
基于DSP的多方会议系统的混音方案
2011-03-06 09:17陈凤伟
通信技术 2011年3期
陈凤伟,陈 光,陶 翠,靳 超
(东华大学 信息科学与技术学院,上海 201620)
0 引言
近年来,随着信号处理算法、网络结构优化、硬件处理能力方面的不断发展,多媒体语音通信已经迅速普及。多方音频电话会议产品是多媒体通信系统的基本模块,作为有多个终端参与的音频电话会议,可以采取令牌控制或轮询控制下的互斥模式,即只有拥有发言权的那个与会者才可以讲话,这样每个与会者某一时刻只能听到一路音频信号,显然这种半双工情况是不方便和不实用的。更多的时候,需要采用自由参与的讨论方式,为了能够在每个终端同时接收多个与会者的声音,必须采取多路音频混音与交换技术,而音频混音算法则是其中的关键技术[1-2]。随着DSP技术的不断发展和进步,由于其具有容量大、成本低、升级灵活等优点,采用通用DSP实现多方电话会议的混音,逐渐成为首选方案。
1 混音算法的原理及实现
1.1 混音的理论依据
声音是由于物体振动对周围的空气产生压力而传播的一种压力波,转换成电信号后,再经过抽样、量化,量化后的语音信号的频率与声音的频率对应,振幅与声音的音量对应,所以当各信号的抽样频率一致时,混音可以实现将各信号的采样数据进行线性叠加[1]。在时域上,语音是短时平稳信号,对语音信号进行处理的一个基本概念就是对语音样本以缓冲区为单位处理,即对输入的语音样本分帧。当多个音频同时播放时,人耳听到的声波就是各个声源的波形的线性叠加,这正是模拟混音的基础。这个事实说明数字音频的混合也应该是音频的线性叠加。而线性相加又可能产生溢出,溢出现象是由于受到语音数据表示精度(8 bit或16 bit)的限制而产生的,而精度是由相应编码器的硬件特性所决定的。对溢出的语音波形进行平滑处理不会改变语音的音质和内容,因为语音信号具有短时相关性(10~30 ms)[3]。
1.2 现有混音算法分析与比较
现有混音算法的方案有很多,但是基本思想都是一致的。混合算法的基本思想是:首先将解码后的多路语音数据进行线性叠加,然后对叠加后的语音数据进行溢出检查,并对含有溢出数据的混合语音包的语音样本进行滤波处理,采用平滑技术消除叠加溢出所引入的噪声[4]。具体的说,混音算法主要完成以下功能:
(1)线性叠加
若有N路音频数据需要进行混音处理,混音的时候,需要屏蔽某一路自己的本地音频数据,这样就不会听到本地的自己的声音,只能听到其他N-1路的声音,也就是说,对于第t路音频,要发送给这个终端t的混音后的数据如公式(1)所示:
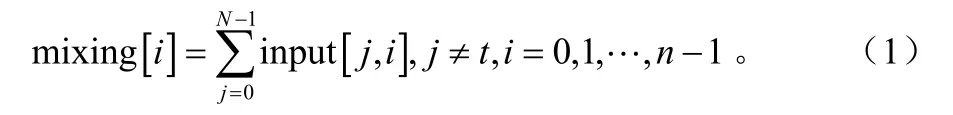
其中mixing[i]为混合后一帧中的第i个样本,input[j, i]为j个用户帧的第i个样本,n为一帧的样本数目,N为会议的与会者个数[3-4]。
(2)溢出判断与平滑处理
将混音后的话音数据与硬件设备允许的极限范围的最大与最小值相比较,若存在超出此范围的数据,表示该混合语音包有溢出,则需要进行平滑处理来消除因溢出所引入的噪声。现有的混音算法如均值混音算法、对齐混音算法、箝位混音算法等都是根据选择不同的权重来防止输出的结果发生溢出,但是这些现有的混音算法都有其不可避免的缺点[1]。其中,均值算法的权重是将采样数据线性叠加后取平均值,但是随着混音的路数的增加,各路语音的衰减将愈加严重,最终导致语音细不可闻。对齐算法的权重是各路音频流中当前帧中采样值的最大值与累加结果中采样值的绝对值的最大值的比值,但是这种算法没有考虑到累加结果的绝对值可能超出硬件所允许的极限范围,从而导致溢出[1,5]。箝位算法实现简单,当发生上溢时,箝位以后的值为其所能表示的最大值,当发生下溢时,箝位后的值为其所能表示的最小值,如式(2)所示:
