
A Novel Multi-Stream Fusion Network for Underwater Image Enhancement
2024-03-11 06:28GuijinTangLianDuanHaitaoZhaoFengLiu
China Communications 2024年2期
Guijin Tang ,Lian Duan ,Haitao Zhao ,Feng Liu
1 Jiangsu Key Laboratory of Image Processing and Image Communication,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
2 Jiangsu Key Laboratory of Wireless Communications,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
Abstract: Due to the selective absorption of light and the existence of a large number of floating media in sea water,underwater images often suffer from color casts and detail blurs.It is therefore necessary to perform color correction and detail restoration.However,the existing enhancement algorithms cannot achieve the desired results.In order to solve the above problems,this paper proposes a multi-stream feature fusion network.First,an underwater image is preprocessed to obtain potential information from the illumination stream,color stream and structure stream by histogram equalization with contrast limitation,gamma correction and white balance,respectively.Next,these three streams and the original raw stream are sent to the residual blocks to extract the features.The features will be subsequently fused.It can enhance feature representation in underwater images.In the meantime,a composite loss function including three terms is used to ensure the quality of the enhanced image from the three aspects of color balance,structure preservation and image smoothness.Therefore,the enhanced image is more in line with human visual perception.Finally,the effectiveness of the proposed method is verified by comparison experiments with many stateof-the-art underwater image enhancement algorithms.Experimental results show that the proposed method provides superior results over them in terms of MSE,PSNR,SSIM,UIQM and UCIQE,and the enhanced images are more similar to their ground truth images.
Keywords: image enhancement;multi-stream fusion;underwater image
I.INTRODUCTION
Image enhancement is an important research topic in the field of image processing.Due to different imaging environments,the captured images usually suffer from different types of damage.For underwater images,they usually have various distortions including color imbalance and heavy blur.Many underwater tasks such as ecological research and object detection rely on high-quality underwater images.The enhancement of underwater images is very important for these applications.
The existing enhancement techniques for underwater images can be roughly divided into two categories:those relying on hardware platforms and those based on software algorithms.The methods based on hardware platforms[1-3]usually have better enhancement effects,but the design and manufacturing costs of such methods are too high to be widely applied.In contrast,the enhancement of software algorithms is highly valued in the field of computer vision.Furthermore,the existing software algorithms can be divided into two types: image enhancement algorithms without physical models [4,5] and image enhancement algorithms based on physical models[6,7].With the wide application of deep learning technology,the research that combines deep learning with low-level computer vision tasks has attracted great attention in recent years[8-11].
This paper follows the idea of deep learning,and proposes an underwater image enhancement network based on residual frameworks.The main contributions of this paper can be summarized as follows:
• A novel network for underwater image enhancement is presented.The network can uncover hidden valuable information in original images.This ensures that more features are retained.Experimental results show the enhanced images are more similar to their ground truth images.
• A strategy of multi-stream fusion processed by residual blocks is proposed.We derive the illumination stream,color stream,and structure stream from the input images.Every stream is regarded as an input path.The original images and the corresponding information from the three streams,acting as four paths,are then jointly input into the network.The streams of four paths are sent to their respective residual blocks for processing.The processed results,which are the extracted features,are fused afterwards.Its benefit is that the model can extract some latent image information.
• A new composite loss function is proposed to jointly constrain the training process of the model for the three aspects of color,structure and smoothness,so that the enhanced results of the model are more in line with human visual perception.We develop the metric functions of color loss,structure loss and smoothness loss,respectively,and then combine them in a weighted form.
II.RELATED WORK
The underwater image enhancement method based on the non-physical model starts from the pixel distribution of the underwater image,and achieves the purpose of enhancing the image by adjusting the distribution of the image.Some of the earliest algorithms introduced the classical histogram equalization method into the enhancement process for underwater images,but it was found to be difficult to achieve desired results for underwater images with serious contrast imbalance,so Pisano et al.[12] proposed a histogram equalization algorithm with contrast constraints.However,it made the image gray level distribution more sparse,resulting in the loss of image detail information.Further,Liu et al.[13] derived an automatic white balance algorithm,which determined the parameters in the algorithm through fuzzy logic rules,in order to minimize the effect of different light sources.It often failed when the image scene color was not rich.Ancuti et al.[14] proposed an enhancement method based on image fusion for the characteristics of underwater images,and obtained the final enhancement result through the combined action of two input channels and four weight maps of color correction and contrast enhancement.It mitigated the noise amplification problem caused by a single weight.Drews et al.[15]proposed a dark channel prior(DCP)-based underwater image enhancement method with the help of the blue and green channels of underwater images.Iqbal et al.[16]proposed an unsupervised underwater image based on color matching.
There is extensive research on physical imaging models of underwater images.Jaffe [17] and McGlamery [18] both proposed a physical model of the degradation process of underwater images.Based on this model,Drews et al.[19]proposed an enhancement method with the dark channel prior.Galdran et al.[20]made further improvements to this model,considered that the pixel values of the red channel rapidly decay when the distance increased,and proposed a method with the red channel prior.On the other hand,Wang et al.[21] used the method of maximum attenuation identification to correct the color of underwater images.They established an adaptive attenuation curve prior model according to the attenuation law of the underwater environment,and used this to estimate the intensity in each channel.The attenuation ratio and transmittance were adjusted accordingly,and the three channels of an image were adjusted accordingly to realize the enhancement of the underwater image.The images enhanced by this algorithm tended to be oversaturated.
The above classic algorithms are clear in theory and easy to implement,but the enhancement effect is not satisfactory.With the development of deep learning,more and more underwater image enhancement methods attempt to use this technology.WaterGAN [22]was an end-to-end convolutional neural network for enhancing underwater images.However,it did not take into account complex practical issues such as uneven illumination and water turbidity.Sun et al.[23]proposed a symmetric encoder-decoder network to refine the enhanced images pixel by pixel.Liu et al.[24]introduced an additional super-resolution reconstruction model during the enhancement process to improve the clarity of the enhanced image.Uplavikar et al.[25]used the architecture of U-Net[26],and exploited domain adversarial learning to enhance and classify underwater images.This algorithm solved the problem of different types of water on enhancement results,but it was highly dependent on training sets.Li et al.[27]used a recurrent generative adversarial network to artificially generate underwater images and guide the model training,and then they used a large number of real underwater images captured by professional equipment to perform the training to obtain the most accurate augmentation effect.However,it tended to produce strange textures.
III.PROPOSED METHOD
When imaging in an underwater environment,because the water has different absorption effects on light of different wavelengths,the distribution of each channel of a captured image is usually seriously unbalanced.For an image in RGB format,the information of the red channel is almost completely lost,resulting in a bluish or greenish tone,as shown in Figure 1.
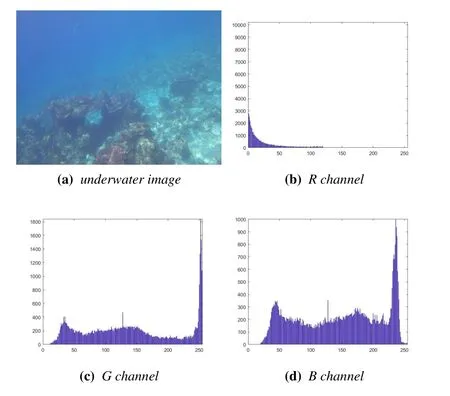
Figure 1.Distribution histogram of each channel.
On the other hand,due to the complex composition of the underwater ambient light propagation medium,the light used for imaging contains multiple components that have been attenuated to different degrees,which further causes a series of more complex distortion phenomena such as blurring and vignetting.
In this paper,we propose an underwater image enhancement network based on multi-stream feature fusion.First,three techniques are used to preprocess an input underwater image,and then the preprocessed results are sent to the residual blocks to extract the features.Next,the extracted features are fused.Moreover,a loss function composed of three terms is designed for the underwater image enhancement task to produce the proper weights for the network,which can ensure the quality of enhanced images.
3.1 Network Structure
The overall structure of the proposed network is shown in Figure 2.

