
可重构服务承载网愈合机理研究
2012-08-06 07:57缪宇霆吴春明杨强姜明
通信学报 2012年8期
缪宇霆,吴春明,杨强,姜明
(1. 浙江大学 计算机科学与技术学院, 浙江 杭州310027;2. 浙江大学 电气工程学院, 浙江 杭州 310027;3. 杭州电子科技大学 计算机科学与技术学院, 浙江 杭州 310027)
1 引言
当今的互联网信息产业正处于高速发展状态。在传统的网络体系结构下,依靠拓展链路传输带宽,提高节点处理能力,增加节点存储容量,融入网络控制协议等升级扩展技术已经难以满足日益扩大的用户业务承载需求,并且随之产生了一系列网络复杂度快速提高和数据传输效率显著降低的问题。可重构柔性网络[1~3]——一种面向服务提供的新型网络体系结构的出现,可以使互联网摆脱传统网络技术的束缚,解决当前互联网面临的2大问题:1) 网络是刚性的,只能依靠升级和扩展;2) 网络资源是共享的,彼此之间会互相干扰。
在可重构柔性网络中,用户业务与网络服务的关系从传统的紧耦合变为松耦合:所构建网络提供服务的方式是基于网络自身的能力,而不是特定的用户业务需求,从而实现了用户与服务分离;每种网络服务可以支持多种特性相似的用户业务,新的业务可以利用原有的网络服务作为支撑,使得网络需要升级的几率大幅降低。
可重构柔性网络技术利用构建可重构服务承载网的方式来提供相应的网络服务。在服务承载网中,网络服务提供的质量直接影响用户需求的满足程度和用户请求的响应速率。因此,服务承载网需要在底层网络发生故障时快速愈合,才能尽可能快地恢复正常的网络服务供应,维持终端用户继续正常地获取他们所订阅的服务。
本文研究了服务承载网的快速愈合机理并提出了服务承载网的快速愈合算法。该算法区别于传统的对失效服务承载网进行全局重映射的方法,它通过引入多商品流问题[4](multi-commodity flow problem)的解决策略,将服务承载网愈合的问题转化为多商品流问题,通过解一次多商品流问题愈合多个损坏的服务承载网,以实现承载网发生故障时的快速愈合,从而使得服务承载网具有快速可重构这一特性。该方法可以提高服务承载网的愈合成功率,降低愈合时的时间消耗,并且可以保持整个底层网络在服务承载网愈合之后的负载均衡。
2 相关工作
通常,服务承载网可被认为是一种面向不同用户提供差异化服务的虚拟网络,用于满足用户对服务的个性化需求。利用网络虚拟化技术可构建多个提供异质服务的承载网,并同时共享底层物理网络的资源。因此,可以认为网络虚拟化技术是实现服务承载网构建、运行和维护的重要技术实现方式。
众所周知,目前基于网络虚拟化技术的服务承载网构建问题大部分是 NP完全(NP-complete)问题。近年来启发式算法和线性规划方法的出现[5~10],初步解决了此类问题存在计算复杂度高的问题。目前,网络虚拟化技术在服务承载网构建方面的应用研究仍集中在如何实现网络映射和优化资源利用方面,且已存在较多成熟机制与算法,但对于在故障情形下的服务承载网愈合问题尚缺乏有效手段。已有的用于解决服务承载网愈合问题的解决方案仍采用全局重新映射的方法。该方法利用文献[7]中提出的构网算法,将失效的服务承载网依次进行节点重映射和链路重映射。其愈合效果等效于将整个服务承载网在底层物理网络之上进行一次重新映射。这将导致服务承载网愈合速度慢,且将严重影响和干扰其他虚拟网的正常运行和端到端的服务提供。
本文认为,可重构服务承载网的快速愈合问题既是承载网重构(重映射)问题,同时也与其自身抗毁性相关。近几年来,虽然服务承载网抗毁方面的研究也取得了较多成果[11~13],但仍然存在诸多不足之处。文献[11]提出了一种基于分布式 Agent的虚拟资源自管理机制,用于监控运行于底层网络上方的服务承载网是否发生故障,并且也提出了承载网“愈合”的概念,但是并没有给出具体的愈合方法。文献[12]设计出了一种基于共享备用资源的服务承载网保护方法,该方法按照预先给每个承载网分配一定数量的备用网络资源,用于避免在底层网络发生故障时带来的承载网失效问题。这种方法可以看作是一种离线的服务承载网保护方法,不能很好地解决在线的承载网失效问题。文献[13]给出的网络环境中错误诊断的策略主要基于及时发现并解决底层网络中出现的硬件故障的方法来恢复失效的服务承载网。当某些硬件故障受客观条件限制不能被及时修复时,就会降低服务承载网恢复的效率。