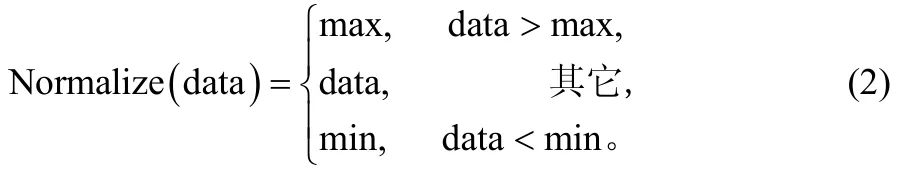
但是,如果在混音路数较多时,溢出的概率就会较大,随着混音路数的增多,导致音量的变化十分明显,此算法适用于小规模、混音路数变化不大的会议中。现在很多现有的论文和系统都是采用箝位方法,因为实现简单,快速,效率很高。但是可以看出,这种箝位方法相当于在最大和最小的临界处切了一刀,非常生硬,会造成较大的波形失真,引入了噪声[3]。
1.3 改进后的混音算法
通过对现有混音算法的分析可以看出,变化的混音权重是导致混音后音量不稳的主要原因,在此基础上,这里提出了一种采用与混音输入路数无关的恒定混音权重的混音算法。
算法的基本思想是:先将所有与会者的语音信号进行混合,变成一路混音信号;再用混音信号与所对应用户的语音信号分别相减,得到除该用户自己以外的所有其他用户的混音信号,然后将此混音信号转发给该用户,这样就实现了所有参会者之间的语音交换。假设某一多方会议系统有k个与会者,即有k路音频输入,一般地,定义第i路输入为 input(i),其在所有路的输入中对应的权重为 w(i),这样经过混音后,总的输出output如下式(3)所示:
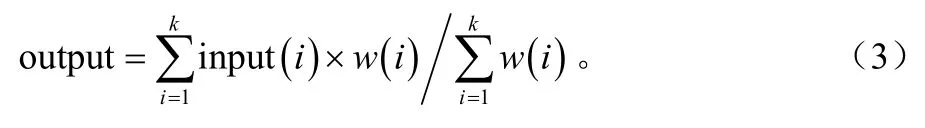
第 i个与会者所能接收到其他与会者的音频输出输出output(i)如式(4)所示:
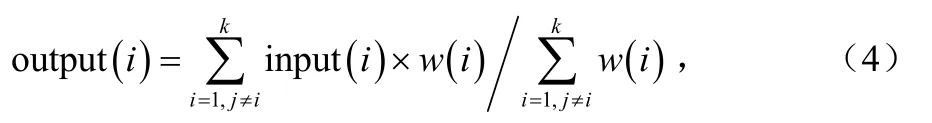
点混音时的高性能、高实时性,同时也保证了参与混音的各路输入的时域细节特征,因此具有很好的听觉舒适感和连续感[1,6]。
2 用DSP实现混音算法
选择通用的16 bit定点DSP TMS320VC5402来完成多路音频流的混音,最多可以实现 64路音频流的混音。由于该算法的数据来自ST-BUS链路送来的某一用户时隙的8 bit A律PCM话音数据,因此需要先将其变为线性码,然后才能进行混音,DSP输出时再变回A律的PCM码流发送出去。DSP数据处理流程图如图1所示。
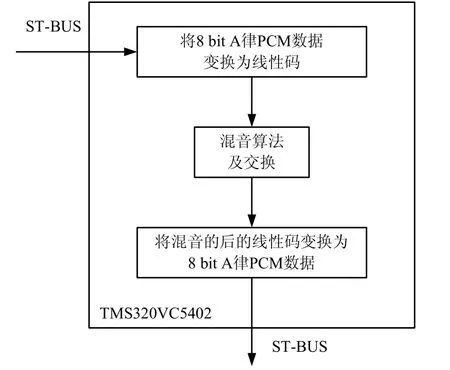
图1 DSP处理数据流程
基本原理是 DSP同时启动 McBSP的收发端口,当McBSP的接收端口收到ST-BUS链路送来的第M帧对应于某一用户时隙的8 bitA律PCM话音数据后,然后在线性码的右端补上 3 bit的 0送给接收寄存器 DRR1,这是因为TMS320VC5410是16位的,只能对片上RAM按16 bit访问,线性码转换完后McBSP通知分配给它的接收DMA控制器,此时,DRR1的数据已就绪,接收DMA控制器立即将此16 bit数据按照其对应的地址写入接收缓冲区中。在配置DMA时,在分配给它的数据缓冲区达到半满和全满时,向 DSP内的CPU发送中断,因此DMA接收完第M帧话音数据后向CPU发送中断。当CPU收到DMA中断时,表明DMA已经接收到了第M帧所有时隙的数据,CPU在第M+1帧的期间依据这里提出的算法对接收到的数据进行处理,然后在第 M+2帧时发送DMA控制器从它的数据缓冲区内依次读出相应的数据送给 McBSP的发送端口,发送端口首先将此线性码语音数据转成A律语音数据,然后完成PCM话音数据发送[6-7]。
