
文本分类中特征权重因子的作用研究
2010-06-04 08:18张爱华靖红芳
中文信息学报 2010年3期
张爱华,靖红芳,王 斌,徐 燕
(1. 中国科学院 计算技术研究所,北京 100190;2. 北京语言大学,北京 100083)
1 引言
随着互联网技术的迅速发展,网络文本的数量迅速膨胀,如何有效管理海量资源受到广泛的关注。文本自动分类技术作为管理海量数据的关键技术,由此得到了巨大的发展。
文本分类是指从预定义的类别集合中选择一个或多个类标号赋给测试文档[1-3],其中的关键技术主要包括文本表示、特征选择及分类模型等[2]。常用的特征选择方法有IG、CHI、TS、DF、MI、OCFS等[4-5],其中效果最好并且应用最广的是IG以及CHI[4]。近年来,主流分类模型基本源于机器学习领域[1-3],主要包括SVM、kNN、LLSF、Naïve Bayes及Neural Network等,其中SVM在文本分类中取得了较好的效果[6-7]。
文本表示是文本分类中的另一难点[2-3],它是将文档形式化的过程,其质量直接影响后续的工作。文本表示的研究目前主要通过以下几种途径进行:(1) 统计方法。如广泛使用的向量空间模型(VSM)[8]及其改进模型[9-14]。(2) 借助语言学的方法。这类方法希望通过自然语言处理方面的技术来弥补统计方法所忽略的文本语言学特征,但是实验证明这类方法对于分类性能没有显著的改进,同时复杂的预处理影响了速度,因此这类方法的发展受到了制约[15-16]。(3) 基于优化的方法。在这类方法中,权重只是一种优化的结果,并没有确定的含义,效果较好,但可解释性差[17]。统计方法由于可理解性好、效率高、效果好等优点目前是最为流行的文本表示方法,其中的VSM模型在文本分类中应用极其广泛。
VSM模型以TF及IDF两个因子的组合来表示特征,受到广泛的认可,但随着分类技术的发展,特征选择技术的提高,VSM模型也暴露了不足之处。在传统的文本分类过程中,文本特征的表示与特征选择相对独立进行,文本以VSM模型表示后,由特征选择函数计算特征得分并按分值排序,排序靠前的指定数目的特征以其由VSM模型表示的原始权重输入分类器。由于VSM模型没有将特征选择函数所计算出来的特征重要性纳入权重表示中,因此特征选择函数计算出的特征重要程度的排序关系并没有被输入分类器,造成权重表示不精确,影响了分类性能。而实际上,特征选择函数算出的得分能够在一定程度上反映特征的全局重要程度,是应当被融入权重表示的。文献[9-14]通过优化TF或IDF因子,或者通过引入特征选择函数等能够代表特征分布的因子等方法对VSM模型进行了改进,使分类性能得到了一定的提高。但是以上工作并没有分析TF、IDF、特征选择函数等各个权重因子是如何影响分类性能的。本文将文档代表性、文档区分性以及类别区分性作为特征的基本属性,通过实验考察了以上特征因子对于文本分类性能的影响。发现文档代表性因子(如TF)能够使得分类结果的峰值达到最高,但是随着特征数的增大,噪音特征的加入,其性能下降非常快。文档区分性因子(如IDF)随着特征数目的增大,性能下降比较平缓,说明其具有一定的抵抗噪音特征的能力。类别区分性因子(如IG、CHI)在选择的特征数超过某阀值后,性能基本保持不变,具有非常好的抗噪音特征的能力。基于所得的结论,本文进一步讨论了如何组合特征因子以得到优化的特征表示方法,并且通过实验验证了这种组合的优化效果。
