
面向网络论坛的突发话题发现
2010-07-18 03:11程学旗
中文信息学报 2010年3期
陈 友,程学旗,杨 森
(1.中国科学院计算技术研究所,北京100190;2.中国科学院研究生院,北京100049)
1 引言
网络论坛因其含有的大量有用信息已经成为Web2.0的典型代表。在网络论坛上用户不仅是信息的享用者,同时还是信息的创建者。这就使得网络论坛上每天都有大量的信息,并且信息更新速度快。国内网络论坛的典型代表“水木社区”[1]在同一时刻有接近一万人登录,每天有十万的新帖被写入。大量的新信息使得论坛对时事反映灵敏,特别是一些突发的事件。一般用户进入论坛基本上都是以主帖或者回帖作为浏览的对象,最普遍的形式就是以同主题的方式浏览论坛内容。如果他想了解一个事件发生的全过程以及与事件相关的一些描述,他可能需要浏览大量的主题才能够找到需要的信息,并且找出的信息可能还不完整。这样浏览的后果是花费大量的时间,且不一定找到满意的结果。如何从论坛大量相关的主题中自动化检测突发话题显得尤为重要。
论坛的开放性使得每一个注册用户都可以发表自己的想法,这就使得论坛上发表的帖子质量参差不齐,并且很多帖子都是口语化表示。论坛内容的随意性,用语不规范,口语化等这些特征使得针对网络论坛的挖掘变得相当困难。传统的话题检测与跟踪模型(Topic Detection and T racking,TDT)[2-3]虽然能够很好的解决话题发现问题,但是在论坛这种噪音环境下处理效果不好,因为TDT文献[4-7]中提出的方法处理对象是新闻语料,相比起论坛内容,新闻语料描述更准确、严谨、规范。内容噪音一直是论坛挖掘的一个障碍,针对论坛的话题发现也无法回避这个问题。
本文提出一种基于噪音过滤的话题发现模型。模型首先利用词以及用户参与度的突发特性进行噪音过滤,提取突发词以及核心用户。我们认为那些非突发词以及参与度低的用户在突发话题发现过程中起到的作用很小,把这些词作为噪音过滤掉。在发现后的突发词以及核心用户上我们应用话题发现算法。我们的算法不仅可以发现一段时间内的突发话题,同时还可以发现与这些话题相关联的用户社区。本文的主要贡献有三方面:
我们利用时间序列对每一个词以及用户参与度进行描述,然后在时间序列上利用频谱划分技术进行突发性计算与检测。我们的检测方法能够及早的发现突发词以及核心用户。
词的突发性被用作噪音过滤。网络论坛下的突发话题发现面临的关键问题是噪音,本文很好的利用词的突发性过滤掉噪音内容。那些非突发词以及活跃度低的用户将被视为过滤的对象。
我们从时间序列的相似性以及文本内容的重叠性两个角度设计了一个无监督学习的突发话题发现算法,该算法不仅可以发现突发话题,而且可以发现与这些话题相关联的用户社区。并且算法的高效性在实际论坛中已经得到了很好的验证。
2 相关工作
