键词转化为搜索陷门并将其发送给服务器。服务器在收到搜索陷门后开始执行搜索操作,并最终将搜索到的加密文件返回给授权的数据用户。

图1 “一对多”的公钥可搜索加密Fig.1 “One-to-many”public key encryption with keyword search
1.2 问题与挑战
传统的可搜索加密通信模式往往是一对一的,在云计算系统中有很多局限性。随着存储在云端的数据越来越多,用户提交的解密请求将会导致大量满足访问权限的密文被云端反馈给用户,其中有相当一部分内容是用户不想访问的,面临密文检索问题[24-27]。通过引入关键词搜索功能,大大提高了用户访问云数据的效率,减少了不必要的通讯开销。云端只需要反馈满足访问权限且和关键词相匹配的密文即可,属性基加密(attribute based encryption,ABE)结合可搜索加密技术可以实现一对多的保密通信,因此,研究可搜索ABE方案是解决云计算环境下密文检索的关键技术。现有的可搜索加密方案面临着严峻的关键词猜测攻击问题,即恶意的检索服务器获取某关键词检索陷门后,可以通过穷举所有可能的关键词的方法,暴力测试出该检索陷门所含的关键词。虽然基于访问控制策略的可搜索加密可以实现多用户在密文上进行关键词搜索功能,但该类机制只能处理同一公钥加密的密文,不能很好地对不同公钥加密的密文进行处理。因此,如何设计支持不同公钥加密得到的密文直接比较、判断是否包含相同的关键词的公钥可搜索加密是一个具有挑战性的课题。
1.3 解决思路与方法
1.3.1 可搜索属性基加密体系结构
为了实现“一对多”的保密通信,Li等[28]提出可搜索ABE体系结构,如图2所示,其工作原理如下:数据拥有者首先提取数据明文的关键词,然后使用数据用户的公钥对关键词进行加密生成关键词密文(即索引),并将关键词密文和数据密文一起上传给云存储提供者;当数据用户需要搜索数据密文时,利用其私钥生成待搜索关键词的陷门信息,并将其发送给云存储提供者;云存储提供者收到数据用户的关键词陷门后,运行测试算法将其与关键词密文进行匹配,如果测试算法成立说明该关键词密文所关联的数据密文中含有数据用户搜索的关键词信息;云存储提供者将所有相匹配的数据密文返回给数据用户,当且仅当数据用户属性列表与数据密文中嵌入的访问策略相匹配时,才能使用自己的私钥对数据密文解密得到相应的数据明文。此外,为了支持属性撤销,可搜索ABE体系结构采用懒散代理重加密技术,仅当数据用户访问存储在云端的数据时,相应的数据才进行更新,提高了系统的灵活性。
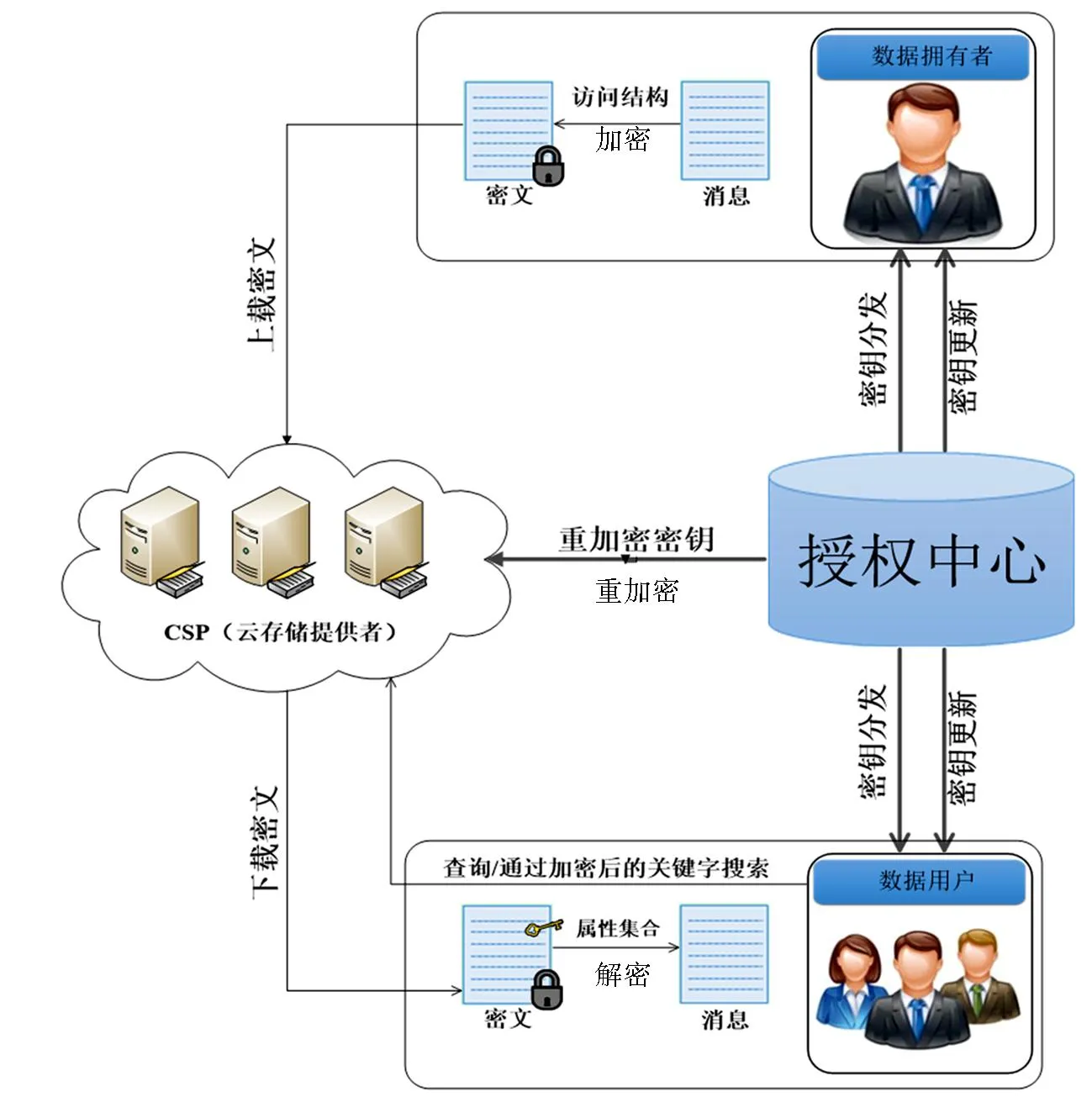
图2 可搜索ABE体系结构Fig.2 Searchable ABE system architecture
1.3.2 解决用户隐私问题
为了解决用户隐私问题,Li等[28]考虑了以下两方面内容:首先,利用通配符表示数据拥有者指定的访问结构中其不“关心”的那些属性值。对数据用户而言,访问策略是部分隐藏的,数据用户能够成功解密,但无法知道访问策略的具体内容,保护了用户的隐私信息。其次,即使云存储提供者执行相关检索和测试,由于数据用户提交的是搜索关键词的陷门信息而不是明文关键词,因此,云存储提供者不能获得关于所请求搜索关键词内容以及文件的明文信息,保护了用户的隐私。
1.3.3 解决关键词猜测攻击问题
在公钥可搜索加密方案设计中,密文关键词和关键词的陷门信息是需要重点考虑的问题。云存储提供者在整个搜索的过程中猜测任意2个搜索语句是否包含相同的关键词,并获得相关搜索结果,可能影响系统安全性。因此,关键词猜测攻击是设计公钥可搜索加密方案面临的主要挑战之一[29]。