2 相关工作
2.1 基于向量空间模型的文本表示方法
在文本分类及信息检索领域,向量空间模型(VSM)由于运算方便、易于解释及其良好的性能一直是使用最广泛的模型,但同时也有大量学者对其缺陷进行了广泛的研究和改进。

VSM模型在将文档形式化的过程中基于“词袋”(Bag of Words)假设,即假设各词语间的关系是独立的,忽略了上下文信息。文献[9] 将文档表示成图,使用随机游走的方法迭代得到的权重来代替原始TFIDF表示中的TF,由于原始文档中邻近的词被构造为图中的邻接节点,因此迭代后的权重相当于对文档进行了平滑,使上下文中的相关词可以互相推荐,克服了TFIDF模型中认为各个词的出现独立无关的不足,改善了分类性能。
VSM模型使用IDF来表示特征对于文档的区分度,受到文献[10-14]的挑战。文献[10]指出特征的区分度应体现在加权机制中,并基于TFIDF权重计算方法构造出代表特征区分能力的因子添加到TFIDF模型中。文献[11-12]认为IDF不能很好的反映特征的区分性及重要程度,因此使用特征选择函数代替IDF因子进行特征表示。文献[13]兼用IDF与特征选择函数来反映区分性,采用TF*IDF*IG的形式来表示特征。文献[14] 将类内方差、类间方差等描述特征分布的因子加入TFIDF模型中,也使得分类性能得到了一定的改善。
以上工作通过不同的方式组合TF、IDF、特征选择函数等因子,在某种程度上改善了分类性能,但是并没有分析这些因子究竟是如何影响分类性能的。本文的目标即在于分析和阐明各个权重因子对分类性能所起的作用,从而指导特征表示方法的构造与选取。
2.2 特征选择方法
文本使用特征选择函数来反映特征的类别区分性。本节简要介绍一下实验中用到的特征选择函数。
Yang Yiming[4]对文档频率(DF)、χ2统计量(CHI)、信息增益(IG)、互信息(MI)等常用的特征选择函数进行了研究,发现IG与CHI的性能最好[4],因此本文的实验基于IG与CHI设计。
IG用于衡量特征的出现或不出现对于类别预测所贡献的信息量。特征t的信息增益定义如下:

χ2统计量(CHI)用于衡量特征与类别的相关性,特征t与某类别ci的CHI如下表示:
其中,A代表ci类中出现t的文档数;B代表t出现在非ci类中文档的次数;C代表ci类中不出现t的文档数;D表示t与ci都不出现的文档数。
特征t全局的CHI可用求平均或最大值的方式得到,计算公式如下:
3 特征权重的组成因子
以往的文献对VSM模型的改良集中在加入一个能够描述特征分布的因子,或用这个因子来代替IDF项,并通过实验来证明方法对于分类性能的改进,但没有探究各个因子是如何影响分类性能的以及为什么某种因子的组合能够增强分类性能,本文将通过实验来分析权重因子对于分类性能的影响。