话题检测与跟踪研究较好的解决了话题发现这个子任务。TDT中大部分研究工作集中在新闻语料上,相比起论坛内容,新闻内容更准确、严谨、规范。它们基本上针对新闻语料进行聚类或者分类以发现新的句子来构成新的话题[8]。论坛与新闻有很大的差异,论坛对时事反映灵敏,参与用户数量庞大,用语不规范。这些差异特征使得TDT在解决论坛中的话题发现任务时力不从心,例如用语的不规范性,使得聚类效果很差。如何利用论坛的时间敏感特性来协助完成话题发现的任务是本文要解决的主要问题。针对论坛对突发事件以及与此相关的一些事件反映灵敏这一特性,我们首先提出在网络论坛下发现突发话题的新任务。这项任务区别于话题发现任务,它是在网络论坛这种特殊的环境下提出的一项新任务,既符合网络论坛及早发现突发事件的功用也符合网络论坛在时间维上的灵敏特性。
在解决网络论坛上的话题发现任务方面有两类典型的工作。首先,从用户角度进行相关研究的工作包括:文献[9]利用用户参与模型从论坛上发现话题。它们通过用户之间的相似度计算来对用户进行聚团,然后从用户出发发现与这些用户团相关联的话题。文献[10]在用户参与上建立马氏逻辑网络模型来发现话题。这些工作的出发点都认为在论坛中,用户相比起内容噪音更小,因此它们都把用户作为话题发现依赖的特征。但是这些方法发现的话题效果很差,描述性不好。其次,从文本内容和用户参与两个角度进行相关研究的工作包括:文献[11]利用TF-IDF以及UF-ITUF模型分别对词和用户参与度进行建模。由于大量噪音词的存在使得该模型的效果不好。并且文献[11]中只考虑thread中前17个帖子,这种做法是缺乏根据的。据我们研究,很多重要的信息出现在thread的前17个帖子之后。我们对每一个词和用户形成相应的时间序列,考察thread中的全部帖子,而不是前17个帖子,并且我们考察的重点是词以及用户在时间上的变化规律。我们通过对论坛时间特性的分析,从中挖掘出时间序列,然后在时间序列上进行相应的处理来帮助解决我们提出的新任务。
近年来,很多研究者在进行话题发现工作的同时,把目光转向发现Web2.0环境下的网络社区、核心用户等研究上来[12-13]。如文献[12]利用突发特征从Web log图中发现突发社区。本文采取一种频谱划分的方法对时间序列进行分析来发现突发特征,这种方法能够及早的发现突发特征;并且在频谱划分后的时间序列上我们可以进行突发话题发现以及用户社区发现相关的工作。
3 时间序列分析
首先定义网络论坛中几个重要的概念:
主题(thread):thread由论题(title)、入口(entry)、帖子(post)组成,并且 title、entry是唯一的。主题包含有一系列的post。每一个post唯一属于一个thread。
论题(title):一个 thread中的标题,是thread中第一个作者提出来的,并且在该thread中是唯一的,它代表着这个thread即将论述的主要内容,以后的post都是围绕这个 title展开论述。一个thread内部的所有帖子共享同一个论题。
入口(entry):它是关于thread中 title的详细论述,是由创建title的作者对 title的一个详细解说。每一个thread中entry也是唯一的。实际上它是thread中的第一个post。
帖子(post):一个post是指作者就某个论题进行论述的文章。它分为两类:主贴与回帖。一个post具有四个特性:发表时间、作者、论题以及论述内容。