3 实验结果
现对这种算法进行了实际试验,图2为1路解码后的语音输入,图3为另一路解码后的语音输入,图3为采用这里提出的混音算法得出的1路混音输出。
根据与现有的混音算法比较,混音后的音频流自然、连续,也没有溢出所导致的爆破噪声,在测试中,随着混音音频流的增加,改进的混音算法的性能改善也越发明显,说明该混音方案完全可以适用于人数较多的混音环境。

图2 解码后的语音输入1
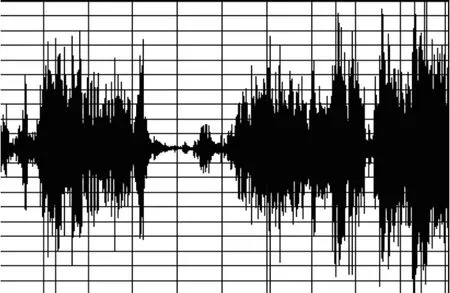
图3 解码后的语音输入2
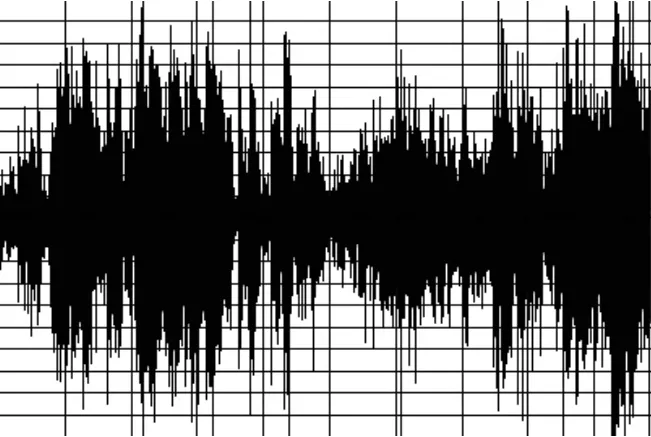
图4 改进混音算法的输出
4 结语
这里所提出的算法,采用了与混音路数无关的恒定的混音权重,混音效果理想,并且不会发生溢出现象,通过用DSP实现验证,混音后语音自然流畅,没有噪音,具有良好的主观听觉感受,而且该算法简单、实时、快速,能够满足多方会议中高性能、高并发的混音要求,能支持大规模的混音应用,容易采用硬件实现。这种混音方案不仅能够满足一般应用场合的实际要求,而且在具有高并发量要求的混音时应用该算法也能获得高质量的实时混音结果。它不仅保证了在多路混音时的高性能,而且具有很高的实时性。
[1] 王文林,廖建新,朱晓民,沈奇威.多媒体会议中新型快速实时混音算法[J].电子与信息学报, 2007,29(03):90-695.
[2] 王崇,周渊平,王维果.基于DSP的语音时延估计实现[J].通信技术,2010,43(11):61-63.
[3] 张微,毛敏.多方电话会议系统中混音溢出问题的一种改进算法[J].电子器件,2007,30(01):294-296.
[4] 赵代强.基于数字语音交换技术的多方会议系统[J].网络与通信,2004,30(13):87-88.
[5] 熊堃,陈向东,葛林,等.针对无线语音通信的G.729算法的改进及DSP实现[J].通信技术,2010,43(06):219-223.
[6] FAN Xing, GU Weikang, YE Xiuqing.Research on Fast Real-time Adaptive Audio Mixing in Multimedia Conference[J].Journal of Zhejiang University-Science A.2005,6(06): 507-512.
[7] 张玉业,邓勇全,李玲远.语音编解码算法 G.729的软件实现[J].通信技术,2002(02):4-6.
猜你喜欢
家庭影院技术(2018年11期)2019-01-21
演艺科技(2018年7期)2018-11-19
电子制作(2018年19期)2018-11-14
电子制作(2017年9期)2017-04-17
演艺科技(2017年2期)2017-03-30
人间(2015年8期)2016-01-09
民间故事选刊·上(2001年3期)2001-06-14
