
基于半监督学习的短文本分类方法
2012-07-23 00:35孙学琛高志强全志斌施嘉鸿
山东理工大学学报(自然科学版) 2012年1期
孙学琛,高志强,全志斌,施嘉鸿
(东南大学计算机科学与工程学院,江苏南京211189)
自20世纪50年代以来,人们对文本自动分类的研究获得了丰硕的成果,但这些研究都局限于长文本,对短文本分类问题涉及较少.短文本分类是一种特殊的文本分类任务,随着万维网(world wide web)的快速普及和发展,web上出现了大量短文本,例如科技文献摘要、微博和电子邮件.短文本内容短小,相互联系,已标注数据获得困难,传统分类方法已经不能适用于短文本分类场景.短文本分类对于获取数据的分布特征以及后续进一步的数据挖掘工作有重要的意义.
1 问题描述
短文本在日常生活中非常常见,例如数字化图书馆中的论文快照(包括标题、摘要、参考文献等,但不包括正文内容)、微博(少于140字)和搜索引擎片段等.本文的主要研究分类对象是论文快照(在没有特别说明的情况下,本文所指论文均指论文快照).短文本的特征主要有两个,一是内容短小,二是特征稀疏.这就导致使用传统的基于bag-of-words表示方法的分类器很难取得令人满意的效果.另外,短文本的规模一般很大,而已标注的数据却很少,利用手工方法对数据进行标注非常耗时耗力.如何利用少量的已标注数据和大量未标注数据进行学习,从而对短文本数据进行高效分类,是本文研究的主要问题.
2 相关研究
对短文本分类的研究在九十年代末才逐渐引起人们的注意,文献[1] 提出了一种使用作者信息和tweets内部特征的Twitter短文本分类方法,取得了较好的分类效果,由于采用手工寻找类别特征的方法,所以通用性较差.文献[2] 使用维基百科作为外部通用数据集,在通用数据集上使用LDA(Latent Dirichlet Allocation)获得主题模型,经过推理得到待分类短文本的主题特征向量,使用词向量和主题向量一起用于分类过程,取得了较好的分类效果.文献[3] 总结了常用的协作分类(Collective Classification,CC)方法,它将整个数据集看成实例组成的网络,网络蕴含了实例之间的联系,借助于网络结构训练分类器以提高分类性能,实验证明协作分类的效果优于基于内容的分类器.上述研究成果都侧重于关系数据使用,而没有考虑在较少已标记数据时的学习问题.半监督学习是一种利用较少已标记数据和大量未标注数据进行学习的方法.文献[4] 提出了协同训练算法,并给出了使用未标注数据学习的PAC(Probably Approximately Correct)形式分析,但它假设数据集有两个充分冗余视图很难得到满足.本文在上述相关研究工作基础上综合协同分类和半监督学习技术,提出了一种基于半监督学习的短文本分类方法.
3 基于半监督学习的迭代分类算法
在传统的监督学习中,学习器通过对大量有标记训练样例进行学习,从而建立模型用于预测未见示例的标记.随着数据收集和存储技术的飞速发展,收集大量未标记实例已相当容易,而获取大量有标记的实例则相对较为困难.如果只使用少量的已标记实例,那么利用它们所训练出的学习器往往很难具有强泛化能力.另一方面,如果仅使用少量昂贵的已标记实例而不利用大量廉价未标记实例,则是对资源的极大浪费.因此,在已标记实例较少时,如何利用大量的未标记实例来改善学习性能已成为当前机器学习研究中最受关注的问题之一.
半监督学习是利用少量标注数据和大量未标注数据进行学习的框架.由于短文本数量巨大,而且仅有少量的已标注数据,所以短文本分类本身就是一个半监督学习问题.借鉴半监督学习的思想,本文提出了基于半监督学习的迭代分类算法(semi-supervised learning-based iterative classification algorithm,SS-ICA).
3.1 数据模型
不同的分类方法对数据集模型的假设是不同的,常用的假设有两种,如图1所示.大部分只基于内容的(Content-Only,CO)分类器使用图1a所示的模型,它强调实例的独立性,实例通过它的内部特征表示,实例之间彼此是没有联系的.在分类问题中,实例的类别仅仅和它的内容相关.例如朴素贝叶斯分类器(Naive Bayes Classifier,NB).协作分类采用了如图1b所示的模型,它强调实例之间联系的重要性,在分类过程中综合利用实例的内部特征和外部关系.例如迭代分类算法[5](Iterative Classification Algorithm,ICA).本文提出的基于半监督的迭代分类算法采用了图1b所示的数据模型.
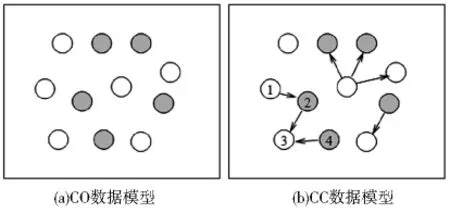
图1 文本分类数据集模型
对于图1b的模型,给出如下形式化定义.数据集由一组结点V={V1,…Vn}和一组近邻函数N描述,Ni⊆V\{Vi},N体现了整个网络的结构.V中的每个结点都是在特定领域中取值的随机变量,可以根据结点的类别是否已知将V分为已知结点集合X和待分类结点集合Y.类别的集合为L={L1,…,Lq},分类任务是为结点Yi∈Y赋予一个合理的类别,简记分类后Yi的标记为yi.
3.2 算法描述
基于半监督学习的迭代分类算法底层依赖于CO分类器.CO分类器一般要求输入特征向量有固定的维数,对于关系数据,可以采用聚合算子[3]将外部关系聚合成实例的关系属性,实例的关系属性和内部属性共同组成实例的特征向量用于训练和分类过程.下面给出基于半监督学习的迭代分类算法流程图(图2)与详细描述.

