
基于SAS的住院量灰色预测及实现
2012-03-11 14:01肖德才符湘云熊晓红余元华来瑞平谢多双
中国卫生统计 2012年4期
肖德才 符湘云 胡 荍 熊晓红 余元华 来瑞平 谢多双
住院量是衡量医院业务状况的重要指标,在医院统计工作及医院管理工作中至关重要,对其准确地预测可以为编制计划和检查计划提供可靠的依据。灰色系统GM(1,1)模型是将原始数据经过一次累加,变为较规律的数据后,再建立模型方程,对未来发展趋势进行预测。它不受一般统计模型对原始数据的种种限值,考虑影响因素少,具有较强的实用性。
资料与方法
1.资料来源 资料来源于某三甲医院的《医院统计年报》,住院量以一年内办理出院结算人次为准。
2.计算方法
(1)灰色预测模型的计算方案
①读入原始序列xt,生成一阶累加序列yt;
②调用ILM模块,计算矩阵参数a、u;
③根据矩阵参数计算预测值、绝对误差和相对误差;
④进行拟合精度评价,包括后验差检验和小概率误差检验;
⑤定义数组,对未来年份进行预测;
⑥绘制图形直观显示实测值和预测值及其趋势;
⑦输出预测结果。
(2)预测模型的拟合精度评价模型拟合精度高,方可用于外推预测。灰色预测模型GM(1,1)的拟合精度检验指标主要有后验差比值C和小误差概率P。按后验差比值C和小误差概率P综合评定模型拟合精度的标准见表1。
(3)根据上述步骤编制SAS程序,对1997年至2010年住院量进行拟合和预测。详细的SAS过程如附录:

表1 后验差比值C和小误差概率P综合评定拟合精度标准〔1〕
结 果
1.运行上述SAS程序输出结果(表2)
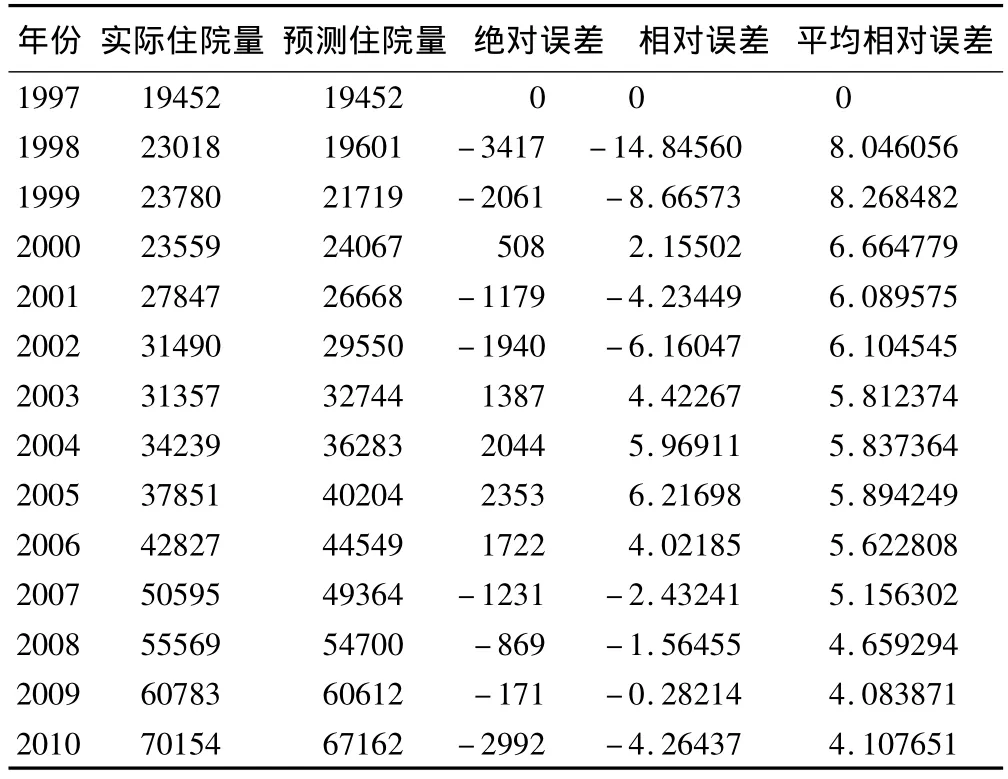
表2 历年预测及误差
2.模型拟合精度检验 1997~2010年该院住院量的预测值和实测值平均相对误差为4.11%。SAS结果显示,后验差C=0.11777,小概率误差P=1。根据表1拟合精度判断标准,可以认为该模型拟合精度为优,拟合效果非常理想,可以用于外推预测。
4.灰色模型外推,预测结果(表3)

表3 医院未来三年住院量
讨 论
灰色预测是应用最为广泛一种统计预测模型。它与一般统计模型相比,最大的优点是对样本量和概率分布没有严格的要求,且预测效果较好〔2〕。灰色模型要求有较多的矩阵计算,使其应用受到一定的限制。如果用手工计算或分步计算,不仅复杂麻烦容易出错,而且中间的结果保留精度也会给预测结果带来一定误差。SAS的IML模块具有强大的矩阵计算功能,可以通过编程实现。同时SAS的IML模块直接提供矩阵和SAS数据集间的相互转换,可以避免保留精度不同对结果的影响,使用非常简单〔3〕。
住院量的高低在很大程度上反映出医院的规模、医疗质量、技术水平、管理水平以及病人对医院的认同度等。近年来,医院逐步落实精益管理,不断促进医院内涵建设,突出医疗特色,着力打造区域性医疗中心,现已取得明显成效。医院规模不断扩大,住院量不断攀升。
文中SAS程序参考文献〔3〕,〔4〕并进行改进,增加小误差概率检验等,预测未来未来三年住院量取得良好效果。
1.郭海强,曲波,丁海龙,等.灰色系统GM(1,1)模型在我国梅毒发病预测研究中的应用.实用预防医学,2010,17(12):2398.
