
Stacking相异模型融合的实验室异常用电行为检测
2024-04-18 03:49王铭海缪希仁郑垂锭
实验室研究与探索 2024年1期
陈 静, 王铭海, 江 灏, 缪希仁, 陈 熙, 郑垂锭
(福州大学电气工程与自动化学院,福州 350108)
0 引 言
随着“碳达峰、碳中和”战略的提出,绿色低碳、节能减排将成为常态和主流[1]。高校实验室用电设备种类复杂且开、关频繁,在实验室使用过程中,往往存在一些因设备未关闭所导致的异常用电行为,例如夜间未关闭照明设备、空调等。这些异常用电行为不仅导致实验室电能浪费,同时还增加了用电安全的风险,增加实验室的运行管理成本。现有人工排查方法难以识别用户的异常用电行为,容易导致误判且效率较低[2]。根据电力计量数据实现对实验室异常用电行为精确检测,规范实验室用电行为,对于实验室用电安全管理和节能降损具有重要意义。
随着智能电网的发展,高级量测体系(Advanced Metering Infrastructure,AMI)逐渐建立,智能电表的普及率不断上升,采集大量蕴含用户用电行为规律的电力计量数据,使得基于数据驱动的异常用电行为检测成为可能[3]。目前基于数据驱动的异常用电行为检测方法可分为无监督学习和有监督学习。无监督学习[4-6]并不依赖带标签样本,而是学习用电行为蕴含的潜在规律,划分出偏离正常用电行为规律,将其标记为异常用电,没有训练过程,因此受数据类别不平衡的影响也较小。由于电力用户用电行为的不确定性,无监督模型的准确性和可靠性较低,同时算法的复杂度高。有监督学习则需要带标签的数据,即需要已知部分用户用电行为的类型,往往具有更好的准确性和可靠性,但是会受到数据类别不平衡的影响[7]。文献[8]中采用决策树优化支持向量机转换为多级分类器,改进蚁狮优化算法优化参数对用户异常用电行为进行检测。文献[9]中提出一种基于贝叶斯优化和改进XGBoost 模型的窃电检测方法,达到了92.78%的检出率。许刚等[10]利用稀疏编码对随机森林进行稀疏化,并设置阈值来判断用电异常行为。文献[11]中提出一种基于宽和深的卷积神经网络模型,将一维用电数据转化为二维用电数据,具有较好的检测效果,但在用电数据二维化处理上只是以周为单位进行数据堆叠。文献[12]中引入基于格拉姆角和场(Gramian Angular Field,GAF)的图转换方法,使用混合卷积神经网络进行窃电检测,检测效果有了进一步的提升。以上文献均使用单一学习器通过改进算法结构和对用电数据进行特征选择与变换来提升算法的检测效果,对模型计算成本有很高的要求。