论坛是由很多的板块构成,如在水木社区中有板块“水木特快”、“个人 show”、“交通信息”等。在每一个板块中,文本的组织形式是thread。每一个板块含有很多的thread。当发生突发事件,我们就会在“水木特快”上找到与该突发事件相关的的讨论,这些讨论可以是关于该突发事件发生的时间、地点、原因以及相关的背景知识。而这些内容的组织形式是很多的thread,它们的量很大,很难在短时间内对它们进行人工整理与归纳,此时在这些thread中自动发现大家讨论的话题显得相当重要。
3.1 时间序列
我们针对每一个词与用户,应用一定的规则形成相应的时间序列。首先定义几个重要的概念如下:
T:考察的post流时间跨度;F:特征空间集合;
TF f(t):特征 f在时间段t-1到 t出现在 post流中的次数;y f(t)=TF f(t);
yf=[yf(1),yf(2),…,yf(i),…yf(T)],特征f在T时间段内的序列;
在网络论坛中,词出现在 thread中不同的位置,其重要性是不一样的。例如如果一个词出现在标题中或是entry中,其重要性要比它们出现在回帖中更高。为此我们根据词在thread中不同的位置,定义一个位置权重策略如下:

该位置权重策略表示如果一个词在时间段t-1到t出现在title中的次数是 f_title,出现在entry中次数是 f_entry,出现在其他post中的次数是f_other,则 y f(t)=ωt×f_title+ωe×f_entry+ωo×f_other。ωt,ωe,ωo是根据经验来确定的,定义它们的目的就是为了突出那些对话题发现有帮助的词,因为标题中的词以及entry中的词在一个thread中重要性很高,突出它们符合论坛中th read的固有特性。ωt,ωe,ωo三个参数根据经验确定,在我们实验中确定为5,2,1。
相比起传统的新闻语料,大量用户参与其中是网络论坛的一个重要特征。在国家舆情控制方面,我们不仅希望发现突发话题,同时更想发现这些突发话题的背后都是哪些用户在参与。因此发现一些活跃的核心用户以及由他们构成的网络社区也显得尤为重要。为了突出那些发起者,我们设计了一个角色权重策略,其定义如下:

该策略表示如果用户是发起者,即是title与entry的作者,其权重为 ωs,如果为跟随者其权重为ωr。例如如果一个用户在时间段t-1到t内其发表了3篇标题(title)和2篇帖子,则其在该时间段内的yf(t)=ωs×3+ωr×2。ωs和 ωr也是根据经验来确定的,在实验中它们被赋值为5和1。
3.2 频谱划分
当前有很多方法[14-15]可以用来判断一个时间序列中是否含有突发(burst)。在这些方法中最典型的就是K leinberg提出的自动机模型。这个模型在很多应用中[16-17]得到了验证。这些典型的burst检测方法效果很好,但是它们的复杂度高,实现困难,特别是在对实时要求很高的系统中很难应用。突发话题的发现对实时性要求很高,这就使得这些方法很难在突发话题发现上应用。为了快速及早的检测burst,我们采取频谱划分的技术对时间序列进行分析。
对时间序列进行分段划分的方法很多,最典型的就是等时间窗口划分。在这些方法中最困难的就是时间窗口大小的确定,如果选择不合适的时间窗口,burst很可能被分解成很多的非burst,这样就会漏报很多的burst序列。我们采取一种新的方法来分割频谱。这种分割技术带来的 burst检测效率高,性能好,易实现。能够满足实时性的需求。