从技术的视角,现有公钥可搜索加密不能抵抗关键词猜测攻击的根本原因在于关键词密文被攻击者伪造。解决该问题的基本思路[30-31]是:使关键词密文对敌手(包括外部攻击者和云服务器)具有不可伪造性,即敌手无法产生其猜测的关键词密文。基于上述思路,一种解决方案是:利用签密的思想,数据拥有者使用自己的私钥和接收者的公钥产生关键词的密文。由于签密不仅满足不可区分安全性而且满足存在性不可伪造性,因此敌手无法伪造其猜测的关键词的签密,从而无法实施关键词猜测攻击。采用这种解决方案,接收者需使用数据拥有者的公钥和自己的私钥产生关键词陷门。关键词签密和关键词陷门匹配的同时,也完成了关键词签密的真实性验证。另一种解决方案是:在关键词密文和关键词陷门中嵌入数据拥有者和接收方共享的秘密值。数据拥有者和接收者首先使用两方或多方安全计算协议建立共享的秘密值k;数据拥有者使用接收者的公钥对关键词w和共享的秘密值k的哈希值H(w,k)进行加密产生关键词密文;接收者则使用其私钥产生关键词w′和共享秘密值k的哈希值H(w′,k)的陷门。如果w=w′,则H(w,k)=H(w′,k),因此H(w,k)的密文与H(w′,k)的陷门必然是匹配的。由于关键词密文的产生使用了敌手未知的秘密值k,因此关键词密文对于敌手具备了不可伪造安全性,进而使得方案能够有效抵抗关键词猜测攻击。易见,第二种解决方案具有一般性,能在已有可搜索公钥加密方案的基础上,将满足相应安全性要求的可搜索ABE方案通用地转化为抗关键词猜测攻击的可搜索ABE方案。在上述2种解决方案中,由于关键词对于敌手都是不可伪造的,敌手即使截获了用户的关键词陷门也无法对其进行关键词猜测攻击。此外,关键词陷门可公开传输,也避免了关键词陷门需要通过安全信道传输的问题。
1.3.4 解决密文关键词等值测试问题
可搜索ABE可以实现多用户在密文上进行关键词搜索的功能,但是只能处理同一公钥加密的密文,不能很好地解决不同公钥加密的密文关键词检索问题。Ma等[32]结合可搜索ABE方案和等值测试方案,构造出满足不同公钥加密的密文关键词检索的密文策略属性基等值测试加密方案。进一步将外包解密技术应用于基本的属性基等值测试加密方案,通过嵌入盲化因子和密钥变换使密文能在解密过程中转化为ElGamal型密文,在支持外包解密的同时,支持等值测试加密,提高了客户端的解密效率。
2 对称可搜索加密
2.1 研究背景和现状
随着云计算的发展,用户希望将文件上传至远端的服务器,但又担心服务器泄漏自己的数据。为了保护个人隐私,2000年,Song等[33]首次提出可搜索加密的概念,并实现第一个对称可搜索加密方案,该方案主要解决不可信赖的服务器存储问题。用户可以将文件加密之后再上传。然而,当用户需要搜索服务器上的某个文件时,通常需要将所有的文件全部下载,解密后再进行搜索。可搜索加密技术使用户能直接搜索服务器上的某个加密文件,而无须下载所有文件。对称可搜索加密过程如图3所示。
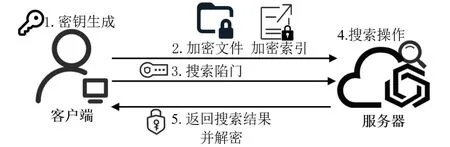
图3 对称可搜索加密Fig.3 Searchable symmetric encryption
上述过程可以看出服务器只在加密索引上进行搜索操作,而不在加密文件上进行搜索操作。SSE方案主要由以下4个算法构成。
(1)密钥生成算法KenG(1k)→K:由客户端执行的概率算法,输入安全参数k,输出对称密钥K。
(2)构建索引算法BuildIndex(K,D)→I:由客户端执行的概率算法,输入对称密钥K和包含n个文件的文件集合D=(D1,…,Dn),输出加密索引I。
(3)陷门生成算法Trpdr(K,w)→t:由客户端执行的确定性算法,输入对称密钥K以及查询关键词w,输出搜索陷门t。
(4)搜索算法Search(I,t)→X:由服务器执行的确定性算法,输入加密索引I以及陷门t,输出文件标识符集合X。
由上述算法框架可观察到,SSE在搜索操作中采用了对称加密算法,带来了显著的搜索效率,适用于大数据的应用场景,尤其是在云存储系统中。因此,SSE成为密码学领域的研究热点[34-37]。
2.2 对称可搜索加密安全模型
2.2.1 IND-CPA安全模型
Song等[33]在2000年首次提出可搜索加密概念,并使用伪随机生成器,伪随机函数和伪随机置换实现了第一个可搜索加密方案,被称为SWP方案,如图4所示。SWP方案采用了顺序扫描索引结构,即将每个文件视为一个有序的关键词排列。对于排列中的每个明文关键词Wi,采用伪随机置换E处理,然后使用流密码对置换结果E(Wi)进行异或,生成相应的密文C。文件的所有密文构成一个顺序扫描加密索引。如图4,Si表示一个伪随机值,而F表示带密钥的伪随机函数。当客户端需要查询某个关键词Wi时,使用伪随机置换E生成搜索陷门E(Wi),然后将其发送给服务器。服务器接收到陷门后,对所有存储密文进行异或。如果某个密文异或后的结果形如(s,Fki(s)),该密文对应的加密文件就是搜索结果之一。
