
一种新的时间序列相似性模式发现算法
2011-12-09 00:55朱渊萍
海南师范大学学报(自然科学版) 2011年2期
朱渊萍
(南昌工程学院 计算机科学与技术系,江西 南昌 330099)
一种新的时间序列相似性模式发现算法
朱渊萍
(南昌工程学院 计算机科学与技术系,江西 南昌 330099)
为了提高效率,基于时间序列的数据挖掘,采用了近似的方法取代原有时间序列,这导致了数据挖掘准确性的降低,文章的主要目标在于有效率地搜寻时间序列中的相似子序列向量,且希望能够兼顾准确性及效率,进而提供不同领域对于时间序列的不同需要.
时间序列;数据挖掘;相似子序列
时间序列相似性模式发现是时间序列数据挖掘中的一个重要方面.在生物信息这个领域中,利用像生物芯片这样的技术,使得生物学家得以分析成千上万基因与基因,甚至是蛋白质与蛋白质之间的相互关系.另外,时间序列分析包含了其它的研究,例如时间序列的索引或查询、时间序列的丛集分析、时间序列的规则或模式的研究.但这些应用都脱离不了最基本的问题,那就是如何正确地定义时间序列间的相似度.最早用于时间序列相似度计算的方法就是利用欧几里德相似度量测法[1],虽然这个方法解决了程度变形及偏移量,但对于时间序列长度长短不一、序列有噪声存在及平移问题,此方法就变得不可行.动态时间变形[2]原本是用于语音识别的分析,其主要想法是允许序列中的任一点多次复制以将序列延伸,如此便可解决时间平移的问题,而序列间的相似度则是利用延伸后的序列,计算他们之间的欧几里德距离当成其相似度,此方法首先找出两时间序列之最佳的对齐方式,然后利用欧几量德距离计算其相似度,但因为使用欧几里德距离,所以依然无法解决程度变形及偏移量的问题.随着数据量的增加,不少时间序列的分析方法都会变得难以运行.因为这些方法执行所需的时间会随着数据量及时间点的增加而变得更高.
目前不少人提出了将原有的时序数据维度转换到另一维度来达成维度缩减的方法,比如Agraw⁃al提出使用离散付里叶变换,即F-index算法[3].在上述算法的基础上Chan Franky提出用小波变换的方法进行时间序列相似性匹配[4],用Haar小波对序列进行维数约简,在R树上进行相似匹配,进而降低所需运行的执行时间.上述隔点采样抽取算法有较大的局限性,在损失峰值信息的同时无法确保所提取曲线趋势的有效性和效率.因此如何在时序数据的正确性及效率上取得一个平衡点,就成了许多人研究的问题.
本文对时间序列做了两次变换,分别为角度变换及符号变换.角度变换后的数据能够保有原有的特性,保证了数据正确性,符号变换比对数值数据直接分析运行时间少.变换后,采用有限状态机检索子模式,时间复杂度降低,进而更有效率地处理相似子序列.
1 相似子序列搜索算法
1.1 角度变换
为了解决时间序列分析所遇到的难题,我们首先为时间序列做角度变换.假设现有一时间序列向量S,为了找到相似的子序列,我们首先将原本的时间序列向量S变换成S′;T代表着时间序列记录的时间点.
将原本的时间序列变换成S′,这样的转换是希望保留住原本序列上升及下降的变化,进而利用这些变化找到相似的子序列.如图1所示,我们希望将所有的时间序列改以其变化的角度来做记录.

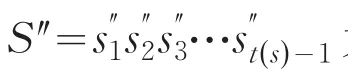
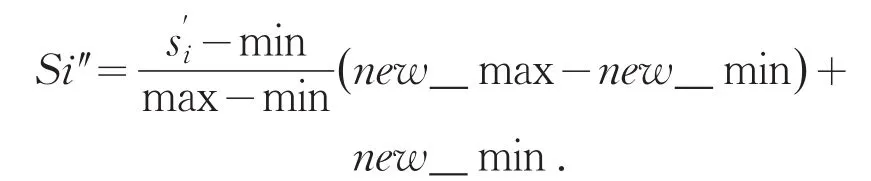
new_min,new_max则分别为正规化后所有向量值域的最小及最大值.
