
全国图书馆联合编目中心书目数据质量控制
2011-02-27 05:55周小敏广东省立中山图书馆广东广州510110
图书馆建设 2011年2期
周小敏 (广东省立中山图书馆 广东 广州 510110)
全国图书馆联合编目中心(以下简称联编中心)的建立不仅使全国图书馆的书目数据资源共建共享,同时也使各图书馆结成一个全国范围的文献保障体系,为馆际互借、文献传递提供了平台。但这一切都以统一的、规范的和高质量的书目数据为依托的。笔者在实际工作中发现,联编中心书目数据库中存在很多有问题或有错误的书目数据,这会造成很多不良的影响:①就联编中心而言,错误的书目数据或由多卷册与丛书的著录不同造成的重复数据给数据用户使用带来困惑和不便,使用户需要仔细检查才能鉴别清楚,这不仅给数据用户的工作带来了麻烦,也不利于馆际互借;②就各成员馆及数据用户而言,在联合编目的大环境下,用户在使用数据时多是全盘套录,对内容修改较少,甚至仅加上本单位的馆藏字段信息,在这种情况下,如果编目人员对数据鉴别不认真、没有发现错误,那么这些错误的书目数据就会广泛应用于各图书馆或机构,影响到各成员馆和数据用户的馆藏书目数据库质量;③就读者而言,错误的(特别是题名和责任者著录错误的)、不规范的书目数据会影响读者查找文献的查全率和查准率,从而降低该文献的利用率。所以,本文将对联编中心书目数据存在的普遍性错误进行详细分析,并提出一些新的观点和对策,希望能与联编中心的其它成员馆及同行交流和讨论。
1 联编中心的数据存在的质量问题
1.1 未严格按照格式著录产生的错误
笔者在使用数据时发现,大部分数据存在着多处没有严格按照机读目录格式著录的问题。例如:①题名页存在其他语种并列题名,但很多数据的101字段缺少著录在$f子字段的与正文语种不同的题名页语种,如例1。②经过修订或以商业目的再版的学位论文或毕业论文在105字段应使用代码v,但几乎联编中心的全部数据都没有使用,如例2。③数据的102字段$b子字段著录的出版地区代码应采用GB2260中华人民共和国行政区划代码,但大部分数据的地区代码只对应到省级行政区划,没有准确标注出各地市对应的行政区划代码,如例3。④正文前页数超过10页的应予以著录,但很多数据只著录正文页码,如例4。⑤俄文字母应为全角字符,而不是英文的半角字符,其意思和读音不同,但几乎所有数据使用的都是大写的英文字母,如例5。针对这些情况,联编中心应重点提出存在的质量问题,以提醒各成员馆注意并改正。
例1:《统计学》,ISBN为978-7-111-29027-8,题名页有并列英文题名,101字段应有$f子字段。

例2:《美国次贷危机引发全球金融危机的思考》,ISBN为978-7-5058-8482-3,后记里写道:“本专著正是在我博士论文的基础上修改完成的。”可见该书是修订过的学位论文,105字段应给代码v。

例3:《内衣应该这样穿》,ISBN为978-7-5459-0150-4,出版社是厦门的鹭江出版社,其出版地区代码应为:350200。
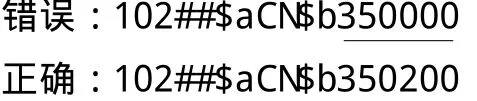
例4:《最值得铭记的800个中国之最》,ISBN为978-7-80179-903-6,正文前有15页,应予以著录。

例5:《超声速飞机空气动力学和飞行力学》,ISBN为978-7-313-05627-6,作者应为俄文字母书写的“Г. С.比施根斯”。

1.2 字段和子字段的错字、漏字等
书名、丛书名、责任者、其他题名、外文题名、主题等字段和子字段的错字、漏字著录多是由编目员粗心大意造成的,其中错别字是数据中最普遍也最不应该出现的错误,这一般是编目员使用拼音输入法误选同音字所致,如例6。
例6:《政治经济学原理》,ISBN为978-7-81134-573-5,作者应为孙爱芹,但数据误题为孙爱琴。这是典型的输入同音字的错误。

1.3 分类号和主题词错误
6--主题分析块字段会因为编目员对某些文献内容理解不同而出现不同的分类号和主题词,联编中心的数据中就存在一些不可否认的错误。标引错误会造成揭示文献内容不全面甚至不正确,必须引起编目员的重视,如例7、例8。
例7:《西藏藏族人类学研究》,ISBN为978-7-5304-4205-0,分类号为K280.1/.7,依中国地区表分,西藏应为:75。

