
WSNs中节点协同声源定位协议研究
2011-09-03 06:24唐树青
合肥工业大学学报(自然科学版) 2011年10期
夏 娜, 唐树青, 赵 娟
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.合肥工业大学 安全关键工业测控技术教育部工程研究中心,安徽 合肥230009)
0 引 言
无线传感器网络技术(Wireless Sensor Networks,简称WSNs)的快速发展为声源定位提供了一种有效解决方案。利用无线传感器节点对声源进行定位具有隐蔽性好、全天候、低成本、不受视线和能见度限制等优点,因此该方案已成为现代军事和民用安防中声源定位的研究热点[1-3]。由于实际环境中的声源目标往往是移动的或具有突发性,因此要求声源定位方法能够快速定位和跟踪声源事件,如何基于计算、通信和能量资源受限的传感器节点完成高效实时的声源定位是研究的难点和关键[4-6]。
目前,基于无线传感器网络的声源定位方法多为相对精确定位方法,主要利用3种物理测量值,即接收声音信号的能量强度、波达方向 (Direction of arrival,简称 DOA)和声音信号到达时间差(Time difference of arrival,简称 TDOA)来计算声源位置。文献[7-8]提出了一种声音传播的能量衰减模型,利用极大似然法(MLE)实现声源定位,并引入EM (Expectation-Maximization)算法减小MLE的计算量;文献[9]提出了基于麦克风阵列的近场二维MUSIC算法,估计声源到达角度及其传播距离,进而实现声源定位;文献[10-11]利用广义互相关法估计声音信号到达多个传感器节点的时间差TDOAs,结合节点的位置信息计算声源位置。上述方法需要传感器节点较准确地采集声音信息,信息汇聚到中心节点进行集中式计算,且计算量较大,因此难以实现动态声源实时定位。
本文在以上工作的基础上,研究了一种多传感器节点协同的声源近似定位协议,完整分析了节点处理声音和射频信号的时间,以及对该声源定位协议精度的影响,得到了声源定位边界性条件。实验结果表明该协议在动态声源定位中的有效性。
1 节点协同声源定位协议
1.1 系统模型
声源监测区域如图1所示,五角星A为声源,灰色圆圈为传感器节点,S1是离声源最近的节点,S2是次近节点。
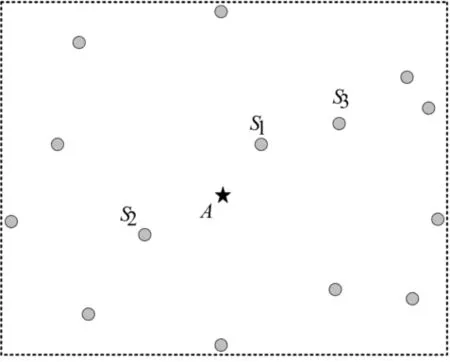
图1 声源区域
1.2 协议描述和分析
1.2.1 协议描述
协议基本思想:声源A发出声音信号,离声源最近的节点S1最先接收到声音信号并立刻广播RF信号,RF以光速传播,瞬间到达其他节点。若其他节点在接收到声音信号之前接收到RF信号就进入被屏蔽状态,在一段时间内忽略声音信号。而S1最终自举成为elected节点,其自身位置可以作为声源的近似位置。节点协同声源定位协议的流程如图2所示,描述如下:
(1)初始时刻所有节点均处于射频和声音的监听状态。
(2)如果节点先监听到声音,则立刻从监听状态转换到射频发射状态,持续时间为Tα(Tα≥Δr2,Δr2是传感器节点识别RF所需的时间)。发射完毕后立刻转换为监听RF的状态,持续时间为Tβ(Tβ≥Δr2),若没有监听到 RF信号,则该节点自举为elected节点,反之,则被屏蔽。无论是否成为elected,该节点都会建立一个长度为Tγ的定时器。
(3)如果节点在接收到声音之前监听到RF,则直接进入被屏蔽状态,同样建立一个长度为Tγ的定时器。在此段时间内,节点对声音信号不做任何处理。
(4)所有节点在定时Tγ时间之后均返回射频和声音的监听状态。
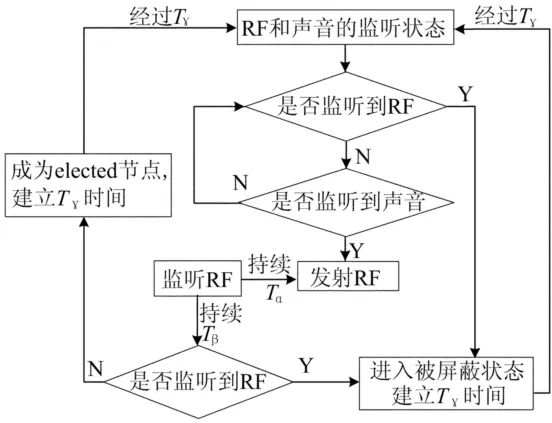
图2 节点协同声源定位协议流程图
