
基于 SQL分层抽样的数据挖掘算法的改进*
2011-12-17 09:10谢笑盈邢君飞
浙江师范大学学报(自然科学版) 2011年2期
谢笑盈, 邢君飞
(浙江师范大学数理与信息工程学院,浙江金华 321004)
0 引 言
关联规则挖掘是知识发现中的一个重要问题,它是由 Agrawal,I mielinski和 Swami[1]于 1993年提出的.关联规则挖掘用于发现数据库中不同项目集之间的关系,从而得出有意义的规则和模式.自关联规则挖掘这一概念被提出以来,诸多研究人员对其进行了广泛的研究,包括对原有的算法进行优化,如引入随机抽样、并行的思想等,以提高算法挖掘规则的效率.Mannila等[2]首先考虑了这一点,认为抽样是发现规则的一个有效途径.引入随机抽样的基本思想是在给定数据的一个子集上挖掘,对前一遍扫描得到的信息进行仔细地组合分析,可以得到一个改进的算法.随后,Toivonen[3]进一步发展了这个思想,先使用从数据库中抽取出来的样本得到一些在整个数据库中可能成立的规则,然后再用数据库中的剩余数据验证这个结果.Toivonen的算法相当简单且显著减少了 I/O代价,但一个很大的缺点就是产生的结果不精确,即存在所谓的数据扭曲.分布在同一页面上的数据时常是高度相关的,可能不能表示整个数据库中模式的分布.为了减少抽样产生的不精确性,本文利用聚类分析方法先对数据库进行分层,并在此基础上抽样,结合 SQL Server 2005实现了这一算法.
1 方法分析
数据挖掘是从存放在数据库或其他信息库的海量数据中挖掘有趣知识的过程.数据挖掘技术自兴起以来一直是研究的热点,现己有大量的实现算法.但随着需要处理的数据规模越来越大,以及数据内部的复杂性,许多算法在进行大规模数据分析时还需要消耗大量的时间和物理资源.如何减少大规模数据分析所消耗的资源问题就不可避免地摆在了我们面前.在提高数据挖掘算法效率的同时,很自然地会引进统计中的抽样思想[4],首先对大规模数据集的部分数据进行数据分析,然后根据相应的结果进行下一步处理,以提高数据分析的效率,这是一种行之有效的方法.为了使抽出的样本对原数据集的数据扭曲尽可能地小,用什么样的抽样策略,以及如何实现抽样,又成了研究的焦点.
假设事物数据集合 T={t1,t2,…,ti,…,tN},其中每个事物 ti均由变量集 A={a1,a2,…,ak}来描述.若属性 ai的取值为有限的且构成对降维有决定意义的小集合{ai1,ai2,…,aim},根据 ai的取值可将T分成m个子集,每个子集的事物个数分别为N1,N2,…,Ni,…,Nm,易知在每个子集中的事物在某方面有很大的相似性,且这种相似性对后面的数据分析有重要的意义.这就实现了对数据集按某个属性的聚类,并自然而然地将数据集分成了 m个层,为对数据集进行分层抽样奠定了基础.例如,在人口普查中考察比较各省的老龄化进程时,按事物 ti所处的省份将集合 T分成 23个子集,这种聚集操作只需对数据库进行一次扫描就能完成.
为了既能发现集合中不同项目集之间的关系,又能避免多次重复扫描处理全体数据集,因此考虑用从数据集 T中抽取出来的样本得到一些在整个事物集中可能成立的规则,然后再用数据集的剩余数据验证这个结果.显然,如果抽出来的样本能兼顾到m个子集的取值,那么这个样本对整体数据集就有较好的体现.因此,引入了分层抽样,即将 m个子集看成是集合 T的 m个层,对每个层进行随机抽样,设抽比例抽样的结果保存到同一个集合 P={p1,p2,…,pj,…,pn}中.至此,实现了对原数据集 T的降维,后续的关联规则分析将在降维后的数据库中进行.
2 实证分析
2.1 模型设计
为了让上述的数据挖掘思想得以实现,本文采用 SQL Server 2005的基于数据挖掘的工具 B I(Business Intelligence)来实现.根据浙江工商大学对杭州经济开发区健身情况的调查表模拟建立数据库,并以此为基础进行联机分析挖掘研究.
