
基于循环策略和动态知识的deep Web数据获取方法
2012-11-06 11:40鲜学丰崔志明赵朋朋梁颖红方立刚
通信学报 2012年10期
鲜学丰,崔志明,赵朋朋,梁颖红,方立刚
(1. 苏州大学 智能信息处理及应用研究所,江苏 苏州 215006;
2. 江苏省现代企业信息化应用支撑软件工程技术研发中心,江苏 苏州 215104;
3. 苏州市职业大学,江苏 苏州 215000)
1 引言
目前主流搜索引擎还只能搜索 Internet表面可索引的信息,在 Internet深处还隐含着大量通过主流搜索引擎少量或无法涉及的海量信息,这些信息称之为深层网页(deep Web,又称为invisible Web 或hidden Web)[1]。Deep Web的信息一般存储在服务器端的Web数据库中,与静态页面相比通常信息量更大、主题更专一、信息质量和结构更好。为了方便用户快捷高效地使用deep Web信息,国内外学者对deep Web数据集成进行了广泛的研究[2~4]。Deep Web数据集成的一种方案是与构建传统搜索引擎一样,将deep Web数据库中的内容爬取出来,存储到本地数据库中并建立索引,它能在最短时间内响应用户的查询要求[5]。目前,这种方案在许多特定领域已成为deep Web数据集成研究的主流。由于集成系统可能需要集成数十个甚至更多的deep Web数据源,因此,该方案中一个关键并十分有挑战性问题是如何高效地获取deep Web数据。
目前,deep Web数据集成的实现方法为:首先独立穷尽获取每一个待集成的deep Web数据源,然后通过数据清洗、实体识别、合并去重等步骤完成获取数据的集成。这种实现方法在数据获取方面主要存在2个缺陷:1) 每个数据源数据获取的后期代价十分巨大,花费较大的代价仅仅获取极少的新数据,同时数据集成时需要处理来自不同数据源的大量重复数据,数据集成的代价也非常巨大;2) 每个数据源的数据获取独立进行,爬虫主要依据该数据源已获取数据的统计信息进行查询选择[6~8],由于统计信息缺乏和查询候选池有限,该方法存在查询选择的准确性较差、数据获取覆盖率较低等问题。
经研究发现,集成系统中待集成的数据源之间并不是相互独立的,而是相互关联。数据源之间数据相互覆盖,甚至一些数据源之间相互依赖,例如:现实世界一些商业数据源彼此分享数据。根据这种关联关系,进一步研究发现同领域deep Web数据源之间具有2个重要特征。特征1:在集成环境中,从某一数据源获取的数据,可能从另一个或一些待集成的数据源中获取,因此从某一数据源数据获取后期获取的数据,可能出现在另一个或一些数据源数据获取的前期或中期;特征 2:同领域的数据源之间具有相似的属性值并且这些属性值也具有相似的分布特征。基于上述发现本文提出一种基于循环策略和动态知识的数据获取方法。该方法根据特征1提出使用循环策略分多次完成数据源的数据获取,当获取某一数据源的效率下降到某一阈值时,停止该数据源的数据获取,爬虫开始获取下一个数据源的数据,依次类推直到把所有待集成数据源都获取一遍;然后再重复上述过程,直到所有待集成数据源都已达到结束获取条件。该方法使一部分应该从一些数据源数据获取后期获得的,从另一些数据源数据的前期或中期获得。与传统一次性穷尽数据获取方法相比该方法能减少数据源后期的数据获取,降低了数据获取的代价,同时也能减少重复数据的获取,降低了数据集成的代价。根据特征 2提出利用集成系统已获取的数据动态构建知识,并设计基于集成系统动态知识的查询选择方法。该方法丰富了查询选择的知识,提高了查询选择的准确性,同时扩展了查询候选池,提高了数据获取的覆盖率。结合循环策略和动态知识进行数据获取时,对于每个数据源可以多次利用丰富后的集成系统动态知识进行查询选择能有效率提高查询选择的准确性,从而提高数据获取的效率。
事实上,不同领域的数据源之间也可能存在一定的关联关系,对存在关联关系的不同领域的数据源进行数据获取时,仍可以使用本文提出的基于循环策略和动态知识的数据获取方法提高数据获取的效率。但是由于同领域数据源之间的关联关系一般强于不同领域的数据源,所以同领域deep Web数据集成时使用本文提出方法的效率更高。