因转换后的时间序列S‴被正规化到-1及1之间,这样我们就能利用反三角函数sin-1求角度.经由角度变换的方式,原有的时间序列改变为只记录其区段的序列变化情况.
1.2 符号变换
为了达到维度缩减的目的,我们采取将数值型态的数据转换成符号型态的数据,虽然这样的方式可能会造成数据的完整性不足.但相对于直接对数值型态的数据做分析,这样的方式时间运行的成本相当高.所以为了在数据完整性及效率上取得一个平衡点,我们提供使用者一个设定参数(SN),来决定应该使用多少符号取代原有的数值型态的数据,这样就能在许可范围内处理所需要的数据.而这样的方式使得我们能有效率地为时间序列做分析,而不失其准确性.
(1)首先利用Z-score正规化法
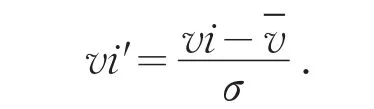
将所有的角度正规化成其平均值为0,且标准差为1,这是为了将序列数据正规化成正态分布,因此当使用者决定好要用多少符号来取代原有的时间序列时,我们便可利用表1来决定不同符号之间的切点,而这些切点大约等分了整个正态分布.
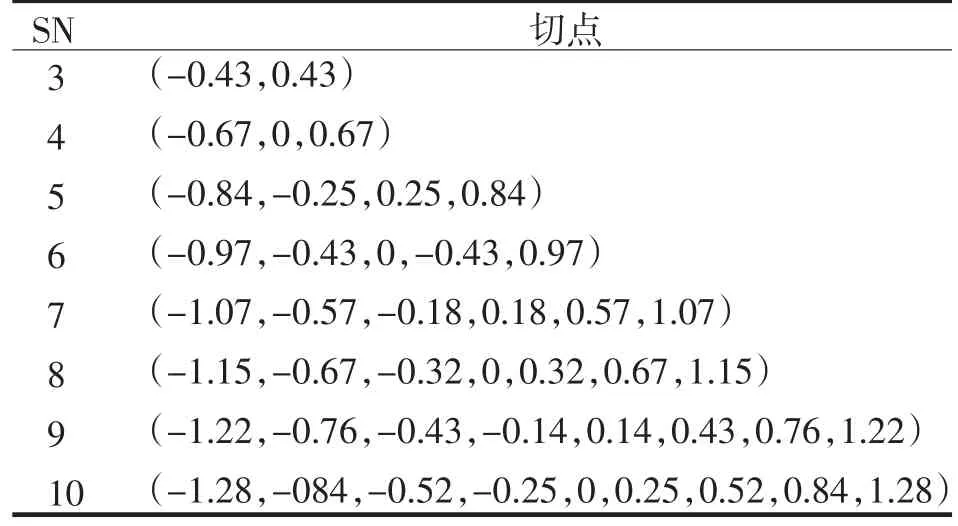
表1 正态分布切点Tab.1 Tangency point of normal distribution
(2)接下来利用表1的切点,将原本的角度取代为符号.如图,假设SN=5且得到符号切点分别为:A(54°至 90°)、B(18°至 54°)、C(-18°至 18°)、D(-54°至-18°)、E(-90°至-54°),则原本的角度将会依序转换成符号.
如图1,第一个时间序列的夹角为45°,介于18°至54°之间,所以于转换时以符号B表示,以此类推将整个序列转换成字串,上图的序列夹角就转变成字串BDEAEB.
利用这样的符号变换,我们可将所有的时间序列数据转换成以符号代表,接着利用现有的有效率的字串算法,便可找出两时间序列中相似的部份.
1.3 检索子模式算法
从上面的变换我们可以看到,所有的时间序列都会由一定个数的字符所代表,这样将时间复杂度降低至与字符个数成比例就成了我们的目标.虽然现有的Suffix Tree[5]已相当有效率的字串算法,但是它的时间复杂度会随着字串的长度而增加,在此我们利用类似有限状态自动机的概念来重新定义一时间序列,且这个时间序列能够保存原有Suffix Tree的信息.其步骤如下:
(1)首先分别建立字符串"BANANAS"及"BAS⁃CANA",比如字符串"BANANAS"只有四种字符,故一开始只拥有四个结点如图2(a),接下来由字符"B"开始,依据其下一个字符在结构上增加边如(b),且在边上会给予编号,这个编号记录的是"B"在字串中的位置,而"B"也同样记录这样的数据,这代表着通过此边的条件为此字符的发现位置必须与边上的编号相同,以此类推,将整个结构建立完成如(g),而我们利用阵列来记录这样的结构如表2(a).
