
基于多目标异权重回归的冷水机组故障诊断显式模型
2024-02-05 01:24吴孔瑞杨钰婷陆海龙凌敏彬
制冷学报 2024年1期
吴孔瑞 韩 华 杨钰婷 陆海龙,2 凌敏彬
(1 上海理工大学能源与动力工程学院 上海 200093;2 重庆美的通用制冷设备有限公司 重庆 401336)
制冷系统发生故障会对其安全性及经济性造成影响。建筑中空调和供暖系统的能耗约占总建筑能耗的50%[1]。冷水机组是建筑空调的核心部件,结构复杂并且长时间运行导致其故障发生的概率也随之增大[2]。冷水机组发生故障不仅会造成能源浪费,降低室内环境舒适度[3],严重时还会危及楼宇安全。传统的故障检测方法费时费力,因此采用人工智能技术使之能够及时精准地发现冷水机组的故障,再由专业人员进行维修,对节约能源及提升用户舒适度均具有重要意义。
相比于1987年J. S. Haber等[4]初次将故障诊断技术应用于制冷系统,近些年来,数据的丰富、算力的提升促进了人工智能在故障诊断领域的应用。张立国等[5]结合模糊熵与GG聚类算法用于滚动轴承故障诊断;焦卫东等[6]改进支持向量机算法用于齿轮箱故障诊断;王群飞等[7]基于随机森林算法对V2G充电桩故障诊断研究。在冷水机组的故障诊断领域,梁晴晴等[8]基于BP神经网络,采用贝叶斯归一化将整体的诊断正确率提升了30%以上;王占伟等[9]将距离拒绝机制融入贝叶斯网络中,构建冷水机组故障诊断模型;董英杰等[10]采用混合神经网络模型保留数据之间的长期依赖关系特征构建了模型,并基于Spring Boot开源框架建立了冷水机组设备健康管理系统;张展等[11]集成多种基础分类器,采用投票法确定最终的诊断结果,集成模型的性能较基础分类器均有显著提升。
但无论是传统的机器学习,还是深度学习,都面临着训练完成的模型难以可视化的问题。显式模型可以观察到模型的内部结构,容易得到模型内部各特征参数对各故障类别的权重,便于更好地理解故障,且无需迭代,对计算性能要求低,易于部署到制冷设备中。本文基于交叉熵损失函数和随机梯度下降算法,建立离心式冷水机组的故障诊断显式模型,可视化各故障的参数权重,得到各故障诊断的重要参数。
1 基本原理
1.1 多目标异权重回归的故障诊断模型