总的来说,成熟的服务承载网愈合方法还未被研究,现存的愈合方法基本上等价于传统的构网算法,即在底层网络发生故障时对失效的服务承载网进行全局重映射;此外,服务承载网抗毁性方面的研究大部分又基本上是基于共享资源保护方面的策略,并未具体实现服务承载网的愈合方法。本文针对服务承载网愈合方法研究的不足,提出了基于多商品流问题思想的可重构服务承载网快速愈合算法,旨在提高服务承载网的愈合能力,加快服务承载网在遭遇故障时的愈合速率,以及缩小服务承载网在愈合时的重构规模。
3 问题描述
随着网络虚拟化研究的深入,网络映射问题的定义已经变得非常成熟。本节给出了物理网络,服务承载网以及服务承载网映射问题的公式化定义,以便在第4节更加清晰地描述可重构服务承载网的快速愈合机制。为了方便起见,本文采用文献[8]中提出的网络映射的问题描述。
3.1 物理网络
3.2 服务承载网
3.3 服务承载网到物理网络的映射
服务承载网 Gv到物理网络 Gp的映射M可以定义如下:找到一个 Gp的子图 Gp'= ( Np',Lp'),使得所有的虚拟节点都被映射到不同的物理节点,并且所有的虚拟链路都被映射到由若干物理链路构成的无环物理路径,即:
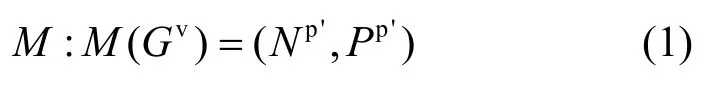
其中, Np'表示物理节点的子集, Pp'表示物理网络中的无环物理路径的集合。M可以进一步分解为节点映射以及链路映射:
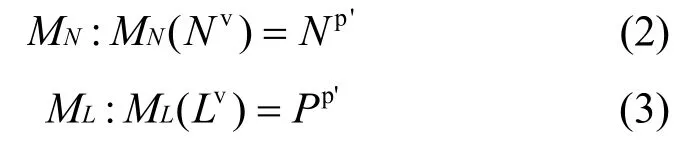
若M( Gv)满足以下2个限制条件:
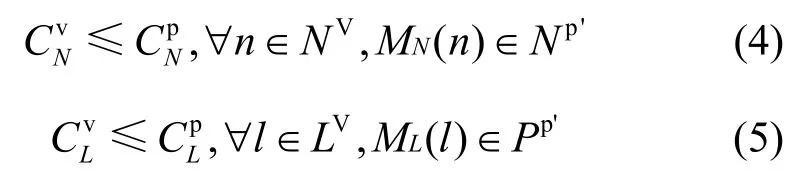
则M是一个合法的网络映射。
4 可重构服务承载网的快速愈合机制
服务承载网在满足用户需求的程度和响应用户请求的速率这2个方面都有着极高的要求。因此,服务承载网必须在底层网络发生故障时快速愈合,才能尽可能快地恢复正常的网络服务供应,从而使终端用户正常地获取他们所订阅的服务。在研究可重构服务承载网快速愈合机制的过程中,仅仅设计出一种服务承载网的快速愈合算法还不能满足复杂多变的网络环境,必须加入一套辅助快速愈合算法运行的机制,才能保证可重构服务承载网快速愈合算法达到迅速、可靠、高效的预期目标。本节将详细介绍可重构服务承载网快速愈合机制的3个重要组成部分:底层物理网络设备可靠性的评估方法,服务承载网的快速愈合算法和未能实时愈合的服务承载网的排队策略。
4.1 物理网络设备可靠性评估
服务承载网快速愈合的问题在某种程度上也可以看作是网络重映射的问题,目的是把一些映射在发生故障的物理设备(物理节点、链路)之上的虚拟节点、链路重映射到正常工作的物理设备。如果在进行重映射之后,无法保障这些新的用于支持虚拟节点、链路的物理设备的可靠性,那势必会影响到服务承载网愈合后的正常工作。因此,必须尽可能地把这些失效的虚拟节点、链路映射到可靠性高的物理设备之上,以保证服务承载网愈合的稳定性。为此,本文设计了2个集中式的容器用来分别记录整个底层网络中曾经发生过故障的物理节点和物理链路,称之为节点容器和链路容器,并采用基于“局部性原理(locality principle)”的“最近最少故障(least recent failed)”策略来评估这些物理设备的可靠性。如图1所示,该策略规定,最近一次发生故障的物理设备的标识符会被记录在容器顶端(图中标记为top)。
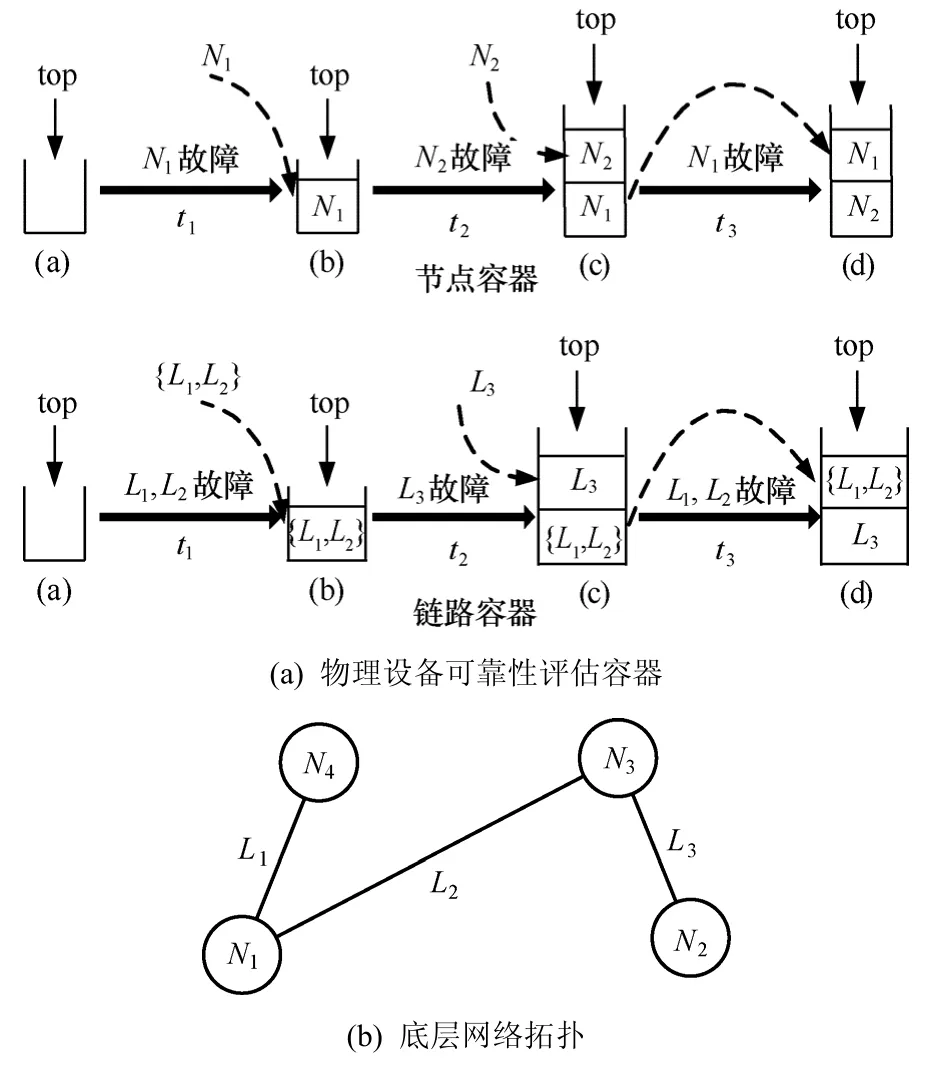
图1 可靠性评估示例
图1(a)给出了图1(b)中所示的底层网络的节点容器和链路容器,初始状态均为空。在t1时刻,节点 N1发生故障,根据评估策略,N1的标识符被加入到节点容器的顶端,与N1相连的链路L1, L2受到N1故障的影响而无法正常使用,所以被对应地加入到链路容器的顶端;在 t2时刻,节点 N2第一次发生故障,因此N2的标识符被加入节点容器中并被记录在顶端,与N2相连的链路L3也被加入到链路容器的顶端,L1, L2相应地下降一个位置;t3时刻的情况类似t1,节点容器顶端被N1的标识符占据,因为N1又发生了一次新的故障,同时L1, L2也被移动到链路容器的顶端。