并且单一学习器只能通过单个维度挖掘用户用电数据的内在规律,异常检测模型性能的提升空间有限。针对单一学习器局限性,文献[13]中采用时间卷积网络(Temporal Convolutional Network,TCN)、文献[14]中采用Adaboost对多个弱学习器进行集成,结果表明,集成学习方法能提升弱学习器的检测效果。Stacking 集成学习能利用一种元学习器融合多个相异基学习器的分类结果,从多个模型多角度挖掘用电数据的内在规律,取长补短,提高模型泛化能力与分类效果[15]。
综上,本文针对实验室异常用电行为检测问题,提出一种基于Stacking 相异模型融合的集成学习方法,利用元学习器融合基学习器的优势和差异,精确识别实验室异常用电行为。让相异基学习器从不同角度对实验室异常用电行为进行研判,综合考虑相异基学习器分类性能并进行优选;选取充分融合相异基学习器优势的元学习器;使用实验室用电量数据验证模型有效性与灵敏性。
1 基于Stacking 相异模型融合的实验室异常用电行为检测
针对实验室异常用电行为的检测问题,单一学习器无法从多个维度去学习实验室历史用电数据中蕴含的内在规律,面对实验室用电行为的多样性,容易导致误判、漏判等现象,本文提出一种基于Stacking 相异模型融合的异常用电行为检测方法。该方法利用相异基学习器,从不同角度不同方式观测实验室用电数据,挖掘用电规律,通过元学习器融合相异基学习器的学习结果,实现对实验室异常用电行为的精确检测。基于Stacking相异模型融合的实验室异常用电行为检测流程如图1 所示。
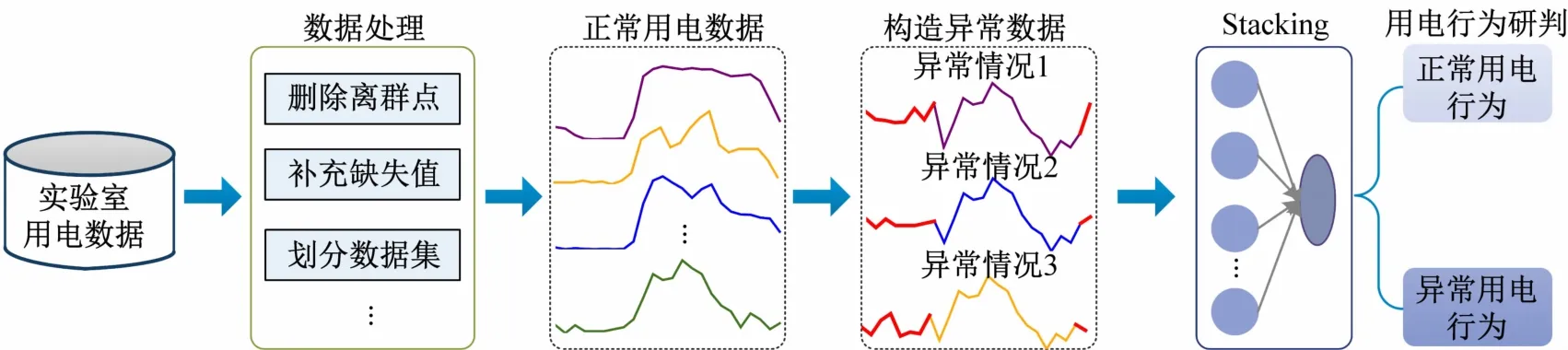
图1 实验室异常用电行为检测流程
具体步骤如下:
步骤1 数据清洗。剔除原始用电数据中缺失数据过多的用电量记录,采用3-sigma 准则判断每日用电量曲线的异常值并进行处理,采用线性插值填补空缺值,获得正常用电数据,并按8∶2的比例划分训练集与测试集。
步骤2 构造异常数据。分析实验室异常用电行为规律,模拟实验室异常用电行为,构造实验室异常用电数据。
步骤3 构建Stacking 集成学习。对常见的SVM、KNN、LR、DT、NB、RF、XGBOOST 和GBDT 等基学习器进行5 折交叉验证,通过综合考虑多个维度,选取最好的基学习器;在选取基学习的基础上,以XGBoost、RF、GBDT分别作为元学习器进行对比分析,选择能够最大限度优化融合基学习器学习效果的元学习器。