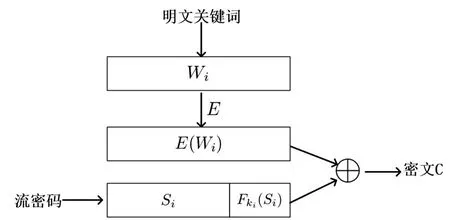
图4 SWP方案[33]Fig.4 SWP scheme[33]
Song等[33]在其SSE方案中没有提出安全定义,而是采用加密方案中的选择明文攻击下的不可区分性(indistinguishability under chosen plaintext attack,IND-CPA)安全模型证明SSE方案的安全性。IND-CPA安全模型保证了存储在服务器上的加密索引不会泄漏明文信息。然而,IND-CPA安全模型并没有保证陷门的信息泄漏,即不保证查询关键词的机密性。而搜索陷门的信息泄漏直接影响存储在服务器上加密文件的安全性。因此IND-CPA安全模型并不能完整地表达SSE方案的安全性。
2.2.2 IND-CKA和IND2-CKA安全模型
2003年,Goh[38]提出第一个可搜索加密安全模型,称为选择关键词下的不可区分性(indistinguishability under chosen keyword attack,IND-CKA)安全模型,并提出一个更强大的安全模型IND2-CKA。2个模型旨在确保敌手无法从加密索引推断出加密文件中的内容。具体而言,IND-CKA安全模型是一个安全游戏,包含以下4个阶段和2个交互实体:挑战者C和敌手A。
(1)设置阶段:由挑战者C选取q个关键词组成一个集合S,将集合S发送给敌手A。敌手A从集合S中选取n个子集构成一个集合S*,然后将其发送给挑战者C。挑战者C使用索引生成算法生成加密索引,最后将加密索引I发送给敌手A。
(2)查询阶段:敌手A想要查询关键词w,则需要向挑战者发送关键词w。挑战者收到关键词之后,使用陷门生成算法生成搜索陷门t,并返回给敌手A。敌手A使用搜索算法确定包含关键词w的文档。查询阶段允许敌手A执行多项式次数的查询。
(3)挑战阶段:敌手A首先从S*中选取一个非空元素V0,然后从S中选取一个子集V1并要求V0和V1具有相同的关键词数量,且至少有一个关键词是不相同的。之后,敌手A将2个集合V0和V1发送给挑战者C。挑战者C从V0和V1中随机选取一个集合Vb,b∈{0,1}。挑战者C使用索引生成算法生成加密索引I并将其返回给敌手A。此时,敌手A依然可以查询关键词,但是不允许查询V0和V1之间不同的关键字。
(4)响应阶段:敌手A返回一个比特b′∈{0,1},表示敌手猜测加密索引对应的集合是Vb′。
敌手的优势定义为AdvA=|Pr[b=b′]-1/2|,其中Pr[b=b′]表示敌手猜测正确的概率,而1/2表示敌手随机猜测的概率。如果任意敌手的优势是可忽略的,该方案是IND-CKA安全的。
从安全游戏可以看出,如果一个SSE方案是IND-CKA安全的,意味着敌手无法从加密索引I中找到有关V0和V1不同关键字的信息,也就表明加密索引I不会泄漏加密文件的内容。IND2-CKA安全模型允许敌手在挑战阶段选取2个关键词数量不同的集合增加敌手优势。因此安全模型IND2-CKA比IND-CKA更强大。虽然2种安全模型都防止SSE方案中加密索引的信息泄漏,但是都没有考虑陷门的信息泄漏。换言之,即使一个SSE方案是IND-CKA安全的,但是该方案也有可能泄漏搜索陷门的信息,从而导致加密文件内容的泄漏。因此IND-CKA和IND2-CKA安全模型也不能完整地表达SSE方案的安全性。
2.2.3 非适应性和适应性安全模型
2005 年,Chang等[39]提出了基于模拟IND-CKA的安全模型,其本质上等价于IND2-CKA安全模型。2006年,Curtmola等[40]指出之前的安全模型[33,38-39]没有考虑陷门的信息泄漏并构造了2个实例,分别揭示了IND2-CKA和基于模拟的IND-CKA安全模型的缺陷。构造的2个实例虽然满足IND2-CKA安全和基于模拟的IND-CKA安全,但敌手却能够直接恢复客户端搜索的关键词。为了完整地表达SSE方案的安全性,Curtmola等[40]提出新的安全模型,其构建在以下4个形式化概念上。
