
商家评论的情感分类研究和应用
2011-03-11 09:02袁立宇鞠久朋杨豪杰宋平波
电信科学 2011年6期
袁立宇,鞠久朋,杨豪杰,宋平波
(1.中国电信股份有限公司广东研究院 广州 510630;2.海量信息技术有限公司 北京 100190)
商家评论的情感分类研究和应用
袁立宇1,鞠久朋2,杨豪杰1,宋平波1
(1.中国电信股份有限公司广东研究院 广州 510630;2.海量信息技术有限公司 北京 100190)
大多数基于有指导机器学习方法的情感分类采用N元(n-gram)词袋(bag-of-words)模型,使用二值(binary)作为特征项的权重。本文系统地分析了信息检索中常用的特征权重计算方法,并从项频、倒文档率、归一化因子等角度加以借鉴和改进,研究其在商家评论上的应用。最主要的改进在于考虑了特征项在不同类别中分布情况的差异以及对倒文档率的平滑。在餐饮评论语料上的实验结果表明,经典的tf·idf若干变形,尤其是倒文档率类差异(delta idf)及平滑因子(smoothing factor)的引入,能有效提高分类准确率。在酒店、电脑、书籍等领域的在线评论公开数据集上也取得了较好的性能,证明了方法的普遍适用性。这一方法目前已经在中国电信“号码百事通”业务中用于餐饮商家及优惠券推荐,效果良好。
商家评论;消费偏好;情感分析;褒贬分类;特征权重
1 引言
移动互联网的普及助推了Web 2.0技术的发展,用户由当初PC时代简单接收互联网上的信息,向主动发布交互信息转变。产生的评论数据正以指数级的速度在增长,这些评论包括对商家品牌、服务和产品的评论。如果对这些用户主动发布的评论进行数据挖掘,判别情感倾向,就能更好地了解用户的消费习惯、分析热点舆情,给商家提供重要的决策依据。因此,情感分析(sentiment analysis)已经成为自然语言处理研究中的热点。情感分析又称意见挖掘(opinion mining),是指通过计算机手段,帮助用户快速获取、整理和分析相关评价信息。
目前,按照处理文本粒度的不同,情感分析可以分为词语级、短语级、句子级、篇章级以及多篇章级等几个研究层次。按照处理文本的类别不同,可分为基于产品评论的情感分析和基于新闻评论的情感分析。按照研究任务的不同,可以分为3项层次递进的研究任务,即情感信息抽取、情感信息分类以及情感信息检索与归纳。本文主要研究情感信息分类中情感表达的褒贬二元分类问题。
基于特征的机器学习是情感分类的主要方法。在基于有指导机器学习方法的情感分类研究中,特征项的权重设置大部分采用二值法。本文借鉴了信息检索中tf·idf的权重计算方法,分析其若干变形,系统地研究了特征权重对篇章级情感分类的作用,在餐饮类评论语料上取得了良好的性能,并在多个领域的公开数据集上实验证明其普遍适用性。
2 相关工作
一般而言,研究者将主观本文的情感极性分为褒义和贬义两类。学术上一般认为,对情感分类比较系统的研究工作始于Turney[1]基于无指导学习(un-supervised learning)对多个领域评论情感倾向性分类以及Pang等[2]基于有指导学习(supervised learning)对电影评论进行情感倾向性分类。纵观目前的研究工作,可分为两种研究思路:基于情感知识的方法以及基于特征分类的方法。
一部分学者通过考察文本内部情感知识的属性来完成情感分类。Turney利用点对互信息(PMI),通过计算文本中抽取的关键词和种子词的语义相似度来判断关键词的情感极性,从而预测整个句子(篇章)的情感倾向性。也有学者构建情感模板判别情感文本的情感倾向。上述基于情感知识的情感分类方法的工作重心在于情感文本中情感知识的挖掘以及各种情感知识融合的方法研究。
还有一部分学者将情感分类定义为一种二元分类任务,即对任意给定的情感文本单元,由分类器协助判断其情感极性。Pang等使用朴素贝叶斯、最大熵、SVM等算法,考虑了unigram、bigram的二值及项频等特征权重,对影评进行分类,其结果显示基于SVM算法的unigram二值权重取得了比较好的效果。基于特征分类的方法目前还是情感分类的主流方法。这种方法定义明确,其根本问题在于特征的选取。因此尝试使用更深层、更复杂的分类特征也许是这类方法的突破方向之所在。
其后的基于机器学习的特征分类方法的研究大多是基于此,算法的改进主要在对文本的预处理和特征的选择。一个重要的预处理是检测出主观性评论 (句子),Hatzivassiloglou等[3]表明主观性检测往往比情感倾向性分析更为困难。Pang等后续的研究也表明,对删除客观性句子后的评论作情感分类的精确率比对整个文本作分类高。Li等[4]提出了情感极性转移结构(polarity shifting structure)用于发现情感转移特征(如否定、对比、转折等),从一定程度上提高了分类性能。