步骤4 用电行为研判。在训练好的模型中,输入测试集中实验室用电量记录,对实验室用电行为进行研判,输出最终的分类结果。
2 相异模型下的Stacking集成学习
2.1 Stacking集成学习原理
集成学习是将多个不同机器学习算法通过不同的方式结合,以获得优于单一学习器的泛化能力和性能。对于二分类问题,集成学习对分类器的常用结合策略可以分为投票法和学习法。投票法仅对学习器的分类结果进行多数投票或加权投票,并未充分利用初级学习器分类结果进行学习。学习法是用另一个学习器来学习初级学习器的分类结果,以提升整个集成模型的性能。Stacking集成学习是学习法的典型代表[16]。
如图2 所示,Stacking 模型通常由3 个部分组成。将训练集均匀分成不交叉的K份,取其中K-1 份作为基学习器的训练集,1 份作为验证集;其次选取M个相异的基学习器并行学习,从不同角度不同方式挖掘实验室用电行为特征,对实验室用电数据进行研判;将基学习器的分类结果作为元学习器的输入,由元学习器在基学习器的分类结果上进行学习,得到最终的分类结果。
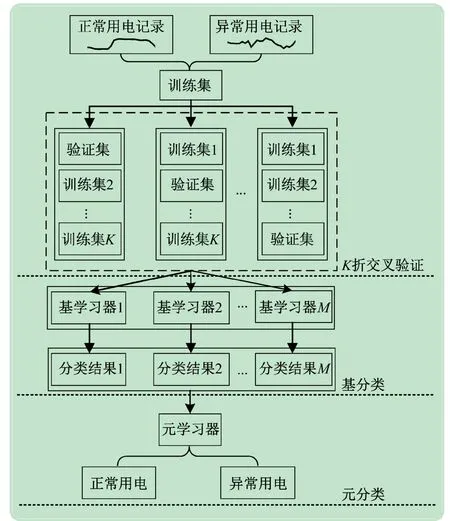
图2 Stacking集成学习原理
由于实验室用电行为具有多样性,单一分类器难以对用电行为进行精确研判,本文选择Stacking 集成学习模型作为实验室异常用电行为的检测模型,通过元学习器对不同基学习器的结果进行学习,从多个模型不同的角度挖掘用电数据特征,提高模型的泛化能力与识别效果,减少漏判、误判。
2.2 相异模型的选择
在集成学习中除了结合策略外,学习器的选择也十分重要,使用不同的学习器也会导致不同的分类效果。为使Stacking 集成学习模型获得最佳分类性能,既要分析每个基学习器的单独分类能力,同时也要考虑元学习器对基学习器的融合效果。
2.2.1 基学习器模型
不同类型的分类算法能从不同角度不同方式挖掘时序数据所蕴含用电行为规律,具有不同的优缺点,同种算法设置不同参数,则有不同的性能。
支持向量机(Support Vector Machine,SVM)将数据映射到高维空间,通过划分超平面来对高维数据与非线性数据进行分类,具有良好的泛化能力;逻辑回归(Logistic Regression,LR)是一种基于概率模型的分类算法,具有可解释性强、易于实现和计算量小等优势;K最邻近分类算法(k-Nearest Neighbor,KNN)无需训练过程,仅以多个最近邻样本进行研判分类;朴素贝叶斯(Naive