参考VSM模型及其改进表示方法,定义用于表示文本的特征应当具备以下特点:1)对所属文档的代表性;2)区分不同文档的能力;3)对不同类别的区分性,该性能也可看作是对于所属类别的代表性。
特征对文档的代表性常由TF表示,通常认为如果一个特征在文档中出现的频率越高,那么它对于该文档的代表性就越好。对于不同文档的区分能力常以IDF来表示,通常认为如果一个特征的文档频率(DF)越小,即IDF越大,则说明其用于区分不同文档的能力越强。有的文献用特征项的分布方差来表示特征对于不同类别的区分能力,而更多的文献使用特征选择函数来衡量这一特性,由于特征选择函数是非常成熟并被广泛使用的衡量特征类间分布的指标,因此本文使用特征选择函数来代表特征的类间区分性。
以下设计实验来探讨TF、IDF以及特征选择函数对于分类性能的影响,特征选择函数选取了性能很好的IG和CHI。
本文最终的目标是希望找到一种能够准确反映特征重要性的权重表示方法,以此来提高文本分类精度,因此,在分析了各个权重因子的作用后,我们将用得到的规则设计文本表示方法,并通过对优化组合的测试来验证其效果。
4 实验设计及结果分析
4.1 实验数据集
实验使用了Reuters-21578*http://www.daviddlewis.com/resources/testcollections/reuters21578/和20newsgroup*http://people.csail.mit.edu/jrennie/20Newsgroups/两个标准的文本分类语料进行测试。Reuters-21578是英文语料,实验采用其ModApte版本。数据集共包括90个类,7 769篇训练文档以及3 019篇测试文档。其中很多文档隶属于多个类,这里做单标签处理,即只采用每篇文档的第一个类别标签。语料中类的分布是非均衡的,最大的类“earn”中包括2 866篇训练文档,而82%的类中只有不到100篇训练文档,33%的类中训练文档数不足10篇。选择训练集不少于10篇文档的类别进行实验,经过处理,满足要求的类有41个。
20newsgroup是英文的均衡语料,共有20个类,每个类包含大约1 000个文档,共约20 000篇文档。实验采用其“bydate”版本,将文档按照6∶4的比例划分为训练集和测试集,没有重复文档,并且每个文档只属于一个类别。
两个语料都经过了预处理,包括去停用词、词干还原等。处理后的Reuters-21578包括17 761个特征,7 659篇训练文档以及2 950篇测试文档,20newsgroup包括85 560个特征,11 314篇训练文档以及7 532篇测试文档。
4.2 实验设计
为了探究各个因子对于文本分类性能的影响,首先将文本的特征分别以其TF、IDF、IG以及CHI表示,经过特征选择方法筛选后输入分类器,进而比较各因子的分类效果。将文本形式化后使用了特征选择函数进行过滤,目的在于降低特征空间的维数以减少计算复杂度,这里仍选取IG与CHI作为特征选择函数。