2 相关研究
在deep Web数据获取方面,Barbosa L等人[6]第一次提出使用已获取数据中最高词频关键词作为下一个查询词的查询选择方法,然后,在实际中最高词频的查询词并不一直能返回更多的新记录,并且由于这种方法产生的查询词具有较高的关键词依赖,将会产生大量重复记录,增加数据获取的代价。Wu Ping等人[7]通过查询选择高效的爬取deep Web数据,将结构化Web数据库看成一个属性—值图模型,将 Web数据库爬行问题转化为图遍历问题,以最少的查询提交次数获取尽量多的deep Web内容,其问题在于每一轮查询结果都要扩充到属性—值图中用于产生下一轮待提交的查询词,这种做法代价非常高。Google也提出了一种多领域跨语言的deep Web数据获取方法[9],将deep Web内容爬取出来Surface化,将爬取出来的内容放进Google索引中,这样用户就可以通过 Google搜索到部分deep Web内容。目前,Google每秒钟可以爬取上千个deep Web动态页面,其不足在于该方法不能应用到Post方法提交的表单上,并且只获取URL而不进一步处理。Lu Jiang等人[10]提出一种基于强化学习的deep Web爬取框架,该框架爬虫作为Agent,Web数据库被作为环境。Agent感知当前状态,并根据Q-value选择一个查询提交到Web数据库。最近,George V等人[11]针对不需要获取查询所有结果的特定应用,提出一种Rank-aware Hidden Web 爬取方法,该方法对所有潜在查询仅仅下载 top-k个结果,从而避免了完全爬取巨大的deep Web数据。综上所述,这些研究主要针对如何提高单个 deep Web的数据获取效率,没有考虑集成环境下进行数据获取时,deep Web数据源之间的关联关系对数据获取的影响。
3 Deep Web数据获取相关概念定义
Deep Web 数据获取方式:结构化的Web数据库可看作一张关系数据表DB,DB包含的数据记录为 T={t1,t2,…,tn},每条记录包含 m个属性 A={a1,a2,…,am}。获取deep Web中的数据只能通过从查询接口上提交查询,从返回结果页面获得 deep Web中包含该查询的记录集,对于一个潜在的查询qi,R(qi)表示在DB上执行查询qi所返回的记录集,即DB中所有包含qi的记录集合(假设不考虑返回记录限制的情况),R(qi)为T的一个子集。
Deep Web数据获取代价模型:爬虫在DB上执行查询qi和获取qi所返回的记录集都需要一定的代价,如时间、网络带宽等。对于一个查询qi,使用Cost(qi, DB)表示爬虫在DB上执行查询qi和获取qi所返回记录集的各种代价总和(即deep Web数据获取代价)。对于结构化的Web数据库,数据获取的代价主要包括:爬虫提交查询到站点的查询代价、爬虫与Web服务器交互的代价、爬虫下载结果页面的代价。交互次数和查询提交次数是不一样的,每个结果页面通常包含固定k个匹配的数据记录,每次初始连接得到至多k个数据记录。例如,在图书数据库中有 104个图书记录匹配属性值“书名,Java”并且每个结果页面显示10(k=10)个数据记录,则获取所有结果记录集的总交互次数为[104/10]=11次。即每获取下一页的数据记录,都需要和Web服务器交互一次。
定义爬虫提交一次查询的代价为 Cq,爬虫与Web服务器交互一次的代价为 Cm,爬虫下载一个结果页面数据记录的代价为Cd。对于一个查询qi,在DB上执行查询qi和获取qi所返回记录集的各种代价总和Cost(qi, DB)可表示为

其中,Cq、Cm、Cd为常量,M为爬虫与Web服务器交互次数,P为爬虫需下载的结果页面数量。

其中,num(qi, DB)为DB中所有匹配qi的数据记录数,k为一个结果页面最多可显示记录数,如果DB存在最大返回记录限制,则N为DB一次查询的最大返回记录数。爬虫需下载的结果页面数量P和爬虫与Web服务器交互次数M相等。