Bayes,NB)假设所有特征之间是相互独立的,避免维度灾难的问题,可很好地处理高维数据;决策树(Decision Tree,DT)根据递归的方式将用电数据划分到对应的类别,决策树的结构非常直观,易于理解和解释,计算复杂度低;随机森林(Random Forest,RF)由多个决策树构成,相比于单一决策树,随机森林可更好地处理高维数据,引入随机采样的方式使随机森林不易过拟合;梯度提升决策树(Gradient Boosted Decision tree,GBDT)通过迭代的方式逐步提高模型的准确性,具有较好的分类效果;极限梯度提升树(eXtreme Gradient Boosting,XGBoost)引入二阶损失函数模型,具有高准确性,并在损失函数中加入正则化项防止过拟合,并行方式能够处理大规模、高维度的数据。不同模型的原理不同,各有其优缺点和适用性。
实验室用电数据表征实验室的用电行为。时序数据具备长期周期性趋势与短期非线性变化特点[17],实验室用电行为也具有周期性和多样性。不同分类器可通过数据的空间角度和结构角度,通过不同的方式对用电数据进行特征挖掘[18]。对于基学习器的选择,要分析每个基学习器的单独分类能力,选择能对各模型优缺点进行互补,提高模型泛化能力的基学习器。
2.2.2 元分类器模型
在Stacking 模型中,元学习器的选择十分重要。元学习器是用于组合基学习器分类结果的模型,其输入是基学习器的分类结果,输出是最终的集成分类结果。元学习器的主要作用是对基学习器的分类结果进行加权或组合,以进一步提高模型的分类性能。相比选择基分类器需要考虑从不同维度、不同类型算法的优缺点进行互补,元分类器模型的选择更偏向于考虑其分类过程中全方位的优化。XGBoost、RF 和GBDT模型具有很强的泛化能力和抗噪能力并可处理高维度和稀疏数据,具有广泛的应用场景,被认为是Stacking中较为可靠的候选元学习器。
2.3 评价指标
实验室异常用电行为检测本质上是对正常用电数据与异常用电数据进行二元分类。如表1 所示,本文通过混淆矩阵中的真正例(True Positive,TP)、真负例(True Negative,TN)、假正例(False Positive,FP)和假负例(False Negative,FN)4 个参数,定义准确率δACC、误检率δFPR、F1分数δF1,ROC 曲线下面积δAUC4 个评价指标,对实验室异常用电行为检测模型的检测效果进行全方位量化分析。
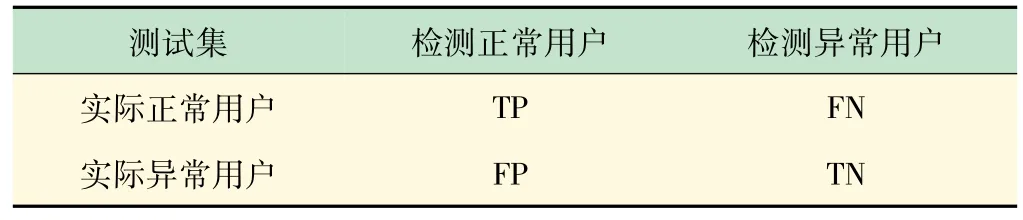
表1 混淆矩阵