给定一个特征的时间序列y f=[y f(1),yf(2),…,y f(i),…yf(T)],我们把它分成k块X1,X2,…,Xi,…,Xk。每一块内部的每一个时间段的频率都大于0。每一块的值Xi为该块内所有时间段内频率值之和。例如时间序列(2 1 2 3 0 2 6 5 4 7 3),我们把它分成两块(2 1 2 3)和(2 6 5 4 7 3)。分块后两块的值X1,X2为X 1=8=2+1+2+3;X2=27=2+6+5+4+7+3。该例子的转换过程如图1所示。
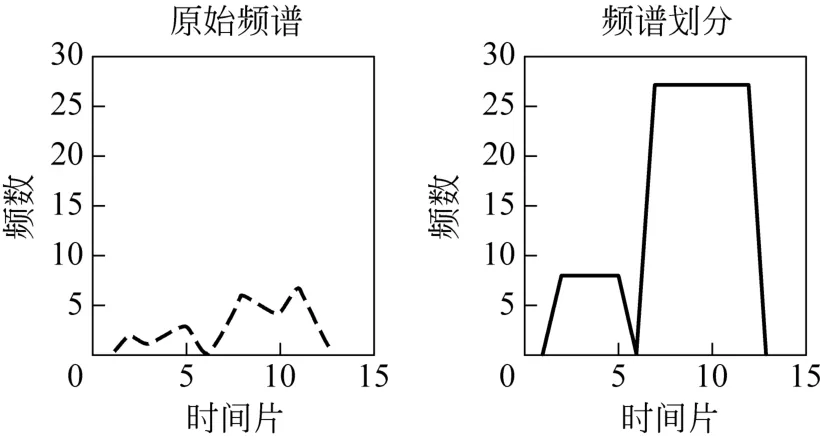
图1 时间序列以及相应的频谱划分片段
图1中可以看出,频谱划分片段相比原始时间序列,其在早期就能够发现burst,并且它把burst的值扩大化,更强调频率的变化。这些都是感性上的认识,为了快速的进行burst检测,需要对频谱划分片段进行量化。首先定义几个基本概念:
Sumseg[i]=Xi,i=1,2,…,k,表示第i块的频率值X i;

用一个二维向量Vf=[(s1,d1),(s2,d2),…,(si,di),…,(sk,dk)]来表示时间序列划分后的频谱片段。其中si=Sumseg[i],di=Devseg[i]。利用这种表示方法,图 1中的实例可以表示为:[(8,-0.72),(27,0.72)]。在二维向量空间中可以看出si表示第i块频率的绝对值,而di则表示第i块频率的相对值。当序列中含有burst时,其块与块之间的绝对值以及相对值差距大。
4 话题发现模型
话题发现的过程主要有原数据预处理,时间序列形成,频谱划分,突发词与核心用户检测,突发话题与用户社区发现五个阶段。原数据预处理是从post流中发现每一个post的五个基本特性:post所属的标题、post作者、发表时间、内容以及post标志号。post内容已经被分成词流的形式,并且一些诸如“的”“re”等停用词被移除。原数据预处理之后,针对每一个词与用户按照时间序列的形成规则形成对应的时间序列。在时间序列的基础上采用频谱划分技术,然后利用二维向量Vf来表示时间序列。在向量空间Vf上发现突发词和核心用户,然后在这些突发词以及核心用户上应用话题发现算法,发现突发话题以及与这些话题相关联的用户社区。
4.1 突发特征提取
通过观察每一个词的二维向量空间V f,我们发现有两种典型的词:普通词与突发词。普通词在向量空间上的表现形式为其偏差均为0,这种词大部分只有一个元素(s1,d1),在物理上表明这些词出现频繁,几乎时时出现;而突发词在向量空间上的表现形式为其向量中某些偏差与Sumseg[i]均很大,物理上表明该词在极短的时间内存在爆发性。普通词中那些Sumseg[i]值很大的词对突发话题的形成也是有作用的。我们从词集合中寻找这两类词,把它们作为突发特征。我们根据经验在普通词中选择那些Sumseg[i]值大于2 000的词作为突发特征,因为Sumseg[i]值小于2 000的词没有突发性。当然不同的数据集阈值是不同的。针对突发词的选择,max(Sumseg[i])>110,max(Devseg[i])>0.3作为阈值来选择。其中m ax(Sumseg[i])表示k个片段中的最大sumseg值,m ax(Devseg[i])表示k个片段中最大偏差值。