目前,基于特征的方法的研究重点在于有效特征的发现、特征选择以及特征权重等问题的研究。其中特征权重的研究是重要突破点之一,本文的研究就是基于此,从信息检索理论中借鉴和改进特征权重的计算方法,并将其成功应用于情感分类。
3 特征权重研究
文档D用词袋(bag of words)的特征向量表示法,可记为D={w1,w2,…,wr}。其中r为词典的维度(特征项项数),wi,i=1,2,…,r为项 i(一个 n-gram单元)在文档D中的权重。Pang等实验表明,采用unigram的二值的权重(当tfi>0时,wi=1;当tfi=0时,wi=0。其中tfi为特征项出现的频率),用SVM分类器,取得了最好的性能。与文本分类相比,一个有趣的现象是,简单地使用tfi的权重往往会导致性能的降低。
这一部分将说明经典的tf·idf权重计算方法,并在此基础上扩展其若干变形,包括类差异idf、SMART和BM25算法,并介绍其在情感分类领域的应用。这一部分,包括实验部分都是采用unigram模型,但是,特征权重计算方法的概念可以很容易地扩展到n-gram模型,本文将不作特别说明。
3.1 经典的 tf·idf权重
在信息检索中,经典的tf·idf计算方法赋予文档D中项i的权重为:
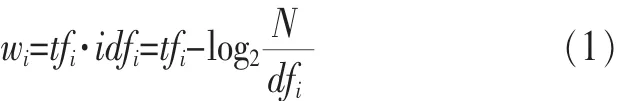
其中,tfi为特征项在文档中出现的频率,idfi为倒文档率(inverse document frequency,IDF),N为训练集合中总的文档数,dfi为含有项i的文档数。
在分类问题中使用项频是很直观的,因为项在文档中出现的频率越高,该文档属于某一类的概率就越大。但正如先前讨论,在情感分类领域往往会带来性能的下降。另一方面,在信息检索中,使用倒文档率的作用是降低类无关项的权重(如停用词),提高只在少量文档中出现项的权重。但是,倒文档率仅提供了项在所有文档中的分布情况,而没有考虑项在类与类之间分布的差异性。
3.2 类差异 tf·idf
鉴于以上对idf的讨论,类差异idf主要衡量特征项在某一类与在其他类分布情况的差异。因此,项i在文档D中的权重为两者之差,即:

其中Nj为训练集合中属于类别cj的文本数目,dfi,j为类cj中包含项i的文档数。
但是,这种计算方法也存在着缺陷,它没有提供任何对dfi,j的平滑因子。因此,当特征项仅在某一类或都在其他类出现时,dfi,j=0,会带来灾难性的错误(如被零除或求零的对数)。
3.3 SMART 和 BM25 的 tf·idf变形
SMART[5,6]是一个基于特征向量空间模型(vector space model,VSM)的信息检索系统,它提出了若干tf·idf的变形。主要从项频、倒文档率、归一化因子等3个角度考虑,分别见表1、2、3的前几行。
其中,maxt(tf)是该文档中所有项出现频数的最大值;avg_dl是所有文档中,文档项个数的平均(平均有效特征维度)。最后一行是BM25算法,参数k1和b均被置为默认的 1.2 和 0.95。注意到,在 L(对数平均)以及 o(BM25)的项频计算方法中,新引入了平均文本长度avg_dl这一因素,这是因为长文本通常有更大的项频,从一定意义上对项频作了归一化处理,使得统计更为合理。

表1 项频tf的若干计算方法
表2的前3行是常见的形式,第4行是BM25的形式,其余行是考虑了类差异(△)和平滑因子(’)的变形,具体细节在后面介绍。

表2 倒文档率idf的若干计算方法

表3 归一化因子
这里,归一化因子取余弦距离(cosine distance)。
SMART系统特征权重计算方法的每个形式都由3个字母表示,第一个表示tf的若干变形,第二个表示idf的若干变形,第三个是归一化因子。这样,权重就有6×9×2=108种不同的计算组合。如bnn表示二值的特征权重(boolean tf No idf No normalization,bnn),原始的项频的权重可记为nnn,带有归一化因子的项频权重记为nnc,BM25的权重就记为okn。
3.4 SMART和BM25的类差异变形
这里,沿用参考文献[7]对SMART和BM25的倒文档率所作的类差异扩展,用希腊字母“△”表示类差异的计算方法,用重音符号“’”标记平滑后的权重,见表2最后几行。
例如,o△(k)n表示的权重为使用BM25的tf以及类差异 BM25 的 idf方法,式(3)为:
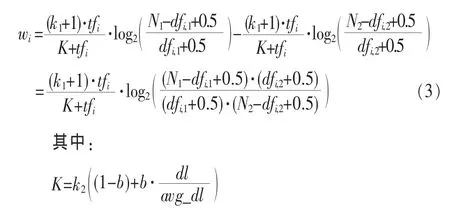