准确率是指分类模型正确分类的样本数与总样本数之比,直接反映模型的分类准确性,即
误检率描述的是在所有实际为负例的样本中,被模型错误预测为正例的样本比例,可以评估模型的错误分类情况,即
F1分数是一种综合评估分类模型性能的指标(它结合了精确率δPRE和召回率δREC两个指标),即
δAUC是指受试者工作特征(Receiver Operating Characteristic,ROC)曲线下面积。ROC 曲线可综合描述精确率δPRE和误检率δFPR变化的相对关系,δAUC则可以同时衡量模型的δTPR和δFPR。
上述指标中,δACC、δFPR、δF1、δAUC的输出值范围均为[0,1]。其中δACC、δF1、δAUC越接近1 越好,模型的检测效果越好;δFPR越接近0 越好,模型越不容易将异常用电行为标记为正常用电行为。
对实验室异常用电行为检测,既要保证尽可能准确识别出异常用电行为,又要尽可能减少正常用电行为被误判为异常用电行为的情况。需综合考虑各个指标,采用合适的算法和技术,对异常用电行为进行准确的识别,同时对正常用电行为进行充分分析,以降低误检率,提高异常用电行为检测的效果和可靠性。
3 算例分析
3.1 数据集
为获得更具有普适性的实验室用电规律和特征,使用某校电气学院各实验室用电量之和来表征实验室用电行为,并使用归一化,去除量级的影响。该数据记录了从2016-01-01 ~2018-04-18 共839 d用电记录,详细记录期间实验室每天24 h 的用电量。去除含大量空缺值的数据,还剩791 d用电数据,默认这些用电记录均为正常用电行为,并按8∶2分割训练集和测试集。
不同类型的用电设备具有不同的用电负荷特性。实验室中的负荷有如照明、风扇等功率恒定负荷,也有空调、冰箱等功率变动负荷。按照表2 模拟实验室夜间设备未关闭的异常用电行为。在训练集中随机选择20%的样本,在测试集中随机选择50%的样本作为异常用电样本。这些异常样本中随机混合3 种异常用电行为。

表2 异常负荷序列变换公式
给定正常用电样本X={x0,x1,…,x23},mean(X)指的是用电样本X的平均值;并定义时间段T={t0,t1,…,t7,t22,t23}用于表征0 ~7 h、22 ~23 h 的夜间时段,几种异常用电样本分别按照表2 生成。
h1(xt)为模拟夜间未关闭功率恒定负荷,即在样本夜间时刻用电量的基础上增加0.1 ~0.5 之间相同随机数乘以用电量的平均值。h2(xt)为模拟夜间未关闭功率变动负荷,即在样本夜间时刻用电量的基础上增加0.1 ~0.5 倍不同随机数乘以用电量平均值。h3(xt)为模拟夜间功率恒定负荷和功率变动负荷均未关闭。生成的3 种异常行为曲线如图3 所示。