例8:《抒情女高音》,ISBN为978-7-5039-3653-1,应用规范主题词“女高音”代替“抒情女高音”。

1.4 责任方式错误
责任方式错误在以前的编目工作中并不多见,但最近发现此类错误比较多。责任方式错误主要表现在200字段责任方式著录错误或与7--字段知识责任块的责任方式著录不一致,如例9。
例9 :《美国国家安全战略解密文献选编》,ISBN为978-7-5097-1182-8,数据中200字段是“周建明,王成至主编”,但第2个701字段的责任方式却变成了“著”。

1.5 缺少著录项目和著录单元(字段和子字段)
联编中心的书目数据编目等级是完全级,表示机读目录完整及编制时曾核对过编目实体,所以著录的书目数据要全面地揭示文献信息,尽量避免因为疏忽而造成的著录格式不完整。如例10、例11。
例10:《收藏品投资》,ISBN为978-7-5058-8963-7,题名页有英文题名,但数据既没有著录101字段的$f子字段,也没有著录510字段的并列题名。

例11:《会说日语的170个理由》,ISBN为978-7-5062-9563-5,缺少305、312、517字段。

1.6 编码字段错误
编码信息块的错误大部分集中在100字段和105字段。100字段的错误多是出版时间与210字段的$d、$h子字段不对应,如例12。105字段除上文提到的没给学位论文代码外,还经常忽略掉会议代码、索引代码、文学体裁代码和传记代码,如例13、例14。
例12:《失眠防与治》,ISBN为978-7-5605-3357-5,出版年应为2010年,但100字段的出版时间误录为2009年。

例13:《水力学与水利信息学进展》,ISBN为978-7-5605-3262-2,其内容提要为:“本书收录了第四届全国水力学与水利信息学大会的部分论文……”由此可知,此书是会议出版物,应给会议代码1。