传统的线性回归模型,将故障类别以一个回归目标中的不同大小来编码,导致模型中的单个特征对所有故障的权重(W)相同,但实际上,每个特征对每个故障的影响程度不同,因此该模型存在一定的局限性。本文提出多目标异权重回归(图1),对故障类别进行独热编码,使回归目标与涉及的故障类别一一对应,确保每个特征对不同的故障均有单独的权重(W1、W2、W3…Wn),便于观察不同故障与特征参数之间差异化的关联特性,进而分析故障及故障诊断原理。模型最终输出目标值最大的类别,作为故障诊断结果。

图1 两种方案的原理对比
模型流程如图2所示,数据处理部分将训练数据与测试数据进行归一化,消除参数量纲对模型中参数权重的影响。在模型训练部分,首先初始化权重得到初始的显式模型,归一化之后的训练数据进入显式模型,计算得到各目标类别的预测值,输出预测值最大类别作为诊断结果。采用交叉熵(cross entropy, CE)损失函数计算诊断类别与真实类别之间的差异,在模型没有达到设定迭代次数之前,采用随机梯度下降算法(stochastic gradient descent, SGD)沿着损失函数的负梯度方向优化显式模型中各目标类别的权重,使模型的诊断结果尽可能的拟合训练数据的真实类别。训练完成可得到每个特征对各故障类别最佳权重的显式模型,在模型验证部分通过测试数据对模型的性能进行评估分析。
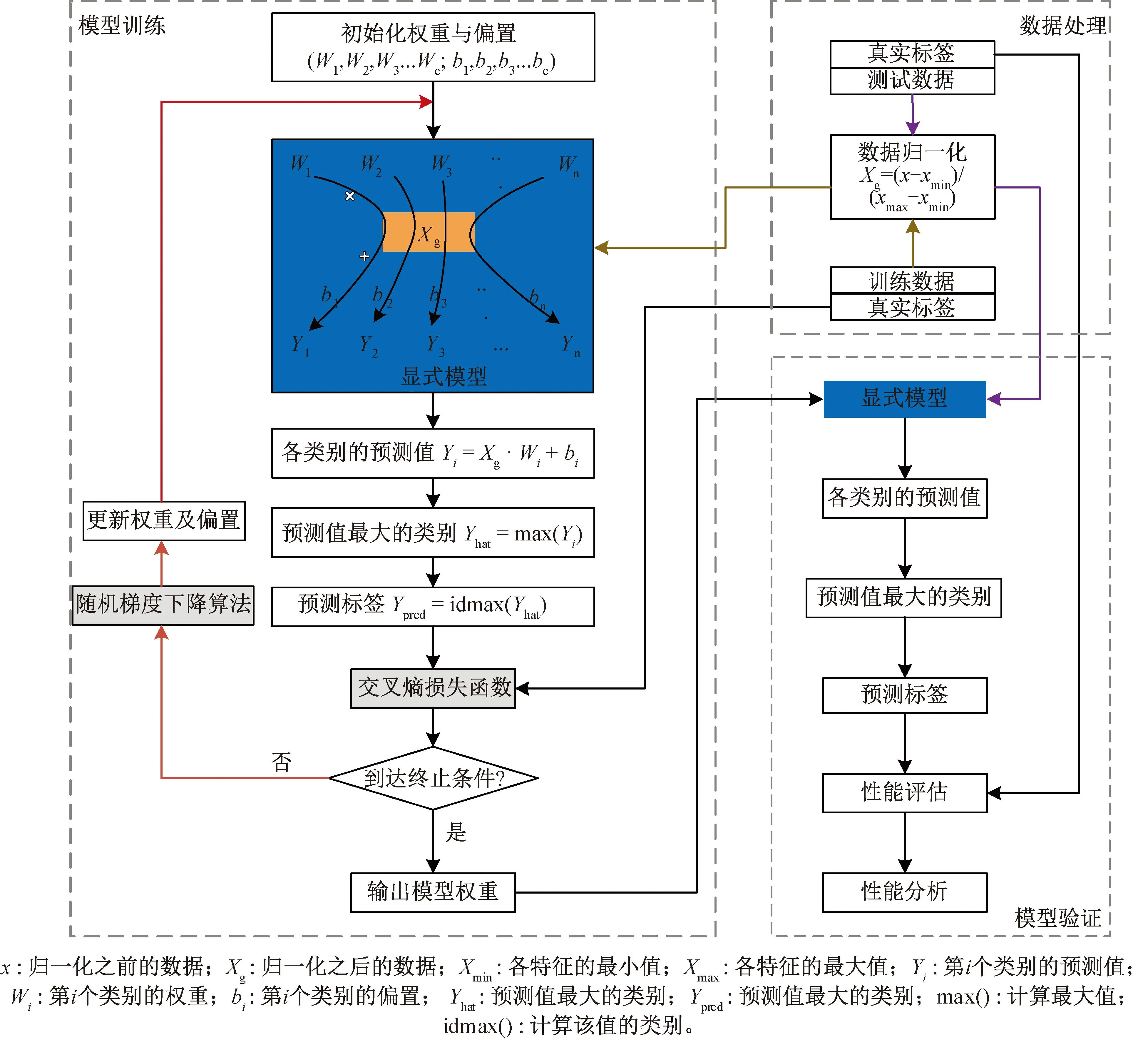
图2 模型流程图
1.2 交叉熵与随机梯度下降算法
交叉熵由S. Kullback等[12]于1951年首次提出,用来度量两个概率分布之间的差异性。对二分类问题,模型最后的输出只有两种情况,故此时的交叉熵损失函数为:
(1-yi)log(1-pi)]
(1)
式中:L为损失值;N为样本总数;yi为第i个样本的标签,正类为1,负类为0;pi为第i个样本诊断为正类的概率。
多分类问题是对二分类问题的扩展,计算式为:
(2)
式中:M为类别总数;yic为第i个样本是否为类别c,若是,则为1,否则为0;pic为第i个样本诊断为类别c的概率。