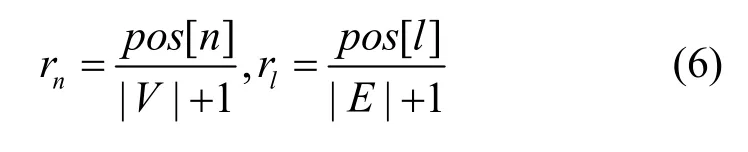
物理节点n或物理链路l的可靠性可以按如下方法定义:其中,|V |和|E|分别表示物理网络中节点和链路的总数, p os[ n], p os[ l]代表物理节点n或物理链路l在各自容器中的位置索引。如图1(a)所示,物理节点 N 1的位置索引为 1, N2的位置索引为 2,即pos[ N1]= 1 , p os[ N2] = 2 ;物理链路 L1, L2的位置索引均为 1, L3的位置索引为 2,即 p os[ L1] =pos[ L2]= 1 , p os[ L3] = 2 。根据式(6)可知,rN1= 0 .2,rN2= 0 .4,rL1= rL2= 0 .25,rL3= 0 .5。显然,如果某个物理节点或某条物理链路从未发生过故障,那么它也不可能被记录在该容器中,此时本文规定这样的物理设备的可靠性固定为1。
4.2 服务承载网的快速愈合算法
通常来说,底层网络节点或链路的故障会导致当前的网络映射(虚拟节点、链路映射)不能正常使用,从而发生服务承载网无法正常提供服务的情况。本文的核心工作是研究失效服务承载网的快速愈合算法。该算法会尽可能多地保留原有的可用网络映射,从而避免将失效的服务承载网进行全局重映射。首先讨论由物理链路故障造成服务承载网失效的问题,再讨论由物理节点故障造成服务承载网失效的问题。因为物理节点的故障同时也会导致所有连接到它的物理链路也发生故障。
4.2.1 物理链路故障
当承载虚拟链路的物理链路发生故障时,这些虚拟链路所对应的服务承载网就会无法正常工作。应对这种情况最直接的方法是找出所有因链路故障而发生状况的服务承载网,并将这些承载网依次进行重映射,包括重映射每个承载网的所有虚拟节点和虚拟链路,并完全忽略那些没有受影响的虚拟节点、链路映射。值得注意的是,在通常情况下,大多数发生状况的服务承载网中的虚拟节点、链路映射依然可以正常工作。如果底层网络的管理者把这些可用的网络映射先保存起来用于重用,将是一个不错的选择。更重要的是,虚拟链路通常是被映射在一些由连续的物理链路构成物理路径之上。这意味着虚拟链路通常只是被部分映射在某条物理链路之上。因此,单个物理链路故障极有可能只是引发了用于承载虚拟链路的物理路径的某一段不能正常使用。如图 2所示,物理链路发生故障导致虚拟链路映射在其上方的片段不能正常工作,而映射在物理链路上的部分则不受影响。事实上,一个失效的服务承载网中的大部分网络映射是可重用的,这也为提高服务承载网的愈合的效率,实现其可重构的特点提供了可能。
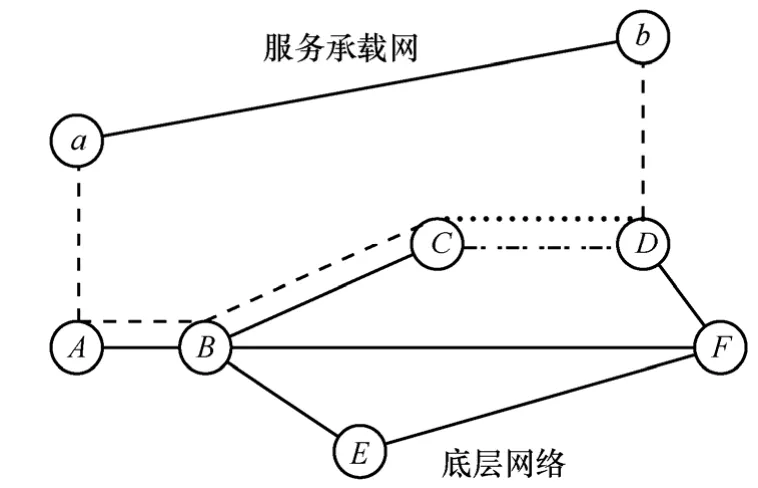
图2 虚拟链路部分故障
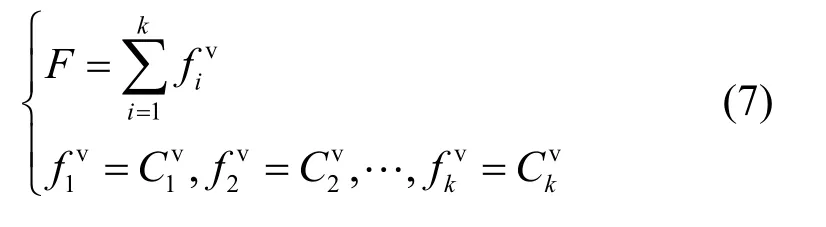
在得到一组可行解之后,只需要把不同的商品流所经过的物理路径加入到它们所对应的服务承载网映射中,即可完成服务承载网的愈合。
利用多商品流问题解决服务承载网的愈合问题可以有效地在愈合过程中减轻底层网络的负载,并且显著地提高服务承载网愈合的成功率,因为这种方法允许将一条虚拟链路映射到多条物理路径之上[8]。更重要的是,以上r个服务承载网的愈合只需要通过解一次多商品流问题即可解决,这也在很大程度上提高了服务承载网的愈合效率。
服务承载网愈合问题等价地转化为多商品流问题解决还需要考虑以下3个方面的问题。
1) 数据分组的乱序:多商品流问题的解决方案允许将一条虚拟链路映射到多条物理路径之上,从而带来了数据分组从源到汇传输的过程中发生乱序(out-of-order)的可能。所需要做的额外工作是在愈合机制中加入一些防止数据分组在进行传输时发生乱序的控制方案[14~16]。