对阈值选择后的突发特征我们利用下面的公式对其进行排序:
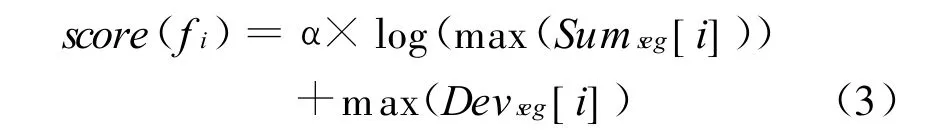
α在实验中被设置成0.16。
在核心用户的选择上,m ax(Sumseg[i])>20,m ax(Devseg[i])>0.35被作为阈值进行选择。
4.2 相似度测量
突发词被发现之后,如何根据这些突发词来发现突发话题是本小节研究重点。我们从词的相似性与post的重叠性两个方面来衡量词与词之间的相似度。两个词与词之间的相似性可以计算如下:
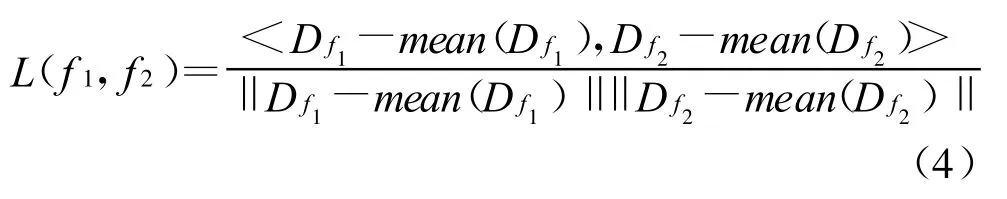
其中,D fj=[d1,…,di,…,dk]是词序列的偏差向量。通过偏差之间的相似性度量,可以发现相关的词集合。mean(D fj)是D fj的平均值,
词的集合R的相似度计算为:
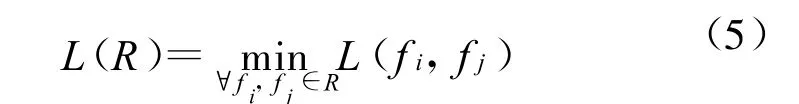
即集合R的相似性是由其内部相似性最小的两个词决定。
两个词所属的post的重叠度也是衡量词相似性的一个重要指标。假设Mi是含有词 f i的所有post集合,则既含有词 fi同时也含有词 f j的所有post集合为 Mi∩Mj。通常 Mi∩Mj的数目|Mi∩M j|越大,词 fi和f j越相关。我们定义两个词 fi与 f j的post重叠度如下:
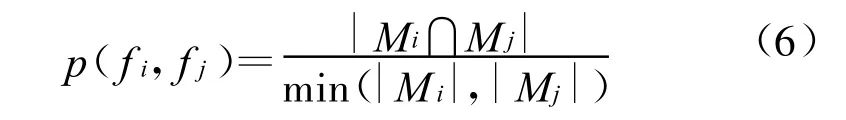
集合R的post重叠度定义如下:

同L(R)一样,p(R)也是由集合中最小post重叠度的两个词决定。
对于用户相似度计算也是从用户时间序列的相似性与用户所属thread的重叠度两个方面来度量。用户时间序列之间的相似性同词时间序列相似性计算一样。用户ui与uj所属thread的重叠度计算如下:
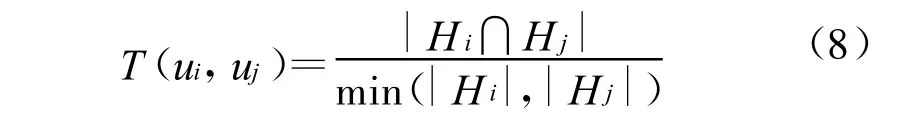
其中H i是含有用户ui的所有thread的集合,Hi∩Hj是既含有用户ui也含有用户uj的所有threads集合。用户集合U的重叠性度量为:
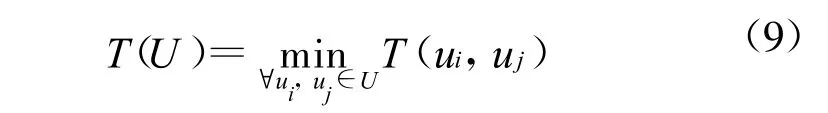
对词集合以及用户集合的相似度进行度量之后,我们可以设计算法来挖掘突发话题与用户社区。
4.3 无监督学习的突发话题发现算法
突发特征提取以后,对于任意给定的突发特征fi∈F′,寻找一组和 fi相关的特征子集来表示突发话题。其中F′是突发特征集合。从突发特征集合F′中寻找特征子集Ri⊂F′来表示突发话题是发现算法需要解决的问题。发现算法的目的是在找到Ri时,所花费的代价最小。代价函数表述如下:
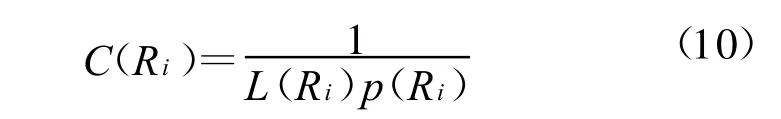
假设 δL是 L(R)最小值 ,δp是p(R)最小值,则在话题发现过程中发现一组相关特征的所需要的代价C(Ri)不能大于C max(R)=1/(δL×δp)。在突发特征集合上F′上同一突发特征可以在不同的突发话题中。应用该算法可以发现与这些突发话题相关联的用户社区。