由于BM25算法本身已经带有平滑因子,△(k)默认就是平滑的,因此没有平滑变形。笔者对上述公式根据参考文献[8]作了部分修正,如表2最后一行。主要出于以下两点考虑:首先,当dfi大于1时,在改进的版本中,平滑因子对最终idf值的影响会比较小,因为它加dfi与Ni在乘积之后;其次,当dfi=0时,平滑因子正确地作了小部分修正,避免了潜在的被零除的风险。
4 实验结果与分析
笔者在中国电信“号码百事通”业务中的餐饮类中文评论数据上做了实验,并在多个领域的公开数据集上作了验证。前者主要是验证其可行性,后者侧重于说明方法的普遍适用性。
4.1 实验设置
采集到的餐饮类评论共计1万条,来源于点评网(www.dianping.com)与口碑网(www.koubei.com)。经过标注人员手工标注后分成两类,其中含有正例6718条、负例3282条。为了使正、负例数据样本均衡,一次性随机抽样两类各3000条作为实验数据。另3个领域的评论数据包含从携程网(www.ctrip.com)抓取的酒店评论、从京东网上商城(www.360buy.com)抓取的电脑(笔记本)评论以及从当当网(www.dangdang.com)抓取的书籍评论[9]。这3类语料都是经过去重后的平衡语料,每类语料均含有正、负例各2000条。语料的一些信息见表4。

表4 多领域语料信息统计
对中文的分词,使用海量分词系统。选用支持向量机的SVMlight[10]实现作为分类器,所有参数均为默认。为了易于对比起见,不作复杂的文本预处理,如常见的繁简转换、去除英文单词、保留指定词性列表中的词性、去除停用词等,仅去除了符号字符,对分词后的结果抽unigram特征。
由于tf、idf的变形较多,不同的组合有108种,限于篇幅,只对具有代表性的组合做了实验,并展示了性能较好的若干组合结果。一般而言,对于没有平滑的类差异idf,采用了归一化因子,因为它们通常比没有归一化的表现要好;对于平滑的,不对其作归一化处理,因为主要关注平滑的性能。经过这样的筛选,每类数据设计了13组有代表性的、相同参数的实验,见表4第一列。
为了从训练集中获得较为精确的idf信息,所有实验都是基于leave-one-out的交叉验证,而不是常用的n-fold(特别地 n≠N1+N2,其中 N1、N2分别为正、负例的样本数)。主要是因为idf及类差异idf是项固有的属性(经验值),且只能从训练语料中获得(无法在测试集中获得),训练语料数量越多,统计结果就越精确。这里,测试集合上项的idf被假定为与训练集合中的分布情况一致。
4.2 实验结果与分析
根据上述实验设置,在餐饮、酒店、电脑以及书籍等4个领域的数据上做了实验,实验结果见表5。第一列是权重计算参数的选择,其余列为不同的数据集。
为了更直观地展示实验结果,表4对应的柱状图如图1所示。
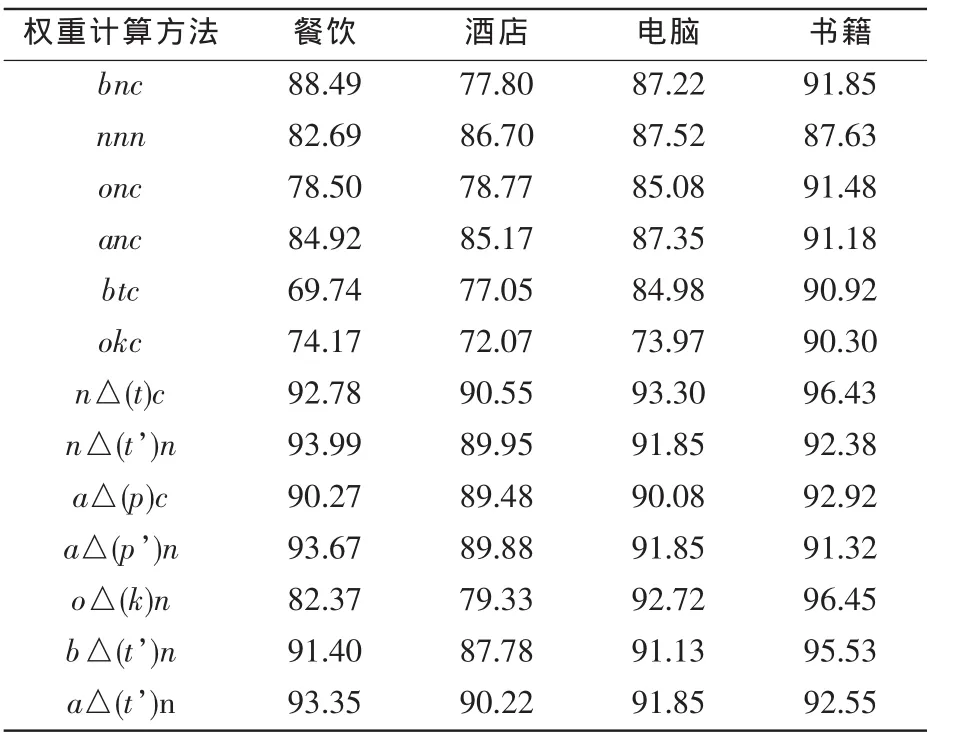
表5 评论情感分类准确率(%)

图1 4类数据实验结果柱状图
以下将就各个类别上的实验结果加以分析。
在餐饮类数据上,实验结果再次表明二值的特征权重(bnc)比直接的项频(nnc)(82.71%)性能要好。在简单的 tf设置(nn)中,归一化因子(c)的作用微乎其微(nnn 82.69%vs.nnc 82.71%)。tf的若干变换(o、a)也没有能明显的效果改善,甚至导致性能的下降。更为有趣的是,在信息检索中表现良好的BM25算法,在这里的性能却一般。idf的若干全局变形(t、k)在餐饮类上也没有新的贡献。考虑了类差异idf及平滑因子的若干变形(除了△(k))都对性能带来了较大幅度的提升,最高可达到5.5%(93.99%~88.49%),且提升的性能相当。对比数据可以看到,平滑因子起到了积极的作用(n△(t)c 92.78%vs.n△(t’)c 92.98%,以及 n△(t)n 93.57%vs.n△(t’)n 93.99%)。除此以外,作了归一化处理的性能反而比没有作归一化处理的性能差,这种复杂的计算并没有带来应有的效果。在性能较好的各种类差异 idf及平滑变形中,tf的 n、a、b,idf的 t、p 及平滑因子的引入,都对性能提升起到了重要的作用。
在酒店的评论中,各种组合的分布情况与餐饮类的数据大致相同。这里,tf的性能比二值的性能要好,且差距较大。也就是说,并不能直截了当地给出结论,究竟是二值的好、抑或是tf的好,在不同的数据集或不同的领域中,它们存在着差异性。但是不管怎样,从实验结果来看,类差异的idf变形以及对它们的平滑,使最终性能同样有了大幅度提升(从86.70%提升到90%左右)。