Figure 2.The structure of the proposed network.
First of all,compared with degraded images which are captured in other scenarios,the red channel of underwater images carries less information.Inspired by[28,29],the model in this paper also exploits three feature extraction strategies to repair the loss of information in underwater images.The three enhanced features are called the illumination stream,color stream and structure stream,respectively.Three streams are acquired by the histogram equalization with contrast limitation acquired by the CLAHE algorithm[30],the gamma correction (GC) withγ=0.7 and the white balance (WB) technique acquired by the gray world(GW) algorithm [13],because these three techniques have been proven to be effective in the literature[28].After the above preprocessing,each underwater image is accompanied by three preliminary prediction images.Figure 3 shows an underwater image and its corresponding three preliminary prediction images.

Figure 3.The preliminary prediction images.
Next,the three preliminary prediction images and the original raw image are used as four input paths for the proposed network for training.The proposed network follows the design idea of the feature extraction and fusion of U-Net[26].The overall network is divided into two parts: the first part is the feature decomposition and extraction,and the second one is the feature combination and mapping.For the input four-path image,the feature of each path of an input image is firstly decomposed and extracted layer by layer through the alternate pooling operations of cascaded residual blocks.The second part of the network fuses the extracted four-path features,uses the cascaded residual blocks and the up-sampling layers to enhance the image features,and restores the image to the original size.In this part,the input of each residual block includes not only the output of the previous network,but also the feature information fusion of the corresponding layers of each channel.The network can therefore use more feature information to complete the enhanced prediction.Finally,the 1×1 convolutional layer replaces the fully connected layer to achieve the dimensionality reduction to get the final enhanced result.The specific structure of the cascaded residual block used in the proposed network is shown in Figure 4.
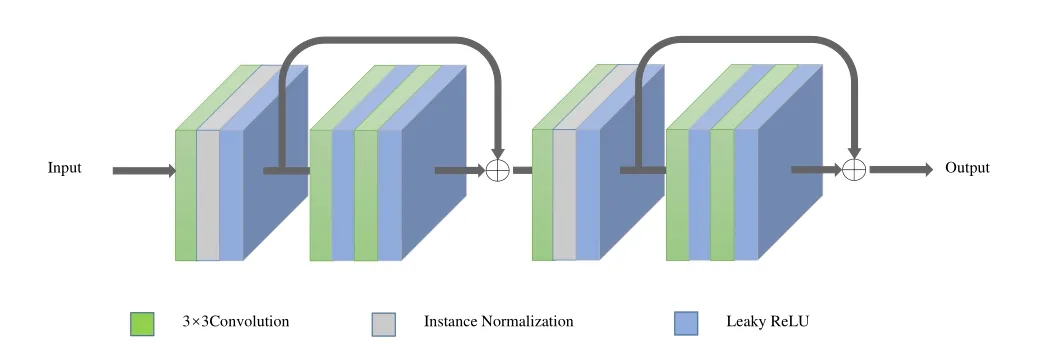
Figure 4.The structure of the residual block.
Each residual block contains two skip connections.The size of the convolution kernel in the convolutional layer is 3×3.An image,which is the input of the residual block,is firstly processed through a convolutional layer to unify the input data,then the instance normalization operation is performed to normalize the data.Next,it is processed by a residual structure composed of two convolutional layers.The operation is repeated twice in each residual block to ensure that the network has sufficient fitting power.For the activation function,all convolutional layers in this structure use Leaky ReLU that can retain a certain amount of negative gradient information.
Each residual block in the proposed network has the same structure as that shown in Figure 4,but the data dimensions of the residual blocks at different depths are different.For the first part of the network,that is,the part of feature decomposition and extraction,the input data dimension of the first residual block of each channel is 3,the dimension of the convolutional layer is 64,and the output data dimension is 128.The input data dimension of the second residual block is 128,the dimension of the convolutional layer is 128,and the output data dimension is 256.The input data dimension of the third residual block is 256,the dimension of the convolutional layer is 256,and the output data dimension is 512.For the second part of the network,that is,the part of the feature combination and mapping,the input data dimension of the first residual block is 2048,the channel number of the convolutional layer is 512,and the output data dimension is 512.The input data dimension of the second residual block is 1536,the channel number of the convolutional layer is 256,and the output data dimension is 256.The input data dimension of the last residual block is 768,the channel number of the convolutional layer is 128,and the output data dimension is 128.
The entire network of the proposed algorithm contains 15 residual blocks.It has 91 convolutional layers.The step size of all convolutional layers is 1,and the coefficientkof the LeakyReLU function is 0.1.
3.2 Loss Function
By analyzing the requirements of underwater image enhancement tasks,this paper designs a new composite loss function,which evaluates the enhancement effect from three aspects: color loss,structure loss and smoothness loss.We use a weighting strategy like[31].The loss function can be expressed as:
whereLc,LsandLtvrepresent the color loss,structure loss,and smoothness loss,respectively,andwc,ws,andwtvare the corresponding weights of the three losses.The specific definitions of each loss are as follows:
(1)color loss
The color loss of channels is a loss term used to measure the difference in color performance between the enhanced image and the reference image,that is,the quantitative performance of the difference between the pixel values of the enhanced image and the reference image.For the different content of underwater images,the tolerance for the pixel distortion of each color channel should be different when the image enhancement effect is evaluated.For example,for the underwater images with cool colors,if the value of the red channel accounts for a large proportion,the visual perception of the enhanced image will be seriously reduced.However,for the underwater images with warm colors,the different values of the red channel will not bring about obvious changes in the visual perception.In the above two cases,the degree of color distortion of the two images should be different from the view of human perception,but under the measurement of mean square error,the calculated distortions are consistent.Therefore,the proposed algorithm introduces the weight of each channel on the basis of the traditional mean square error function.For a pixelpof an underwater image,the color loss of the corresponding channel can be expressed as:
where ΔRp,ΔGpand ΔBpare the pixel difference of each channel between the enhanced image and the reference image,andare the corresponding weights of each channel.For different image content,the distribution of pixel values of each channel is usually quite different,so the proposed algorithm determines the weight of each channel according to the distribution of each channel,which is expressed as:
(2)structure loss
For underwater image enhancement tasks,another important quality evaluation criterion is the degree of image feature preservation in the restored image.There are too many scattering media in the underwater imaging environment,resulting in a large amount of blurring.If the enhancement algorithm further loses image texture and structure features,it will seriously affect the quality of final images.Therefore,this paper uses structure loss as the second loss term to measure the enhancement result,which is also implemented by the VGG-19[32]pre-training model.Features are extracted from the enhanced image and the reference image,and the structure loss is defined as the L2 distance between the feature tensors:
whereIpredictis the enhanced image,Igtis the reference image,ϕ(•) represents the network operation after the VGG-19 pre-training model removes the last fully connected layer,C,H,Wrepresent the number of channels,height and width of the extracted feature tensors,respectively.
(3)smoothness loss
For underwater images,the degree of smoothness is also an important metric that affects direct perception.Due to the existence of various floating substances in the body of water,it is apt to cause serious graininess in the enhanced images.
For an image,the degrees of smoothness of different regions are different.Therefore,the proposed algorithm uses the gradient information in the reference image as a reference when calculating the gradient loss,and dynamically adjusts the proportion of the gradient information in different regions to the total smoothness loss.This strategy can retain the main information of an image while removing the noise caused by a part of the floating medium.It is defined by the following formula:
whereC,H,Wrepresent the dimension,height,and width of an image,respectively,prepresents the pixels in the channel,∇xcand∇ycare the gradient information of the enhanced image in thecchannel,wc,xandwc,yare the gradient weights of the pixels in the current channel in the horizontal and vertical directions.The weight is defined as a dynamically updated coefficient that is inversely proportional to the gradient at the corresponding pixel of the reference image,and is defined as follows:
IV.EXPERIMENTAL RESULTS AND PERFORMANCE EVALUATION
4.1 Experimental Dataset
The experiments in this paper use the scene set of the public underwater image dataset EUVP produced by Islam et al.[33]in their experiments.It contains 2185 pairs of underwater images with a resolution of 320× 240.In the training process,2000 pairs are used as training data to train the network,and the remaining 185 pairs are used for testing the experimental results.In addition,this paper also uses another dataset UFO-120 [34] which consists of 1500 paired images for training and 120 paired images for testing.
4.2 Experimental Environment
In the training process of the proposed model,all image blocks of the input paths are unified into RGB format with a size of 128×128.They are cropped from 2000 pairs of underwater images and reference images in the training set.Each image pair is randomly cropped into three image blocks.This results in 6000 groups of image blocks being obtained for training.The Adam algorithm is used as the optimization algorithm in the training process,and the algorithm parametersβ1andβ2are set to 0.9 and 0.999,respectively.The initial learning rate is set to 0.0001.The minibatch training mode is adopted.Each batch size is set to 2,and 80 epochs are iterated.The learning rate decays to 10% of the previous rate after every 20 iterations.All experiments in this paper are run on a computer with the Windows 10 operating system,and an Intel Core i7-8700 processor at 3.2GHz.The memory is 16GB,the GPU is Nvidia GTX 1080Ti,the experimental programming platform is PyCharm,and the deep-learning framework is Tensorflow.
4.3 Experimental Results and Analysis
Based on the above experimental configurations,this section tests the performance of the proposed model and compares it with a variety of existing underwater image enhancement algorithms.The comparison algorithms include GW[13],UDCP[35],ULAP[36],UIEIFM[37],Water-Net[28],UDnet[38]and TACL[39].The test is conducted on two datasets:EUVP and UFO-120.The assessment metrics are mean-square error(MSE),the peak signal-to-noise ratio (PSNR),structural similarity (SSIM)[40],underwater image quality measures (UIQM)[41] and underwater color image quality evaluation(UCIQE)[42].Among them,MSE,PSNR and SSIM reflect the noise distribution and structure distribution of the enhanced image respectively.If MSE is small or PSNR is large,it means that the quality of the enhanced image is good.The larger the SSIM value is,the more complete the detailed features of the enhanced image are.UIQM and UCIQE are determined by multiple image properties,respectively.Their results reflect the comprehensive performance of the underwater image in terms of color density,contrast,saturation and clarity.If their values are large,it means the algorithm performs well.
4.3.1 Experimental Results on the EUVP Dataset
This section tests the performance of the proposed algorithms and various comparison algorithms for underwater image enhancement on the EUVP dataset.Figure 5 shows some test images,and the subjective comparison effects are shown in Figures 6 to 8.

