
消除 MARC记录与 OPAC检索之瓶颈研究——以汇文 4.0为例
2011-05-03 09:51吴丽坤
图书馆界 2011年4期
吴丽坤
(哈尔滨工程大学图书馆,黑龙江 哈尔滨 150001)
1 引 言
MARC是 Machine Readable Cataloging的缩写,即机器可读目录。MARC格式就是机器可读目录格式,是指以代码形式和特定结构在计算机载体上能够被计算机识别和编辑输出书目信息的目录格式。它的使用提高了文献目录的质量和编目的速度,方便读者检索和利用文献。
OPAC(Online Public Access Catalogue)即联机公共目录查询,是图书馆向读者提供的电子目录查询服务,是读者检索和使用图书馆信息资源的一种重要手段[2]。随着图书馆集成管理系统的普遍应用,OPAC系统成为读者查询、检索图书馆资源的最重要的途径。OPAC功能的实现主要归结于三个方面的内容——书目数据、系统设计和软硬件的支持。书目数据库是 OPAC系统的数据源,是由一条条MARC记录组成的,所以,为了使读者能够更加方便、快捷、准确地检索和利用馆藏资源,各馆都十分重视 MARC数据质量,自从高等教育文献保障体系共建的队伍壮大之后,对 MARC记录著录的要求细化到一个标点、一个代码、一个指示符。可是,笔者却发现并不是所有著录到 MARC记录中的信息都应用到了检索中。目前笔者所在的哈尔滨工程大学图书馆使用的自动化集成系统是汇文 4.0,工信部部署 7所院校中除哈尔滨工业大学使用本校开发的系统外,其他 6所院校都在应用该系统,所以,问题是共性的。简而言之,某一类文献的某一个点编目员依照著录规则准确著录了,反过来,读者无法看到如此著录的所有同类文献,就是说著录和检索没有形成一个很完美、统一的闭环。
2 公共检索与 MARC著录不能统一的表现
1XX是 CNMARC格式中的编码信息块,该信息块记录定长编码数据元素,通过其所在字符位置定义。本字段块共包含 26个字段,其中中文图书包含信息较多、可以应用到检索中的主要是 101、105字段,详见表 1。

表1 101字段 文献语种
我馆目前使用汇文 4.0系统,其 OPAC多字段检索中可以选择语种类别。
例如:检索分类号是 H319.4的英文图书。
在馆藏书目多字段检索的索书号框中输入分类号 H319.4,语种类别选择“英语”,结果如图 1所示。