2) 可行解不存在:如果当前网络中的资源紧张,不存在满足式(7)中限制的多商品流可行解时,可以选择减小总流量F的方法,从而先愈合部分服务承载网。底层网络管理者可以根据服务承载网所提供网络服务的类型,适当减小总流量F的大小。例如,若服务承载网 1V和 2V提供的是非实时响应的服务,则可以从F中去掉这2个流量。在F减小之后,再用多商品流问题的解愈合剩下的服务承载网。
3) 流的选择:利用多商品流解决服务承载网的愈合问题有可能产生多组可行解,即在源和汇之间存在多种传输商品流的方案。这时需要选择可靠性最高的一种。假设一个商品流的传输方案需要经过n个物理节点和l条物理链路,那么该商品流传输方案的可靠性φ定义为
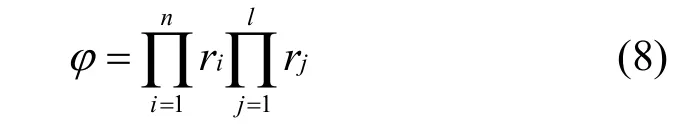
其中,ir和jr分别代表物理节点和链路的可靠性(式6),其中, ir和jr的大小均不大于1。式(8)意味着如果多商品流问题的解所经过的物理节点和链路越少,那么这条商品流的可靠性就越高。这是因为如果商品流传输路线上的任意一个节点或链路发生故障,这条商品流就不可能达到预期的流量,所以它所经过路线上的任何一个节点或链路都不能发生故障,才能保证这条商品流的正常传输。
服务承载网 v1,v2各虚拟链路的需求带宽以及底层网络PN的物理链路带宽如图3所示。为更方便地描述服务承载网的愈合过程,图中不考虑物理节点的能力值物理链路发生故障引发 v1,v2的虚拟链路映射不可用。服务承载网快速愈合算法会在节点B和F之间解一个流量大小为的多商品流问题,并得到一组可行解:流量为3的流 f1通过物理路径传输;流量为4的流 f2通过物理路径传输,这2条物理路径各自传输的流量大小均为2。最后更新与这2个商品流对应的虚拟链路映射,得到至此,服务承载网 v1,v2愈合完成。

图3 链路故障引发的服务承载网愈合
4.2.2 物理节点故障
在讨论完由物理链路故障导致服务承载网失效及其愈合算法之后,服务承载网因物理节点故障发生失效,并进行愈合的问题就变得相对简单。概括地讲,只需要把那些映射在故障物理节点上的虚拟节点转移到其他合适的物理节点,再更新那些因重映射虚拟节点而发生变化的虚拟链路映射即可完成服务承载网的愈合。
选择合适的物理节点进行虚拟节点重映射需要考虑以下3个方面的问题。
1) 可靠性:新物理节点的可靠性直接影响到服务承载网愈合的过程可靠程度。如果新的物理节点经常发生故障,则需要再次更换物理节点用作虚拟节点的重映射。
2) 资源:应该尽可能地把虚拟节点转移到那些拥有更多资源的物理节点上,这样可以有效的保持底层网络的负载均衡,并且提高网络资源的利用率。物理节点n的资源 nR定义如下:

3) 距离:新的物理节点与发生故障的物理节点的距离对服务承载网的愈合也存在一定的影响。如果距离发生故障的节点太近,有可能会存在可用物理链路过少的隐患;如果距离发生故障的节点太远,则在服务承载网愈合之后,会存在数据分组传输距离过远的问题。
综合1)和2),定义物理节点的价值:

其中,l→n表示物理链路l与物理节点n相邻接,rn 与 rl的定义见4.1节;根据3),本文限定新物理节点的选择范围H,H代表新物理节点与距离故障物理节点之间的跳数。选择H范围内具有最高节点价值ψ的物理节点,用于虚拟节点的重映射。虚拟节点重映射完成之后,虚拟节点映射的变化会导致原来与该虚拟节点相关的虚拟链路不可用,必须对这些虚拟链路也进行重映射,才能完成服务承载网的愈合。先记录下与发生故障的物理节点存在虚拟链路映射关系的物理节点,然后在选择完新的物理节点之后,恢复新物理节点与那些被记录的物理节点之间的虚拟链路映射。可以采用直接重映射的方法进行一对一(一条虚拟链路对一条物理路径)的映射,也可以采用多商品流的思想进行一对多(一条虚拟链路对多条物理路径)的映射。重映射方法的选择取决于网络中资源的数量。
假设有一条物理节点 Np发生故障,有k个虚拟节点映射在 Np上,记为这k个虚拟节点分别包含在r个不同的服务承载网中,记为V1, V 2 ,… ,Vr( r = k)(r = k 是因为同一服务承载网的虚拟节点必须映射到不同的物理节点)。物理节点Np的故障会导致这k个虚拟节点的映射变得不可用,同时这k个服务承载网也将不再正常工作。本文将进行k次恢复工作,对于第 i(1 ≤ i≤k)次恢复,愈合算法都会选择与 Np距离在H之内,并具有最高ψ值的物理节点用来重映射虚拟节点,并更新受到影响的虚拟链路,来完成对应服务承载网 Vi的愈合工作。在服务承载网 Vi愈合之后,都会更新网络中各个物理节点的ψ值,来为下一个承载网Vi+1的愈合做好准备。
