
TESLA
2009-05-19 09:16线圈
微型计算机 2009年18期
线 圈
衡量计算机的计算能力,并行计算能力是一个很重要的方面,被广泛地应用于企业级并行处理、工程以及生物、物理等科学计算当中。由于设计初衷和架构的缘故,CPU在执行这类并行计算任务时效率并不明显。相反,GPU却凭借“先天”优势大有凌驾于CPu之上的趋势。以目前民用级显卡中最高端的GT200核心为例,它拥有240个流处理器,每一个都能进行相关的并行计算,其内部架构相当于240个微处理器,因此其浮点计算能力可以达到恐怖的933GFIops,是目前顶级CPU——Core i7 965 69.23GFlops(浮点运算能力)的十多倍。但是,在我们惊叹GPU强大的并行处理能力的时候,有没有想过把这种能力实际应用到高性能的企业级并行处理和科学计算中呢?
为什么并行计算会选择GPU?
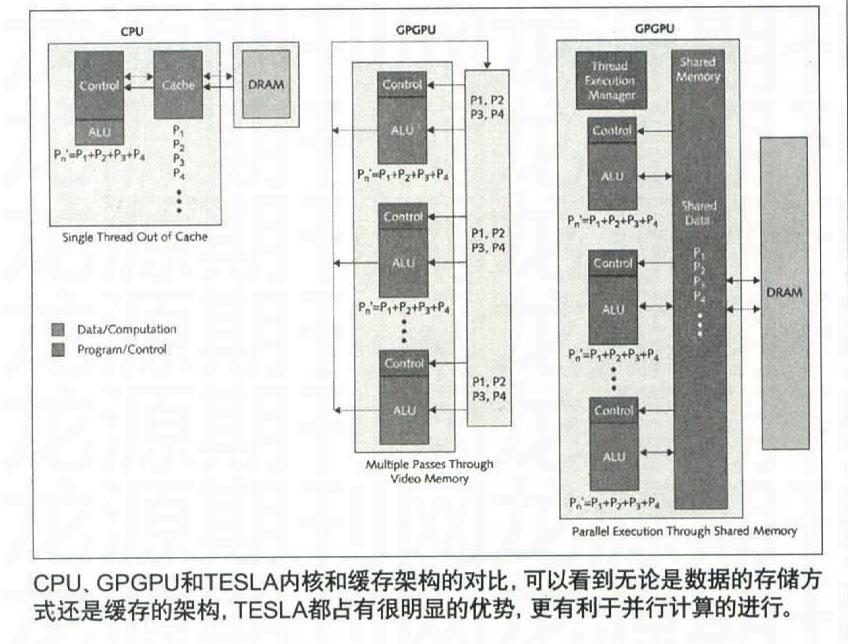
处理器的多核心化带来了一定程度上并行处理计算的兴起。以往单核心处理器通常只在一个时间段内执行单一任务,多任务操作都依靠中断指令或者等待排序来完成。虽然在宏观角度,多核心处理器体现了一定程度的并行化设计,但仔细分析,处理器的每一个核心依旧是为了串行任务而设计,优化的。比如CPu内往往设计了大容量高速缓存、超标量架构、乱序执行,以及强大的分支预测单元一一这些设计的目的主要是为了加速单一任务的计算。总的来说,CPU的设计追求大而全,编程自由化程度极高。但很明显,这种设计思路依旧是以串行为核心,并行程度极为有限。虽然可以自由完成复杂的串行任务,但是面对数据庞大的并行计算时,CPU只能使用一个单独的线程循环处理,效率不够高。
并行处理则不然。它适合计算关联不大甚至无相关性的操作。比如每一个像素都有自己的光照和色彩等数据。A像素不会由于B像素而无法完成计算,只要给定了目标,即使B像素不计算。A像素也基本上可以毫无影响的得到正确结果,实际上,并行任务有众多计算目标,这些目标之间没有什么关联性,几乎不会互相影响。另外,并行计算要求核心结构相对简单,不需要复杂的分支预测,对片上缓存的要求也非常低,只要有充足的内存即可很好地完成任务。
这就恰好解释了为什么GPU核心设计可以完美执行并行处理任务。首先,在以单个像素为计算目标发展了多年之后,GPU的并行计算能力达到了一个恐怖的程度。从浮点运算数值上我们就可以看出,GeForce GTX 280YLV-达到了Core i7965的十几倍。并且,经过长时间的发展,GPU相比CPU浮点性能差距AAGeForce FX时代的一倍左右迅速攀升到今天的十倍以上,并且还有继续增大的可能。这样看来,GPU拥有强大的性能和极为美好的发展前景,已经在硬件方面先为并行处理打好了基础。