实验选用目前性能最好的分类器SVM进行测试[6-7],同时,为了保证分析的普适性,使用了另一种高效的分类器Naïve Bayes[18]来进行测试,但由于两个分类器所得结果的走势基本相同以及本文篇幅的限制,没有将Naïve Bayes的结果在此展示。分类器的实现均基于weka*http://www.cs.waikato.ac.nz/ml/weka/所提供的工具包,SVM的核函数使用线性核,其他为默认设置。
4.3 性能评价方法

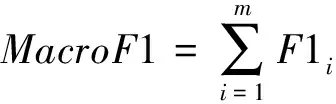
4.4 权重因子的作用
以下首先测试权重因子对于分类性能的影响,这里测试TF、IDF、IG以及CHI的分类性能随特征数目增加的变化,分类器采用SVM,特征选择函数使用IG与CHI。
4.4.1 Reuters语料
由于Reuters语料为非均衡语料,因此用微平均F1与宏平均F1共同衡量其性能,使用IG及CHI作为特征选择函数对其进行降维处理,查看性能随特征数变化的改变趋势。
图1及图2是对Reuters语料进行分类的结果。由图可见以下几点:

图1 Reuters语料权重因子的性能随所选特征数变化图示(分类器:SVM,特征选择函数:IG)
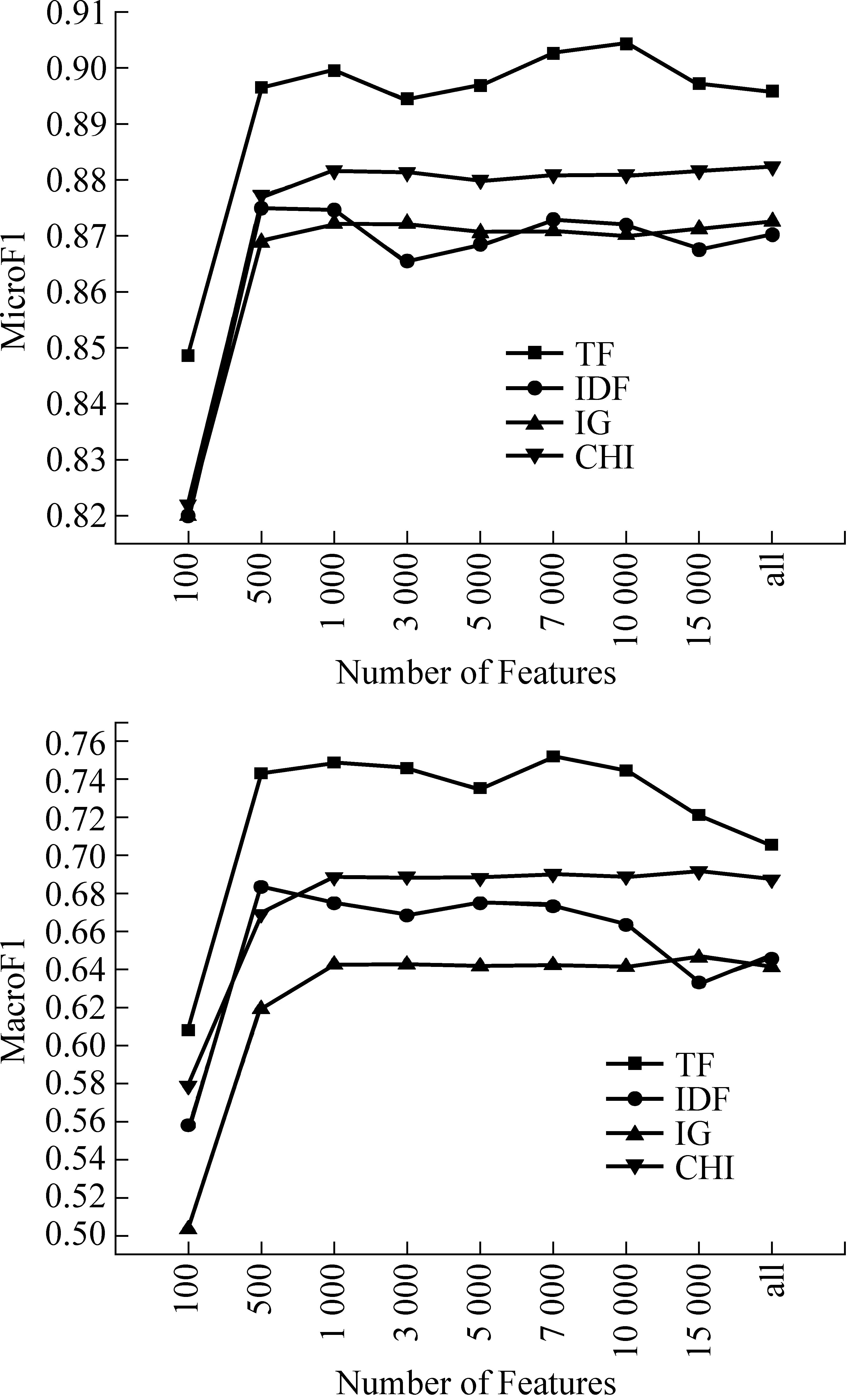
图2 Reuters语料权重因子的性能随所选特征数变化图示(分类器:SVM,特征选择函数:CHI)
首先,不论微平均还是宏平均,TF的峰值是所有表示方法中最大的,但是随着特征数目的增多,TF性能的下降也是最剧烈的。
其次,虽然IG与CHI的峰值始终没有超过TF,但它们的性能随着特征数目的增加没有出现下降的趋势。而被特征选择函数排序靠后的特征很可能是噪音特征,这说明IG或CHI作为特征权重时有着很强的抗噪音特征的能力,同时,当特征数大于1 000后,分类性能几乎不随特征数目的增加而变化,说明选择特征数目的设定不会影响所得的结果,鲁棒性很强。
再次,IDF既没有表现出高于其他的峰值,也没有在宏平均或微平均上表现出稳定或抗噪音特征的性能。
最后,在图1及图2中,相对应的权重表示因子的性能走势基本相同,而没有出现不同的权重表示方法与特征选择函数的组合使分类性能优化的情况,说明两者的叠加并没有增加过滤效果,表明了权重表示方法与特征选择函数的相对独立性。
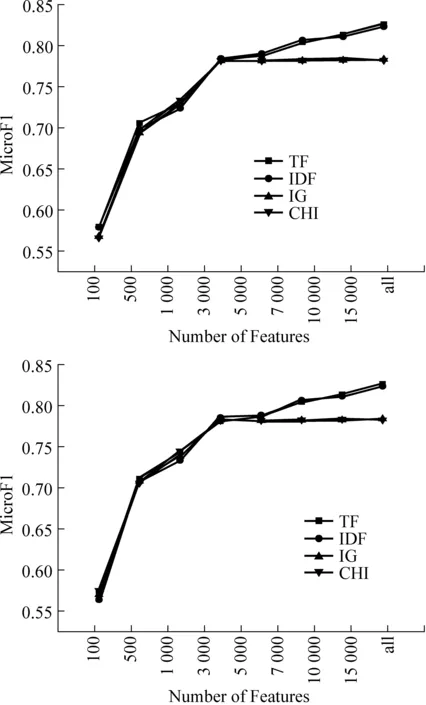
图3 20newsgroup语料权重因子的性能随所选特征数变化图示(分类器:SVM图的特征选择函数为IG,右图为CHI)
4.4.2 20newsgroup语料
由于20newsgroup是均衡语料,其微平均与宏平均效果相当,因此这里仅使用微平均F1来衡量其性能。由图3可以看出以下几点:
首先,随着特征数的增加,TF的分类性能不断递增。这与Reuters先升后降的走势有所不同。其次,IG与CHI在某阈值后走势非常平缓,这与Reuters的观察结果是一致的。同时,左右两图的相似性也反映了特征表示方法与特征选择函数的无关性。最后,IDF因子在该语料中的表现非常好,几乎与TF因子相当,这点也与Reuters语料不同。