例14:《明日之城:一部关于20世纪城市规划与设计的思想史》,ISBN为978-7-5608-4039-0,正文后面有索引和插图索引,应给索引代码1。

1.7 内容提要的质量问题
330字段内容提要的某些地方或许不能算错误,但存在的质量问题较多,表现为:①错别字、标点符号错误或出现多余的空格;②表述过于敷衍,有的甚至直接罗列章节;③行文不考究或出现张冠李戴的现象。
例15:《Web站点优化》,ISBN为978-7-111-26908。
书目数据的330字段为:本书为您提供了众多来自首席专家们的意见,囊括了在线营销和网站性能提升技术两方面内容,帮助您最大化有效流量、加速用户响应并最终提高销售额。
建议改为:本书包括在线营销和网站性能提升技术两方面内容,论述如何最大化有效流量、加速用户响应并最终提高销售额。
例16:《启功论艺》,ISBN为978-7-80725-887-2。
书目数据的330字段为:本书从启功《论书绝句》中遴选了最能代表先生论书观点的代表诗作35首、《论书札记》(全篇)及《书法入门二讲》(全文),并从4个方面撰写了数万言的“导读”。
这是《启功论书》的提要,并非《启功论艺》的提要。应改为:本书收录了作者的书法论文、鉴定论文、题跋、论画的文章、绘画生涯的亲历、实录和切身感悟、学艺往事、以书画为主题的诗词和人生感悟的代表文章。
2 联编中心书目数据质量问题产生的原因
2.1 没有统一的图书著录细则
联编中心的各成员馆各自执行本馆的编目细则,没有编目数据制作的统一规范。虽然大多数成员馆的编目细则都是以《新版中国机读目录格式使用手册》和《中国文献编目规则》(第2版)为基础建立的,其大方向一致,但对细节问题的不同理解造成了编目结果的差异。
2.2 联编中心对数据监控不完善
目前,联编中心采取了定期检查、反馈信息、加强业务辅导、年底评价性检查等措施来控制质量,这些措施固然起到一定的积极作用,但仍未能改变数据质量参差不齐及数据重复的现象。笔者认为,这些措施不够强硬,奖惩也不够分明。
2.3 重视速度,对数据质量把关不严。
在各联编中心分中心、成员馆的共同努力下,书目数据的时效性有了较大提高,不但下载量增长迅速,上传量也逐年增加,由 2004 年的 29 818 条书目数据增加到 2008年的 135 954 条(包括少儿图书馆中心回溯数据)。但同时,成员馆为了追求上传的速度有时会过于简单地制作书目数据,对文献没有进行深层次的揭示,甚至只按照图书在版编目(cataloging-in-publication)数据简单著录和标引,导致出现一些本不应该出现的错误,如使用非规范词汇进行主题标引,分类号存在明显差错。
2.4 编目员、校对员的综合素质和职业水平良莠不齐
由于待编文献种类繁多、学科内容复杂,编目员、校对员不可能对所有的学科知识有全面、精准的了解,这必然使分类主题标引有偏差。另外,编目工作者的职业素养和责任意识也直接影响到编目数据的质量,疏忽其中任何一个环节都会造成编目工作中的失误。其中校对员是数据质量控制的关键,校对人员如果缺乏高度的责任心、对书目数据没有按要求严格审校,也将导致书目数据出现错误。
3 提高联编中心数据质量的对策
3.1 制定统一的中文图书机读目录数据处理细则
编目细则是中文图书分编工作的核心业务规则。联编中心应尽快将中文图书机读目录数据处理细则修订完毕,细化编目规则,明确机读目录格式,指导中文图书标引规范。只有对编目细则进行统一,才能使编目工作有章可循、有本可依,使编目数据更为标准化和规范化。
3.2 建立分明的奖惩制度,加强对成员馆的质量监控。
3.2.1 强调质量与速度并重,建立奖惩制度。
编目工作不能只注重速度,还要进一步提高编目质量。联编中心可把各成员馆的上传数据差错率按从高到低的顺序排名并予以公示,对数据质量优秀的成员馆应予以公开表彰以树立榜样,对经常反馈数据库数据质量问题的成员馆给予奖励,同时也应扣减该数据上传馆的上传数据费。
3.2.2 引入“扣分制”, 加强对成员馆的质量监控。
笔者大胆设想将驾驶证的扣分制度运用到质量控制中。例如,上传馆都是要经过严格审核才具有上传资格的,如果每月或每季超过一定的差错率则扣减其分数,当分数为零时取消其上传资格,需要再经过重新考查才能“持证上岗”。这种做法对各成员馆形成无形的压力和动力,将大大提高各成员馆对编目工作的重视,从而更进一步保证高质量书目数据的上传。
3.3 培养优秀的编目员、校对员,加强审校机制。
3.3.1 成员馆有责任通过各种途径提高一线编目人员的综合素质
成员馆应制订编目人员培训计划,通过编目论坛、业务培训及继续教育等方式提高编目员、校对员的专业水平和综合素质。
3.3.2 共同提高校对员的责任感和专业水平
校对员要有过硬的业务能力和高度的责任心,发现错误要及时修改,对于有不同意见的问题大家应共同讨论,排除疑难,统一分歧。
3.3.3 加强审校机制,控制差错。
采取两级校对及差错率统计措施,提高编目员和校对员的工作水平。例如,规定编目员差错率不得超过5%,校对员差错率不得超过1%。总审校每月底要从MARC格式到著录、分类、主题标引、名称规范等各方面抽查校对人员完成的数据,将差错记录后交到当事人手中。差错记录对编目员和校对员全面公开,提高查错工作的透明度和有效性。
3.3.4 调动编目员、校对员的积极性
差错率要和编目员、校对员的经济利益挂钩。对于连续半年差错率超过规定的校对员,取消其校对资格。同时,每年度评选“最佳编目员”和“最佳校对员”并给予适当的奖励,从而树立先进典型,促进编目员、校对员业务技能的提升。通过这一系列奖惩分明的举措,提高编目员、校对员的工作积极性,有效地防止编目员、校对员工作中的松懈态度。
3.4 建立月结报送制度,定期向联编中心提交数据质量反馈。
联合编目数据的质量需要成员馆的共同维护,各成员馆应积极投入到数据质量控制工作中,向中心及时、详细地反馈共享数据的质量情况,提交错误数据报告,如例17。此举能及时发现错误、修改错误,进一步提高联编中心数据库的数据质量。
例17:ISBN为978-7-80214-522-1,题名应为“荒漠甘泉”,但2010年2月20日的数据误题为“荒漠甘露”,广东省分中心在2010年6月的月结报告中指出该错误,此数据于2010年7月19日修正。

4 结 语
截至2010 年5月,联编中心的直接数据用户已累计达1 171 家,成员馆724家;书目数据的下载量由 2005 年的156 万余条增加到 2009年的 245 万余条[1]。由此可见,联编中心数据库的质量会直接影响到各成员馆的书目数据库质量,在某种程度上也影响了我国图书馆界书目数据库的质量。所以,联编中心有必要采取更有效的措施提高书目数据库质量。只有加强了书目数据库的质量控制,才能打造一个数据最全、质量最优的数据库典范,才能更方便地服务于各成员馆,才能更有效地促进联合编目事业的建设和发展。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
都市人(2022年3期)2022-04-27
天一阁文丛(2020年0期)2020-11-05
戏曲研究(2017年3期)2018-01-23
图书馆学刊(2015年8期)2015-12-26
西藏科技(2015年1期)2015-09-26
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
中国民间疗法(2012年1期)2012-07-27