定义1(查询历史) 令△是一个关键词集合,D是△上的文件集合。D上的一个q-查询历史是一个二元组H=(D,w),其中D是文件集合,w=(w1,w2,…,wq)是一个查询向量。
定义2(访问模式) 令△是一个关键词集合,D是△上的文件集合。对于一个D上的q-查询历史H=(D,w),访问模式是一组向量α(H)=(D(w1),D(w2),…,D(wq)),其中D(wi)表示包含关键词wi的文件集合。
定义3(搜索模式) 令△是一个关键词集合,D是△上的文件集合。对于一个D上的q-查询历史H=(D,w),搜索模式是一个q×q的对称二进制矩阵σ(H),当第i个查询关键词和第j个查询关键词相同时,即wi=wj,则σ(H)的第i行第j列为0,否则为1。
定义 4(痕迹) 令△是一个关键词集合,D是△上的文件集合。对于一个D上的q-查询历史H=(D,w),痕迹τ(H)=(|D1|,…,|Dn|,α(H),σ(H)),其中|Di|表示第i个文件的大小,α(H)表示访问模式,σ(H)表示搜索模式。
对于以上定义,查询历史表明客户端在q次查询中分别查询了哪些关键词。访问模式表示SSE方案泄漏了包含查询关键词的文件标识符集合。搜索模式揭示了SSE方案泄漏了哪2次查询关键词是相同的。痕迹表示在q次查询中服务器都知道了哪些信息。随后,Curtmola等[40]借助上述概念提出4种安全模型:非适应性不可区分安全模型、非适应性语义安全模型、适应性不可区分安全模型和适应性语义安全模型。“非适应性”要求所有的查询只能一次性提出。相比之下,“适应性”允许敌手根据先前的查询和搜索结果,自适应地提出新的查询关键词。非适应性不可区分安全模型和非适应性语义安全模型的形式化定义如下。
定义5(非适应性不可区分) 令SSE=(KenG,BuildIndex,Trpdr,Search)是一个基于索引的SSE方案,A=(A1,A2)是非一致性敌手,考虑以下概率实验。
InDSSE,A(k):
K←KenG(1k)
(stA,H0,H1)←A1(1k)
将Hb视为(Db,wb)
ib←BuildIndex(Db,K)
对于1≤i≤q,
tb,i←Trpdrk(wb,i)
令tb=(tb,1,…,tb,q)
b′←A2(stA,ib,tb)
如果b′=b,输出1,否则输出0。
上述概率实验中stA表示敌手A1状态。此外,实验还要求H0和H1的痕迹是相同的,即τ(H0)=τ(H1),否则敌手A2可以直接区别两个查询历史。如果对于所有多项式大小的敌手A=(A1,A2),都存在一个可忽略函数negl(k),使得
则一个SSE方案是非适应性不可区分的。
由于查询历史包含q个查询关键词,因此敌手可以利用搜索陷门的信息泄漏区分2个查询历史。如果一个SSE方案是非适应性不可分区的,也就意味着敌手无法利用搜索陷门区分2个查询历史,从而表明该SSE方案防止了搜索陷门的信息泄漏。因此与之前的安全模型[25,30-31]相比,非适应性不可区分考虑了搜索陷门的信息泄漏。

定义 6(非适应性语义安全) 令SSE=(KenG,BuildIndex,Trpdr,Search)是一个基于索引的SSE方案,A是一个敌手,S是一个模拟器,考虑以下2个概率实验。
RealSSE,A(k):
K←KenG(1k)
(stA,H)←A(1k)
将H视为(D,w)
I←BuildIndex(D,K)
对于1≤i≤q,
ti←TrpdrK(wi)
令t=(t1,…,tq)
输出V=(I,t)和stA
SimSSE,A,S(k):
(stA,H)←A(1k)
V←S(τ(H))
输出V和stA
如果对于所有多项式大小的敌手A,存在一个多项式大小的模拟器S,对于所有多项式大小的区分器D有|Pr[D(V,stA)=1:(V,stA)←RealSSE,A(k)]-Pr[D(V,stA)=1:(V,stA)←SimSSE,A,S(k)]|≤negl(k),则该SSE方案是非适应性语义安全的。
非适应性语义安全主要依靠模拟器S证明SSE方案的安全性。如果一个SSE方案是非适应性语义安全的,存在一个模拟器S仅使用痕迹τ(H)就能生成原来SSE方案的加密索引和搜索陷门。而模拟器S并不知道查询历史H的信息,从而表明SSE方案只泄漏了痕迹τ(H)。因此非适应性语义安全模型同时防止了加密索引和陷门的信息泄漏。适应性语义安全模型扩展了上述非适应性语义安全模型,允许敌手可以根据先前的搜索结果提出下一次查询关键字,增加了敌手的能力。