图1
出现在检索结果中的 73种中文图书都是 102字段的第一个子字段著录了@eng(英语的语种代码)的,其中包括英汉对照读物。同为分类号是H319.4的英汉对照读物,如果把@eng著录到 102的第二个子字段,则结果不在检索列表中。
而 1 234种西文图书是 008定长数据元素的35—37字符位取值为 eng的 MARC记录。翻译指示符的意义没有体现。
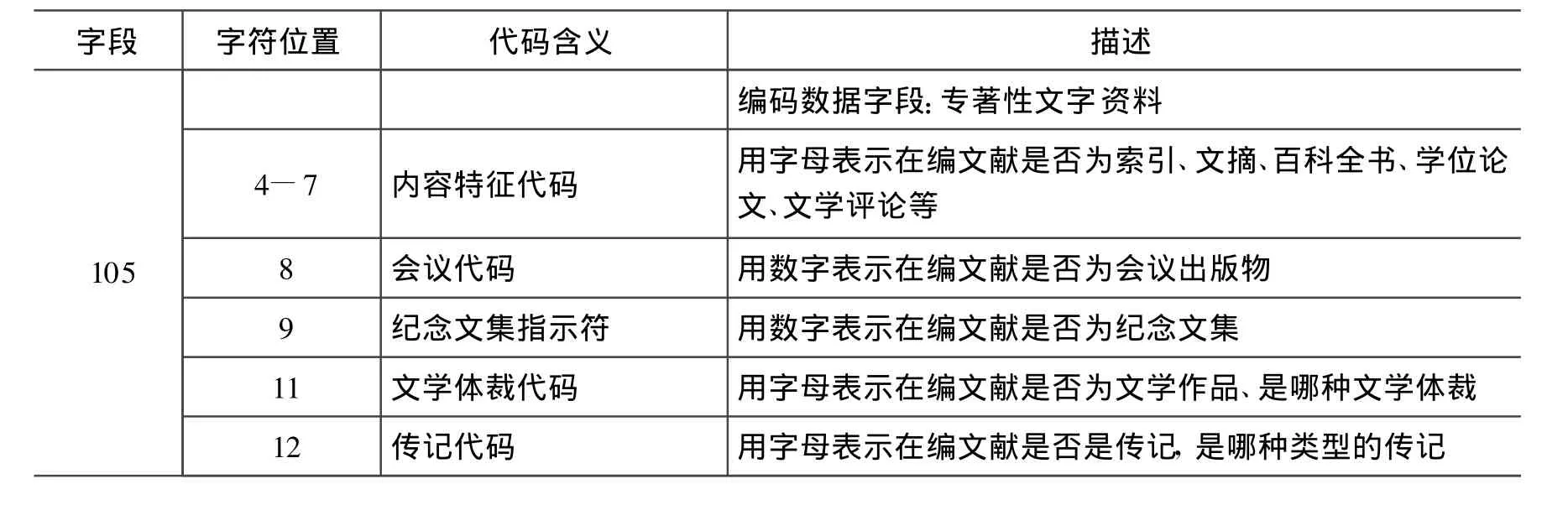
表2 105字段编码数据字段:专著性文字资料 (图书必备字段)
OPAC中,无法根据具体字符位取值的不同实现上述内容的分类检索统计。
606字段@j子字段是文献类型因素,同样,OPAC无法根据 606@j中著录的文献类型 (常见的文献类型包括教材、参考资料、学位论文、年鉴、会议录等)进行检索。上述问题用一个例子可以进行准确的描述。
例如:检索我馆所有馆藏会议录。在馆藏书目多字段检索的主题词框中输入“会议录”,结果如图2所示。