服务承载网 v1各虚拟链路的需求带宽以及底层网络PN的物理链路带宽如图4所示。为更方便地描述服务承载网的愈合过程,图中同样不考虑物理节点的能力值。物理节点F发生故障引发服务承载网 v1的虚拟节点映射 M1( b ) = F 不可用。快速愈合算法在距离F固定为 2跳的范围内( H = 2 )选择节点B或节点C用作虚拟节点重映射。假设2个节点的可靠性分别为 rB=0.5, rC=1。底层网络中剩余的4条物理链路的可靠性均为1。根据式(10)可知节点B和节点C价值的大小关系为ψB<ψC。虚拟节点b映射到C之后( M1( b) = C ),愈合算法随之更新转移虚拟节点而发生变化的虚拟链路映射,将更新为从而完成v1的整个愈合过程。

图4 节点故障引发的服务承载网愈合
4.3 未能实时愈合的服务承载网的排队策略
在详细介绍完服务承载网的快速愈合算法之后,还必须为那些受物理网络资源限制,未能及时愈合的服务承载网建立一套合理的排队调度策略,用于尽快处理那些服务承载网等待愈合的请求。利用一个优先级队列来存储承载网等待愈合的请求,这些请求按照到达的时间顺序被加入到队列中。该队列采用一种称为“可恢复优先(restorable first)”的调度策略来进行管理:底层网络的管理者会周期性地按序处理队列中的若干请求,一次周期内处理请求的数量取决于底层网络的处理能力。如果当前请求所指向的服务承载网可以愈合,则该请求会得到迅速响应,并在服务承载网愈合之后被移出队首;否则,该请求会被移动到队尾。这种调度策略可以第一时间判断当前的网络资源是否能满足队首的服务承载网愈合请求,从而在整体上降低了愈合请求的平均等待时间。
图5详细描述了“可恢复优先”调度策略的工作流程。假设在一个底层网络的处理周期T内可以处理2个服务承载网愈合请求,并且请求队列在初始状态存有4个请求: 1m(队首), 2m, 3m和 4m,分别代表第1到第4个请求。在第1个处理周期内,m1得到处理并被弹出队列,因其对应的服务承载网已成功愈合。m 2被移动到队尾,代表目前网络中的资源还不能支持其对应承载网的愈合工作;在第 2个处理周期内, m 3和 m 4都被弹出队列,代表它们对应的承载网都可以成功愈合。并且又有一个新的请求 m 5按照到达队列的时间先后顺序被加入到队尾,代表 m 5对应在承载网在愈合算法执行后未能成功恢复。
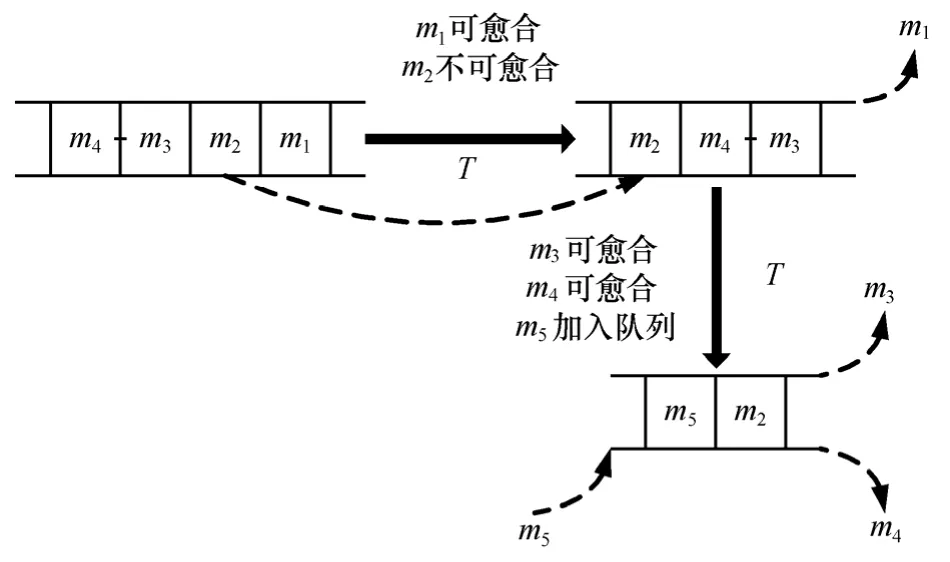
图5 愈合请求队列调度
5 实验数据与性能评估
在本节中,本文通过C++编程语言实现了服务承载网的快速愈合算法,并通过大量的仿真实验对其在愈合成功率、愈合效率以及对底层网络负载均衡的影响3个方面进行了性能评估。本文还将服务承载网的快速愈合算法与传统的应对服务承载网故障时的全局重映射方法进行了对比,并通过实验数据说明本文提出的算法比传统的全局重映射算法在性能上有了一定的提高。
5.1 实验环境部署
1) 底层物理网络:底层物理网络的拓扑结构由GT-ITM[17]拓扑生成工具生成:物理网络包含50个节点,每个节点之间的连接概率为25%,即物理网络包含300条物理链路。物理节点的能力和物理链路的带宽在区间[15,20]内服从均匀分布。在进行仿真实验的过程中,物理节点故障次数和物理链路故障次数的比例为 1:4。这些故障均发生在事先预定的时间点。物理节点和链路的初始可靠性均为 1。物理设备故障:在实验的过程中,预设了 50次物理设备故障,包括10次物理节点故障和40次物理链路故障。这些故障会在每个固定的时间按顺序发生,并且发生过故障的节点和链路在实验过程中不会被修复。
2) 服务承载网:在仿真实验环境中,假设同时存在 50个拥有随机拓扑结构的服务承载网运行在共享的底层网络之上。这些承载网的虚拟节点的能力需求以及虚拟链路的带宽需求在区间[5,10]内服从均匀分布。在仿真实验的过程中,通过服务承载网快速愈合算法来恢复因物理设备故障导致的承载网。