另外,GPU本身结构也非常适合并行计算。在GPU内部,有统一调度流处理器的线程分派设计,也有大量的结构整齐的流处理器。在遇到如上百个几乎没有相关性的任务同时计算时,GPU可以依靠庞大的流处理器资源同时对这些数据进行处理,在极短的时间内完成。值得一提的是,在进化至统一渲染架构,特别是在CUDA等专注于并行处理的高级编程语言出现后,GPU的编程灵活性大大提升。程序员可以更为自由,轻松的获得各种想要的计算资源,编程难度大大降低。
除此之外,GPU目前的“核心——显存”结构也非常适合并行计算。并行计算不需要大量的片上缓存。例如在石油探测的处理中,数据量会达到几百兆字节甚至几千兆字节,利用片上高速缓存来容纳数据肯定是不现实的。因此GPU的“核心——显存”接口设计以及带宽庞大的显存控制器,能够很好的满足数以千计的线程并行计算时的资源需求。
综上所述,GPU似乎已经是并行计算板上钉钉的最佳执行者了。不过依然有一些问题需要解决。比如采用何种编程语言才能保证最大程度的兼容性和统一性?对并行计算而言,怎样的任务才能发挥它的作用?理论问题解决后,实际使用的可行性也是极为重要的。接下来,我们就一起来看看实际产品——TESLA是如何解决并行计算的实行运行问题的。
专为并行计算而生——TESLA的硬件构成
TESLA是以发明家尼古拉·特斯拉的名字来命名的,主要适用于服务器高性能电脑运算,是继GeFome和Quadro之后,NVIDIA的又一个显示核心商标。针对不同的用户群,目前TESLA系列主要分为三类产品,分别是定位于-%k和普通用户的C系列TESLA计算处理器,定位于服务器用户的S(Server)系列TESLA 1U服务器系统和定位于桌面超级计算机用户的D(DeskTOP Supercomputer)系列TESLA个人超级计算机。各个不同系列产品之间的核心结构部分差别不大,更多的是核心数量上的差别。比如TESLA D系列个人超级计算机就利用四块TESLA C系列计算处理器组成。因此,本文重点介绍TESLA C系列产品。
从外观上看,TESLA C系列产品和普通显卡非常相似。不过由于TESLA仅为并行计算加速而生,因此它没有提供DVI等输出接口,全部通过PCI-E x16总线和系统进行数据交换。另外,TESLA往往配备了容量惊人的显存。比如常见的GeForce GTX 280的显存容量为1GB,与其规格相近的TESLA C1060计算处理器的显存容量则达到了4GB。
上一代的TESLA 8系列和G80 GPU核心架构设计基本相同;而新一代的TESLAC 10系列产品则采用了GT200核心架构。以TESLA C1060为例,其内核含有240个流处理器,流处理器频率为1296MHz,显存频率则为800MHz(等效1600MHz GDDR3显存),显存位宽也同样为512-bit,核心电压则保持了GT200的1,1875V。供电方面,TESLAC1060还是需要1个8pin+1个6pin外接电源接口,最大功耗为183W。
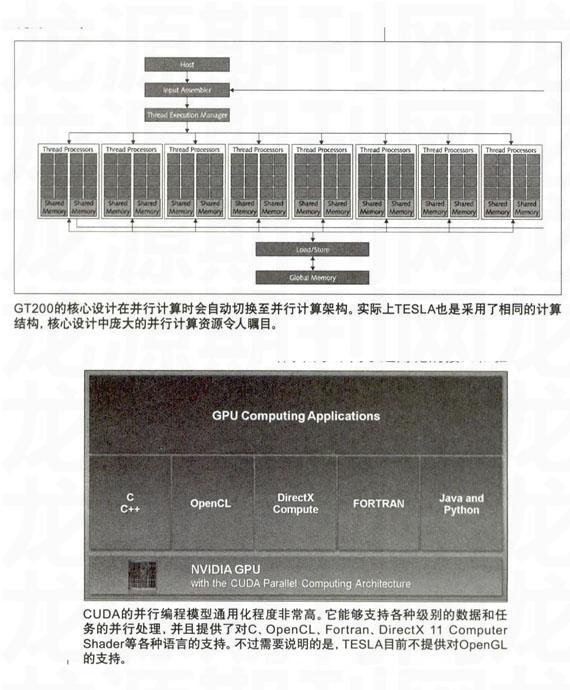