无监督学习的突发话题发现算法如下:

5 实验
5.1 实验数据
实验数据采用“水木社区”的“水木特快”十天的数据。“水木特快”是“水木社区”里面最具典型性的一个板块,对突发事件的反映灵敏,并且参与的用户数量大。我们实验的数据是“水木特快”从2008年3月1日到2008年3月10日的数据。数据的详细描述在表 1中,并且这个数据集已经被人工标注[11]。
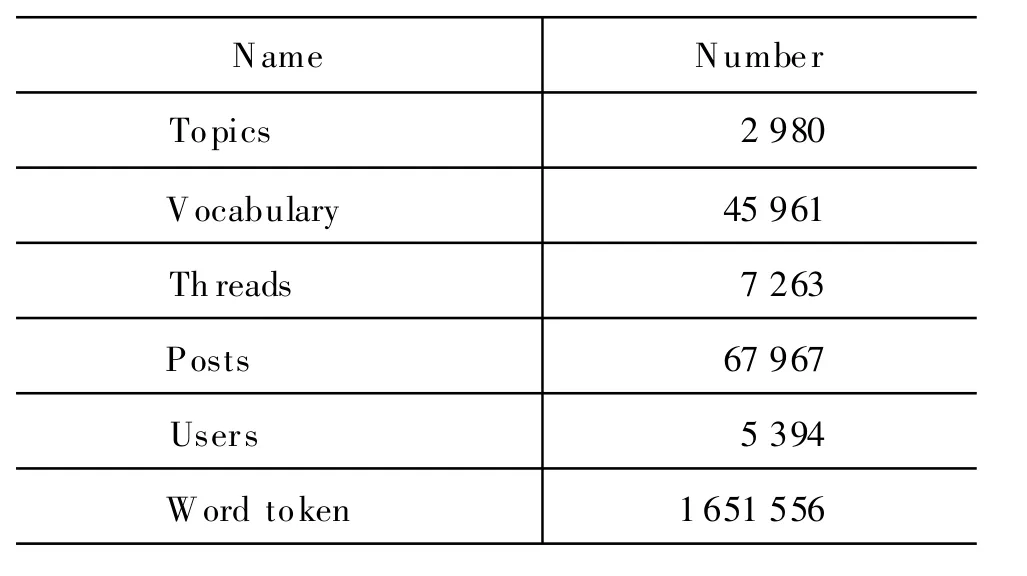
表1 实验数据集描述
我们实验的数据集有7 263个 thread,这些thread总计包含67 967个post。这相当于每天平均有6 796.7个post和 726.3个thread被加入到板块中。在数据集中,文献[16]的研究者们标注了2 980个话题,我们在此基础上标注了246个突发话题.在2 980个话题中,几乎有超过2 000个话题仅仅含有单个 thread。突发话题往往含有多个thread,在标注的246个突发话题中有接近62%的post被包含。这说明在网络论坛中突发话题需要进行归纳与总结,这样用户就能够及时全面的了解发生的突发事件以及与这些事件相关的一些事件,从而帮助用户节约大量的浏览时间,同时提高他们的浏览质量。
5.2 实验结果分析
我们利用两个阈值Sumseg>110,Devseg>0.3来发现突发词,发现的结果见图2,其中在两条虚线构成的四个区间中,右上角的区间就是我们需要的突发词。通过阈值选择的突发词数目有2 591。这就表明通过突发词发现之后,原本需要处理的45 961个词,现在只需要处理2 591个词。这种对噪音词的过滤方法不仅减小了模型的复杂度,同时也提高了发现算法的准确率。
在发现的2 591个突发词上,应用score(fi)对它们进行排序。
相比起文献[16]中的TF-IDF,UF-ITUF模型在所有词上的话题发现,我们的算法在排序好的突发词上性能更好,效率更高。
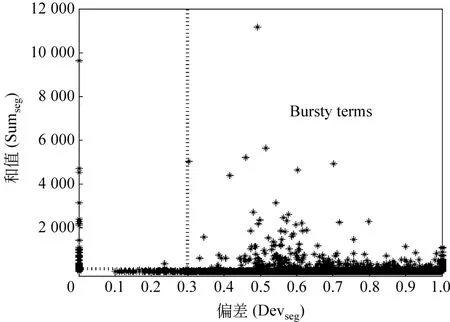
图2 所有偏差不小于0的词在Sumseg-Devseg上的分布
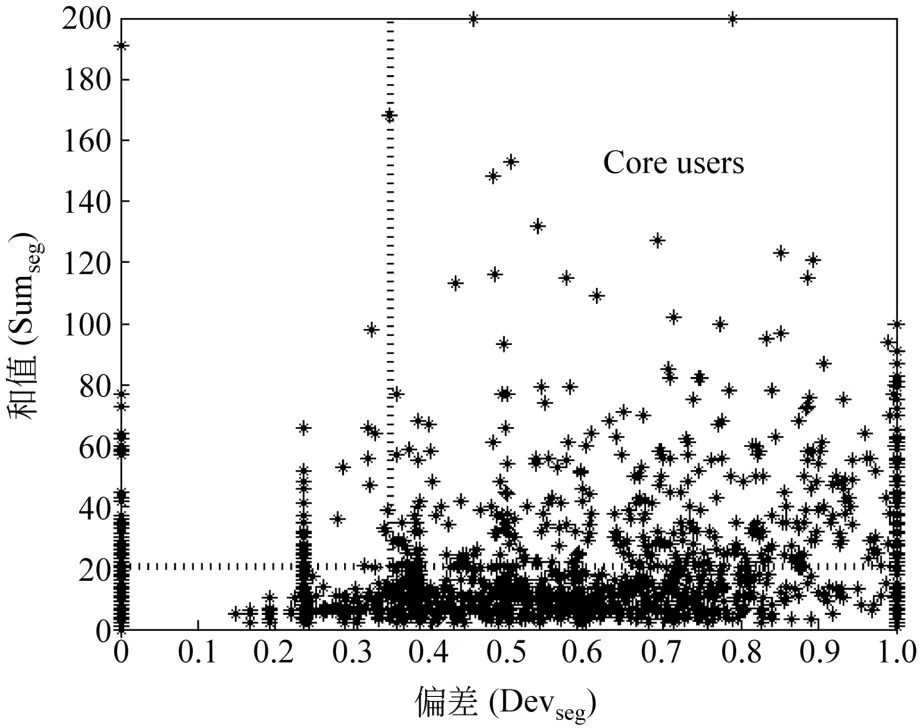
图3 所有偏差不小于0的用户在Sumseg-Devseg上的分布
在核心用户发现上,我们利用阈值Sumseg>20和Devseg>0.35。首先我们给出了所有偏差不小于0的用户在Sumseg-Devseg上的分布图,然后把两条虚线构成的右上角区间作为核心用户区间。详细的分布图见图3。在5 394个用户中我们选择了390个用户作为核心用户。图3从某种程度上说明更多的用户只是在跟从主要用户,因此对核心用户的考察意义非凡。我们同样利用score(fi)函数对用户进行排序,对这些排名靠前的用户进行观察,他们中的大部分是突发话题的发起者,在突发话题发展过程中起到主导作用,并且有很多的追随者。可见核心用户是突发话题发现过程中一个重要的特征。在突发词发现之后,为了验证话题发现算法的性能,我们根据不同的阈值Cmax(R)进行了7组实验。实验结果如图4所示。