单个deep Web数据源的数据获取:对于一个deep Web数据源DBk,deep Web数据获取问题可形式化定义为:寻找一组查询关键词集合 Qk={q1,q2,…, qn}使得 P(q1∨q2∨…∨qn,DBk,)值最大,其约束条件是,其中,t为爬虫获取DBk中数据可使用的最大代价。对于一个给定的查询qi,P(qi,DBk)表示在DBk上执行查询qi所返回的结果记录数占DBk总记录数的比例。
面向deep Web数据集成的数据获取:对于一个集成系统I,S={DB1, DB2, …, DBn}为I待集成的所有deep Web数据源的集合,面向deep Web数据集成的数据获取可形式化定义为:需找一组查询关键词集合 Q={Q1,Q2,…,Qn}使得 P(Q1∨Q2∨…∨Qn)最大,其约束条件是其中,T为集成系统I的可使用的最大代价,Qi为获取第i个数据源所提交的查询集合Qi={q1,q2,…,qn},P(Qi)为 P(q1∨q2∨…∨qn, DBi)。
4 Deep Web数据集成的数据循环获取策略
4.1 数据循环获取策略
对于一个集成系统I,S={DB1,DB2,…,DBn}为I待集成的所有deep Web数据源的集合。针对传统的deep Web数据集成实现方法在数据获取方面存在的缺陷,本文基于同领域数据源之间的关联关系,提出使用循环策略分多次完成数据源的数据获取,该策略主要思想为:首先对S中的数据源,根据其可能对集成系统I贡献的效用大小进行排序,效用评价标准可以根据数据源的大小、数据源的数据质量等,或者由这些量组成的一个函数。然后从S中排在第一位的数据源开始进行数据获取,数据获取的策略是当正在进行数据获取的当前数据源的特定特征达到阈值(特征和阈值将在停止条件进行详细描述),则停止获取该数据源,根据达到阈值的特征判断该数据源是继续保持在S中等待下一次获取,还是从S中删除该数据源,结束该数据源的获取任务;然后爬虫开始获取下一个数据源的数据,依次类推把S中的所有数据源都获取一遍;再重复上述过程,直到S为空,S中的数据源都达到获取结束条件。循环获取的具体算法如下。据源
T={t1,t2,…,tn}; // T为数据源的最大代价集合
θ; //θ为一个查询获取新数据的效率阈值
ω; //ω为获取数据源的数据量阈值
α; //α 为常量
Begin:
Int U={u1,u2,…,un}; // uk统计DBk已被获取的次数
L=SourceSort(S);//SourceSort()为数据源排序函数
While(L<>Null)
For every DBkin L by order
x=0; // x为计数器,统计对于DBk连续多少个查询获取新数据的效率都不大于θtk)
Dowload(R(qi));IF (qi从DBk获取新数据的效率不大于θ)
x= x +1;
Else x=0; EndIF
L = L-DBk;//满足结束条件,从L中删除DBk
EndIF
uk= uk+1; // DBk被循环获取次数加1
EndFor
Done
S中的数据源具有不同的特征,例如:数据源的大小、数据源的质量等;另外数据源之间的覆盖率也各不相同,一些数据源之间覆盖率较高,而另一些覆盖率较低,甚至可能包含另一些。因此不同的数据源对集成系统的贡献效用是有差异的。为了提高数据集成的效率,本文在开始数据获取前首先利用排序算法 SourceSort()对 S中的数据源按它们可能对集成系统 I贡献的效用大小进行排序,SourceSort()是一种数据源排序方法[12],该方法主要依据数据源可能给集成系统贡献的效用大小进行排序,这里的效用是指数据源能为集成系统新增新数据量与新数据质量(数据的完整性、一致性和冗余性等)的函数。