1.2.2 协议分析
考虑传感器节点对声音和射频信号的识别时间以及信号处理时间,对上述声源定位协议进行有效性分析。
假设传感器节点识别声音信号所需的时间为Δs,电路推动RF信号发射所需的时间为Δr1,识别RF信号需要的时间为Δr2。设传感器节点Sj到声源A 的距离为dj(j=1,2…),不妨设j越大节点Sj距离声源越远。声速为v。
情况1:如图3a所示,d1/v+Δs+Δr1+Δr2<d2/v+Δs。其中d1/v为声音到达节点S1的时间,d1/v+Δs表示S1识别出声音信号的时间,d1/v+Δs+Δr1表示S1发射出RF信号的时间,d1/v+Δs+Δr1+Δr2表示S2识别出RF信号的时间;与此同时,d2/v表示声音到达节点S2的时间,d2/v+Δs表示S2识别出声音信号的时间。上述不等式表示节点S2在识别声音信号之前已经识别出S1发来的RF信号,因此被屏蔽。最终S1自举成为elected节点。
情况2:如图3b所示,d1/v+Δs+Δr1+Δr2>d2/v+Δs,即节点S2在识别S1发射的RF信号之前已经识别了声音信号,开始发射RF信号,因此不会被屏蔽。此时,S2也自举成为elected节点。
情况3:如图3c所示,d1/v+Δs+Δr1+Δr2>d2/v+Δs,且d1/v+Δr2<d2/v,则节点S2发射的RF信号会屏蔽S1节点。S2自举成为elected节点。
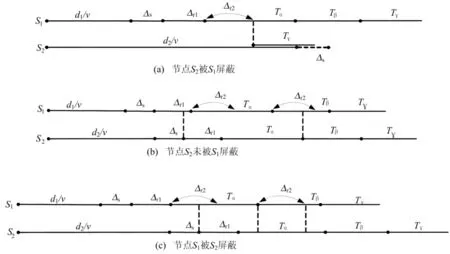
图3 节点S1、S2的状态分析
根据以上分析得到该声源定位协议的边界性条件:
(1)当d1/v+Δs+Δr1+Δr2<d2/v+Δs时,即当d2>d1+(Δr1+Δr2)v时,S2被S1发出的 RF信号屏蔽。S1自举成为elected节点。
(2)当d1/v+Δs+Δr1+Δr2>d2/v+Δs时,即当d2<d1+(Δr1+Δr2)v时,S2不会被S1发出的RF信号屏蔽。S2自举成为elected节点。
(3)当d1/v+Δs+Δr1+Δr2>d2/v+Δs,且d1/v+Δr2<d2/v时,即当d1+Δr2v<d2<d1+(Δr1+Δr2)v时,S2发出的RF信号会屏蔽S1。S2自举成为elected节点。
(4)当d1<d2<d1+Δr2v时,S1和S2均自举成为elected节点。
令l1=d1,l2=d1+Δr2v,l3=d1+(Δr1+Δr2)v;如图4所示,以声源A为圆心,半径为l1的圆形区域为C1,半径在l1与l2之间的圆环区域为C2,半径在l2与l3之间的圆环区域为C3,C3以外的区域为C4。可见,C1内不会有节点,因为S1是离声源最近的节点;若C2内有节点,则它与S1同时自举成elected节点;若C3内有节点,则只有它自举成elected节点;若C4内有节点,则它被屏蔽。
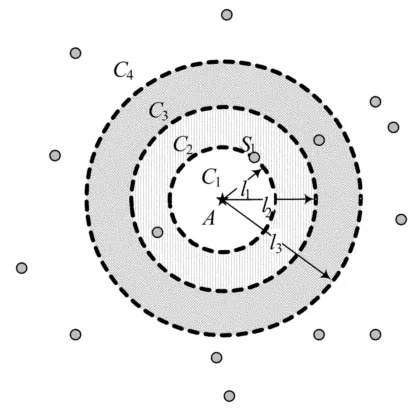
图4 节点协同声源定位协议边界性区域
1.2.3 定位解算
设elected节点数为m。若m=1,则用该节点的位置近似作为声源位置;若m≥2,则由这些节点的坐标质心作为声源的估计位置。elected节点以CSMA的方式通报中心节点,由中心节点计算声源的估计位置。由于Δr2v通常很小 (如Mica2节点的Δr2v<0.2 m),距离S1在Δr2v范围内的节点往往没有,因此中心节点通常只会收到1个elected节点的通报信息,定位解算得以简化。定义声源的实际位置与声源的估计位置的欧式距离e作为声源定位协议定位精度的评价指标。
2 协议测试
采用伯克利大学研制的Mica2节点对节点协同声源定位协议进行性能测试。声音采集传感器为DFR0034。点声源为一单片机触发的小型扬声器,发声频率为1Hz,声速为340m/s,声强大于50dB。测定的节点时间参数见表1所列。