模型中的权重直接影响损失值的大小,若需获得损失函数的最小值,则需要沿着梯度的反方向进行权重的更新。对于优化问题minL(w),梯度下降算法的迭代公式为:
(3)

随机梯度下降算法(SGD)借鉴粒子群的随机游动思想,在算法陷入局部最优值时,给予算法一个适度的干扰,希望可以跳出当前的局部最优解以寻找一个更好的极值点。将高斯噪声作为该扰动[13]添加至迭代公式中,得到新的迭代公式:
(4)
式中:β为添加的扰动的强度;N(0,σ2)表示服从0,σ2的高斯分布的随机数,其它参数同式(3)。
2 研究对象
2.1 实验数据
本实验数据来自ASHRAE 1043-RP[14]项目,该项目以一台制冷量约为317 kW的离心式冷水机组作为研究对象,充注制冷剂为R134a。该项目主要对制冷系统中常见的3种系统性故障(制冷剂泄漏/充注量不足、制冷剂过充和润滑油过量)和4种局部故障(蒸发器侧水流量不足、冷凝器结垢、冷凝器侧水流量不足和制冷剂含不凝性气体)及正常运行情况进行模拟,获得实验数据。其中正常和每种故障均在27种不同的工况下模拟运行,工况的详细信息如表1所示。
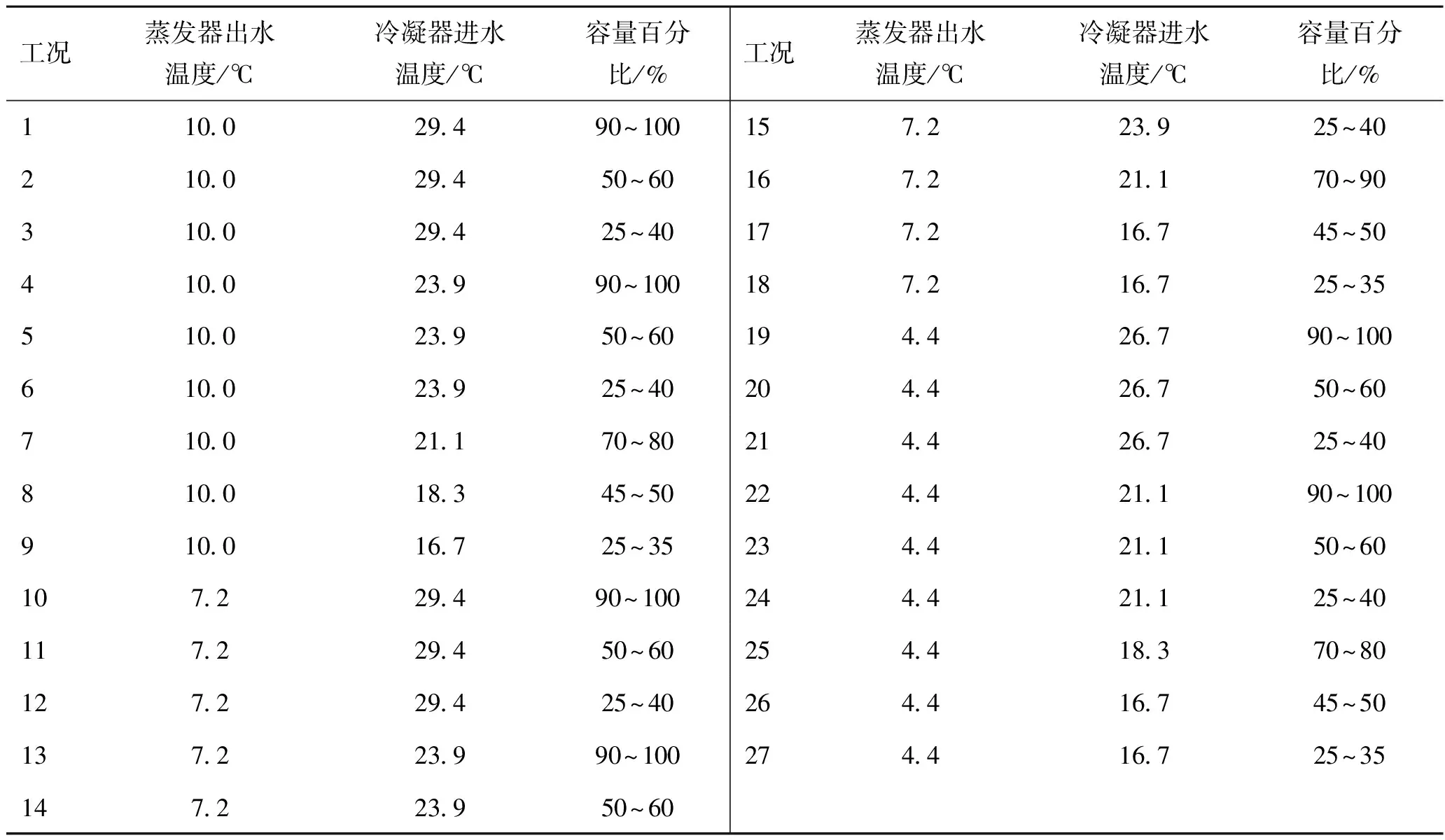
表1 27个工况参数设置
本文从经过稳态筛选[15]的数据中随机选择了12 000条数据,随机选取8 000条作为训练数据,用于模型训练,另外4 000条作为测试数据,用于训练完成后对故障诊断模型性能进行评估,保证模型具有一定的泛化能力。表2为正常状态与7种典型故障的英文缩写。
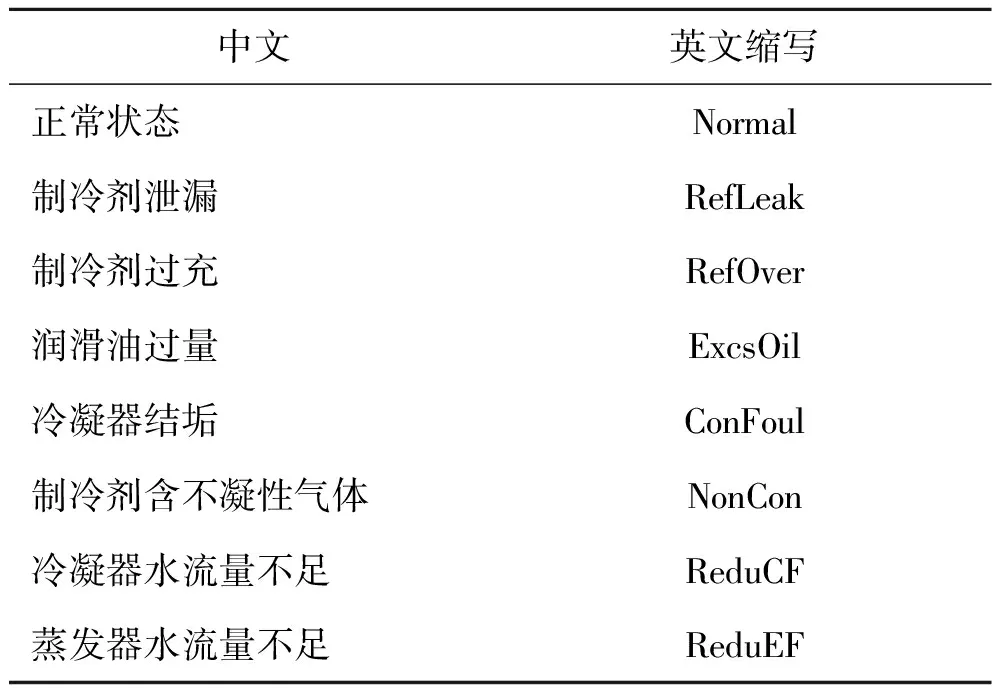
表2 制冷系统正常运行及7类典型故障
2.2 模型评价指标
为评价所构建的机器学习中分类模型的效果,常有准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1-Score等评价指标来衡量分类模型的好坏。
1)准确率(Accuracy,A):表示所有诊断样本中被诊断正确的样本所占比例。计算式为:
(5)
式中:TP为样本真实为正类且被诊断为正类;FP为样本真实为负却被诊断为正类;FN为样本真实为正类却被诊断为负类;TN为样本真实为负类且被诊断为负类。
