
动态文本会话抽取技术研究
2011-03-15 01:22张娅婷
电视技术 2011年11期
张 瑛,张娅婷
(湖南信息职业技术学院 计算机工程系,湖南 长沙 410200)
1 文本会话简介
随着网络聊天室以及聊天工具的普及,以新闻报道为代表的长文本已经不是人们获得信息源的唯一途径,博客、门户网站的新闻影响力正在降低,而网络论坛、微博、网络社群等新兴舆论载体异军突起。文本会话抽取就是针对此类动态数据,将属于同一会话的不同消息文本组织在一起,为后续工作(如话题的检测、网络社区发现、热点话题挖掘)奠定基础。
1.1 基本概念
相对于话题检测与追踪(Topic Detection and Tracking,TDT)中的基本概念,文本会话抽取中的相同术语被赋予了新的含义。
消息:会话讨论的参与者一次发表的言论信息,有一个或多个句子构成。如图1所示,动态文本流中消息相互交织在一起,按序到达。
会话:由讨论相关话题的一系列消息组成,起始于一个开始消息,跟随相关的回复消息,并结束于一个结束消息。
话题:一个种子事件或活动,以及所有与之直接相关的事件或活动。在文本会话抽取研究中,一般认为一个会话对应一个话题,一个话题可以包含多个会话。
会话抽取:从动态交织的文本信息流中检测出属于同一会话的消息。
会话在有些研究中也被称为线程,与操作系统中的线程的定义不同,文本会话中的线程是指一组相关的消息序列。同样,会话抽取在有些研究中也称为线程检测。

1.2 研究内容
与新闻报道的话题检测和追踪相比,动态文本会话抽取面临更大的挑战,主要研究内容有:
1)消息、会话模型
话题检测与追踪中的经典模型,如向量空间模型、LDA(Latent Dirichlet Allocation)模型等。向量空间模型在会话抽取中运用较多,但由于特征度量的限制并不明显,生成模型LDA针对短文本有天然优势,但目前在文本会话抽取中的运用较少。
2)模型特征信息度量
在向量空间模型中,TFIDF方法是针对静态文本词汇权重计算而设计的,直接用于动态文本会话流的权重计算存在很大不足。因而,找到更适合动态文本信息流的模型特征信息来表示词汇权重显得尤为重要。
3)语言学特征的利用
动态文本会话流中包含许多语言学信息,比如疑问句一般用陈述句回答。“再见”一般标识会话的结束。充分利用这些语言学信息挖掘上下文之间的关联对文本会话抽取具有十分重要的意义。
4)相似度的计算方法
相似度比较是决定两个消息是否属于同一会话的决定性因素,传统余弦相似度方法对处理短文本非常不利,并且在动态文本会话中,时间上相隔越远的消息讨论属于同一会话的概率越小,因此,计算相似度时必须考虑时间因素。由此可见,找到合适的相似度计算方法是文本会话抽取的核心所在。
1.3 评测方法
动态文本会话抽取对评测方法研究较少,大多数使用已有的方法,通常采用两种,一种是信息检索中准确率、召回率以及F度量指标。另一种则是TDT中的评测方法。
在信息检索系统中,准确率、召回率和F度量是经典的评估检索结果的度量指标[1],并适用于评估聚类算法的性能。由于TDT与文本会话抽取归根都属于聚类的问题,从而采用TDT的评测标准作为文本会话抽取的评测标准有很大的参考价值。在此,只给出准确率、召回率F度量的计算公式以及TDT中DET曲线的计算方法,详细内容参考文献[2],这里不再详述。
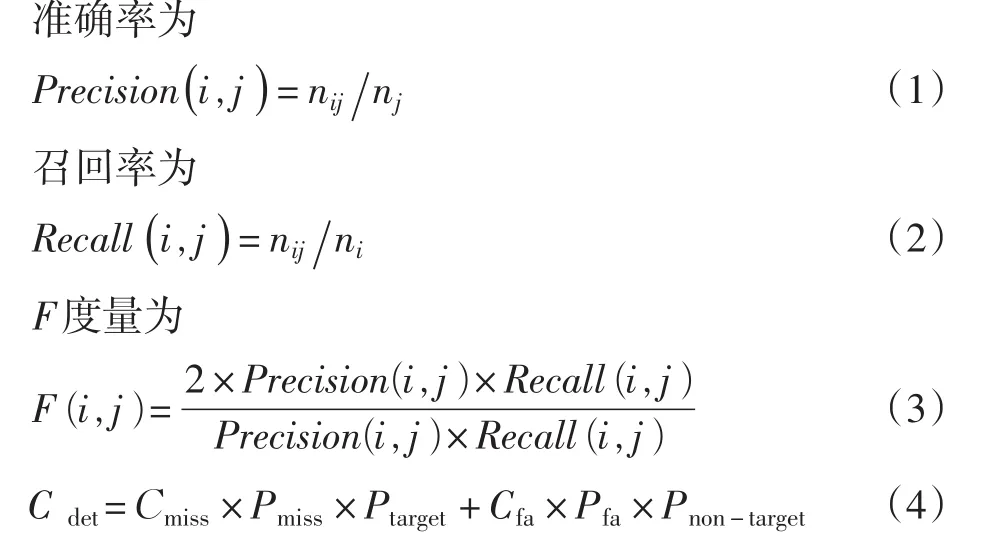
式中:nij为实际分类结果类j中分类正确的属于人工标注的类i的文档数目;nj为实际分类结果类j的文档数目;ni为人工标注的类i的文档数目;Cdet为系统的错误识别代价;Cmiss和Cfa分别是漏报和误报的代价,通常根据应用预先给定;Pmiss与Pfa分别是系统识别的漏报率和误报率,可由实际输出与标准答案的性对照结果计算得到;Ptarget是一个先验的目标出现率,表示关于某个话题的新网报道出现的可能性;Pnon-target=1-Ptarget。