4.4.3 权重因子的作用
我们考察了大量以Reuters语料为实验数据的文章,随着特征数目的增加,其性能都会呈现下降趋势,说明当特征数目达到一定阈值后,若再加入新特征,其中的有用特征对分类效果的提升作用小于噪音特征对分类效果的削减,因此,我们可粗略地认为路透语料的特征中是有噪音的,并且噪音特征影响了分类性能。而20newsgroup的性能都随着特征数目的增加不断增加,说明增加特征数目所引入的噪音特征对性能的削减作用小于引入的有用特征对分类性能的提高,因此可粗略的将20newsgroup看作无噪音特征或噪音特征较少的语料。
综合在两个语料上进行实验的结果,可以得到以下分析及结论:
首先,反映文档代表性的因子TF可以提高分类性能的峰值,但其抗噪音特征的能力差,因此随着增加特征数目而引入噪音特征后,其性能开始下降。
其次,反映类别区分性的特征选择函数(如IG,CHI等)能够过滤掉噪音特征,使得增加特征数目而引入噪音特征后仍保持分类性能的稳定,因此,即使设定的特征选取数目过大,仍然不会对性能产生过多影响,增强了鲁棒性。但对于无噪音特征语料,该因子的引入使得排名靠后的有用特征被过滤掉,因此在权重中引入该因子有可能影响20newsgroup的分类性能,该假设将在后面的实验中得到验证。
再次,反映文档区分性的因子IDF能够反映特征在文档间的分布。但是其对于分类效果的提高对于均衡语料比较明显,而对于非均衡语料并不明显。原因是由于均衡语料上各个类别的文档数基本相等,因此IDF在某种程度上可以同时反映特征在类间的分布,而对于非均衡语料,各个类别的文档数目相差非常大,特征在文档间的分布不能反映其类间分布,因此其过滤效果相对较差。这就解释了IDF在20newsgroup上的效果非常好而在Reuters语料上并不好。此外,对于非均衡语料,由于IDF无法替代反映类间分布的因子,因此IDF在Reuters语料上也呈现了震荡的趋势,不如IG、CHI等稳定。
综合以上分析,可以按照如下的原则构造文本的权重表示方法:
1) TF因子能够增加分类性能的峰值,因此在权重表示方法中应考虑该因子。
2) 特征选择函数能够起到过滤噪音特征,增加分类效果鲁棒性的作用,对于有噪音特征的语料,这种过滤所带来的效果提高非常明显。
3) IDF能够反映特征对于不同文本的区分度,对噪音特征也能够起到一定的过滤作用,因此它与TF、特征选择函数三者组合在一起,会达到比直接用IG等特征选择函数替代IDF更好的效果。对于无噪音特征的语料,特征选择函数的过滤作用过强,因此只选择IDF作为过滤因子较好。
4) 对于均衡语料,IDF能够在一定程度上反映特征的类间分布差异,因此它能够在一定程度上替代特征选择函数的功能。 对于非均衡语料,IDF不能很好的代表特征在类间的分布,因此在考虑文档区分性的同时要结合类别区分性以得到更好的效果。
5 应用