图2 SS-ICA算法流程图
1)对每个实例Vi:根据邻接关系Ni计算特征向量ai,在后续分类过程中均使用ai.
2)使用X作为训练集训练分类器f.
3)对Y中的每个实例Yi:使用f进行分类,yi←f(ai).
4)使用X∩Y作为训练集更新分类器f.
5)对Y中的每个实例Y1:根据现在的Ni重新聚合更新ai,使用f进行分类,yi←f(ai).
6)如果达到预设迭代次数或类标记稳定,则分类结束,否则执行步骤3).
ICA是一种简单有效的迭代分类方法,假定初始训练数据数目是充足的,整个训练过程都依靠使用初始训练数据训练得到的分类器f.由于f的性能和泛化能力受到已标注数据质量和数量的制约,如果初始训练数据数目较少,训练得到的局部分类器f将很难刻画真实的分类边界,迭代过程在增加外部关系作用的同时,也放大了f所带来的误差,导致整个迭代过程不能得到较高的分类精度.
SS-ICA也是一个迭代的分类过程,但是不同于ICA,迭代过程中不仅考虑到引入外部信息,同时也考虑到迭代中未标记数据对分类器本身的影响.初次用于训练的已标注数据过少,聚合后特征向量的外部关系特征不精确,训练得到的f有着一定的误差.迭代中使用f对未标注数据进行分类后,再次聚合使得向量外部关系特征被进一步丰富,更趋向真实的分布,使用更新后的数据训练分类器将会提高分类器正确分类的能力.这样就可以在迭代过程中有效地使用未标记数据.实验证明,SS-ICA方法在训练数据稀少的情况下对改善分类精度是十分有效的.
4 实验结果与分析
本文使用两个关系数据集CORA[6]和CiteSeer[7]进行试验.CORA包含了一系列计算机科学领域的学术论文(包括摘要和引用信息).CiteSeer也是一个计算机科学领域的数据集,它的引用关系密度比CORA小.两个数据集均使用文档频数方法进行特征选择,删除了单词出现次数少于10的所有单词属性.CORA和CiteSeer的详细信息见表1.

表1 CORA和CiteSeer数据集详细信息
实验使用NB和ICA与本文提出的SS-ICA方法进行了对比.其中NB分类器由WEKA[8]工具包提供,ICA和SS-ICA均采用NB作为迭代分类器,均采用计数聚合[5](Count Aggregation)作为聚合算子.实验使用选择采样技术[9]随机采样,迭代次数为10次,精度取10次采样实验的平均值.表2是在不同已标注样本比例训练集上的实验结果.