图2
结果只有四种且都是中文图书。
如果利用馆藏书目全文检索,在检索条中“任意词”框中键入“会议录”,结果如图 3所示。

图3
结果仍然都是中文图书。
3 问题所在
事实上凡是中文会议录编目员在编写 MARC格式时在 105字段的第 8字符位已经做过标注,606@j子字段也已经明确著录了会议录的文献类型,西文会议录分别在 008第 29字符位和 650@v中体现,由于所有 CNMARC中的 1XX编码信息块和 606@j子字段及 USMARC的 008定长数据元素和 650@v都没有包含在 OPAC的检索字段列表中(见表 3、表 4)。所以,即便是编目员对文献类型分别进行了代码和文字形式的两种不同标注,公共检索时仍然没有体现出来。
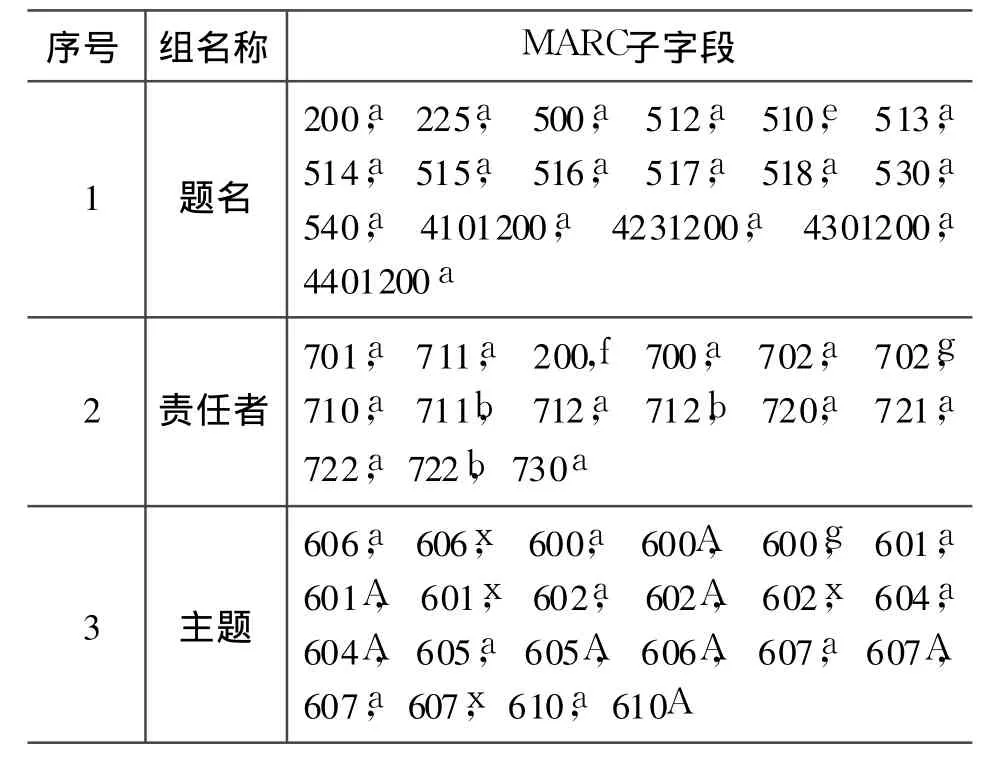
表3 CNMACR全文检索字段列表(表中省略标准号、分类号、丛编等组名称)
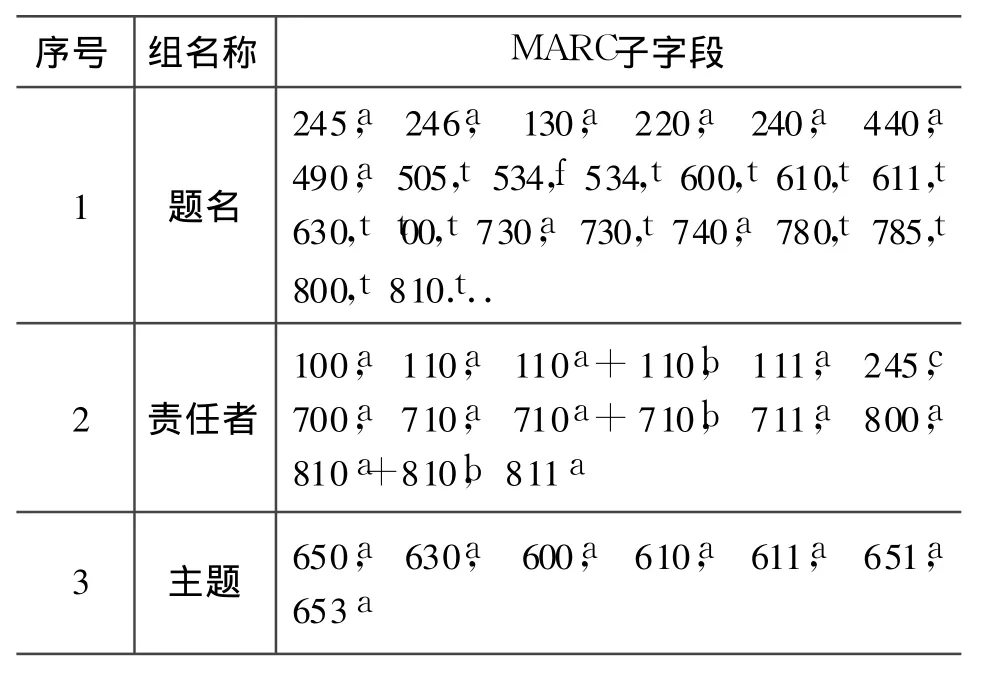
表4 USMARC全文检索字段列表(表中省略标准号、分类号、丛编等组名称)
4 解决方案
由于 OPAC检索功能的实现主要归结于三个方面的内容——书目数据、系统设计和软硬件的支持,所以,在书目数据质量达到很高的标准的情况下,系统设计和软硬件的支持就成为 OPAC功能实现的重要保障。之所以会出现并不是所有著录到 MARC中的信息都能够在检索中反映出来的情况,是因为目前我馆应用的自动化集成系统 (汇文 4.0)没有给予足够的支持。为了使 OPAC功能得到完美的实现,笔者参照北京大学图书馆书刊目录检索界面,列出下表供技术人员完善系统设计时参考,以期实现利用编码信息和定长字段进行文献类别检索。表 5是检索内容与不同 MARC格式中各字段特定字符位取值的对应情况。