表1 测定参数 μs
2.1 静态与动态声源定位
在50m×60m的监测区域内,布置15个传感器节点,采用本文声源定位协议对一静态声源进行定位,其结果如图5所示。
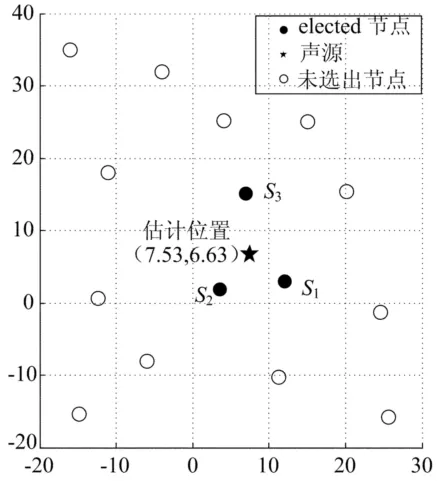
图5 静态声源定位结果
在50m×60m的监测区域内,布置50个传感器节点,进行动态声源定位,结果如图6所示。
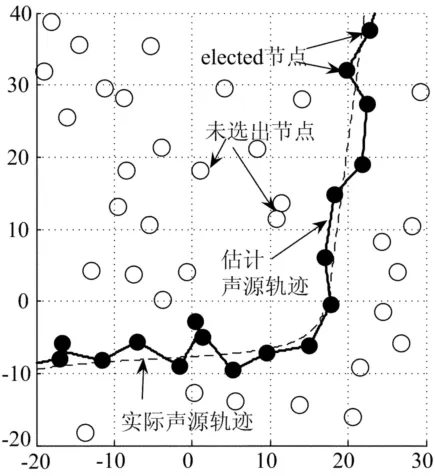
图6 动态声源定位结果
由图5可见,S1、S2和S3自举成elected节点,它们以CSMA的方式通报中心节点,中心节点通过质心法计算出声源的估计位置为(7.53,6.63),如图中五角形所示;声源的实际位置为(7.10,7.90),本次定位误差为1.34m。为了充分验证协议的定位效果,在网络布置相同的情况下调整声源位置,进行了6组定位实验,每组实验操作10次,统计实验结果,见表2所列。由表2可见在各组实验中声源定位的误差均值为0.06~1.34m,可以满足实际应用的需求。
由图6可见,一点声源沿实线穿越监测区域,声源发声频率为1Hz,声音强度大于50dB,速度为0.5m/s。传感器节点运行本文声源定位协议对该动态声源进行定位。图6中黑色圆点为elected节点,虚线为动态声源定位跟踪结果。由此可见,节点协同声源定位协议可以实现动态声源的实时定位,并具有较好的定位精度。
2.2 协议性能分析
将本文多传感器节点协同的声源近似定位协议与文献[10-11]提出的相对精确定位方法进行比较。后者利用广义互相关法估计声音信号到达多个传感器节点的时间差TDOAs,结合节点的位置信息,通过最小二乘法迭代计算出声源位置。分析比较结果见表3所列。
由表3可见,本文研究的声源近似定位协议通过节点间的协同,分布式地完成声源定位。该方法对声音信号采集要求不高,计算量小,实时性好,适用于动态声源定位。

表3 性能比较
3 结束语
本文研究了一种多传感器节点协同的声源定位协议,结合传感器节点对声音和射频信号的识别和处理时间,对上述声源定位协议进行了有效性分析,得到了相应的边界性条件。静态和动态声源定位实验结果表明,该协议作为一种分布式可实现的声源定位协议,具有较好的定位精度,同时计算量小,实时性好,适用于复杂场景中的动态声源定位。按照目前的协议设计,节点在大部分时间里处于射频和声音的监听状态,能耗较大,因此如何使节点尽可能地处于休眠状态,从而提高协议的能量有效性是下一步工作。
[1]You Y,Yoo J,Cha H.Event region for effective distributed acoustic source localization in wireless sensor networks[C]//IEEE Communications Society in the WCNC Proceedings,2007:2764-2769.
[2]Kushwaha M,Koutsoukos X,Volgyesi P,et al.Acoustic source localization and discrimination in urban environments[C]//12th International Conference on Information Fusion,Seattle,WA,USA,2009:1859-1866.
[3]夏 娜,李 敦,唐 媚,等.无线传感器网络中时效性优化的GEAR路由协议[J].合肥工业大学学报:自然科学版,2010,33(4):519-523
[4]鲁 佳.基于传声器阵列的声源定位研究[D].天津:天津大学,2008.