首先通过 SQL ServerManagement Studio建立一个数据库,导入模型所需要挖掘分析的表,然后创建数据库关系图.创建好数据库关系图后,再打开 SQL Server Business Intelligence Development Studio,新建一个数据库关系图 Analysis Services项目,然后新建一个数据源连接刚在 SQL ServerManagement Studio中建立的数据库,接着创建数据源视图 DSV.为了分析职业、性别、年龄、省份、运动项目、运动时间等属性之间的关联情况,建立 1张事实表和 2张维度表.事实表的结构如下:运动情况 (登记 I D、周运动时间、设施收费);网民情况表 (登记 I D、性别、年龄、工作性质、居住省份);健身事实表 (登记 I D、运动时段、运动项目).
2.2 模型建立
由于该数据库中存在的记录数很大,若直接对数据库进行关联规则的数据挖掘,则需要进行大量的计算.SQL Server 2005根据工作性质对网民情况表进行聚类,下面是实现的 SQL语句:
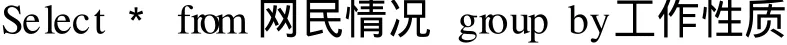
至此,网民情况表根据工作性质被分成了 6个结构相同的子表,分别按职业保存为:公务员表、教师表、民营表、外资表、国企表、自由职业表,这就相当于把网民情况表按工作性质分成了 6个层,对每个层进行随机抽样.
以公务员表为例,用 SQL语句实现如下:

将从 6个子表中等比例抽样的结果保存到同一个表中,表名为网民情况抽样,至此,实现了对网民情况表的降维.将网民情况抽样表与健身事实表和运动情况表进行连接处理,就实现了对整个数据库的降维,后续的关联规则分析将在降维后的数据库中进行.
为了调查职业、省份、性别、年龄对运动时间、运动项目的影响,要对降维后的数据库进行深入的挖掘分析.以前面的数据库为基础创建一个以健身事实表为事例表,以网民情况抽样表和运动情况表作为嵌套表的挖掘结构,然后将所需分析的居住省份、年龄、性别作为输入列,以运动时段和运动项目作为预测列,具体建模如图 1所示.
将最低支持度设置为 0.5,最小项集设置为 1,最小置信度分别设置为 0.95,0.96,0.97,0.98,0.99,1.00,即挖掘结构采用支持度-置信度评估框架来选择关联规则.

图 1 基于Microsoft算法关联规则的挖掘模型
2.3 模型分析
通过对原数据集、随机抽样、分层抽样前后数据的关联规则挖掘结果进行对比,结果如表 1所示 (支持度为 0.5,以运动项目为后件).
从挖掘结果来看,在支持度相同的前提下,分层抽样挖掘的结果与原数据集的挖掘结果最为近似.在相同的置信度水平下(minconf≥0.95),分层抽样算法能发现原数据集下的所有的关联规则,且规则的前后件都分别相同.这说明分层抽样的样本数据与原数据集的分布较为接近,且保留了原数据集的大部分信息.随机抽样的挖掘算法在相同的置信度水平下都发现了比原数据集下更多的关联规则,这可能是因为随机抽样下的样本数据出现了数据扭曲,即随机抽取了具有较强关联度的数据,使得样本数据中出现了更多的关联规则,而有些关联规则在原数据集下是达不到相应的置信度水平的.此结果能从支持度-置信度框架下说明基于分层抽样的关联规则算法的可行性,以及与随机抽样相比下的优势性.