Curtmola等[40]证明了4种安全模型之间的关系,非适应性不可区分安全模型与非适应性语义安全模型等价,而适应性语义安全模型包含适应性不可区分安全模型。
2.2.4 L-适应性安全模型
虽然Curtmola等[40]提出的安全模型较全面地表达了SSE方案的安全性,但是其安全模型必须使用查询历史、访问模式、搜索模式、痕迹来描述SSE方案的安全性。而上述4个概念不能统一表达不同SSE方案中的信息泄漏。2010年,Chase等[41]引入泄漏函数(leakage function)概念用于描述SSE方案中的信息泄漏,使用L1描述加密索引的泄漏,L2描述搜索陷门的泄漏,并在此基础上提出基于现实范式和理想范式的SSE安全模型。2012年,Kamara等[42]提出基于索引的动态对称可搜索加密方案(dynamic SSE,DSSE),并将Chase等[41]的安全模型扩展为动态SSE安全模型,使用4个泄漏函数描述动态SSE中信息泄漏。2013年,Cash等[43]结合适应性语义安全模型和泄漏函数,提出L-适应性安全模型,其中L表示SSE整个方案的泄漏函数。Cash等[43]将所有静态SSE方案都分解成一个设置算法和一个搜索协议。设置算法由客户端执行,包含密钥生成算法和索引生成算法。搜索协议由客户端和服务器共同执行,包含陷门生成算法和搜索算法。下面是L-适应性安全模型的形式化定义。

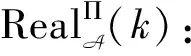
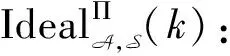
在上述形式化定义中L(D)表示设置算法的信息泄漏,而L(D,q)表示搜索协议的信息泄漏。因此泄漏函数L也可以表示为(LSetup,LSearch),其中泄漏函数LSetup描述设置算法的信息泄漏,泄漏函数LSearch描述搜索协议的信息泄漏。整个SSE方案的信息泄漏形式化重新表达为泄漏函数L=(LSetup,LSearch)。此外,上述定义表明敌手除了知道泄漏函数之外,其他有关SSE方案的信息一概不知,准确地刻画了SSE方案的信息泄漏。
相较于Curtmola等[40]提出的安全模型,上述定义较为简洁,没有使用烦琐的概念表述SSE方案的信息泄漏,统一将SSE方案的信息泄漏形式化表达为一个泄漏函数。2014年,Cash等[44]为SSE方案添加了一个更新协议,并将静态的L-适应性安全模型扩展为动态的L-适应性安全模型。更新协议由客户端和服务器共同执行,并使用Lupdate描述更新阶段时的SSE方案的信息泄漏。动态SSE方案信息泄漏的形式化表达为泄漏函数L=(LSetup,LSearch,Lupdate)。L-适应性安全模型是目前公认的SSE方案要满足的安全模型。
2.2.5 UC安全模型
2012年,Kurosawa等[45]构造了一个可验证对称可搜索加密(verifiable searchable symmetric encryption,VSSE)方案抵抗恶意敌手,并将通用可组合(unersal composability,UC)安全模型引入到SSE方案中。UC安全模型是由Canetti[46]提出的一个基于模拟的安全范式,描述了一个由n个参与实体P1,P2,…,Pn共同交互执行的协议Σ的安全性,其由环境机Z、理想世界和真实世界构成。环境机Z生成所有参与实体的输入以及读取所有协议的输出,并且在整个过程中能以任意方式与攻击者A进行交互。理想世界由一个理想函数F和一个模拟器S构成,理想函数F需根据不同的协议具体定义,模拟器S模拟对理想函数F实行敌手A的等效攻击。真实世界由协议Σ和一个敌手A构成,协议Σ在真实世界中安全实现理想函数F,而敌手A与诚实的参与实体进行交互,控制其余腐败的参与实体,并且与协议自由交互。如果对于任意概率多项式时间敌手A,都存在一个模拟器S,使得对所有非一致环境机Z区分真实世界和理想世界的概率是可忽略的,则协议Σ安全实现了理想函数F。