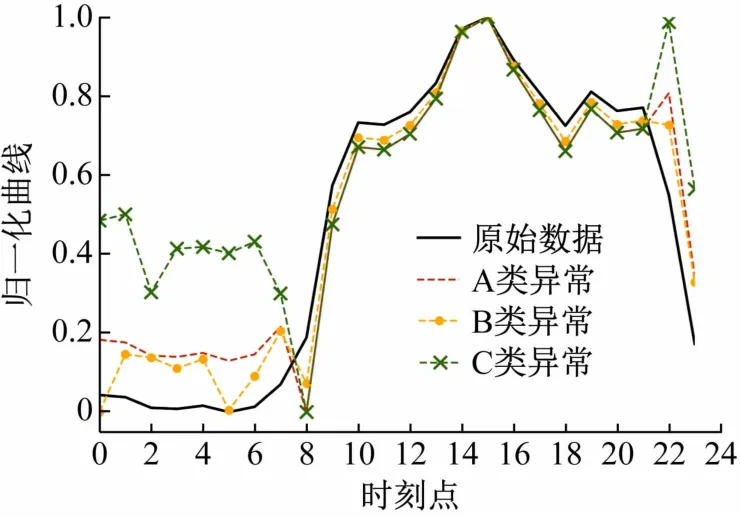
图3 正常用电行为与3种异常用电行为的区别
3.2 基学习器的选取
为构建基于Stacking相异模型融合的实验室异常用电行为检测模型,需利用评价指标筛选不同基学习器,从中选出最终用于模型融合,能充分挖掘实验室用电行为规律,优势互补的基学习器。因此考虑上述8个常见分类器在实验室异常用电行为数据集的δACC、δFPR、δF1和δAUC4 个评价指标,仿真结果见表3。
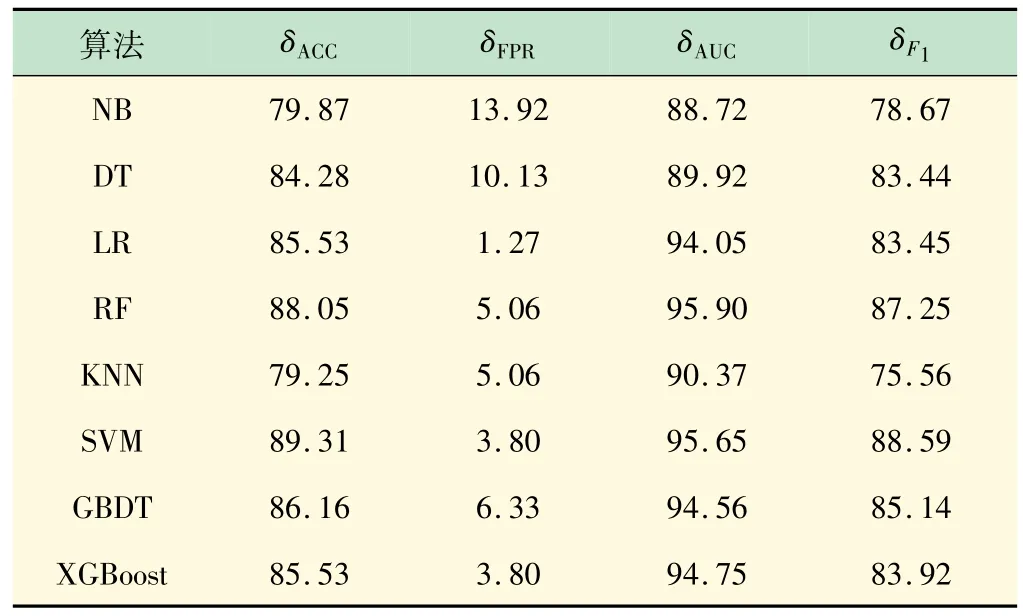
表3 各基学习器的结果对比 %
实验室出现异常用电行为,需人工介入规范实验室的用电行为。在异常用电行为检测中,高误检率将会导致大量实验室正常用电行为被错误识别为异常用电行为,这会增加人工干预成本。实验室异常用电行为检测既要保证尽可能高的准确率和尽可能低的误报率。
NB和DT的δFPR均大于10%,难以符合实际应用的需求应首先排除。而KNN的δFPR虽然比较低,但是δACC和δF1是所有模型中最差的、δAUC值也比较差,综合性能与RF、SVM、GBDT、XGBoost有明显的差距。
在Stacking集成学习方法中,基学习器的差异越大,元学习器就有越多的优化提升空间。LR虽然δACC不高,但是其δFPR很低,有助于与SVM、RF、GBDT、XGBoost的优势和缺陷进行互补,且LR观测数据的角度与4 种模型差异较大,有助于模型的多样性。
3.3 元学习器的选取
元学习器的选择和设计对模型的性能有着重要的影响。元学习器是用于组合基学习器分类结果的模型,其输入是基模型的分类结果,输出是最终的集成分类结果。一个合适的元学习器能更好地组合基模型的分类结果,改善各基学习器的偏差,提高模型的泛化性能,防止过拟合,本文选定RF、XGBoost 和GBDT 3 种类学习器作为元学习器进行训练,结果如图4 所示。
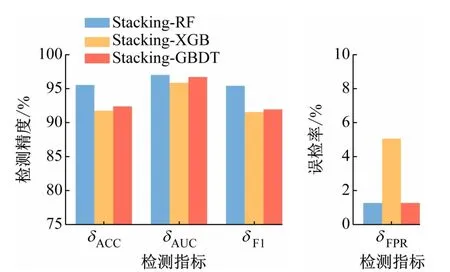
图4 不同元学习器的Stacking集成学习结果对比
融合基学习器学习效果最差的元学习器是XGBoost,δACC、δAUC、δF1和δFPR分别为91.82%、95.93%、91.61%和5.06%,除δFPR外,其他效果均优于最好的基学习器SVM。而RF和GBDT作为元学习器,对基学习器具有更好的融合效果,各评价指标均高于SVM。这说明Stacking集成学习中元学习器能学习相异模型的分类结果,在基学习器的基础上进一步提高对实验室异常用电行为的检测效果与性能。