Figure 5.Some of the test images of EUVP.
From Figures 6 to 8,it can be seen that each algorithm has a certain enhancement effect on the degradation images in the EUVP dataset.The GW algorithm can effectively mitigate the problem that the tones of underwater images are always blue and green.However,it is difficult to achieve good results for images with a single color,such as Figure 6(a),because it uses the average value of all pixels as a reference for the grayscale.The UDCP algorithm uses the blue and green channels as reference information to enhance the image,which has a certain effect on the underwater image with less serious color cast,and can effectively improve the contrast of the underwater image,but for the serious color cast underwater images,it will reduce the image quality.For example,on the whole,the color of the image in Figure 6(c) is greener than the original image,and the color of the water in Figure 7(c) is bluer than the original image.This will lose many image features.ULAP is based on the underwater light attenuation prior and linear regression.However,due to the different water environments of different underwater images,the attenuation process of underwater light is also different,so it is prone to using wrong prior information,which will lead to serious distortion.For example,the overall color of the reef in Figure 7(d) is wrong.In Figure 8(d),the fish is well enhanced,but the water suffers from overenhancement,which makes the color of the water appear white.The UIEIFM algorithm and the Water-Net algorithm are based on deep learning,and have higher robustness than the classic algorithms.They can basically guarantee the effectiveness of different underwater image enhancement,but the UIEIFM algorithm has insufficient balance for each color channel.Water-Net has a good color restoration effect on most images,but there is a certain amount of feature blurring in the enhancement results,such as the sea urchin in the lower left corner and the texture of the reef in the lower right corner in Figure 7(f),and the texture of the sandy beach on the right in Figure 8(f).The proposed algorithm can better balance the distribution of the three channels of underwater images.In the meantime,because it fuses the features of different levels to predict the enhancement results,it has the effect of blur resistance to some extent.It can preserve more details,and provide a better visual perception.