2 统一研究框架
文本会话抽取的各个研究方面虽然采用不同的模型或者算法,但其系统结构仍存在内在统一性。对文本会话系统结构进行抽象,提出文本会话抽取统一研究框架,如图2所示。

从图2可以看出,文本会话抽取系统首先对消息进行预处理,去除噪声。然后建立消息和会话模型,并充分利用消息的文本内容信息和语言学特征,综合得到相似度值,并将最终相似度与相似度阈值比较,判断加入已有会话还是建立新会话。
接下来详细分析、比较图中几个主要模块的关键技术。
3 关键技术分析
从图2中可以看出,文本会话抽取统一研究框架中主要包括预处理、模型建立、相似度度量和相似度组织4个模块,其关键技术分析如下。
3.1 预处理
文本会话抽取系统首先需要进行预处理,且基于以下事实:1)动态文本消息不同于新闻报道,并不是每篇消息都在谈论特定的话题,并且部分回复简短不规则,存在拼写和语法错误,因此产生一些干扰性的噪音文本;2)中文网络聊天语言具有奇异性的特点[3],奇异性文本需要转换成标准文本才能为后面各个模块所用。
为此,文献[4]提出了一种基于社会网络的聊天数据噪声过滤方法,通过分析聊天数据的时序关系,推断出聊天用户间的社会网络关系,并根据用户交流特点判断并过滤噪声。另外,在文本层次上的噪声过滤主要有两种解决方案,第一种方案可以设置阈值,将太短的文本过滤掉。另一种解决方案为短文本,只参与会话抽取的聚类,而没有建立新会话的权限,从而保证了系统不至于因为噪声问题产生太多的会话。
3.2 表示模型
表示模型包括表示模型选取、特征度量以及模型本身的改进等。
向量空间模型是目前最简便高效的文本表示模型之一,作为TDT的主流表示模型,在会话抽取中应用也颇为广泛。向量特征的选取范围通常是对消息词集进行停用词过滤后的候选集合,其基本思想是:给定一自然语言文档D=D(t1,w1;t2,w2;… ;tN,wN),其中ti是从文档D中选出的特征项,wi是项的权重,1≤i≤N。这时可以把t1,t2,…,tN看成一个N维的坐标系,而w1,w2,…,wN为相应的坐标值,因而D(w1,w2,…,wN)被看成是N维空间中的一个向量。
特征选取会直接影响使用该模型的系统性能。目前针对会话抽取模型的研究大都是在向量空间模型基础上对特征度量的改进。
传统的特征度量包括TFIDF、TFIWF、信息互增益和熵等,其中TFIDF度量应用最广泛。如1.2节所述,传统TFIDF值在文本会话抽取中存在很大局限性。文献[5]运用增量改变TF和DF值的方法,使特征度量值随时间动态改变:dft(w)=dft-1(w)+dfCt(w),tft(d,w)=tft-1(d,w)+tfCt(d,w),有一定程度上提高了模型精度。文献[6]提出了一种专门针对聊天数据的词汇权重计算方法CDTF*IDF,通过分别计算词汇在不同数据源中的权值并汇总,同时对重点词汇提高权重等方式来计算聊天数据的词汇权重。除了TFIDF度量外,文献[7]提出通过知网抽取概念属性,用CHI-MCOR方法构建特征集合,文档信息由出现频率高的词和出现频率低但有重要意义的词组成,从而避免了重要词语被海量无用信息淹没。
会话模型一般对应于消息文档模型。在传统向量空间模型中,会话模型表示为各消息模型的向量和,所有消息文本对会话模型占有相同的权重。但动态文本会话对时间的敏感性使得在会话中新到来的消息对会话模型的贡献更大。文献[8]基于权重质心的Single-Pass算法中线性衡量随时间到来的消息的权重在话题检测与追踪的研究中,IBM提出动态改变话题项权重的方法,初始化IDF值为标准的与话题无关的IDF0,随着文档变化,IDF值不断调整,从而动态改变话题中项的权重。这对基于向量空间模型的会话抽取也同样适用。
3.3 相似度度量