表5 利用编码信息和定长字段实现文献类别检索时检索内容与不同MARC格式中各字段特定字符位取值的对应情况

续表5

续表5
另:把 CNMARC中 600、601、602、605、606字段中@j子字段和 USMAR中 600、610、611、630、650、651字段中@v子字段列入 MARC索引管理的主题检索列表中,使其能够实现检索。
OPAC馆藏目录检索的设计参照北京大学图书馆馆藏目录复杂检索[5](见图 4)。

检索限制:
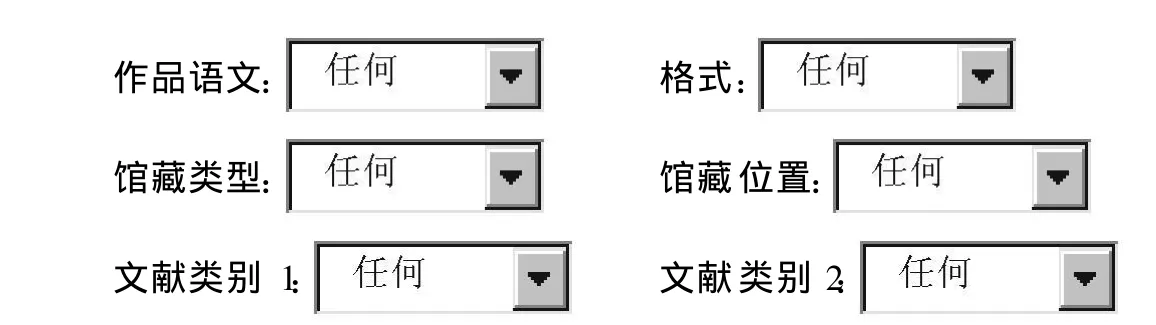
图4
5 期待实现的结果及意义
更加细化具体化的分学科分类别检索和统计。
例 1:检索所有馆藏的马克思的传记,在图 4主题框中输入“马克思”,在文献类别检索框中选择“传记”,检索结果是:
馆藏马克思的传记类文献66

例 2:检索馆藏力学的会议出版物,在图 4的主题框中输入“力学”,在文献类别检索框中选择“会议录”,检索结果是:
馆藏力学会议录 21种

OPAC是图书馆向读者提供的电子目录查询服务,是读者检索和使用图书馆信息资源的一种重要手段。读者通过 OPAC检索时,想要某类文献的目的是明确的、愿望是强烈的,OPAC能否根据这种明确的指示快速准确全面地给出检索结果是读者能否便捷充分利用图书馆的关键所在[3],尤其是在馆藏MARC记录都完整规范著录的前提下,我们更加迫切地希望高质量的书目数据能够充分应用到 OPAC的检索中,用简单的手段来得到想要的结果。消除MARC记录和 OPAC间检索瓶颈之后,还能实现各学科、专业相关教材及参考资料的检索,更有利于统计不同学科馆藏情况,为馆藏资源建设提供依据。
6 结 论
规范著录的目的是实现快捷、准确的检索,这是机器可读的真正意义。当 MARC记录规范到一定层面时,如果目录查询服务还不能够完全展现这种规范,就应该考虑如何使二者充分契合,使著录和检索形成完整、统一的闭环。
[1]朱 茗.基于 OPAC的书目信息推拉服务[J].图书馆学刊,2010(8):70—72.
[2]金 岩,于 静.基于 OPAC的资源整合研究[J].图书馆杂志,2009(2):27—30.
[3]黄 进.浅析 OPAC系统功能发展趋势[J].图书馆,2010(4):95—96.
[4]北京大学图书馆馆藏目录检索[EB/OL].[2011-03-21].http:∥162.105.138.200/uhtbin/cgisirsi/DmRgtbT1J4/北大中心馆/221170492/60/60/X.
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
现代仪器与医疗(2022年2期)2022-08-11
都市人(2022年3期)2022-04-27
电脑爱好者(2021年23期)2021-12-08
中国收藏(2018年1期)2018-04-04
北京档案(2016年12期)2016-12-27
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
全国新书目(2009年1期)2009-04-13
家庭医学·下半月(2009年2期)2009-03-27

- 图书馆界的其它文章
- 浅析《中国图书馆分类法》(第五版)G25类修订特色及问题