以RF 为元学习器的Stacking 集成学习模型的δACC、δAUC和δF1均为3 种元学习器中最好的,分别为95.60%、97.08%和95.48%,δFPR仅为1.27%。RF 通过并行方式减少方差,有效地融合不同学习器的优势,互补基学习器的缺陷,使得在Stacking 集成模型表现最好。
为验证本文所选基学习器组合具有更优的分类性能,在保持元学习器为RF的情况下,用以下几种基学习器的组合与本文选取的组合进行对比,对各种组合进行编号,编号见表4。仿真结果见表5。本文选取的SVM、RF、GBDT、XGBoost和LR 作为基学习器组合在δACC、δAUC、δF1和δFPR均优于其他基学习器组合。这5 种基学习模型观测数据的角度不同,分类原理不同,能进行优势互补,提升模型的分类效果。

表4 不同基学习器组合编号表
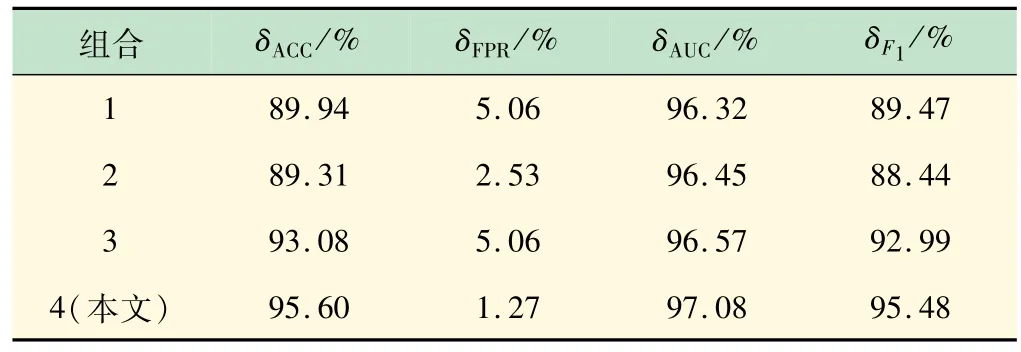
表5 不同基学习器的结果对比
3.4 Stacking的有效性验证
为验证Stacking 集成学习方法的有效性,使用最优的单一分类器SVM、集成最优单一分类器SVM 的AdaBoost和Bagging集成学习模型、融合本文选取的5种最优相异基学习器Voting 的集成学习方法进行对比,其结果如图5、6 所示。
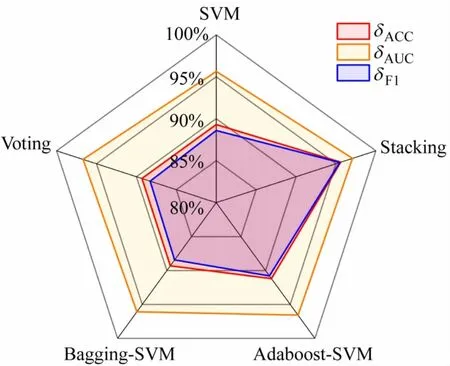
图5 5种算法的检测效果对比
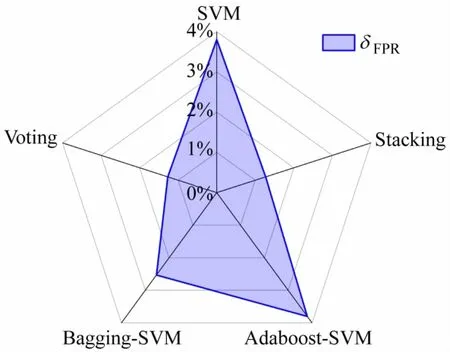
图6 5种算法的误检率对比
Stacking 的δACC、δAUC和δF1均达到最优,表明Stacking集成学习优于其他集成学习方法,能充分融合多个基学习器,从不同方式和角度观测实验室的用电行为,取长补短,能有效识别实验室正常用电行为与异常用电行为。
在这5 种算法中,Stacking 和Voting 通过集成不同基学习器,可有效降低δFPR,防止将实验室正常用电误判为异常用电行为。
3.5 灵敏性验证
实际生活中实验室异常用电行为较于正常用电行为是少数,存在样本不均衡的情况。为验证Stacking相异模型融合在样本不均衡的情况下的检测效果,分别设置训练集中异常用电样本占比为10%、20%、30%、40%和50% 5 种情况,得到δACC、δAUC、δF1、δFPR如图7 ~10 所示。