Figure 6.The enhancement effect on the image“Shoal”.

Figure 7.The enhancement effect on the image“Reef”.

Figure 8.The enhancement effect on the image“Fish school”.
As a quantitative analysis,this paper also uses the MSE,PSNR,SSIM,UIQM,and UCIQE metrics to evaluate the enhancement results of each algorithm.Tables 1 to 5 give the test results.
According to the test results,the proposed algorithm is basically better than other algorithms in five objective quality evaluation metrics,and has better performance in color correction,feature preservation,antiblurring and so on.
4.3.2 Experimental Results on the UFO-120 Dataset In order to further test the generalization performance of the proposed network,this subsection uses the UFO-120 dataset to test.Figure 9 shows some test images.The subjective comparison of different algorithms are shown in Figures 10 to 12.

Figure 9.Some of the test images of UFO-120.
It can be seen from the results on the UFO-120 dataset that the overall performance of each algorithm is roughly the same as that in the experiments on the EUVP dataset.For the traditional algorithms,GW has a good effect on the color balance processing of each channel of an underwater image,but it tends to incorrectly estimate some structural parts with red components,such as the color of the turtle shell in Figure 10(b).In addition,it has no constraints on the integrity of the image structure,resulting in the loss of a large number of detailed structures in the enhanced image,as it is shown in Figure 12(b)that the reef texture in the background is lost.The generalization performance of the UDCP algorithm is insufficient,and the area with only one color is likely to cause serious color distortion.For example,the background areas of the first three images have different degrees of color distortion.The ULAP algorithm may probably make the overall tone of an enhanced image reddish if the original image has a large proportion of the red component.For example,the color in the middle area of Figure 11(d)is reddish.For the methods based on deep learning,the UIEIFM algorithm can not effectively enhance the areas with too dense features and shadows.For example,the shadows on the left and right sides of the water body in the background in Figure 10(e) are enlarged.The Water-Net algorithm will result in the blurring of local details.For example,the spots on the turtle fins in Figure 10(f)and the texture structure of the reef in Figure 11(f) are blurred to a certain extent.The proposed algorithm has an almost identical distribution to the reference image in terms of the color balance of three channels.Meanwhile,compared with other al-gorithms,the proposed algorithm can deblur to a certain extent,restore more image features,and make the enhancement results more acceptable to the human vision system or subsequent processing.