Kurosawa等[45]为VSSE方案定义了一个理想函数FVSSE并证明构造的方案是UC安全的,通过引入隐私性和可靠性2个概念重新定义了VSSE方案的安全性。隐私性要求服务器除文件大小、数量和访问模式之外一无所知。相对于Curtmola等[40]提出的适应性语义安全,Kurosawa等[45]定义的隐私性更严格。可靠性表明客户端能够检测恶意的服务器是否正确地执行搜索操作。最后,Kurosawa等[45]证明了一个VSSE方案在非适应性UC安全性和满足隐私性以及可靠性之间存在等价关系。2014年,Stefanov等[47]为动态SSE方案提出了抵抗半诚实敌手和恶意敌手的UC安全模型。2016年,Kurosawa等[48]将静态VSSE方案的UC安全模型扩展为动态VSSE方案的UC安全模型。
3 针对SSE方案的攻击和防御方法
与公钥可搜索加密方案可能面临的关键词猜测攻击不同,大多数SSE方案通常不会受到关键词猜测攻击。因为大部分SSE方案的搜索陷门FK(w)由伪随机函数F、关键词w以及对称密钥K构成。攻击者在不知道对称密钥的情况下,无法在多项式时间内通过穷举关键词猜测搜索陷门对应的关键词。但是,近些年的研究提出了一系列攻击方法,通过利用SSE方案的信息泄漏和已知数据集成功恢复了查询关键词。攻击方法主要分成2类:针对被动敌手的泄漏滥用攻击[49-55]和针对主动敌手的注入攻击[56-59]。泄漏滥用攻击允许攻击者在连续的查询周期内观察泄漏模式,然后将所观察到的信息与已知的数据集结合以恢复查询关键词。具体的攻击方案根据SSE方案的泄漏模式不同,而执行不同的攻击操作。注入攻击允许攻击者为客户端生成一些包含已知关键词的注入文件,然后客户端将加密文件发送给服务器。之后,攻击者观察目标查询过程中的泄漏模式以恢复查询关键词。本节将重点介绍访问模式泄漏攻击[49]、搜索模式泄漏攻击[50]和文件注入攻击[56]。此外,还讨论了一些相应的防御方法。
3.1 访问模式的攻击方法:IKK攻击和计数攻击
大部分SSE方案都允许泄漏访问模式,意味着攻击者可以获知每次搜索某个关键词的文件标识符集合。2012年,Islam等[49]提出了一种利用访问模式的攻击方法。在攻击方法中,即使文件是加密的,攻击者也可以通过分析访问模式以及一些公开的数据库而推断出文件中的信息。具体的攻击方法如下:假设攻击者已经截获了由客户端发送给服务器的l个查询Q=〈Q1,…,Ql〉以及每次查询的返回结果RQi。攻击者根据公开的数据库计算获得一个m×m的概率矩阵M,其中m是总的关键词数量。该矩阵的第i行第j列元素表示第i个关键词和第j个关键词同时出现在任意文件中的概率,即Mi,j=Pr[(Ki)∈d∧(Kj)∈d]。攻击者的目标是恢复l个查询的底层明文关键词KQ=〈Ka1,…,Kal〉。现在攻击者可以通过以下公式推测出最有可能的l个底层明文关键词。
在SSE方案中,上述攻击方法称为IKK攻击。实验结果表明,在关键词数量小于2 500个,查询的关键词为150个时,IKK攻击的恢复底层明文关键词的准确率高达60%~80%。当关键词数量为1 500个,查询关键词数量为150个以及已知关键词数量小于25个时,恢复底层明文关键词的准确率高达80%。值得注意的是,攻击者还可以借助猜测得到的关键词对概率矩阵进一步调整,以达到更好的攻击效果。
IKK攻击针对较少的关键词数量能够达到相对较高的恢复准确率,一旦关键词数量增加,其恢复的准确率就明显降低。然而,2015年,Cash等[51]在IKK攻击的基础上提出了计数攻击,该攻击即使在关键词数量较多时依然保持较高的恢复准确率。计数攻击要求攻击者除了能够知道概率矩阵M外,还要知道每次查询返回的文件数量。图5直观地展示了计数攻击与IKK攻击之间的差异,表明即使在关键词数量较多的情况下,计数攻击依然能保持较高的恢复准确率。
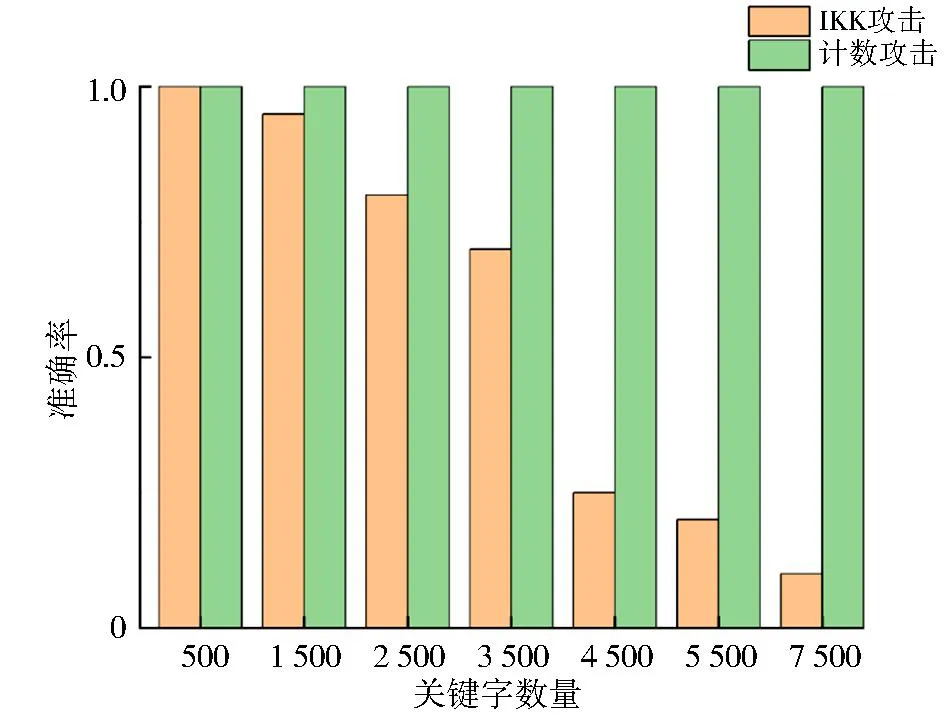
图5 IKK攻击和计数攻击比较[51]Fig.5 Comparison between IKK attack and Counting attack[51]