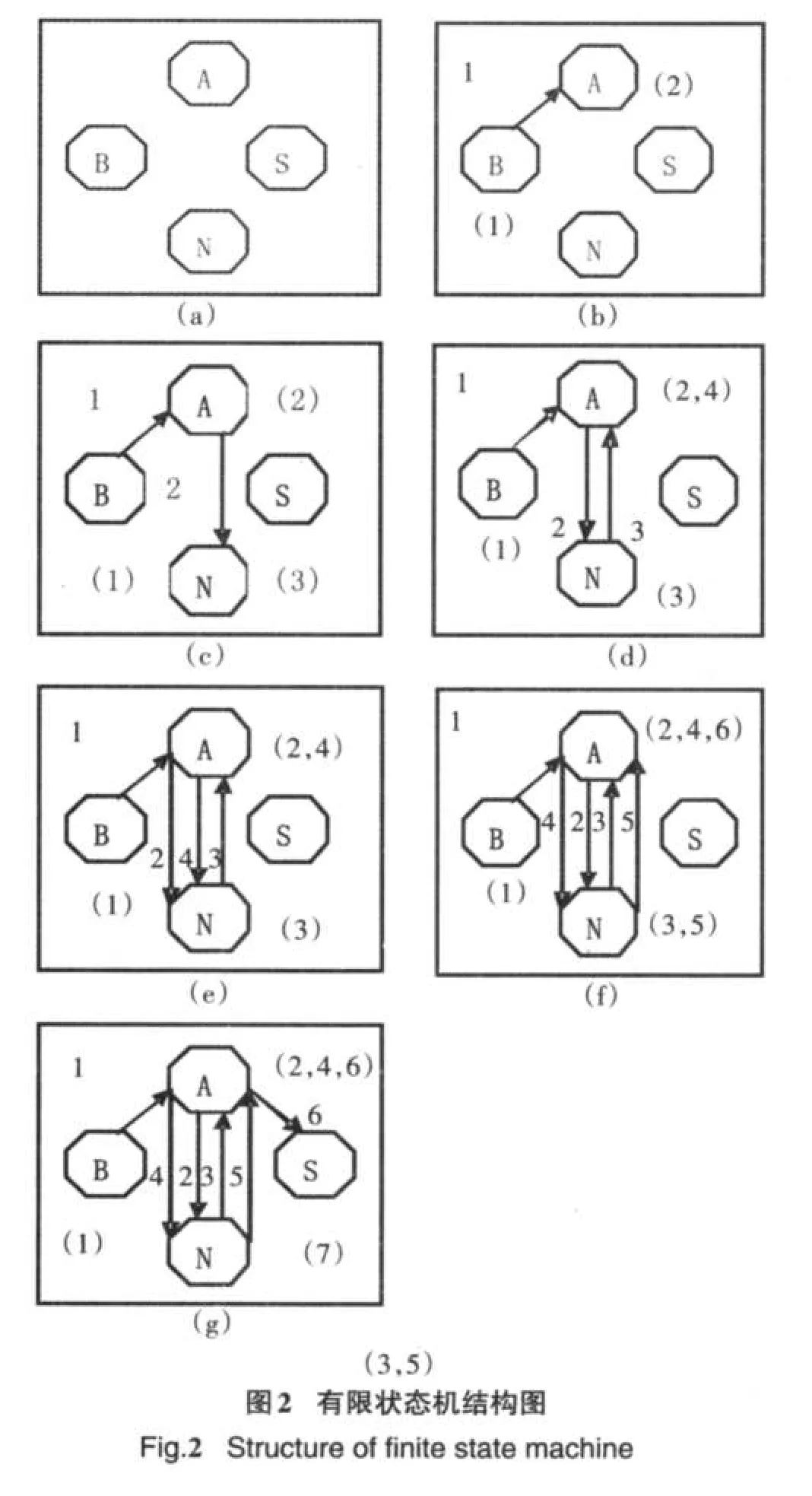
(2)接下来利用记录字符串"BANANAS"的表2(a)及"BASCANA"的表2(b),取此两表的交集得到表2(c).