新一代的TESLA的GT200核心在设计时就充分考虑到并行计算的需求,拥有诸如线程调度器、内存界面单元,纹理高速缓存等设计。在并行计算时,TESLA依靠强大的线程调度器,将程序自动调整,分配给每一个流处理器并完成计算,时刻保证计算的高效率,非常适合并行计算任务的运行。
那对于企业级用户来说,TESLA的吸引力究竟在哪里呢7我们不妨besESLA$1070 1U系统为例来分析。该系统能够提供高达4T FLOPs的浮点运算能力,而实际功耗只有700W。700W对于个人电脑来说确实是一台高功耗平台,但是对于服务器集群来说却不值一提,因为,要搭配同样一套4T FLOPs的传统X86 CPU集群,大概需要170颗3,0GHz四核CPU,满载功耗至少在TESLA$1070的10倍以上,这还不包括前期投入的费
用,部署以及后期散热的成本。无论是从经济角度,还是从实际部署的难易程度上看,TESLA的优势都很明显,对于企业级和经常需要进行科学计算的用户来说,确实是一个经济而高效的选择。
专为并行计算而生——TESLA的软件配备
除了硬件部分,TESLA在软件部分采用CUDA来完成并行计算的编程。有关CUDA的介绍,我们已经提及了多次。对TESLA以及其它的并行处理显卡来说,CUDA能够支持各种级别的数据和任务并行处理。并且,CUDA基于编程人员熟悉的C语言结构,在语言友好性方面也相当不错,
在CUDA中,编程人员可以先将计算目标划分为粗放的子目标,这些子目标可以用并行的方式独立解决。之后编程人员可以进一步调整这些并行任务,使其能够在诸如TESLA等并行处理设备上完美运行。除此之外,CUDA也会在程序内部将要处理的目标自行分配为更为细小的区块,然后尽可能地利用流处理器迅速,并行地执行。在驱动端,编程人员也不用关心TESLA是怎样和系统沟通,怎样和CPU进行互动的,甚至在编写程序的时候可以将给CPU的命令和给GPU的命令混合编入,随后只需要使用一些简单代码将其区分出来,CUDA就可以自动评估,将任务交由GPU或CPU处理,并且自动载入GPU进行计算。这种智能的操作和编程模式将编程人员从程序的调度以及管理运算资源中解放出来,转而专注于提高计算的并行化和运行效率,
除了CUDA带来的强大编程能力外,TESLA还能支持128-bit的IEEE754单、双精度浮点单元,和CPU浮点单元一样支持各种高级的浮点操作。由于采用了通用化的接口和驱动结构,TESLA能够很轻松地兼容AMD和英特尔的X86处理器,并且完美支持Windows 32-bit/64-bit以及Linux操作系统。
由于CUDA的存在,TESLA在软件方面发展极为迅速。目前已有100多种专业软件提供了对CUDA?FITESLA的支持,其中包括地震预测、油气资源探测核磁共振成像,分子动力学,神经电路模拟等。
技术分析:CUDA在GeForce和TESLA上的差异
CUDA作为一种开放式的并行计算技术,不仅可以运行在TESLA上,也可以用于GeFome显卡上。那么CUDA在GeForce(或者Ouadro)上运行和在TESLA上运行有什么不同?