为了抵抗IKK攻击和计数攻击,SSE方案需要保护其访问模式或隐藏搜索返回结果的大小。目前存在许多技术可用于保护SSE方案中的访问模式,包括不经意随机访问、盲存储和差分隐私等。不经意随机访问是Goldreich等[60]于1996年提出的一项技术,旨在保护软件访问过程,至今仍然是一个备受关注的研究方向。尽管不经意随机访问为SSE方案提供了高级别的安全性和较小的信息泄漏,但也伴随着过大的计算复杂度、带宽开销以及较低的搜索效率。2014年,Naveed等[61]提出一种被称为盲存储的新密码原语用于保护SSE方案的访问模式。该技术使得服务器不知道客户端存储了多少个文件以及单个文件的大小。当某个文件被搜索时,服务器只知道该文件存在,而不了解文件的标识符和内容。另一方面,2018年,Chen等[62]引入差分隐私作为保护SSE方案中访问模式的手段,并提出了适用于通用对称可搜索加密的d-隐私访问模式混淆机制。该机制使用纠删码和差分隐私实现对访问模式的保护。实验结果表明,该机制能有效防止IKK攻击,当允许的最大泄漏值为200时,IKK攻击的准确率仅为0.1。
在隐藏搜索返回结果的大小方面,文件填充是一种常见的通用方法,通过为单个关键词添加虚拟文件,确保每个关键词返回的搜索结果大小相同。此外,还有一些隐藏返回结果大小的其他方法。例如,2018年,Lai等[63]使用隐藏向量加密构造一个支持联合关键词查询且隐藏搜索结果大小的SSE方案。
3.2 搜索模式的攻击方法
2014年,Liu等[50]提出一种新的攻击方法,攻击者通过利用搜索模式统计用户在一段时间内发出特定搜索陷门的次数,从而获得该搜索陷门的频率。攻击者通过公开的单词频率数据推测与该搜索陷门对应的查询关键词。为了更好地理解该攻击方法,通过以下例子说明。假设某个SSE方案存在搜索模式泄漏,攻击者可以知道用户查询某个关键词的频率。攻击者会在一个月的时间内每天都统计该用户某个搜索陷门出现的频率,并将结果绘制成折线图。随后,攻击者从公开数据库(例如在谷歌搜索中获取)中获得相同时间内一些关键词的搜索频率折线图。攻击者将自己统计的频率与公开的搜索频率进行对比,如果2条折线相似,则某个搜索陷门对应的明文关键词很有可能是那个公开的关键词。比如,用户可能在感恩节频繁搜索某个关键词。如果该关键词对应的搜索陷门频率与从谷歌搜索获取的“感恩节”搜索频率相似,则用户很可能正在对“感恩节”进行搜索。
一种防止搜索模式攻击的通用方法是将生成搜索陷门的确定性算法改为概率性算法。对于相同的查询关键词,每次生成的搜索陷门都是不同的,从而使得攻击者无法知道2次搜索是否为相同的关键词,进而无法统计搜索陷门的频率。例如2020年Wang等[64]使用了一种带双陷门的加法同态加密算法来保护搜索模式。
除了访问模式和搜索模式的泄漏滥用攻击,还有一些其他信息泄漏滥用攻击。例如Pouliot等[53]和Ning等[54]利用Cash等[51]提出的泄漏模式和已知部分数据集来攻击高效可部署的可搜索加密方案[65]。
3.3 文件注入攻击
2016年,Zhang等[56]提出一种针对动态对称可搜索加密的文件注入攻击。在该攻击中,服务器向用户发送文件,用户使用SSE方案中的构建索引算法生成加密索引,并将其上传给服务器。通过这种攻击方式,恶意的服务器只需向用户发送极少量的文件,然后观察SSE方案的信息泄漏,就能恢复用户的搜索关键词。下面通过一个简单例子说明文件注入攻击。假设从k0到k7共有8个关键词。如图6所示,服务器构建了3份包含特殊关键词的文件。第1份文件包含k4,k5,k6,k74个关键词,第2份文件包含k2,k3,k6,k74个关键词,第3份文件包含k1,k3,k5,k74个关键词。然后,服务器将3份文件发送给用户,用户使用构建索引算法生成的索引返回给服务器。服务器利用之前用户的搜索陷门对3份文件进行搜索。如果搜索结果是第2份文件,则意味着用户该搜索陷门对应的底层明文关键词是k2。因为第2份文件包含k2,k3,k6,k74个关键词,而k3,k6,k73个关键词包含在第1份文件或者第3份文件。如果底层明文关键词对应的是k3,k6,k7中的一个,搜索结果必然会是第1份或者第3份文件。因此,用户之前的搜索陷门对应的底层明文关键词为k2。上述确定搜索陷门对应明文关键词的方法也称为二分法。文件注入攻击简单高效,恶意服务器可以任意设定关键词数量,如果事先了解到用户的搜索习惯,可以构建包含较少关键词的文件,以确定之前用户的陷门对应的明文关键词。对于m个关键词,只需构造log2m个文件就能百分百确定之前搜索陷门对应的明文关键词。