2.邓聚龙.灰色预测与决策.第2版.武汉:华中理工大学出版社,1998,125.
3.颜杰,相丽驰,方积乾.灰色模型及SAS实现.中国卫生统计,2006,23(1):75,80.
4.孔超,刘元凤,沈续雷.灰色预测模型的SAS程序改进.中国卫生统
计,2008,25(6):640-641.
附录:
data a1;/* 建立原始数据集a1*/
input t year xt@@;/* 读入原始数据序*/
yt+xt;/* 生成一阶累加序列*/
index=1;zt=-(yt+lag(yt))/2;/* 为数据矩阵b准备数据*/
jbi=lag(xt)/xt;/*为光滑性检验准备数据*/
datalines;
1 1997 19452 2 1998 23018 3 1999 23780 4 2000 23559 5 2001 27847 6 2002 31490 7 2003 31357 8 2004 34239
9 2005 37851 10 2006 42827 11 2007 50595 12 2008 55569
13 2009 60783 14 2010 70154
;
proc iml;use a1;/* 调用ILM模块,计算矩阵参数*/
read all var{zt index}into b where(zt^=.);/* 将 a1中变量zt和index值(不含第读入矩阵b*/
read all var{xt}into yn where(zt^=.);/* 将a1中变量xt矩阵yn*/
ahat=inv(b`* b)* b`*yn;/* 计算参数矩阵^a=〔a,u〕t=〔btb〕-1btyn*/
ahatt=ahat`;na={a u};/* 将参数矩阵转置*/
create a2 from ahatt〔colname=na〕;/*用转置后的参数矩阵数据建立sas数据集a2*/
append from ahatt;/* 将数据读入到数据集*/
quit;/* 退出iml模块*/
data a3;set a2;index=1;run;/*为预测做准备*/
data a4;set a1;if_n_=1;xt0=xt;keep xt0 index;run;
data a5;merge a1 a3 a4;by index;
if_n_=1 then xp=xt;
else do yt1=(xt0-u/a)*exp(-a*(t-1))+u/a;
yt0=(xt0-u/a)*exp(-a*(t-2))+u/a;
xp=yt1-yt0;/*计算预测值*/
end;
error=xp-xt;rerror=error/xt*100;n+abs(error);m+xt;are=n/m*100;
keep index t year xt xp error rerror are;
title'预测值与实测值对比';
proc print data=a5;run;/* 输出预测值与实测值对比,其中are为平均相对误差*/
proc means data=a5 std mean noprint;
var xt error;
output out=a5_2 std=s1 s2 mean=x_e_;
data a5_3;set a5_2;c=s2/s1;
if 0.65<c then jdu='不合格 ';
else if 0.5 <c< =0.65 then jdu='基本合格 ';
else if 0.35 <c<0.5 then jdu='合格 ';
else jdu='优';
keep c jdu;
title'后验差检验';
proc print data=a5_3;run;/*输出后验差检验结果*/
data a5_4;set a5_2;index=1;run;
data a5_5;merge a5 a5_4;by index;run;
data a5_5;do t=1 to 14;/*循环计算14年内出现小概率*/
if abs(error-e_)/s1 <0.6475 then px+1;end;p=px/14;keep p;
title'小误差概率P';
proc print data=a5_5;run;/*输出小误差概率P*/
data a6;input t year@@;/*读入预测年份*/
cards;
15 2011 16 2012 17 2013
;
data a7;merge a3 a4;
array t(5)(13 14 15 16 17);/*定义一个数组(预测年份序号)来实现循环计算*/
do i=3 to 5;
yt1=(xt0-u/a)*exp(-a*t(i-1))+u/a;
yt0=(xt0-u/a)*exp(-a*t(i-2))+u/a;
xp=yt1-yt0;output;
end;
drop t1 t2 t3 t4 t5 t6 a u b xt0 i yt1 yt0 index;
data a8;merge a6 a7;run;
data a9;set a5 a8;drop error rerror;run;proc gplot data=a9;
plot xp*year=1 xt*year=2/overlay;
symbol1 v=star i=join c=red;
symbol2 v=circle i=join c=blue;
title'Forecast and the actual contrast';
run;
proc print data=a8;/*显示预测值*/
title'预测结果';run;
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
电子产品世界(2021年6期)2021-02-10
中国卫生统计(2020年3期)2020-06-28
小学生学习指导(低年级)(2020年3期)2020-06-02
统计与决策(2019年6期)2019-04-22
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
雷达学报(2017年6期)2017-03-26
为了孩子(3~7岁)(2016年8期)2016-05-14