Table 1.The MSE values on the EUVP dataset.

Table 2.The PSNR values on the EUVP dataset.
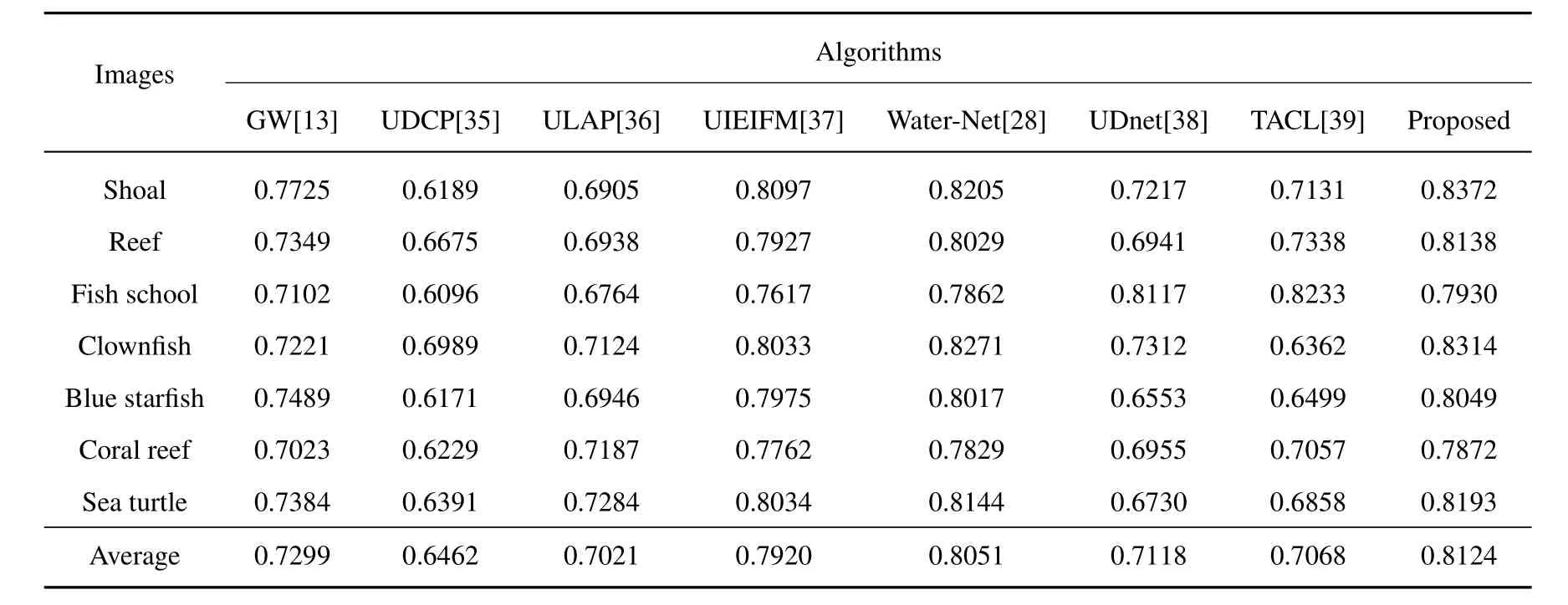
Table 3.The SSIM values on the EUVP dataset.