分析了各个因子的作用后,本节使用TF与IDF的组合,TF与IG、CHI的组合以及TF、IDF、IG或TF、IDF、CHI三项的组合作为文本的特征权重,经过特征选择方法筛选后输入分类器,通过比较分类效果来阐明各种组合所发挥的作用。基于上节给出的原则1),各种组合均包含TF因子。
Reuters-21578是有噪音特征的语料,由原则2),加入特征选择函数能够过滤噪音特征,结合原则3)及4),该语料上分类效果的排序应为TF*IDF*IG及TF*IDF*CHI最好,而由于在特征数较少的情况下噪音特征少,过滤显得不那么重要,因此TF*IG/CHI与TF*IDF的效果好坏不能确定,但随着特征数目不断增大,由于TF*IG/CHI对噪音特征的过滤效果更强,其性能开始提升,这些推断都在图4所示的实验中得到了验证。
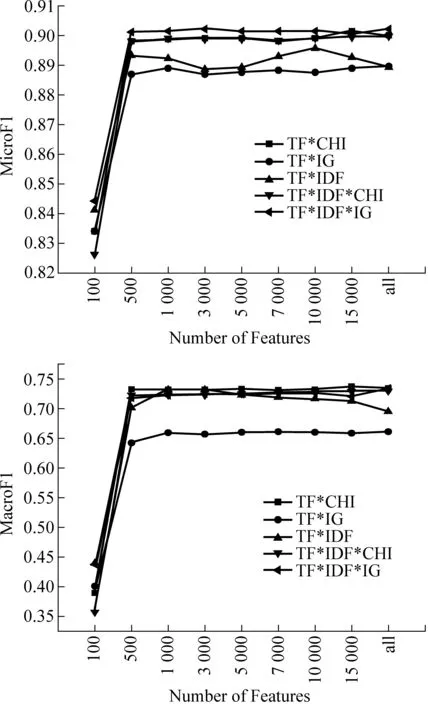
图4 Reuters语料权重因子组合效果试验(分类器:SVM,特征选择函数:IG)
图4是Reuters语料几种权重组合表示的分类效果示意图,由图可以看出:除了TF*IDF,其他表示法在特征达到一定数目后都很稳定,没有震荡;TF*IDF*IG/CHI最完整地反映了不均衡语料的特征分布规律,因此其分类性能最好;而TF*IG/CHI忽略了文档间分布差异,其性能变得不稳定(TF*CHI效果好而TF*IG效果不好,无法对这类组合的效果做整体判断)。此外,使用CHI做特征选择函数与图4使用IG的分类效果类似,这里不再赘述。
图5是20newsgroup语料几种权重组合表示的分类效果示意图,由图可以看出:由于该语料没有噪音特征,因此当特征数目大于30 000以后,特征选择函数过滤掉了有用特征,造成其他表示法的效果都不如TF*IDF,这验证了上节的原则3)及4);其他四种表示法由于只是过滤掉了一些有用特征,并没有引入不利因素,因此其效果并没有下降,这与原则2)是一致的;当特征数小于10 000时,由于包含特征选择函数的表示法能有效的选择更有用的特征,因此其分类效果比TF*IDF好。使用CHI做特征选择函数与图5使用IG的分类效果类似。

图5 20newsgroup语料权重因子组合效果试验(分类器:SVM,特征选择函数:IG)
6 结论与下一步工作
本文指出了文本特征权重表示中应当包含文档代表性、文档区分性以及类别区分性三个因子,以TF、IDF以及IG/CHI为代表通过实验探究了这些因子对于分类性能的影响,给出了构造文本权重表示方法的四点指导性原则,基于具体语料的特点构造了权重表示,并通过实验验证了其有效性。
下一步的工作包括:探究哪些统计量能够充分代表特征的文档代表性、文档区分性及类别区分性属性;探究是否还存在其他的影响分类性能的特征权重因子;上下文及词性等因素是如何影响分类性能的等等。
[1] Yang Y. An evaluation of statistical approaches to text categorization[J]. Information Retrieval, 1999, 1: 69-90.