2)精确率(Precision,P):表示所有被诊断为正类样本中实际为正类的样本的比例,(1-精确率)为虚警率。计算式为:
(6)
3)召回率(Recall,R):表示被正确判定的正类样本数占总的正类样本数的比例,(1-召回率)为漏报率。计算式为:
(7)
4)F1-Score:为精确率和召回率的调和平均,更接近于精确率与召回率中较小值,能够有效平衡精确率和召回率的影响,可以较为全面地评价分类模型的性能。计算式为:
(8)
(9)
3 实验分析
3.1 性能对比分析
ASHRAE的数据中由传感器直接测得的有48个参数,在实际使用中,安装如此多的传感器是不现实的。因此许多文献均针对ASHRAE RP-1043项目冷水机组7种典型故障,提出了相应的诊断用特征集,如Gao Y. 等[16]采用基于随机森林的全局敏感性分析,并结合相关性分析进行特征清洗与增补得到9个特征,记为Gao_9;Han H. 等[17]基于互信息、遗传算法与支持向量机(SVM)结合得到8个特征,记为Han_8;Zhao Yang等[18]从独立性、冗余性和特征数量三方面综合考虑得到16个特征,记为Zhao_16;Zhou Qiang等[19]根据故障与正常运行性能差异建立的定性规则表进行筛选,得到8个特征,记为Zhou_8;范雨强等[20]从现场传感器出发,适当增补得到10个特征,记为Fan_10,各特征集中至少有两个特征集合的共有特征列于表3中,“√”号表示该特征集合具有该特征参数;每个特征集合的特征参数列于表4中。
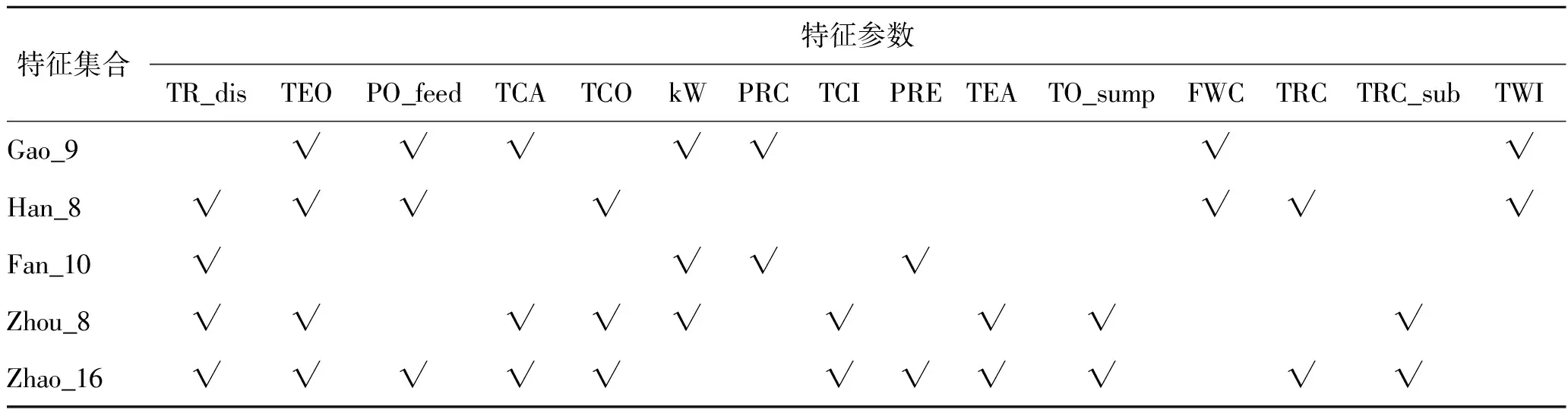
表3 各特征集合中的共有特征参数

表4 各特征集合的特有参数
本文提出的模型是在线性模型基础上的改进,因此选择了与原始的线性回归模型进行对比分析。图3所示为几组特征集合在本文提出的模型上的性能表现。对比同一特征集合在两种模型下的性能,可知本文提出的权重回归模型比线性模型的性能大幅提升,各特征集合分别提高了64.10%、61.55%、40.5%、59.48%和44.58%。对比各特征集合在权重回归模型下的性能,特征集合Gao_9可以达到88.65%的准确率,比性能最差的特征集合Fan_10的准确率高28.82%。