相似度计算和表示模型关系密切,需要结合模型本身特点并充分利用表示模型的内容。一般来讲,会话相似度由两部分组成,一是文本内容相似度,二是语言学特征相似度。
1)文本内容相似度
由于话题发现与追踪中的相似度计算是针对新闻报道的内容而进行的研究,因而用于TDT中的相似度计算方式也同样适用于会话抽取中的文本相似度计算。对于向量空间模型计算方法很多,如Okapi公式、Clarity公式、Hellinger、Tanimoto等,其中余弦相似度最常用,也最有效。如果采用概率模型表示文档,如LDA,则常用KL(Kullback Leibler)相对熵来衡量主题之间的相似度。
2)语言学特征相似度
如上文所述,相邻消息间的语言特征并不是随机的,而是隐含某种隐形规则,这种隐含在上下文之间的关系用条件概率来标识。文献[8]引入了两种参考指标:句式和人称代词。采用M.STF和M.STL表示消息开始句和结束句的类型。用M.PPF和M.PPL表示消息开始句和结束句的人称代词,从而前后消息的条件概率可以用P(T(Mi,Mi)|Mi.STL,Mi.STF)和 P(T(Mi,Mi)|Mi.PPL,Mi.PPF)表示,通过贝叶斯条件公式及训练集的最大似然估计得到两个概率值,然后加权平均作为消息Mi和Mj的语言特征相似度。
3)最终相似度决定
消息文本最终相似度一般取决于上述两种相似度度量。文献[8]采用两者平均值作为最终相似度,文献[9]在此基础上引入了权衡因子,通过调整权衡因子的大小可改变各相似度所占的比重。除此之外,文献[5]提出了将用户活动作为相似度的一部分,并基于社会网络中的社区用户模型提出了UF-ITUF模型,动态改变会话抽取系统中用户活动的影响。文献[8]在计算相似度时还考虑了姓名、内容、时间、地点等实体要素。
3.4 会话组织策略
不同于静态的新闻报道,文本会话流具有动态性,随着时间变化文档不断到来。K-means聚类算法等静态聚类算法,由于其要事先制定聚类数目,并不适用于文本会话抽取。目前采用最多的是Single-Pass策略。文献[8]提出了3种不同的Single-Pass策略,其中基于最邻近距离的Sing-Pass策略中消息的分类算法类似于KNN。KNN算法在新会话的检测中运用广泛,而从系统实现的角度讲,通常采用相似度直接与阈值比较的策略。
除此之外,文献[11]提出基于频繁刺激的短文本聚类算法FTSDC和基于密度的短文本聚类算法DSDC,首先根据频繁刺激进行初始簇划分,然后利用语义信息进行簇优化。DSDC使用语义信息来计算样本距离,基于共享近邻图来进行基本聚类,并通过数据抽样和子图划分来实现并行聚类。
4 难点与展望
由于文本会话本身的特点和处理对象的特殊性,使得话题发现与追踪中的许多经典方法不如在原来领域中那么有效。与TDT相比较,文本会话的难点包括消息语言奇异性与标准语言的映射和表示模型的修正、相似度的度量等,这也是今后研究的重点内容。
动态文本会话虽然与话题检测和追踪相比有很大的特殊性,但是都同属于文本聚类问题。随着网络的普及和论坛、社区、微博的迅速发展,动态文本会话抽取技术的研究将得到越来越多的重视。到目前为止,国内外的研究并不是很多,而且其研究方法大都是借鉴于话题检测与追踪中的方法,文本会话抽取技术要得到飞跃必须冲破传统思想的禁锢,结合本身问题及处理对象的特点,创造适合自己的模型。从应用的角度来说,随着文本会话研究的深入,其相关领域也受到越来越多的关注。动态文本会话系统将在会话抽取后的话题检测、社区发现、基于话题的多文本摘要等方面体现其越来越重要的地位。
[1]WANG Lin,JIANG Minghu,LIAO Shasha,et al.Concept features extraction and text clustering analysis of neural networks based on cognitive mechanism[J].Concept Features Extraction and Text Clustering Analysis of Neural Networks Based on Cognitive Mechanism,2006,4113:235-246.