[2] Sebastiani, F. Machine learning in automated text categorization[J]. ACM Computing Surveys, 2002, 34(1): 1-47.
[3] 苏金树, 张博锋, 徐昕. 基于机器学习的文本分类技术研究进展[J]. 软件学报, 2006, 17:1848-1859.
[4] Yang Y, Pedersen J. A Comparative Study on Feature Selection in Text Categorization[C]//Proceedings of the 14th International conference on Machine Learning, 1997: 412-420.
[5] Yan J, Liu N, Zhang B, et al. OCFS: optimal orthogonal centroid feature selection for text categorization[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval, 2005: 122-129.
[6] Yang Y, Liu X. A re-examination of text categorization methods[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, 1999: 42-49.
[7] Thorsten J, Text Categorization with Suport Vector Machines: Learning with Many Relevant Features[C]//Proceedings of the 10th European Conference on Machine Learning, 1998: 137-142.
[8] Gerard S, Christopher B, Term-weighting approaches in automatic text retrieval[J]. Information Processing and Management: an International Journal, 1988, 24(5): 513-523.
[9] Hassan S, Banea C, Random-Walk Term Weighting for Improved Text Classification[C]//Proceedings of TextGraphs: 2nd Workshop on Graph Based Methods for Natural Language Processing, ACL, 2006: 53-60.
[10] Shankar S, Karypis G. A Feature Weight Adjustment Algorithm for Document Categorization[C]//Proceedings of SIGKDD’00 Workshop on Text Mining, 2000.
[11] 陆玉昌, 鲁明羽, 李凡, 等. 向量空间法中单词权重函数的分析和构造[J]. 计算机研究与发展, 2002, 39(10):1205-1210.
[12] Debole F, Sebastiani F. Supervised term weighting for automated text categorization[C]//Proceedings of the 2003 ACM symposium on Applied computing, 2003: 784-788.
[13] 鲁松, 李晓黎, 白硕, 等. 文档中词语权重计算方法的改进[J]. 中文信息学报, 2000, 14(6): 8-13.
[14] Lertnattee V, Theeramunkong T. Effect of term distributions on centroid-based text categorization[J]. Information Sciences-Informatics and Computer Science: An International Journal, 2004, 158(1): 89-115.
[15] Kehagias A, Petridis V, Kaburlasos VG, et al. A Comparison of Word- and Sense-Based Text Categorization Using Several Classification Algorithms[J]. Journal of Intelligent Information Systems, 2003, 21(3): 227-247.
[16] Moschitti A, Basili R. Complex linguistic features for text classification: A comprehensive study[C]//Proceedings of the 26th European Conference on Information Retrieval (ECIR), 2004: 181-196.
[17] Frigui H, Nasraoui O. Simultaneous Clustering and Dynamic Keyword Weighting for Text Documents[M]. Berry, M. W. (Ed.), Survey of Text Mining, Springer, Berlin. 2004: 45-72.
[18] McCallum A, Nigam K. A Comparison of Event Models for Naive Bayes Text Classification[C]//Proc. of the AAAI-98 Workshop on Learning for Text Categorization, 1998: 41-48.
猜你喜欢
客联(2022年3期)2022-05-31
通信技术(2021年12期)2022-01-25
中国新闻周刊(2021年26期)2021-07-27
小学科学(学生版)(2020年10期)2020-10-28
疯狂英语·新悦读(2019年10期)2019-12-13
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
电脑爱好者(2017年7期)2017-05-06
民族古籍研究(2014年0期)2014-10-27