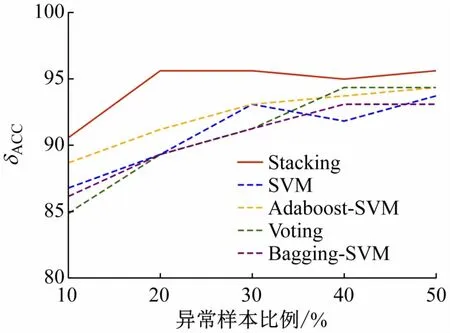
图7 5种算法下不同异常样本比例的δACC对比
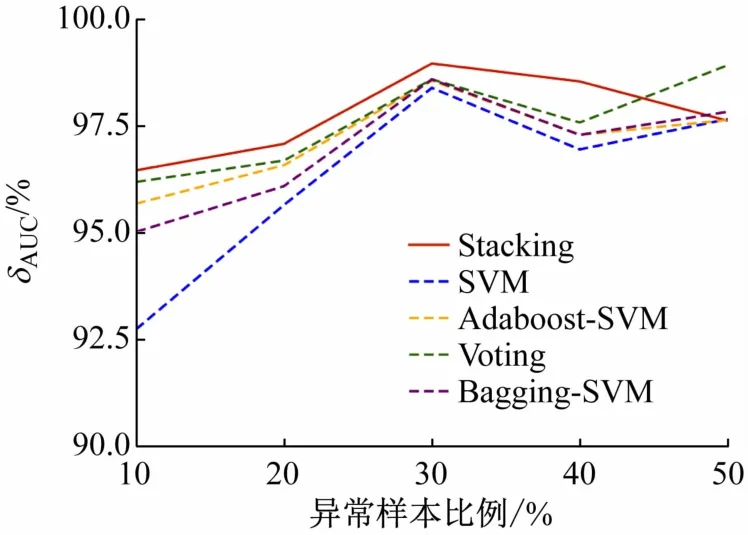
图8 5种算法下不同异常样本比例的δAUC对比
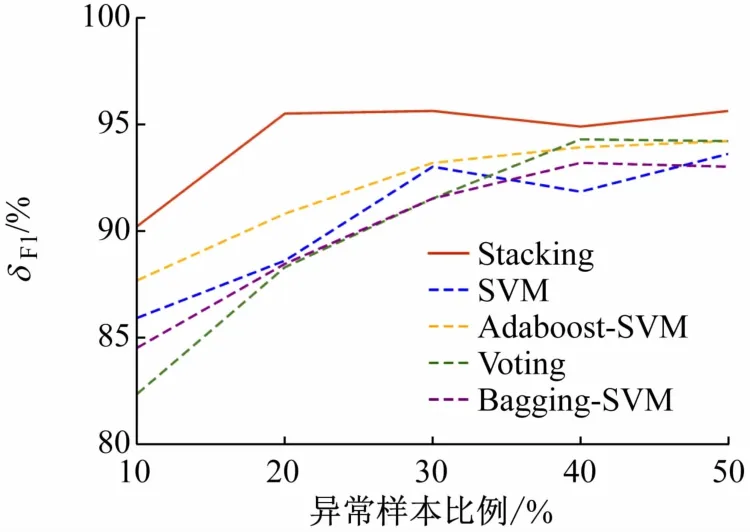
图9 5种算法下不同异常样本比例的δF1对比
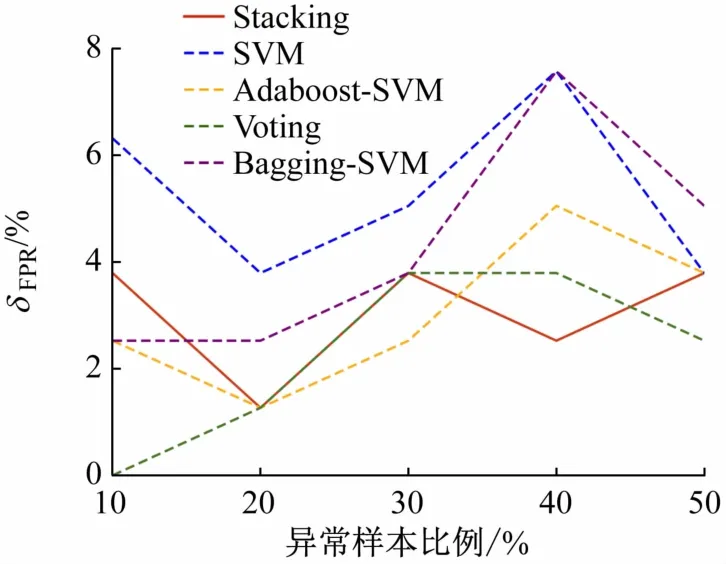
图10 5种算法下不同异常样本比例的δFPR对比
随着训练集中异常样本所占比例的减少,δACC、δAUC和δF1均受到影响,检测效果变差。Stacking的δACC和δF1在5 种情况下均为最优;δAUC在50%异常样本占比下,略低于Voting和Bagging-SVM,其余情况均最优;Stacking 在δFPR的表现上与Voting 相差不多,Stacking的δFPR最大为3.80%,最小为1.27%,较其他模型在各个异常样本比例中的δFPR较为稳定。仿真结果表明,基于Stacking 相异模型融合的集成学习方法具有良好的灵敏性,可适应样本不均衡的情况。
4 结 语
本文主要针对实验室异常用电行为提出一种基于Stacking相异模型融合的集成学习检测算法。采用SVM、RF、GBDT、XGBoost 和LR 作为基学习器,以RF为元学习器,实现对实验室异常用电行为的有效辨识。在某校电气学院实验室的数据上进行测试,准确率达到95.60%,误检率仅有1.27%。通过对比实验及有效性可知:Stacking能够融合不同基学习的优势,从不同角度挖掘实验室异常用电行为的内在规律,并能较好适用于样本的不平衡情况,对实验室异常用电行为具有良好的检测效果,有助于规范实验室用电行为,防止电能浪费和避免用电安全隐患。
猜你喜欢
经营者(2023年10期)2023-11-02
中国化肥信息(2021年12期)2021-04-19
中学生数理化·中考版(2020年12期)2021-01-18
电子竞技(2019年22期)2019-03-07
电子竞技(2019年21期)2019-02-24
电子竞技(2019年20期)2019-02-24
电子竞技(2019年19期)2019-01-16
小学生必读(中年级版)(2018年10期)2019-01-04
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