[2]XI W,LIND J,BRILL E.Learning effective ranking functions for newsgroup search[C]//Proc.SIGIR’04.Sheffield,UK:[s.n.],2004:394-401.
[3]夏云庆,黄锦辉,张普.中文网络聊天语言的奇异性与动态性研究[J].中文信息学报,2007,21(3):83-91.
[4]高鹏,曹先彬.基于社会网络的聊天数据噪声过滤[J].计算机工程,2008,34(5):166-168.
[5]HONG Yu,ZHANG Yu,LIU Ting,et al.Topic detection and tracking rewiew[J].Journal of Chinese Information Processing,2007,21(6):71-87.
[6]李卓尔,胡运发.一种对BBS语料进行话题提取的聚类算法[J].计算机应用与软件,2008(8):1-3.
[7]WANG Le,JIA Yan,CHEN Yingwen.Versation extraction in dynamic text message stream[J].Urnal of Computers,2008(10):86-93.
[8]ZHU Mingliang,HU Weiming,Wu Ou.Topic detection and tracking for threaded discussion communities[C]//Proc.the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology.[S.l.]:IEEE Press,2008:77-83.
[9]SHEN Dou,YANG Qiang,SUN Jiantao,et al.Thread detection in dynamic text message streams[C]//Proc.the 29th annual international ACM SIGIR conference on Research and Development in Information Retrieval.New York,USA:[s.n.],2006:35-42.
[10]STENBACH M,KARYPIS G,KUMAR V.A comparison of document clustering techniques[EB/OL].[2011-01-02].http://rakaposhi.eas.asu.edu/cse494/notes/clustering-doccluster.pdf.
[11]王永恒.海量短语信息挖掘技术的研究与实现[D].长沙:国防科学技术大学,2006.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
客联(2022年3期)2022-05-31
数学年刊A辑(中文版)(2022年4期)2022-02-16
中国新闻周刊(2021年26期)2021-07-27
长江丛刊(2020年17期)2020-11-19
数学年刊A辑(中文版)(2019年3期)2019-10-08
计算机系统应用(2017年3期)2017-03-27
海外华文教育(2016年3期)2017-01-20
信息安全研究(2016年4期)2016-12-01
中国学术期刊文摘(2016年1期)2016-02-13