5.2 仿真实验数据
仿真实验比较了服务承载网快速愈合算法和传统的全局重映射方法在成功率,效率以及负载均衡3个方面的性能。从实验图表来看,仿真实验会在第10次、第20次、第30次、第40次以及第50次物理发生故障的时间点上对比两者在这3个方面的性能。
1)愈合成功率:服务承载网愈合的成功率SR定义如下,

其中,Fv代表失效的承载网个数,Sv代表通过愈合算法成功恢复的承载网个数。如图6所示,快速愈合算法在整个服务承载网的愈合过程中保持了约85%的平均恢复成功率,而传统的全局重映射算法的平均成功率仅有大约70%。特别是当物理网络故障越来越多时,全局重映射算法的愈合成功率急剧下降。这是因为当物理网络中的资源紧缺时,快速愈合算法大量地重用了先前的网络映射,并允许虚拟链路进行一对多的映射,充分利用了网络中的剩余资源。而全局重映射算法只能进行虚拟链路的一对一映射,导致网络中一些剩余的带宽不能被充分利用,所以愈合成功率会大幅度下降。
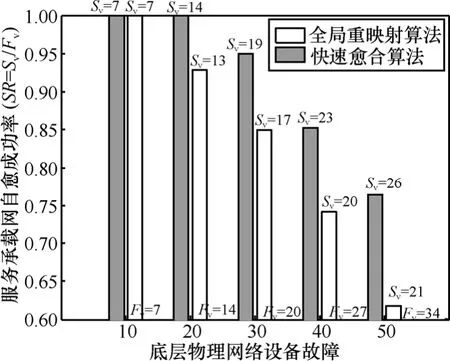
图6 服务承载网愈合成功率
2) 愈合效率:在本文的仿真实验中,通过比较2种算法在愈合每个失效的服务承载网时所消耗的平均时间来进行算法的效率评估。从图7显示的实验结果可以看到,使用快速愈合算法进行愈合的服务承载网的平均愈合时间约为0.5s左右,而使用全局重映射算法进行愈合的服务承载网的平均愈合时间为0.7s左右,快速愈合算法的运行效率比全局重映射算法的效率提高了近30%。这是因为快速愈合算法可以在一次运行的过程中愈合多个服务承载网,而全局重映射算法只能一次愈合一个服务承载网。
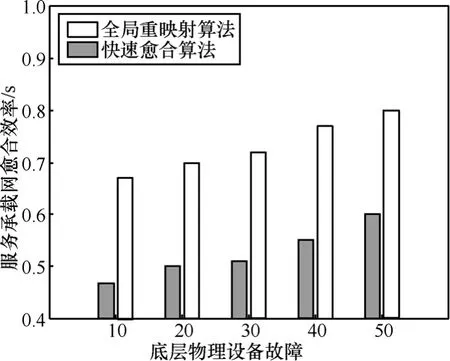
图7 服务承载网愈合效率
3) 负载均衡:底层网络的负载均衡Ω包含物理节点的负载均衡NΩ以及物理链路的负载均衡LΩ,本文用标准差的形式来定义这3种负载均衡,定义如下:
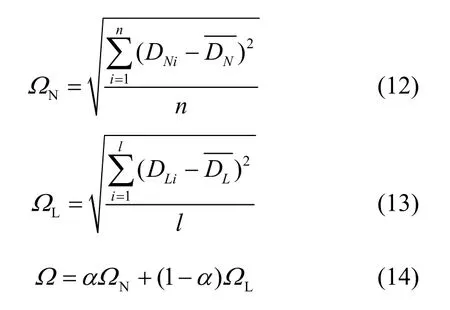
其中, D Ni表示物理节点 N i用于虚拟节点映射之后的剩余能力,代表底层网络中所有n个物理节点剩余能力的平均值;类似地, D Li表示物理链路 Li用于虚拟链路映射之后的剩余带宽,代表底层网络中所有l个物理链路剩余带宽的平均值。显然,根据标准差的特点,虚拟节点和虚拟链路分配在各个物理节点和物理链路之上的程度越是平均,底层网络的负载就越是均衡。对应地,ΩN, ΩL,Ω三者的值就越趋近于0。在仿真实验中,参数α的值由物理节点和物理链路发生故障的比例决定。因为节点故障和链路故障发生次数的比例为1:4,所以α=20%。图8给出了在服务承载网愈合之后,底层网络中节点、链路以及全局负载的变化趋势。从图中可以看到2种算法在对物理节点负载的变化趋势方面的影响基本相同,这是因为2种算法所采用的虚拟节点重映射策略基本相同,都是选择一个适当的物理节点用作虚拟节点重映射。由于快速愈合算法允许虚拟链路进行一对多的映射,可以将虚拟链路相对平均地分配在各条物理链路之上,充分利用了网络中的剩余带宽,所以在服务承载网愈合之后,物理链路负载的增长趋势较为缓慢;而全局重映射算法只能进行一对一的链路映射,不能充分利用网络中的剩余带宽,所以在服务承载网愈合之后,物理链路负载的增长趋势比较明显。在本文的实验环境中,有80%的故障都来自物理链路,所以底层网络的全局负载主要受物理链路负载的影响。因此,两者的增长趋势也较为接近。
4) 网络规模变化:图9~图11分别给出了当网络规模发生变化时,即底层网络物理节点和服务承载网的数量分别同时增加10%、20%、30%、40%、50%时(物理节点依然保持25%连接率),2个算法在底层网络50次故障全部发生之后在愈合成功率,效率以及对底层网络全局负载 3个方面的变化趋势。从实验结果可见,随着网络规模逐渐的增大,2个算法在愈合成功率和负载均衡方面的差异越来越小。这是因为在大规模网络环境中底层网络资源丰富,当底层网络发生故障时,并不会导致网络资源的稀缺,快速愈合算法在网络资源稀缺时体现的性能优势相对弱化,所以在愈合成功率和负载均衡方面的差异变小;相反,当小规模网络发生故障时,很可能引起底层网络资源的稀缺,而快速愈合算法可以充分利用底层网络剩余资源,所以快速愈合算法在小规模网络环境中的性能更加突出。此外,服务承载网愈合效率,即愈合平均时间,是由算法的复杂度所决定。因为 2个算法的复杂度相同,所以当网络的规模逐步从10%扩大到50%时,2个算法在愈合效率方面的差异变化并不明显。