Figure 12.The enhancement effect on the image“Diver”.
Similarly,for quantitative analysis,the experiments in this subsection also test various objective performance metrics on the UFO-120 dataset,as shown in Tables 6 to 10.It can be seen that the comparison re-sults are similar to the previous experiments.The proposed algorithm is basically better than the other algorithms in the five objective quality evaluation metrics.
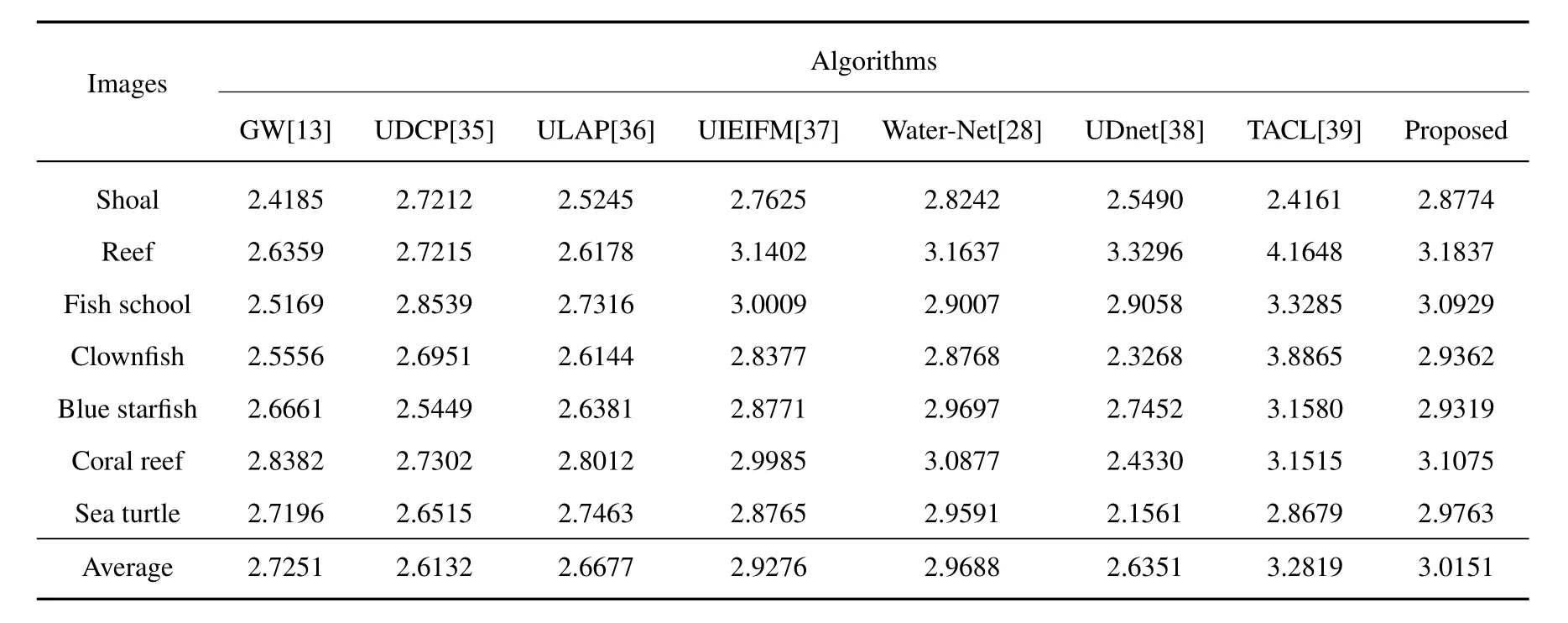
Table 4.The UIQM values on the EUVP dataset.

Table 5.The UCIQE values on the EUVP dataset.

Table 6.The MSE values on the UFO-120 dataset.

Table 7.The PSNR values on the UFO-120 dataset.

Table 8.The SSIM values on the UFO-120 dataset.
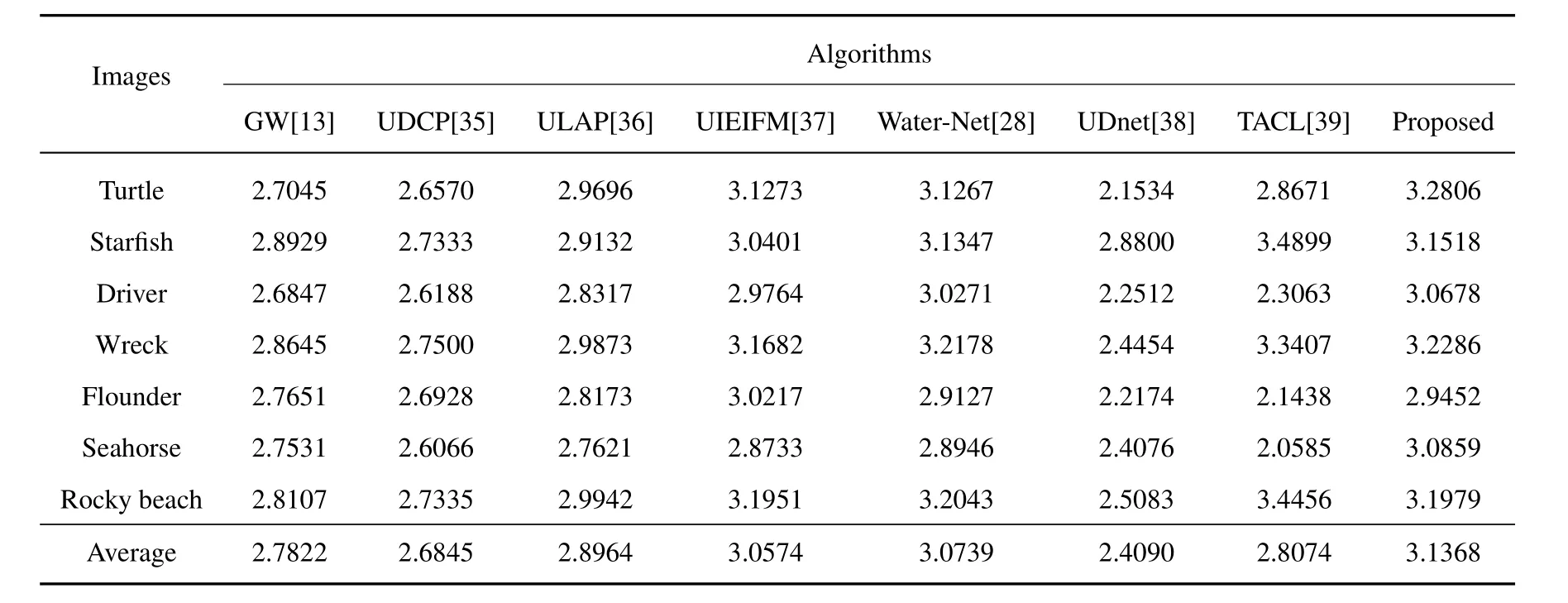
Table 9.The UIQM values on the UFO-120 dataset.
4.4 Ablation Experiment
4.4.1 Ablation Experiment for the Loss Function The loss function of the proposed algorithm is composed of three types of losses.In this section,each type of the loss in the enhancement results is further verified through ablation experiments.The test results are shown in Figure 13.