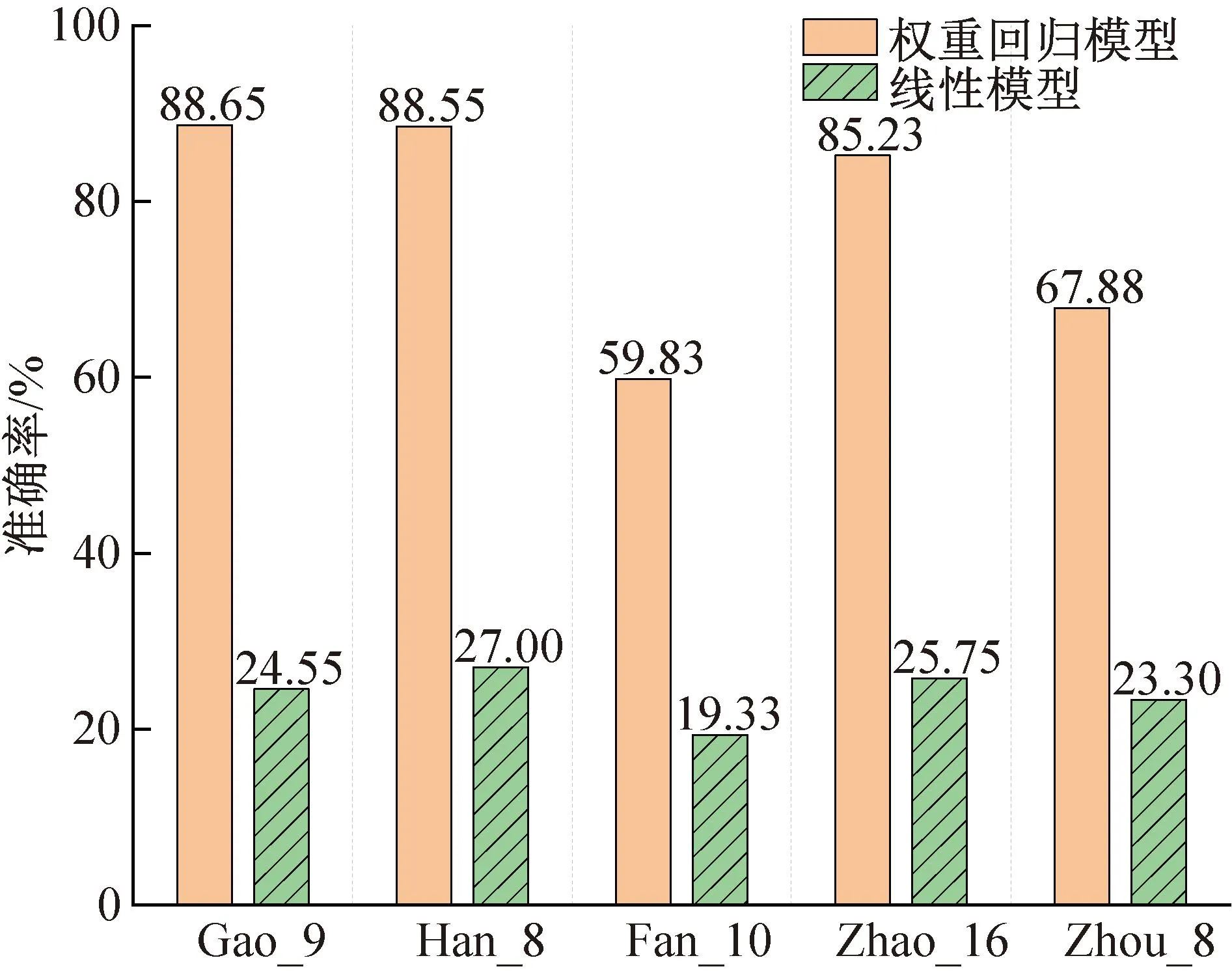
图3 不同特征集下权重回归模型与线性模型性能对比
表5为特征集合Gao_9在权重回归模型的方法下的各性能指标。冷凝器结垢、冷凝器水流量不足、制冷剂含不凝性气体和蒸发器水流量不足4种局部故障的各评价指标均可以到达95%以上。制冷剂泄漏、制冷剂过充及润滑油过量属于系统性故障,较难检测,故诊断性能不佳。对正常状态识别的召回率不足50%,说明大量正常的样本被误报为故障,导致正常状态识别的F1值较低。

表5 Gao_9特征集下模型的性能
为进一步分析该模型对样本的误报类别,表6为Gao_9特征集训练得到模型的混淆矩阵。正常状态虚警为制冷剂泄漏故障(RefLeak)的样本量有150个,润滑油过量故障(ExcsOil)被误报为制冷剂泄漏故障的样本量有84个。此外3种系统性故障与正常状态之间的识别均存在混淆,以正常与制冷剂泄漏故障之间最为突出,因为在制冷剂轻度泄漏时,由于冷水机组的自我调节能力,使各参数值与正常状态时相差较小,难以分辨。
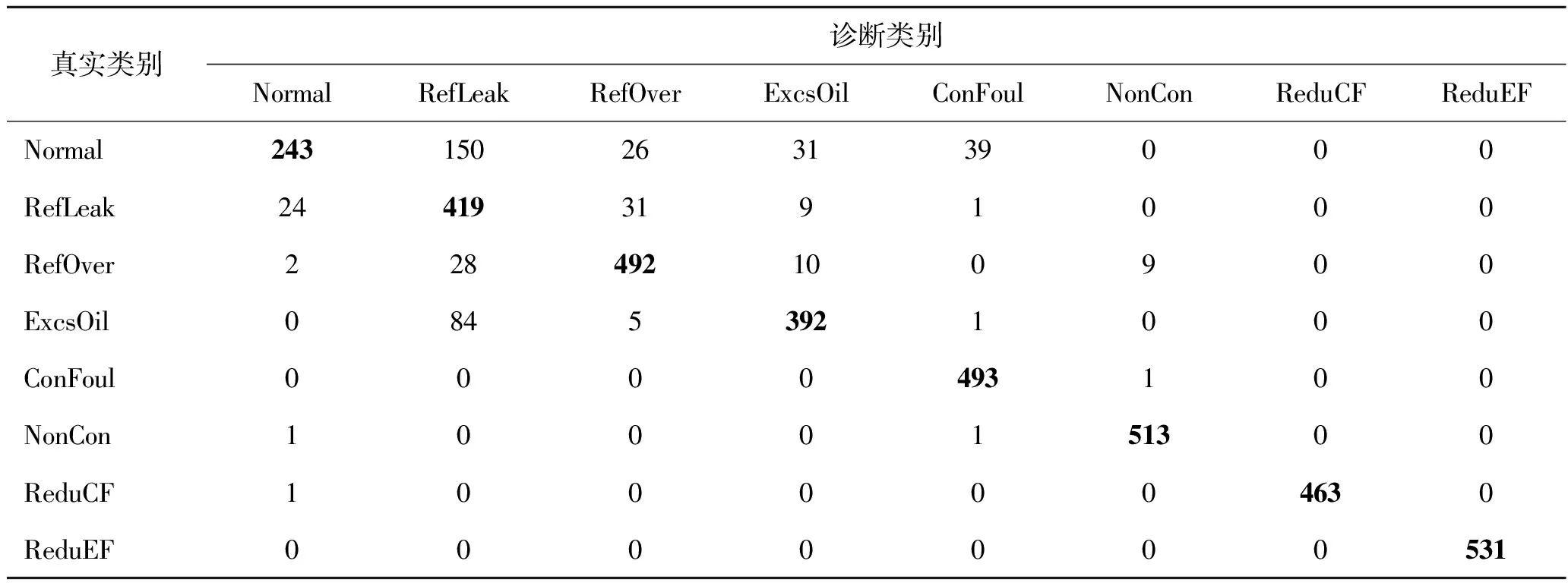
表6 Gao_9特征集下的混淆矩阵
3.2 新特征集的选取及性能分析
在关于制冷剂充注量的故障中,I. N. Grace等[21]指出,冷凝器下游液体管路制冷剂过冷度(TRC_sub)是很好的表征参数。且考虑到Gao_9特征集合中的特征TWI(自来水供水温度)属于模拟故障实验时存在,但在实际制冷系统中并不存在的参数,因此将Gao_9特征集中的参数TWI替换为TRC_sub,得到新的特征集,记作Selected_9。
表7为特征集合Selected_9在权重回归模型的方法下的各性能指标,新的特征集在故障诊断中可获得89.83%的准确率,对比表5与表7,特征替换之后,模型的准确率提升了1.18%,表明采用TRC_sub较TWI性能更佳。通过采用故障新特征集,模型对制冷剂泄漏故障的诊断性能略有下降,但对制冷剂过充与润滑油过量故障的诊断性能均有提高,特别是制冷剂过充故障,F1-Score提升了4.31%。
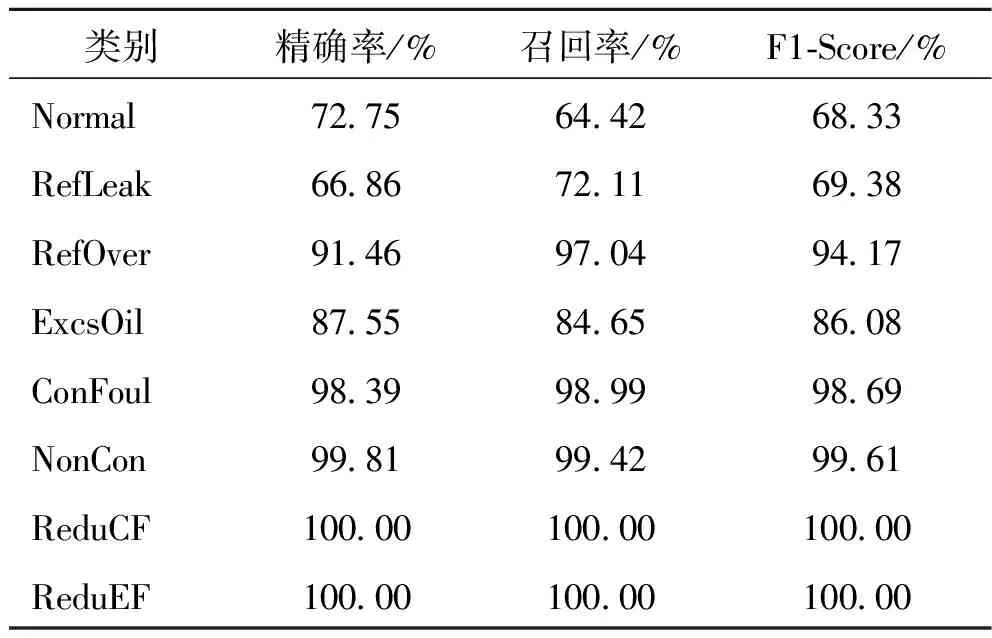