图8 底层网络全局负载
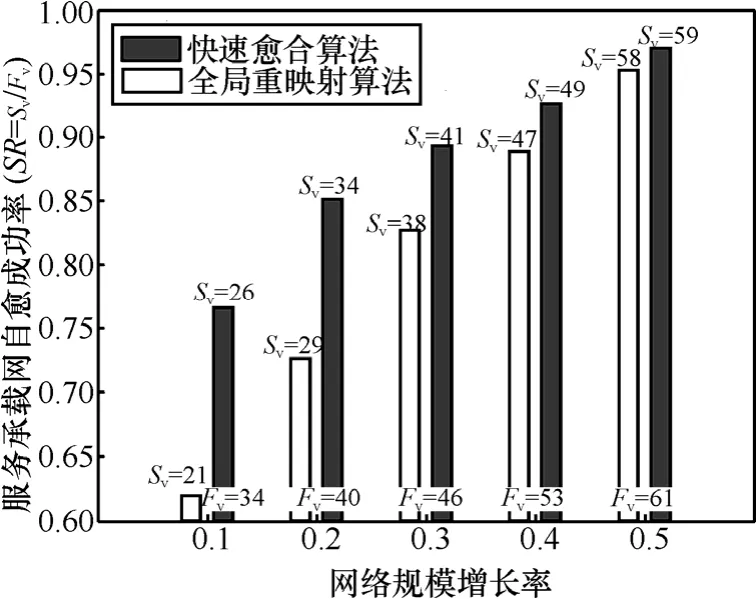
图9 网络规模变化下的服务承载网愈合成功率

图10 网络规模变化下的服务承载网愈合效率

图11 网络规模变化下的底层网络负载
6 结束语
本文研究了可重构服务承载网的快速愈合机制,通过部分调整失效的虚拟节点或链路映射来愈合失效的服务承载网,避免了从全局上进行服务承载网重映射的繁琐工作。该方法基于网络流的思想,将服务承载网的愈合问题转化为多商品流问题加以解决,并通过解一次多商品流问题同时恢复所有失效的承载网,极大地提高了服务承载网愈合的成功率和效率,并且保持了底层网络的负载均衡。通过大量的仿真实验数据表明,该算法与传统的全局重映射方法相比,能更高效地提高服务承载网的愈合成功率和愈合效率,并可显著降低对底层网络负载的影响。
[1] ANDERSON T, PETERSON L, SHENKER S, et al. Overcoming the Internet impasse through virtualization[J]. IEEE Computer Magazine,2005, 38(4): 34-41.
[2] GENI[EB/OL]. http://www.geni.net/.
[3] BAVIER A, FEAMSTER N, HUANG M, et al. In VINI veritas: realistic and controlled network experimentation[A]. Proc ACM SIGCOMM[C]. Pisa, Italy, 2006.
[4] AHUJA R K, MAGNANTI T L, ORILIN J B. Network Flows: Theory,Algorithms, and Applications[M]. Prentice Hall, 1993.
[5] SZETO W, IRAQI Y, BOUTABA R, A multi-commodity flow based approach to virtual network resource allocation[A]. Proc of IEEE Global Telecommunications Conference (GLOBECOM’03)[C]. San Francisco, CA (USA), 2003. 3004-3008.
[6] FAN J, AMMAR M. Dynamic topology configuration in service overlay networks-a study of reconfiguration policies[A]. Proc of IEEE INFOCOM06[C]. Barcelona, Spain, 2006. 1-12.
[7] ZHU Y, AMMAR M. Algorithms for assigning substrate network resources to virtual network components[A]. Proc of IEEE INFOCOM06[C]. Barcelona, Spain, 2006. 1-12.
[8] YU M, YI Y, REXFORD J, et al. Rethinking virtual network embedding: substrate support for path splitting and migration[A]. Proc of ACM SIGCOMM[C]. 2008. 17-29.