完成对S中数据源的排序之后,算法开始进行数据获取,一次查询的数据获取流程为:首先由SelectQuery()选择一个查询关键词qi(SelectQuery()将在下一节详细介绍),然后 Query(qi,DBk)在 DBk上执行查询qi,并返回结果页面记录集R(qi),接着Dowload(R(qi))实现从结果页面下载数据记录到本计入获取DBk已耗费的总代价Cost(DBk)。数据获取的过程为不断重复该流程直到满足循环停止条件。
4.2 数据获取停止条件
对于该算法停止条件的设置非常重要,该算法的停止条件可以分为2类。第1类为暂时停止条件:对数据源DBk的数据获取暂时停止,仍然保留在L中,等待下一次获取;第2类为结束条件:结束数据源DBk的数据获取,并将该数据源从L中删除。
暂时停止条件设置:对于数据源 DBk,如果SelectQuery()连续选择的 α个查询的新数据获取率都不大于θ,则说明SelectQuery()在目前的知识(查询候选池和统计知识)下已经不能进行有效查询选择,继续对DBk进行获取,代价将非常高,需要暂时停止对DBk的数据获取,等待下一次循环时再继续获取。在下一次获取时则可利用丰富后的动态知识进行查询选择。
结束条件设置:当对数据源DBk进行数据获取时,DBk的特征满足以下3种结束条件之一,即可从L中删除DBk,结束DBk的数据获取。DBk估计大小的一定比例(例如:ω=95%),即大部分数据,剩下的少量数据对集成系统的影响较小,并且获取这部分数据付出的代价也可能较高,所以可以结束DBk的数据获取。
2) 如果集成系统I分配给DBk的数据获取资源耗尽,即则结束DBk的数据获取。
3) 如果DBk被循环获取的次数uk达到阈值β,即uk≥β,则结束DBk的数据获取。
对于数据源DBk经过了β次查询候选池扩展和统计知识丰富的循环获取后,从DBk中继续获取新数据的可能性也较小,同时获取数据的代价随着循环获取的次数增加也不断增大,因此可以结束DBk的数据获取。
5 基于集成系统动态知识的查询选择
根据同领域数据源之间的相关性,S中数据源之间通常具有相似的属性值并且这些属性值也具有相似的分布特征,例如:在图书领域不同图书销售网站(数据源)所销售的图书具有一定的相似性,并且图书书名出现的频率也是相似的。本文提出利用集成系统已获取的数据构建动态知识,并设计基于集成系统动态知识的查询选择方法。与传统方法比较,该方法使爬虫获得更广泛的分类属性值,扩展了查询候选池,从而能避免信息孤岛问题,提高数据获取的覆盖率;同时动态知识使爬虫获得了更全面和时新的统计知识,利用动态知识可提高查询回报率估算的准确性,从而提高查询选择的效率。
5.1 动态知识构建
对于一个集成系统I,S={DB1,DB2,…,DBn}为I待集成的所有deep Web数据源的集合,在某一时刻取的数据,集成系统的动态知识(dynamic knowledge)DK可定义为:从SLocal中得到的候选查询关键词以及该查询关键词在 SLocal中出现的概率对的集合,即:qi代表候选查

随着数据获取工作的进行,SLocal中的数据会动态变化,因此,DK也需要根据SLocal保持动态更新,以便为查询选择提供更时新和全局的知识。理论上集成系统每执行一次查询(数据获取)都可能使例如:执行一次查询qk(数据获取)都有可能改变的候选查询关键词,因此理论上每执行一次查询的数据获取都需要更新DK。对于集成系统I和SLocal,当一个候选查询 qk被选择在数据源 DB上执行Query(qk,DB),返回数据记录集合为R(qk),更新DK主要有2个方面的工作。
1) 统计分析是否有新的候选查询产生,如果有新的候选查询qnew产生,则向DK添加候选查询qnew现的概率更新可由以下式计算
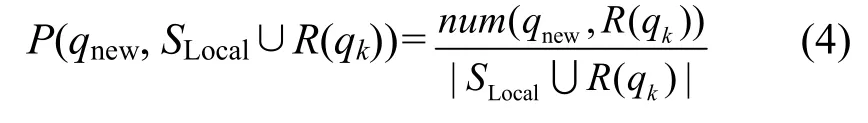
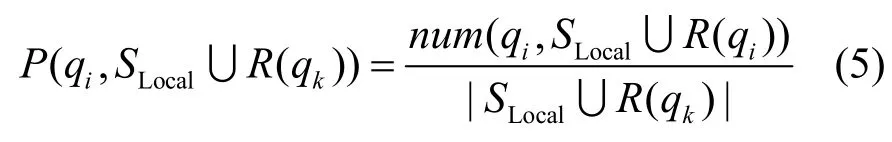