首先,TESLA是专为企业部署设计。它在系统配置上尽可能满足并行计算的需求,比如在单卡上就配备了多达4GB的高速显存。而GeFo rce显卡没有如此高的显存配备。其次,TESLA在质保和产品支持方面更有优势,产品周期更长。除此之外,TESLA还有支持服务器的1U规格以及个人桌面超级计算机等配置,普通的GeForce显卡则没有这些定制型选择。
至于GeFo rce显卡,它主要面向游戏和娱乐用户,在产品定位和系统配置上明显低于TESLA系列,支持普通的CUDA加速完全可以,但是在专业的、要求极高的,计算强度大的计算时效率肯定不如TESLA。而Quad r0显卡主要是面向专业绘图领域,支持OpenGL的高级功能(TESLA不支持OpenGL),专业绘图速度远高于GeForce,在同等配置情况下价格也远远高于TESLA。
大展神威——TESLA在实际应用中的性能提升
目前基于CUDA的加速软件均可以在TESLA上无缝运行并获得强大的加速计算效果,其中涉及到科学计算和日常应用的各种方面(以下均为科研组织或者NVIDIA官方提供的数据)。
从这些应用的实际测试结果来看,TESLA~_少能提供2-250倍的性能提升。比如在计算电磁学中,四块TESLA C870计算处理器对比Xeon(至强)2,6GHz cPu,可以获得超过50倍的性能提升。而在流体动力学的计算中,TESLA的性能几乎达到了Xeon以及Itamium(安腾)处理器的100倍左右。
金融计算领域,利用TESLA C1060计算处理器加速并行计算,相比原采用Xeon处理器的计算结果,TESLA胜出了58倍之多;而在Monte Carlo定价模型中,TESLA只用了最多0.4秒就完成了计算任务,而Xeon2.6GHz处理器需要3111秒才计算结束。
很多用户比较关注MATLAB的加速计算。目前MATLAB已经推出了利用CUDA进行并行处理的加速计算插件,我们来看看它能带来多大的性能提升。在对比主流的Core 2 Duo处理器中,TESLA普遍将时间减少到只有之前的1%甚至不到,速度提升了一百倍。
从各种科研组织以及NVIDIA官方发布的数据来看,TESLA在并行计算方面的确有极为惊人的优势,其领先幅度之高令人惊叹。这种结果一方面说明了TESLA在硬件基础上为大规模并行计算打下了良好基础:另一方面,不得不佩服CUDA~TESLA带来的极为明显的优化作用。如果说TESLA硬件部分是人的躯体的话,CUDA就ATESLA的灵魂和大脑。
MC点评:TESLA从发布到现在仅仅一年多的时间,已经得到众多厂商和科研单位用户的广泛支持。它的优势很明显,就是利用GPU强大的并行处理能力打造小型化、经济化的服务器平台和超级计算机。在充分展现低成本、低功耗、体积更小、高效等特点的同时赢得了大家的认可。不过。我们也看到,目前TESLA的核心架构以及附属功能与GeForce和Quadro的区别不是太明显;另外。尽管新一代的TESLA 10产品的双精度浮点运算的速度有一定提升(与单精度浮点运算相比提升了8%)。但还不够。这些都是有待改进的地方。对此,NVlDIA TESLA产品事业部总经理Andy Keane先生表示:未来的TESLA系列产品将拥有专为高性能计算而设计的其它特性,双精度浮点运算的速度也将有5倍以上的提升。如果这些说法得到印证。那么TESLA将有一个更加值得期待的明天。
猜你喜欢
凤凰动漫(军事大王)(2022年9期)2022-11-05
导航定位学报(2022年2期)2022-04-11
科技传播(2019年22期)2020-01-14
铁道通信信号(2019年4期)2019-10-10
中国教育网络(2018年7期)2018-08-10
中国计算机报(2018年42期)2018-01-31
环球市场(2017年36期)2017-03-09
电测与仪表(2015年18期)2015-04-12
电子设计工程(2015年3期)2015-02-27
计算机工程与科学(2013年2期)2013-06-07