表7 Selected_9特征集下模型的性能
表8为特征集合Selected_9在权重回归模型下的混淆矩阵。该混淆矩阵与表6(Gao_9特征集下的混淆矩阵)相比,虽然制冷剂泄漏故障被漏报的样本量有所增加,但其它各类故障之间被混淆诊断的样本量有所减少,总体看来,模型的性能有所提升。由表8可知,被诊断混淆的样本主要集中在表格的左上角,即正常状态与3种系统性故障识别的相互混淆依然是限制模型性能的主要影响因素。
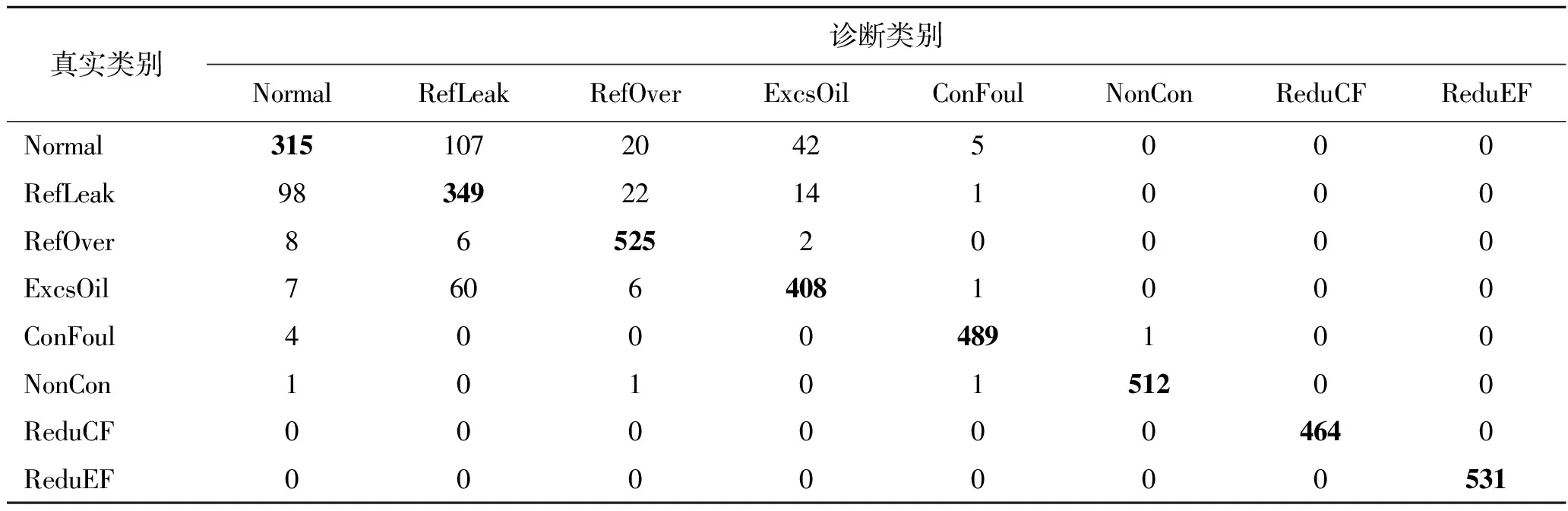
表8 Selected_9特征集下的混淆矩阵
3.3 显式模型
选择出最好的特征集之后,将在Selected_9特征集合下训练的显式模型展示。表9为模型得到的权重矩阵(W)及偏置矩阵(B)。其中权重矩阵的维度为8×9,表示8个类别与9个参数对应的权重;偏置矩阵的维度为8×1,与每个类别对应。表10所示为随机选取的10条样本及其真实对应的类别标签,表11所示为9个特征参数的范围值,用来计算实际数据归一化之后的值。
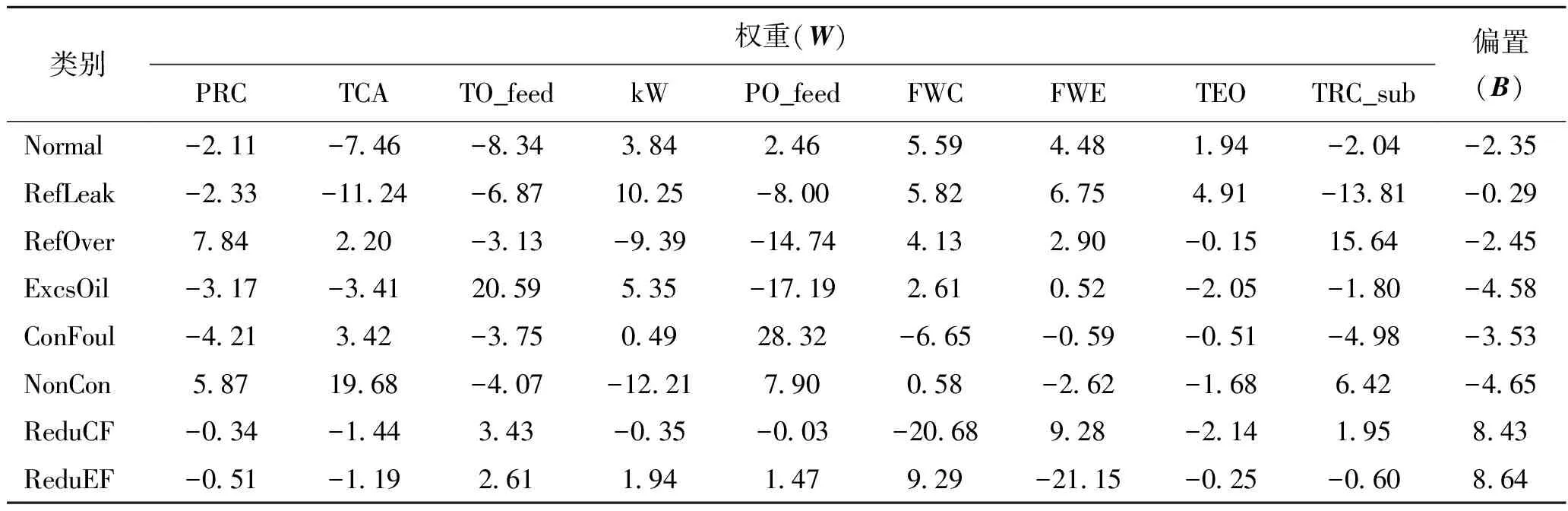
表9 权重矩阵及偏置矩阵
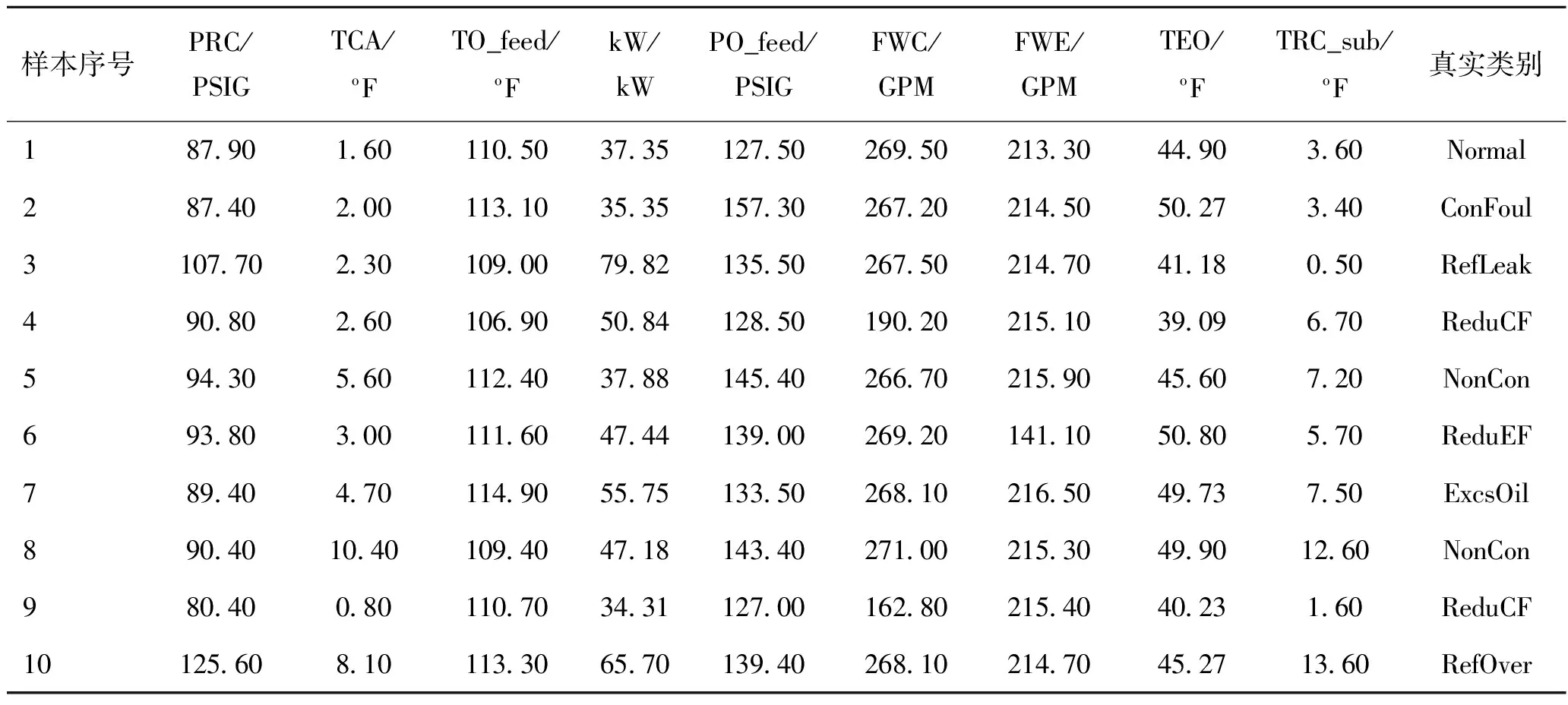
表10 10条测试数据(x)及真实类别

表11 各特征值的范围
表12所示为上述的权重矩阵与测试数据计算后得到的结果。例如,第一行第一个数据2.40表示序号为1的测试数据判定为正常的计算值,计算方法为:表10中序号为1的数据中每个参数(x)先根据表11中的参数值范围计算得到归一化之后的值,乘以表9中正常(Normal)的各参数权重(W),然后再加上正常(Normal)的偏置值(B),如式(10)所示。每一条数据均需计算判定为各状态的计算值,最后各状态的计算值中的最大值(采用红色加粗标注)所对应的列为诊断的类别;最后一列表示该条样本的真实类别;第1条样本(添加灰色背景)诊断结果与真实类别不一致,实际为正常的一条样本虚警为制冷剂泄漏故障。
(10)
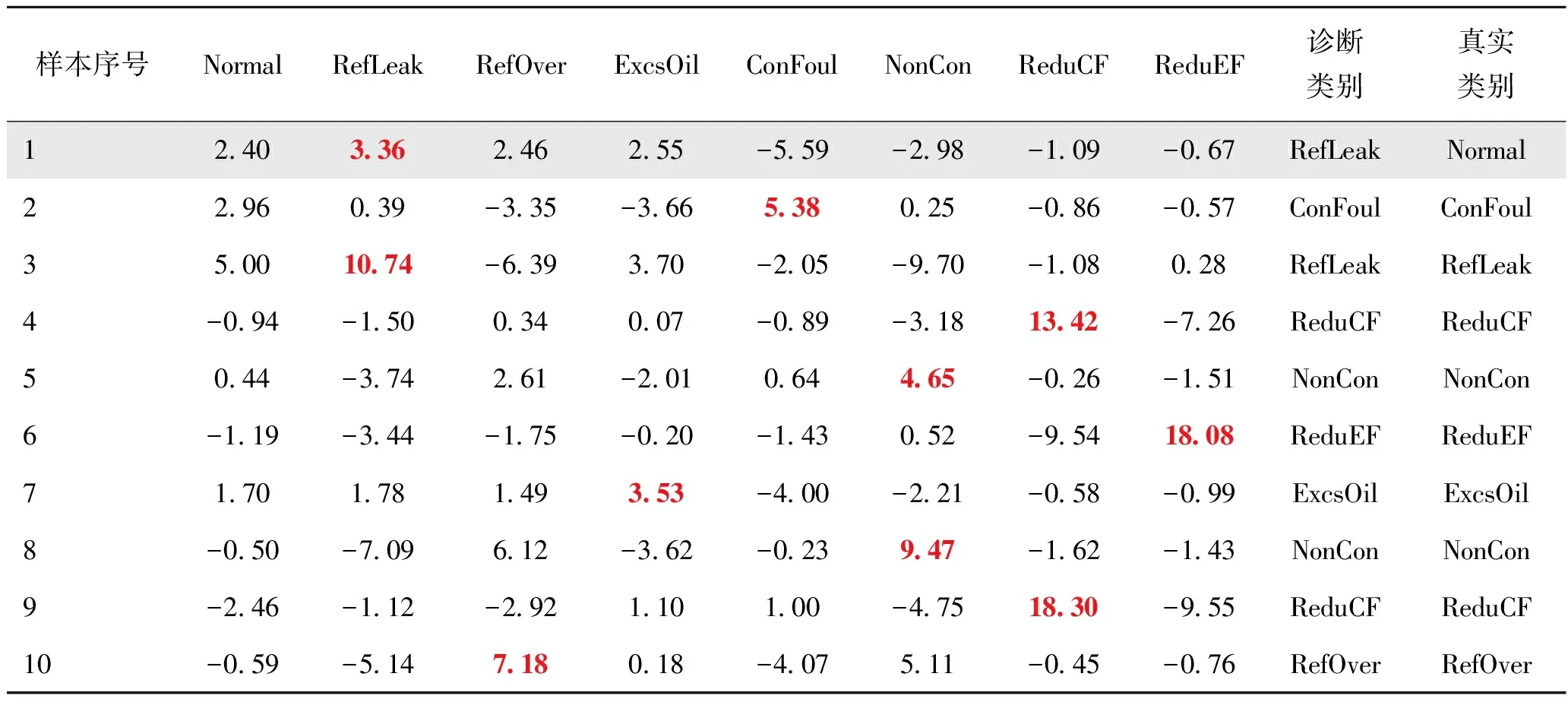
表12 计算诊断结果与真实类别的对比