但是如果每一次查询执行都动态维护 DK,那么代价将十分巨大,随着系统集成数据规模的增加,维护DK的代价将变得无法接受。本文发现在实际应用中对于一个集成系统I,当I所集成的数据达到一定规模 M后(即 DK中知识达到一定规模后),一个查询甚至若干个查询的执行对DK的更新结果对查询选择的影响非常小。基于上述发现本文使用一种优化方式实现更新 DK。当集成系统 I所集成的数据达到一定规模M之前,对每一次查询都更新 DK。当集成系统 I所集成的数据达到一定规模M之后,执行K个查询后再更新DK,K可以随M的变化而变化,从而在不影响查询选择效率的前提下,尽可能减小更新DK的代价。

式(4)可重写为其中,R(q[1,2,…,K])为{q1,q2,…,qk}在 DB 上执行所返回结果的集合。
5.2 基于动态知识的查询回报估算
DK是S中所有数据源已获取的数据中得到的知识,因此爬虫拥有了一个更大的查询候选池和更全局、更时新的统计知识。对于正在进行数据获取的当前数据源DB,DK中的候选查询可分为2类:QDB和QDK。QDB为包含在DK中,且已出现在DBLocal中的候选查询;QDK为包含在 DK中,但没有在DBLocal中出现候选查询。对于一个候选查询qi是否能被选择执行,一个重要的因素是执行qi能获得的查询回报,这里的查询回报指查询能够获取新数据的数量,下面将讨论如何估计QDB和QDK这2类查询的回报率。
1) QDB查询回报估计:使用从集成系统的全局知识DK来估算qi∈QDB的回报率,查询回报估算公式如下

num(qi,DBLocal)是DBLocal中与qi匹配的数据记录数,num(qi,DB)是目标数据源 DB中与 qi匹配的记录数,num(qi,DB)在qi在DB上执行之前是未知的。
下面讨论如何估算num(qi,DB),基于S中数据源之间通常具有相似的属性值并且这些属性值也具有相似的分布特征,在不考虑偏差的情况下,假定qi出现在DB的概率等于它在全局数据上的概率P(qi,SLocal),P(qi,SLocal)能从DK中得到。基于这个假定,所有在DB上已提交的查询q[1,2,…,m]出现在DB上的概率与全局数据上的概率也相同。因此使用如下式估算num(qi,DB)
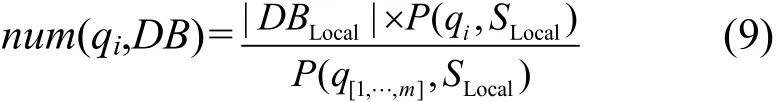
2) QDK查询回报估计:现在讨论如何估算qi∈QDK的回报率(查询qi未出现在DBLocal中),同上本文假设 P(qi,DB)等于 P(qi,SLocal)。因此Reward(qi,DB)的计算式如下:据量)。

5.3 查询选择
Deep Web数据集成爬虫的目的是在一定资源约束下尽可能多地获取数据。基于这个目的爬虫进行查询选择时必须考虑以下2个因素:第一,候选查询qi在DB上执行的查询回报率;第二,候选查询qi获取DB中数据需要花费的代价。例如:存在2个候选查询qk和qj,如果它们获取DB的数据时需要花费的代价相同,但是qk比qj的查询回报率更高,qk应先于qj被选择,同理,如果qk和qj具有相同的查询回报率,但qk比qj花费更少的代价,qk已应先于qj被选择。因此候选查询qi的效率可由下式计算。
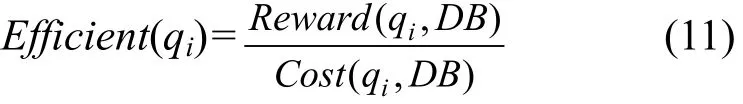
Reward(qi,DB)查询 qi在 DB的查询回报率,Cost(qi,DB)表示查询qi获取DB中数据需要花费的代价。
因此,Efficient(qi)估算单位代价情况下qi能返回多少新记录。根据这个函数爬虫能够估计每一个候选查询qi的效率,从而选择一个最高效率的查询首先执行。查询选择算法采用贪婪方法每次都选择具有最高潜在效率的查询,具体算法如下:

6 实验
6.1 数据准备
为了验证本文方法的有效性,本文使用2类测试数据:一类是人工构建的模拟deep Web数据源,另一类是真实的deep Web数据源。人工构建专利领域的模拟deep Web数据源,使用项目组已从7个国家2个组织获取的63.32万条专利数据,构建5个专利领域的deep Web数据源。为了模拟真实世界的同领域数据源之间存在一定的相关性(相互覆盖),又避免大量覆盖导致的实验代价过大的问题,设置每个数据源随机从63.32万条数据中抽取15万~25万条不等的数据记录。同时,本文也在真实 deep Web数据源上验证本文方法的有效性,从BrightPlanet公司的CompletePlanet网站的音乐领域中选取 5个 deep Web数据源(music.aol.com,www.chicagoreader.com,www.onlinemusicdatabase.com,www. sheetmusicplus.com, www.bestwebbuys.com)。对于这些数据源大小通过Arjun Dasgupta等人[13]提出的数据源大小估计方法进行估算。