(3)最后利用表2(c),由不同的字符出发便可得到如表3中所有的相同子字串,最后依照其在原字串中的顺序一一排列.

表2 字符串记录表Tab.2 String recording
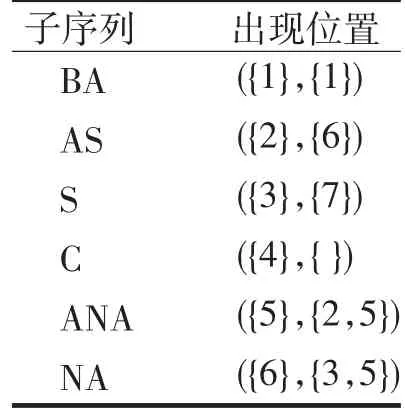
表3 子串位置Tab.3Substring position
而这当中的"C"可以直接忽略,因在字串"BA⁃NANAS"并没有相对应的位置,而"AS"及"C"则因在"BANANAS"中出现的位置皆在"ANA"之后,所以比较其子字串的长度后会保留"ANA",而"NA"出现的位置皆被"ANA"所包含,故也可省略.
(4)最后我们得到的子序列分别为"BA"及"ANA",因"ANA"共出现在字串"BANANAS"的第2及第5个位置,但第2个位置会与"BA"有重复,因此正确的对应的方式应为:


假设n代表时间序列库中被搜索字符串的长度,m代表要搜索字符串的长度,而k代表字串中符号的个数,采用Suffix tree方法的时间复杂度是O(n+m),而该方法是O(k2)可以看出当时间序列的长度很长时,使用有限状态自动机的概念能够大幅地减少时间复杂度.此外用来记录的结构也能用来同时处理多个时间序列相似的部份,且这样的结构在k值不变时,并不需要重新建立,因此用来为相似子序列做索引或重复搜索时能提供信息的再利用.
2 结论
维度变换的缺点就是原始数据正确性的降低,但在数据量不断增加情况下,现有的方法已不再能够承受如此庞大的计算量,如何快速地寻找有效的信息,便成了数据挖掘领域的一大挑战.在本文中,利用符号变换取代原有的数据,接着再利用有限状态机的字符串算法来改进搜索的效率,这不仅仅提供了更有效率的方式给使用者,更大大地提升原本耗时耗力的运算.
[1]李斌,谭立湘.面向数据挖掘的时间序列符号化方法研究[J].电路与系统学报,2000,4(5):9-14.
[2]郑诠,朱明,王俊普.相似时间序列的快速检索算法[J].小型微型计算机系统,2004,25(5):785-789.
[3]Agrawal,Faloutsos C,Swami A.Efficient similarity search in sequence databases[A].Proceedings of the 4th Int'l Con⁃ference on Foundations of Data Organization and Algo⁃rithms[M].New York:Springer,1993:69-84.
[4]Franky C,Fu Waichee.Efficient Time Series M atching by Wavelets[J].15th IEEE International Conference on Da⁃ta Engineering,Sydney,Australia,1999,23/26:126-133.
[5]Pampapathi R,Mirkin B,Levene M.A suffix tree ap⁃proach to anti-spam email filtering[J].Machine Learning,2006,65(1):309-338.
An New Algorithm of Finding Simliar Subpattern Based on Times Series
ZHU Yuanping
(School of Information Engineering,Nanchang Institute of Technology,Nanchang330099,China)
Based on the data mining of times series,the approximation-like methods for performance improvement,lead to decrease of accuracy.In this paper,we focus on the efficient method of searching similar subpattern,which considers balance between performance and accuracy.
times series;data mining;similar subpattern
TP 301.6
A
1674-4942(2011)02-0151-04
2011-01-23
江西省科技厅科技支撑项目(2009ZDG08400)
黄 澜
猜你喜欢
幼儿园(2021年6期)2021-07-28
大众投资指南(2021年35期)2021-02-16
中学生数理化(高中版.高考数学)(2020年12期)2021-01-13
小学生学习指导(低年级)(2019年11期)2019-11-25
中等数学(2018年7期)2018-11-10
小学生导刊(2017年13期)2017-06-15
电力与能源(2017年6期)2017-05-14
福建中学数学(2016年4期)2016-10-19
信息通信技术(2015年6期)2015-12-26
天津科技大学学报(2015年4期)2015-04-16