3.4 故障权重分析
图4所示为制冷剂泄漏、制冷剂过充和润滑油过量3种系统性故障下,各参数的权重分布(图4(a))及权重绝对值占比(图4(b),图中未标出占比小于3%的数值)。某故障下,参数权重的绝对值越大,说明该参数对该故障的判定越重要:若权重为正,则该参数值越大,判定为该故障的概率越大(正相关);若权重为负,则该参数值越小,判定为该故障的概率越大(负相关)。例如,制冷剂泄漏故障与制冷剂过充故障中,权重占比最大的参数均为过冷度(TRC_sub),符合参考文献[21]中指出的过冷度是制冷剂充注量的很好表征参数的结论。对比制冷剂泄漏故障下各参数的权重分布(图4(a)中红色线),过冷度的负权重最大,说明系统的过冷度值越小,判定为制冷剂泄漏故障的可能性越大;相反,对制冷剂过充故障(绿色线),该参数具有较大正权重,说明系统过冷度值越大,判定为制冷剂过充故障的可能性越大。对润滑油过量故障,TO_feed(供油温度)具有最大的正权重,而PO_feed(供油压力)具有较大的负权重,二者权重占比高达66%,表明润滑油参数与润滑油过量故障紧密相关。
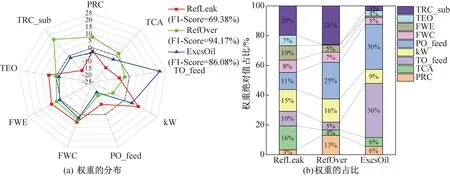
图4 3种系统性故障的各特征的权重分布及权重绝对值的占比
图5所示为冷凝器结垢、蒸发器水流量不足、冷凝器水流量不足以及制冷剂含不凝性气体4种局部故障下,各参数的权重分布(图5(a))及权重的绝对值占比(图5(b),图中未标出占比小于3%的数值)。由图5可知,每个系统性故障都对应有一个参数的权重明显大于其它故障的权重,说明局部故障的诊断不易混淆,进而确保局部故障的诊断性能好。冷凝器趋近温度(TCA)对制冷剂含不凝性气体故障的判定最为敏感,制冷剂中的不凝性气体主要存在于冷凝器中,导致冷凝器的传热效率低,故冷凝器温度与冷凝器趋近温度(TCA)会增大;供油压力(PO_feed)对冷凝器结垢故障的判定具有最大的正权重,可能与冷凝器结垢故障实验前进行了一次油压调整(提升)[14]有关,导致供油压力对冷凝器结垢故障的判定敏感;冷凝器水流量(FWC)对冷凝器水流量不足故障的权重绝对值占比最大,且权重值为负,说明冷凝器的水流量值越小,则越可能是冷凝器水流量不足故障;蒸发器水流量参数(FWE)对蒸发器水流量不足故障的影响类似。