电脑(笔记本)领域的实验结果中,当选择 BM25的形式(okc)时,性能有较大程度的降低,其余权重计算方法基本保持相当的性能。除okc外,未考虑类差异idf与考虑类差异idf的性能百分点的方差分别为1.3167和0.9295,相对较小。
在书籍领域上测试的性能,虽然没有特别离群的结果,但是波动比较大,两组的方差分别为1.9462和3.8998。但是可以看到,在书籍领域的平均准确率比较高,最高的准确率达到了96.45%。在众多idf类差异的变形中,△(t)和△(k)与其他变形的性能差异尤为明显。
总体而言,类差异idf的引入,在各领域的数据上都显示了其对性能提升的重要性,且通常情况下,平滑因子对性能也能起到积极的作用。归一化因子的作用并不是很明显,考虑到其计算代价,在以后的实践中,归一化因子可暂不纳入考虑的范畴。就类差异idf的若干变形而言,△(t’)的变形表现出普遍适用的效果,BM25的变形所起到的作用,却不及其在信息检索中的作用大。
5 结束语
本文系统地研究了从信息检索领域继承和扩展来的特征权重的计算策略在商家评论情感分析上的应用。在多个领域的评论数据上的实验结果表明了该方法的有效性与普遍适用性。
本文的方法已经在中国电信“号码百事通”业务中微博客上的餐饮商家及优惠券推荐上实际得到了应用。这一推荐业务的框架包括根据用户所发表的博文生成用户兴趣概要(profile)的模块,用户兴趣概要与待推荐商品、服务的类别匹配以及待推荐商品服务的筛选等模块。其中,前两个模块使用了海量公司的基于知识树的关键词提取以及文本分类,待推荐商品服务的筛选应用了本文的情感分析方法。实际应用效果良好。
进一步研究在于,将提出的权重调整方法用于自然语言处理的其他领域,如文本分类、话题发现等,并将其从二分问题扩充到多分问题中。
1 Peter Turney.Thumbs up or thumbs down Semantic orientation applied to unsupervised classification of reviews.In:Proc of the 40th Annual Meeting ofthe Association for Computational Linguistics(ACL),2002
2 Pang Bo,Lee Lilian,Vaithyanathan S.Thumbs up Sentiment classification using machine learning techniques.In:Conferenee on Empirieal Methods in Natural Language Processing,Morristown,NJ,USA,2002
3 Vasileios Hatzivassiloglou,Janyce Wiebe.Effects of adjective orientation and gradability on sentence subjectivity.In:the International Conference on Computational Linguistics(COLING),2000
4 Li Shoushan,SophiaY M,YingChen,et al.Sentiment classification and polarity shifting.In: the International Conference on Computational Linguistics(COLING),2010
5 Salton G.The SMART retrieval system-experiments in automatic document.In:Processing of Prentice-Hall,Inc,Upper Saddle River,NJ,USA,1971
6 Gerard Salton,Chris Buckley.Term weightingapproaches in automatic text retrieval.Technical report,Ithaca,NY,USA,1987
7 Justin Martineau,Tim Finin.Delta TFIDF:an improved feature space for sentiment analysis.In:Proceedings of the Third AAAI International Conference on Weblogs and Social Media,San Jose,CA,2009