Figure 13.The loss function with different loss terms.
It can be seen from the test images that when only the color loss is used,the edge details of the animal in the enhanced image are blurred to a certain extent,and there is also some noise in the image.After adding the structure loss,the edges of the objects in the enhanced image are much clearer,and different structures of the image are easier to be distinguished.However,it can be seen that there are some uneven traces on the edge of the object: the enhanced image is not smooth enough.After exploiting the smoothness loss,the above two phenomena in the image are weakened,making the image smoother as a whole.Therefore,the three terms of the composite loss function can jointly constrain the enhancement process of the model from the three aspects of color,detail and smoothness,so that the final image is closer to the reference image.
4.4.2 Ablation Experiment for the Input Paths
The proposed algorithm includes three additional streams as the input of the network.In order to verify the influence of each stream,the ablation experiment is conducted.The test results are shown in Figure 14.

Figure 14.The enhancement effect of different paths.
It can be seen from Figure 14 that no matter which path is removed,some features of the enhanced image will be lost to a certain extent.If the CLAHE path is removed,the overall brightness of the enhanced image is lower than other results: it looks dim.This is because the function of the CLAHE path is to enhance the illumination information.If the WB path is removed,the overall tone of the enhanced image is blue because the balance of each channel is not enough.If the GC path is removed,the enhanced image is not smooth enough,and the change between different color areas of an image is too stiff.
To sum up,in the proposed enhancement model,all three kinds of preprocessing input paths have a certain influence on the performance of the final enhanced image.Each of them is necessary.
V.CONCLUSION
Aiming to solve the problems of color imbalance,image blurring and detail loss in the existing underwater image enhancement algorithms,this paper proposes a multi-stream feature fusion network.Three operations are used to expand the input image information,so that the model has enough input feature information for enhanced prediction.In the meantime,a weighted loss function is designed for training.The experiments prove that compared with other existing algorithms,the proposed enhancement algorithm obtains better performance in terms of color and detail restoration.However,we also found the shortcomings of the proposed network.For the underwater image with serious blurring,the network cannot distinguish the object and the background in the image very well.It will result in the fact that both the object and the background use the same mapping relationship,which leads to the distortion.In the future,we will try to exploit a pre-trained model of the super-resolution technique for the input channels of our network to better distinguish the image structure.
ACKNOWLEDGEMENT
This work is supported by the national key research and development program (No.2020YFB1806608),and Jiangsu natural science foundation for distinguished young scholars(No.BK20220054).

- China Communications的其它文章
- Resilient Satellite Communication Networks Towards Highly Dynamic and Highly Reliable Transmission
- Mega-Constellations Based TT&C Resource Sharing: Keep Reliable Aeronautical Communication in an Emergency
- High-Precision Doppler Frequency Estimation Based Positioning Using OTFS Modulations by Red and Blue Frequency Shift Discriminator
- Blockchain-Based MCS Detection Framework of Abnormal Spectrum Usage for Satellite Spectrum Sharing Scenario
- Energy-Efficient Traffic Offloading for RSMA-Based Hybrid Satellite Terrestrial Networks with Deep Reinforcement Learning
- For Mega-Constellations: Edge Computing and Safety Management Based on Blockchain Technology