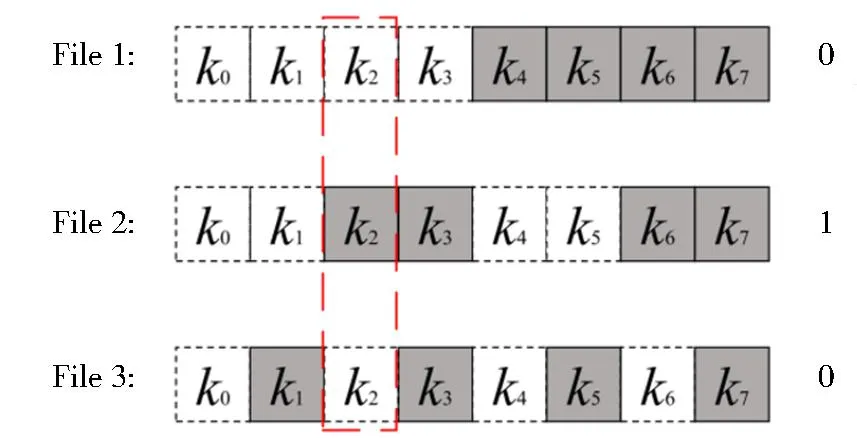
图6 文件注入攻击[56]Fig.6 File injection attack[56]
文件注入攻击的关键点在于恶意服务器需要利用之前的搜索陷门来搜索文件注入后的加密索引,即之前的搜索陷门泄漏了新添加文件。为了防止该攻击,动态对称可搜索加密方案需要达到前向安全。前向安全是由2014年Stefanov等[47]提出的动态SSE方案的安全概念,其保证了用户添加的新文件不会被之前的陷门搜索到。如果一个动态SSE方案满足前向安全,则上述的文件注入攻击是无效的。因为服务器利用之前的陷门也无法搜索到注入的文件或称为添加的文件,从而无法使用二分法确定明文关键词。Stefanov等[47]虽然提出前向安全的概念,但是并没有给出前向安全的形式化定义。直到2016年,Bost[66]首次给出前向安全的形式化定义,并精妙地构造了一个满足前向安全的动态SSE方案,该方案主要利用陷门置换函数来控制搜索陷门的有效搜索范围。一旦有新的文件插入,客户端就利用私钥将搜索陷门向前置换。置换后的搜索令牌只能解密新插入的文件集合。而服务器可以利用公钥对搜索陷门向后置换(直到初始令牌),以此来解密之前添加的文件。该方案通过一个递归调用即可解密包含某关键词的所有文件。由于服务器无法向前置换,使得搜索陷门无法搜索新添加的文件,从而保证了前向安全。之后,各种构建具有前向安全的动态SSE方案[67-70]层出不穷,并迅速成为研究热点。
最近的研究提出体积注入攻击[57-59]优化文件注入攻击。体积注入攻击减少了攻击者需要注入文件的数量,攻击者通过已知的关键字并观察搜索结果返回的加密文件数量而高效恢复查询关键字。
4 结束语
本文从公钥可搜索加密和对称可搜索加密2个方面入手,着重探讨了可搜索加密的安全性。关于公钥可搜索加密的安全性,深入介绍了关键词猜测攻击和密文关键词等值测试,并给出相应的解决方法。在对称可搜索加密方面,回溯了其常见安全模型,并深入介绍针对SSE方案的3种基本攻击方法以及相应的防御方法。当前情况下,可搜索加密技术已经初步完善,具备广泛应用的前景。然而,其安全性仍然是制约其应用的主要挑战之一。在此基础上,本文思考可搜索加密在安全性方面的未来发展方向。
(1)迄今为止,许多公钥可搜索加密方案依然未能有效地应对关键词猜测攻击的潜在威胁。因此,将研究集中在构建具有高效性的公钥可搜索加密方案,以抵挡关键词猜测攻击。这不仅需要对目前技术进行深入审视,还应探索创新性的方法,以提高公钥可搜索加密的安全性水平,确保用户的数据隐私得到可靠保护。
(2)目前,大多数SSE方案并不能同时有效地防止多个方面的信息泄漏,例如访问模式和搜索模式泄漏。即便有一些SSE方案能够防止多个方面的信息泄漏,其搜索效率往往较低。因此关于SSE方案的安全性的研究应该专注于构建更安全的SSE方案,旨在实现最小化的信息泄漏的同时实现高效的搜索。
(3)近年来,同态加密和安全多方计算发展迅速,且二者都在隐私保护方面展现出强大的潜力。因此一个备受关注的未来研究方向是如何巧妙地结合同态加密[71]、量子密钥协商[72]或安全多方计算,以设计一种既安全又高效的可搜索加密方案。该方向的研究旨在充分发挥同态加密的数据加密能力和安全多方计算的隐私保护机制,从而为构建更加强大、全面的可搜索加密技术提供创新的解决思路。
猜你喜欢
电子与信息学报(2023年9期)2023-10-17
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
阅读与作文(小学高年级版)(2019年2期)2019-03-27
信息通信技术(2018年6期)2019-01-18
衡阳师范学院学报(2016年3期)2016-07-10
信息安全研究(2016年11期)2016-02-10
深圳大学学报(理工版)(2015年5期)2015-02-28
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
作文与考试·高中版(2008年12期)2008-07-01