[9] CHOWDHURY N M M K, RAHMAN M R, BOUTABA R. Virtual network embedding with coordinated node and link mapping[A]. Proc of IEEE INFOCOM09[C]. Rio de Janeiro, Brazil, 2009. 783-791.
[10] LISCHKA J, KARL H. A virtual network mapping algorithm based on subgraph isomorphism detection[A]. Proc of ACM SIGCOMM[C].Barcelona, Spain, 2009.
[11] FAJJARI I, AIARI M, BRAHAM O. Towards an automatic piloting virtual network architecture[A]. Proc of IFIP International Conference on New Technologies, Mobility and Security (NTMS)[C]. Paris,France, 2011.
[12] GUO T, WANG N, MOESSNER K. Shared backup network provision for virtual network embedding[A]. Proc of IEEE ICC2011[C]. Kyoto,Japan, 2011.
[13] YALIAN P, XUESONG Q, SHUNLI Z. Fault diagnosis in network virtualization environment[A]. Proc of 18th Conference on Telecommunications (ICT)[C]. Ayia Napa, Cyprus, 2011.
[14] AVRAMOPOULOS I, SYRIVELIS D, REXFORD J, et al. Secure Availability Monitoring Using Stealth Probes[R]. Princeton University,Technical Report TR-769-06, 2006.
[15] FELDMANN A, GREENBERG A, LUND C, et al. Netscope: tra_c engineering for IP networks[J]. IEEE Network Magazine, 2000,14(2):11-19.
[16] AUGUSTIN B, CUVELLIER X, ORGOGOZO B, et al. Avoiding traceroute anomalies with paris traceroute[A]. Proc of Internet Measurement Conference[C]. New York, NY, USA: ACM Press, 2006.153-158.
[17] ZEGURA E W, CALVERT K L, BHATTACHARJEE S. How to model an internetwork[A]. Proc of IEEE INFOCOM[C]. Francisco,CA , USA, 1996.594-602.
猜你喜欢
井冈教育(2022年2期)2022-10-14
军民两用技术与产品(2022年2期)2022-06-01
移动通信(2021年5期)2021-10-25
空间科学学报(2020年3期)2020-07-24
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·中考版(2017年12期)2017-04-18
中学生(2015年2期)2015-03-01
中国交通信息化(2014年3期)2014-06-05
小说林(2014年5期)2014-02-28
电影新作(2014年5期)2014-02-27