本文在创建挖掘结构后,用支持度-置信度框架来选择关联规则.但是,用支持度-置信度框架决定关联规则的可接受程度存在局限性,因为支持度的限制可能会使许多潜在的有意义的模式因为包含了支持度小的项而被删除,而置信度的度量可能会忽略了规则后件中出现的项集的支持度.因此,研究人员已经开始用提升度 (lift)来弥补支持度-置信度评估的缺点,它计算了规则置信度和规则后件中项集的支持度之间的比率.下面是提升度度量的统计定义 (提升度也常被称为兴趣因子):


表 1 不同算法下关联分析效果比较
然而,在某些情形下,用提升度评估关联规则也会存在局限性.例如,当 A,B项集同时出现的概率水平较高时,lift(A→B)的值会接近于 1,这表明 A,B之间是相对独立的.但事实上,当 A,B同时出现的概率水平高时,会使得 A→B的置信度水平较高,即 A,B之间存在着较强的关联,这就产生了悖论.此时,结合数据集本身的特点 (主要是数据集所表示的实际意义,而不全是它的统计特点),即所谓的领域的知识来解决这一悖论问题.本文结合领域知识,引入数据库系统中的范式理论,对关联规则的评估作进一步的探讨.
为了使有意义的关联规则不被删除掉,可以通过设置较低的支持度阀值 (minsup)而保留大部分的关联规则.这样的设置会使所产生的规则数量呈几何数量级递增,如果直接在这些规则上再使用其他评估方法,如置信度、提升度等对规则进行进一步的删减,工作量会很大.但是,如果在这之前先进行一轮删减,将会大大减轻后面的工作量.本文借鉴数据库理论中关系数据库的范式理论,并对之作部分改进以实现对规则的删减.
关系数据库第 2范式 (2NF)要求关系模式 R(U,F)中的所有非主属性都完全依赖于任意一个候选码,第 3范式 (3NF)要求关系模式 R(U,F)中的所有非主属性对任何候选码都不存在传递依赖,剔除非主属性和候选码的限制,将这 2个范式进行如下改进:
删减规则 1:X→Z且 Y→Z,其中,Y⊆X,则 X→Z规则可以删除;
删减规则 2:X→Z且 X∧Y→Z,则 X∧Y→Z规则可以删除;
删减规则 3:X→Y,Y→Z,X→Z,则 X→Z规则可以删除.
表 2是对健身数据集的抽样子集在各个支持度阀值下经过删减前后的关联规则数比较.
从表 2可以看出,经过删减规则处理后,产生的关联规则已经大大减少了,在此基础上再对规则集进行置信度和提升度的处理将变得更加有效.当然,这其中是否删减了一些在实际领域中有一定意义的关联规则,还有待于进一步检验,或许还会有更好的剔除方法.

表 2 基于范式理论的删减规则作用前后对比表
3 结 语
数据挖掘软件凭借高性能的硬件设备为数据挖掘工作带来了越来越多的便利和越来越高的速度,但若不从算法和实现方法上作改进,再好的硬件设备在面对庞大的数据海洋时也会一筹莫展.此时,统计思想和统计方法的灵活运用将会为数据挖掘工作带来事半功倍的效果.本文在关联规则挖掘算法改进中作了一定的尝试,但限于篇幅,没有对数据库的剩余部分验证挖掘结果.另外,对于如何为抽样选择合适的样本容量也有待于进一步研究.
[1]Agrawal R,I mielinski T,SwamiA.Mining association rules between sets of items in large databases[C]//Proceedings of the ACM SIG MOD Conference onManagement of data.New Bruns wick:Publishiing House ofW illey,1993:207-216.
[2]Mannila H,Toivonen H,Verkamo A.Efficient algorithm for discovering association rules[C]//AAA IWorkshop on Knowledge Discovery inDatabases of Technology.Swizerland:Publishiing House of 21stVLDB Conference Zurich,1994:181-192.
[3]Toivonen H.Sampling large databases for association rules[C]//Proceedings of the 22nd International Conference on Very Large Database.Bombay:Publishiing House ofODB,1996:134-145.
[4]李金昌.分层抽样估计精度控制方法的研究[J].统计与预测,1999(5):1-2.
猜你喜欢
车主之友(2022年4期)2022-08-27
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
南京大学学报(数学半年刊)(2020年1期)2020-03-19
海峡姐妹(2019年12期)2020-01-14
吉林大学学报(理学版)(2018年4期)2018-07-19
中国财政年鉴(2016年0期)2016-06-05
火控雷达技术(2016年1期)2016-02-06
都市丽人(2015年4期)2015-03-20