为了更好验证基于动态知识的查询选择方法QuerySelect-DK的效率,本文对QuerySelect-DK进行适当简化得到QuerySelect-T,两者查询选择策略一样,两者的区别为:QuerySelect-DK可利用集成系统已获取所有数据的动态知识进行查询选择,而QuerySelect-T仅能利用当前数据源已获取的有限知识进行查询选择。
本文主要从以下几个方面验证本文提出的方法的性能:①基于循环策略与动态知识的数据获取方法(Cycle-A)与基于 QuerySelect-T、图遍历Graph-Based[7]和高词频 High-frequency[6]查询选择方法的独立数据获取方法性能比较;这里的独立数据获取方法是指利用上述查询选择方法独立穷尽获取每一个待集成的deep Web数据源,然后合并从各个数据源获取的数据,完成所有待集成数据源的数据集成。独立数据获取策略不考虑待集成的deep Web数据源之间的关联关系;②基于动态知识的查询选择方法(QuerySelect-DK)与基于QuerySelect-T、图遍历 Graph-Based[7]和高词频High-frequency[6]查询选择方法性能比较;③更新DK的查询间隔次数K对查询选择效率的影响。
6.2 实验结果
6.2.1 基于循环策略与动态知识的数据获取方法与独立数据获取方法的性能比较
为了比较本文提出的基于循环策略与动态知识的数据获取方法(Cycle-A)和采用基于QuerySelect-T、图遍历Graph-Based和高词频High-Frequency查询选择方法的独立数据获取方法(Separate-A)的性能,集成系统分别使用2种方法集成专利和音乐领域的所有数据源,根据deep Web数据获取代价模型,2种方法获取相同覆盖率的查询提交次数越少,deep Web数据获取的代价也越小。因此实验时不考虑数据获取的代价因素,实验通过比较2种方法数据获取时的数据源覆盖率与查询提交次数的关系,测试基于循环策略与动态知识的数据获取方法的效率。实验中设置暂时停止条件为α=5,结束条件ω=95%,β=4,数据获取时代价条件不受限制。
图1给出了2种数据获取方法的效率对比,从图1可见,在专利领域Cycle-A的数据获取效率明显优于采用 3种查询选择方法的 Separate-A(Separate-A-QST、Separate-A-GB和 Separate-AHF)。随着查询提交次数的增加,Cycle-A的效率优势越来越明显,当覆盖率达到 80%时,Separate-A-QST策略的查询提交次数几乎为 Cycle-A策略的5倍,当覆盖率达到95%时,Cycle-A策略的查询提交次数约为4 900次而Separate-A-QST策略达到了13 000次左右,从音乐领域已得到类似的结果。这是因为Cycle-A能在较大程度上避免Separate-AQST在每个数据源数据获取后期效率迅速降低的情况,同时也得益于基于集成系统动态知识的查询选择方法。同样 Cycle-A性能与 Separate-A-GB和Separate-A-HF相比已具有较大的优势。
6.2.2 QuerySelect-DK与现有主要查询选择方法的性能比较
集成系统已获取了某领域n-1个数据源的数据,通过比较分别使用基于动态知识的查询选择方法QuerySelect-DK与基于 QuerySelect-T、图遍历Graph-Based和高词频High-frequency的查询选择方法获取第n个数据源的数据的效率,测试本文提出的基于动态知识的查询选择方法QuerySelect-DK的效率。