[5]Azimi-Sadjadi M R,Kiss G,Feher B,et al.Acoustic source localization with high performance sensor nodes[C]//Unattended Ground,Sea,and Air Sensor Technologies and Applications IX,Vol 6562,2007:65620Y-1-10.
[6]Bergamo P,Asgaris S,Wang H B,et al.Collaborative sensor networking towards real-time acoustical beamforming in free-space and limited reverberance [J].IEEE Transactions on Mobile Computing,2004, 3 (3):211-224.
[7]Sheng X H,Hu Y H.Maximum likelihood multiple-source localization using acoustic energy measurements with wireless sensor networks [J].IEEE Transactions on Signal Processing,2005,53(1):44-53.
[8]Kitakoga N,Ohtsuki T.Distributed EM algorithms for acoustic source localization in sensor networks[C]//Vehicular Technology Conference,IEEE 64th,2006:1-5.
[9]Asano F,Asoh H,Matsui T.Sound source localization and separation in near field[J].IEICE Transactions on Fundamentals of Electronics,2000,E83-A(11):2286-2294.
[10]Ajdler T,Kozintsev I,Lienhart R,et al.Acoustic source localization in distributed sensor networks[C]//Conference Record of the 38th Asilomar Conference on Signals,Systems and Computers,Vol 2,2004:1328-1332.
[11]Knapp C H,Carter G C.The generalized correlation method for estimation of time delay[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1976,24(4):320-327.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
好日子(2022年3期)2022-06-01
家庭影院技术(2020年6期)2020-07-27
意林·少年版(2020年23期)2020-01-15
电子制作(2019年23期)2019-02-23
中老年健康(2017年8期)2017-12-16
电子制作(2017年20期)2017-04-26
厦门理工学院学报(2016年1期)2016-12-01
噪声与振动控制(2016年5期)2016-11-09
海军航空大学学报(2015年3期)2015-11-11