表2 各分类器在不同标注比例训练集上的性能
由表2可知,当初始已标注数据稀少的情况下SS-ICA的分类精度明显高于NB和ICA,在初始标注比例为5%时,SS-ICA要比其他分类器的分类精度高出13%以上.注意到在初始标注比例为5%时,ICA的分类精度要低于NB,这是因为标注数据稀少导致学习到的分类器泛化能力太差,而在迭代过程中分类器误差被放大导致的.
ICA和SS-ICA在CORA数据集上的分类精度要高于CiteSeer上的分类精度,这是因为前者的连接密度要高于后者,而高连接密度可以有效提高协作分类精度.由于NB只是基于内容的分类,所以在两个数据集上有着相似的性能.在总体上来看,随着初始标注数据的增多,所有分类器的误分率都呈下降趋势,两个数据集上误分率随初始标注比例变化情况如图3所示.

图3 CORA和CiteSeer数据集上的分类错误率随标注数据比例的变化情况
由于SS-ICA是ICA的一种改进,它在初始标注数据较少的情况下使用未标记数据更新分类器提高分类精度,当训练数据充足时SS-ICA和ICA能达到同样高的分类精度.SS-ICA和ICA的精度曲线如图4所示.

图4 CORA和CiteSeer数据集上分类器分类精度比较
5 结束语
面对Web上日益增多的短文本数据,人们对短文本数据的挖掘越来越重视,有效的分类短文本对获取数据的分布特征以及后续的挖掘工作都有重要的意义.短文本长度短小,特征稀疏,训练数据获得困难,导致传统分类方法不能取得令人满意的分类精度.
为了有效解决短文本分类问题,本文提出了基于半监督的迭代分类算法SS-ICA,算法综合利用了短文本内容信息和文本的引用关系,同时借鉴半监督学习中使用未标记数据的思想,在迭代过程中使用未标记数据更新修正分类器,有效提高了标注数据稀少情况下短文本分类的精度.通过在CORA和CiteSeer数据集进行实验证明,在标注数据稀少的情况下SS-ICA比NB和ICA有更高的分类精度.
[1] Sriram B,Fuhry D,Demir E,et al.Short text classification in twitter to improve information filtering[C] //Proceedings of the 33rd annual international ACM SIGIR conference on Research and development in information retrieval.Geneva:ACM,2010:841-842.
[2] Phan H X,Nguyen L M,Horiguchi S.Learning to classify short and sparse text &web with hidden topics from large-scale data collections[C] //Proceedings of the 17th Internatinal Conference on World Wide Web.Beijing:ACM,2008:91-100.
[3] Sen P,Namata G,Bilgic M,et al.Collective classification in network data[J] .AI Magazine(AIM),29(3):93-106.
[4] Blum A,Mitchell T.Combining labeled and unlabeled data with cotraining[C] //Proceedings of the 11th Annual Conference on Computational Learning Theory Madison:ACM,1998:92-100.
[5] Neville J,Jensen D.Iterative classification in relational data[C] //Proceedings of the AAAI 2000Workshop Learning Statistical Models from Relational Data.Austin:AAAI press,2000:13-20.
[6] McCallum A K,Nigam K,Rennie J,et al.Automating the construction of internet portals with machine learning[J] .Information Retrieval Journal,2000,3(2):127-163.
[7] Giles C L,Bollacker K,Lawrence S.CiteSeer:an automatic citation indexing system[C] //The third ACM conference on digital libraries,1998:89-98.
[8] Hall M,Frank E,Holmes G,et al.The WEKA data mining software:an update[J] .SIGKDD Explorations(SIGKDD),2009,11(1):10-18.
[9] Knuth D E.The art of computer Programming[M] .北京:清华大学出版社,2002:142-143.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电测与仪表(2014年15期)2014-04-04
新课程学习·中(2013年3期)2013-06-14
测绘科学与工程(2013年2期)2013-03-11