实验具体设置为:对于专利和音乐领域,系统已分别集成了各领域 3个数据源,现在分别使用上述4种查询选择方法获取第4个数据源的数据,对于QuerySelect-DK方法,动态知识DK根据集成系统已获取的前3个数据源的数据构建。图2给出了4种查询选择方法获取专利和音乐领域第 4个数据源的效率。从图2可见,在音乐领域,QuerySelect-DK方法提交大约1 200次查询已获取数据源大约95%的数据,而QuerySelect-T方法相同查询提交次数仅仅获得大约 70%的数据。QuerySelect-DK方法提交大约400次查询时可获得大约80%的覆盖率,从获得相同覆盖率需要提交查询次数方面比较,QuerySelect-DK方法的效率也明显优于QuerySelect-T方法。QuerySelect-DB方法的效率略优于QuerySelect-T,但与QuerySelect-DK的性能仍有较大差距,而QuerySelect-HF的效率最差。专利领域的实验结果与音乐领域类似。因此实验说明在不考虑代价的前提下,QuerySelect-DK方法的效率高于具有相同查询选择策略的 QuerySelect-T。同时基于QuerySelect-DK方法的效率也明显高于现有主流的图遍历Graph-Based和高词频High- frequency的查询选择方法。
6.2.3 更新DK的查询间隔次数K对查询选择效率的影响
为了评估更新DK的查询间隔次数K对查询选择效率的影响,实验在DK为空和DK较丰富的这2种情况进行,比较不同情况下更新DK的查询间隔次数K对查询选择效率的影响。第1种情况,初始DK为空,从专利领域的第一数据源开始数据获取;第2种情况,系统已获取专利领域的前2个数据源的数据并构建了DK,开始获取第2个数据源的数据。实验分别比较K为1,10,30时查询选择的效率,实验结果如图3和图4所示。
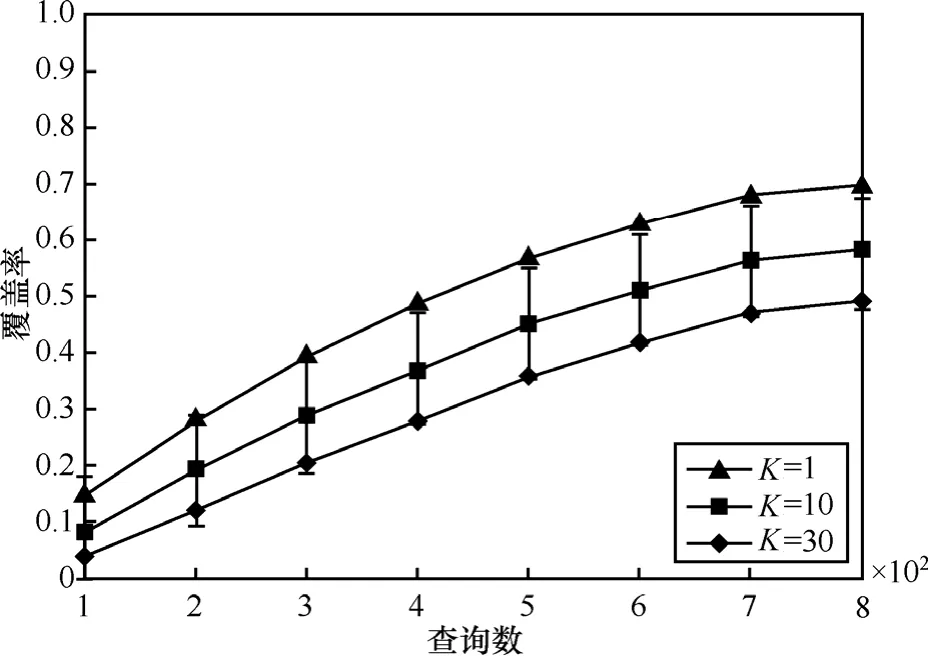
图3 当DK较小时K对查询选择效率的影响
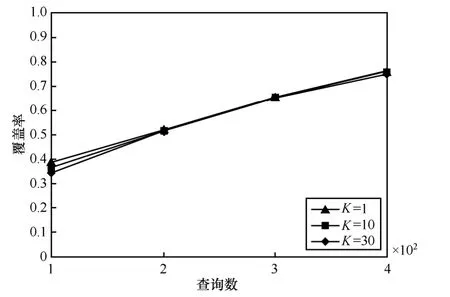
图4 当DK较丰富时K对查询选择效率的影响
从图3中可见,在初始阶段K=1的效率明显高于其他3种情况,并且数据获取效率按照K值递增而递减。在大约400次查询提交之前,随着查询提交次数的增加3种情况的数据获取效率差距逐步扩大,但扩大幅度越来越小;在大约400次查询后3种K值数据获取效率差距已基本稳定,不再扩大,说明在此之后这3种K值的查询选择效率已基本相当。该实验说明在DK较小时,为了高效的数据获取需要使用较小的K值,虽然这样更新频率较高,但是由于此时DK较小,更新DK的代价也能接受。当随着DK的不断丰富,K的大小对查询选择效率的影响逐步减小。从图4中可见,第2种情况下3种K的数据获取效率基本相同,说明在此时这3种不同K对查询选择效率的影响基本相同。因此,通过本实验可得出随着数据获取的进行,可以逐步调整K值,使集成系统在不太影响数据获取效率的前提下,尽量降低更新DK的代价。
7 结束语
针对集成环境下的deep Web数据获取问题,本文提出了一种新的数据获取方法。该方法根据同领域数据源之间关联性,使用循环获取策略减少了数据源后期数据的获取,较大程度上避免了传统方法数据获取后期代价巨大的问题;利用集成系统的动态知识进行查询选择,扩展了查询候选池、丰富了查询选择的知识,从而提高了数据获取的覆盖率和查询选择的准确性。实验表明,提出的基于循环策略和动态知识的deep Web数据获取方法能够很好地满足deep Web数据集成的需要,与传统方法比较,具有较高的数据获取效率。
[1] MICHAEL K B. The deep Web: surfacing hidden value[J]. Journal of Electronic Publishing, 2001 7(1):1174-1175.