4 结论
本文结合交叉熵损失函数与随机梯度下降算法,对离心式冷水机组建立了显式的故障诊断模型,对正常运行及7种典型故障进行识别诊断。对比了多目标异权重回归模型与传统线性回归模型的性能差异,分析了不同特征子集上的诊断性能,并对模型中得到的各参数权重进行了可视化分析。得到结论如下:
1)多目标异权重回归模型较传统线性回归模型略显复杂,但故障诊断性能明显优于后者:在多个公开文献所提特征集合中,性能提升达40.50%~ 64.10%;在本文所提包含9个参数的Selected_9特征集合中,总体诊断准确率最高,可达89.83%,性能提升65.11%。局部故障诊断准确率超过98%;制冷剂泄漏、制冷剂过充及润滑油过量属于系统性故障,影响范围大,较难检测与诊断,因此性能不及局部故障。该模型对正常状态检测精确率为72.75%,召回率64.42%。
2)通过展示Selected_9特征集合下,冷水机组故障诊断的多目标异权重显式模型,并可视化模型中的参数权重,发现:过冷度和供油温度参数,对诊断制冷剂泄漏、制冷剂过充和润滑油过量3种系统性故障最为重要;供油压力、冷凝器趋近温度、蒸发器与冷凝器的水流量参数,对诊断冷凝器结垢、制冷剂含不凝性气体、蒸发器水流量不足、冷凝器水流量不足4种局部故障最为重要。
显式模型避免了反复的在线优化计算,通过简单的线性运算得到模型结果,在实际应用中,对设备计算性能要求低,可以更好地嵌入现有的制冷设备中,而且通过对模型中各特征参数的权重分析,有助于更好地理解故障及故障诊断原理。
猜你喜欢
江苏安全生产(2023年10期)2023-12-18
绿色建筑(2021年4期)2022-01-20
中国特种设备安全(2021年12期)2021-04-26
制冷技术(2016年2期)2016-12-01
现代工业经济和信息化(2016年12期)2016-05-17
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
制冷学报(2014年1期)2014-03-01
化工生产与技术(2014年2期)2014-02-27