从图4中可以看出,当 C max(R)在2.4时,其准确率、召回率以及F1值表现都不错,它们的值分别为0.86,0.82和0.84。根据实验结果可以得出两个结论:
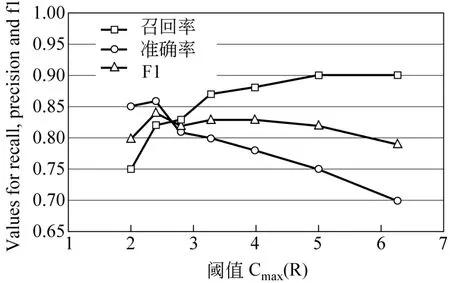
图4 话题发现算法在不同的C max(R)值上的准确率、召回率以及F1
(1)我们的模型能够发现80%以上的突发话题。
(2)突发词是突发话题发现的一个重要特征。不用从整个词空间,而只需要从少量的突发词中我们的模型就能以很高的F1值来发现话题。这样不仅节省了模型开销,同时也提高了话题发现的性能。
网络论坛的突发话题发现是一项新任务,前人的相关工作较少,最相关的就是网络论坛的话题发现。基于网络论坛的话题发现最具代表性的模型就是TF-IDF和UF-ITUF模型,文献[16]中的研究者们把两个模型结合起来作为话题发现的模型。这种综合模型不仅考察了内容特征,而且对用户参与度也进行了考察,具有一定的效果。本文把这种综合模型用来进行突发话题发现,同时与我们的模型进行了对比,对比结果如表2所示。
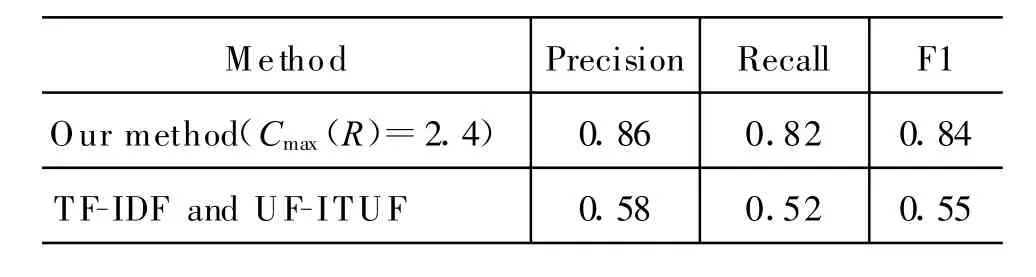
表2 我们的模型与TF-IDF-UF-ITUF模型在准确率、召回率以及F1值上的对比
从表2可以看出,我们提出的话题发现模型拥有更好的性能,当C max(R)=2.4时,F1值为0.84,相对于TF-IDF-UF-ITUF模型有将近 30%的提高。这是因为 TF-IDF-UF-ITUF模型是在噪音环境中操作的,它针对所有的词以及用户,并且在内容方面只考虑thread中的前17个post。这在一定程度上会丢失大量的信息。我们的模型通过burst特性过滤掉噪音词,并且 burst词的提取是在整个post空间,而不仅仅是考虑thread的前17个post。
6 结论
本文提出一种基于噪音过滤的话题发现模型,用来发现网络论坛中的突发话题。针对论坛中的词与用户分别设计了一套基于位置的权重策略和基于角色的权重策略。在两大权重策略的基础上,首先对词与用户建立相应的时间序列;然后采用频谱划分技术来分割时间序列;最后利用二维向量空间Vf来表示划分后的时间序列。基于二维向量空间,模型可以过滤掉噪音词,提取burst词与核心用户。在burst词与核心用户上应用无监督学习的话题发现模型来发现突发话题与用户社区。
我们在“水木社区”数据集上进行了大量的实验,实验结果表明,提出的模型在少量的burst词上就能够检测到80%以上的突发话题。Burst词不仅帮助发现算法节约了开支,同时对噪音词的过滤也提高了突发话题的发现精度。舆情控制的目的不仅是找到突发话题,更重要的是能够找到与这些突发话题相关联的一些核心用户以及由这些用户所构成的网络社区。本文提出的模型就能够很好的满足这点。
未来的研究集中在突发话题的演变与衰老上,我们计划从核心用户以及他们构成的网络社区来研究话题的演变与衰老。无论如何,我们相信本文提出的模型对网络论坛post流的基础性研究将会有很大的帮助。
[1] http://www.new sm th.net/[EB/OL].