[2] HE B, PATEL M, ZHANG Z, CHANG K C C. Accessing the deep Web: a survey[J]. Communications of the ACM, 2007,50(5):94-101.
[3] 刘伟, 孟小峰, 孟卫一. deep Web 数据集成研究综述[J]. 计算机学报, 2007,30(9):1475-1489.LIU W MENG X F, MENG W Y. A survey of deep Web data integration[J], Chinese Journal of Computers, 2007,30(9):1475-1489.
[4] NAN Z, GAUTAM D. Exploration of deep Web repositories[A]. Proceedings of the 37th International Conference on Very Large Data Bases[C]. Tutorial, Westin, Seattle, WA, 2011.
[5] JAYANT M, SHAWN J, SHIRLEY C, et al. Web-scale data integration: you can afford to pay as you go[A]. Proceedings of 3rd International Conference Innovative Data Systems Research[C]. Asilomar,CA, 2007. 342-350.
[6] LUCIANO B, JULIANA F. Siphoning hidden-Web data through keyword-based interfaces[A]. Proceedings of the 19th Brazilian Symposium on Database[C]. Brasilia, Brazil, 2004.309-321.
[7] WU P, WEN J R, LIU H, et al. Query selection techniques for efficient crawling of structured Web sources[A]. Proceedings of the 22th International Conference on Data Engineering[C]. Atlanta,GA,USA,2006.47-56.
[8] NTOULAS A, ZERFOS P, CHO J H. Downloading textual hidden web content by keyword queries[A]. Proceedings of the Joint Conference on Digital Libraries[C]. Denver, Colorado, USA, 2005. 100-109.
[9] JAYANT M, DAVID K, LUCJA K, et al. Google's deep-Web crawl[A]. Proceedings of 34th International Conference on Very Large Data Bases[C]. Auckland, New Zealand, Springer,2008.1241-1252.
[10] JIANG L, WU Z H, FENG Q, et al. Efficient deep Web crawling Using reinforcement learning[A]. Proceedings of the 14th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining[C]. Hyderabad, India, Springer, 2010. 428-439.
[11] GEORGE V, ALEXANDROS N, DIMITRIOS G. Rank-aware crawling of hidden Web sites[A]. Proceedings of the International Workshop on the Web and Databases[C]. Athens, Greece, 2011.
[12] XIAN X F, ZHAO P P, YANG Y F, et al. Efficient selection and integration of hidden Web database[J]. Journal of Computers, 2010,5(3): 500-507.
[13] ARJUN D, Xin J, BRADLEY J, et al. Unbiased estimation of size and other aggregates over hidden Web databases[A]. Proceedings of the ACM SIGMOD International Conference on Management of Data,Indianapolis[C]. Indiana, USA, ACM Press, 2010. 855-866.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子制作(2018年2期)2018-04-18
计算机与生活(2018年3期)2018-03-12
海峡姐妹(2017年12期)2018-01-31
中国科技期刊研究(2017年2期)2017-05-14
作文与考试·初中版(2017年12期)2017-04-19
电子制作(2017年9期)2017-04-17
浙江大学学报(工学版)(2015年2期)2015-05-30
中学生(2015年12期)2015-03-01