8 Georgios Paltoglou,Mike Thelwall.A study of information retrieval weighting schemes for sentiment analysis.In:Proc of the 48th Annual Meeting of the Association for Computational Linguistics,Uppsala,Sweden,2010
9 http://www.searchforum.org.cn/tansongbo/corpus-senti.htm
10 http://www.cs.cornell.edu/People/tj/svm_light
11 薛立宏,张云华,曹敏.移动互联网运营关键问题及商业模式探讨.电信科学,2009,25(5)
12 罗志强,沈军.移动电子商务用户溯源认证技术研究与应用.电信科学,2009,25(6)
Feature Weighting for Sentiment Classification of Online Chinese Reviews
Yuan Liyu1,Ju Jiupeng2,Yang Haojie1,Song Pingbo1
(1.Guangdong Research Institute of China Telecom Co.,Ltd.,Guangzhou 510630,China;2.Hylanda Information Technology Co.,Ltd.,Beijing 100190,China)
Most supervised machine learning method based sentiment classifications apply binary n-gram weights.In this paper,we systematically explore whether more sophisticated feature weighting schemes adapted from information retrieval(IR)can enhance the accuracy of sentiment classification for business reviews.Considered points of view are term frequency(tf),delta inverse document frequency(idf),and smoothing factor.Using restaurant reviews from the number wizard service created by China Telecom as experimental data show that,variants of the classic tf·idf scheme,especially incorporating of delta idf and smoothing factors,provide significant increases in accuracy.Tests on multi-domain public data sets indicate the universality of our approach.The proposed method has been implemented as effective application of restaurant recommendation system on China Telecom Number Wizard micro-blog.
business review, consumer preference, sentiment analysis, polarity classification,feature weighting
2011-05-13)
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
数学小灵通(1-2年级)(2021年4期)2021-06-09
当代陕西(2020年17期)2020-10-28
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
人大建设(2018年5期)2018-08-16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
信息安全研究(2016年4期)2016-12-01