[2] J.A llan,R.Papka,and V.Lav renko.On-linenew event detection and tracking[C]//Proceedings of the 21st Annual International ACM SIGIR Conference,1998:37-45.
[3] K.Zhang,J.Li and G.W u.New Event Detection Based on Indexing-tree and Named Entity[C]//Proc.of ACM SIGIR'07,2007:215-222.
[4] J.Allan,V.Lav renko,and H.Jin.First story detection in tdt is hard[C]//CIKM,2000:374-381.
[5] N.Stokes and J.Carthy.Combining semantic and syntactic document classifiers to imp rove first story detection[C]//SIGIR,2001:424-425.
[6] Y.Yang,J.Zhang,J.Carbonell,and C.Jin.Topicconditioned novelty detection[C]//SIGKDD,2002:688-693.
[7] G.Kumaran and J.A llan.Text classification and named entities for new event detection[C]//SIGIR,2004:297-304.
[8] J.Allan,C.W ade,and A.Bolivar.Retrieval and novelty detection at the sentence level[C]//SIGIR,2003:314-321.
[9] Zhi-LiW u,and Chun-hung Li.Topic Detection in Online Discussion using Non-Negative M atrix Factorization[C]//IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology,2007.
[10] V ictor Cheng,and C.H.Li.Topic Detection Via Participation using M arkov Logic Netw ork[C]//Third International IEEE Conference on Signal-Image Technologies and Internet-Based System,2007.
[11] M ing liang Zhu,W eim ing H u,and Qu Wu.Topic Detection and Tracking for Threaded Discussion Communities[C]//IEEE/WIC/ACM International Conferences onWeb Intelligenceand Intelligent Agent Technology,2008.
[12] J.K leinberg.Bursty and hierarchical structure in streams[C]//SIGKDD,2002:91-101.
[13] R.Kumar,J.Novak,P.Raghavan,and A.Tomkins[C]//On the bursty evolution of blogspace.In WWW,2005:159-178.
[14] Qi He,Kuiyu Chang,and Ee-Peng Lim.Analyzing feature Trajectories for event detection[C]//Proceedings of the 30th Annual International ACM SIGIR Conference,2007:207-214.
[15] Gabriel Pui Cheong Fung,Jeffrey Xu Yu,Philip S.Yu,and Hong jun Lu.Parameter free bursty events detection in textstreams[C]//Proceedings of the31st international conference on Very large data base,2005:181-192.
[16] R.C.Sw an and J.A llan.Ex trac ting significant time varying features from text[C]//Proceedings of the 8th international conference on Information and know ledgemanagement,1999.
[17] Nish Parikh and Neel Sundaresan.Scalable and near real-time burst detection from eCommerce queries[C]//Proceedings of the 14th ACM SIGKDD international conference on Know ledge discovery and data m ining,2008:972-980.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小学科学(学生版)(2020年10期)2020-10-28
疯狂英语·新悦读(2019年10期)2019-12-13
阅读与作文(英语初中版)(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
小学生学习指导(低年级)(2018年11期)2018-12-03
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
现代防御技术(2016年1期)2016-06-01
