
高斯混合模型盲信号分离方法的CUDA实现*
2013-07-02 01:15苏洁洪李宇
自动化与信息工程 2013年1期
苏洁洪 李宇
(广东药学院医药信息工程学院)
高斯混合模型盲信号分离方法的CUDA实现*
苏洁洪 李宇
(广东药学院医药信息工程学院)
对一组线性瞬时混合信号,采用高斯混合模型拟合各个独立源的概率密度分布进行分离,其复杂度随信号源数量、高斯混合模型阶数的增加急剧上升。提出用统一计算设备架构(compute unified device architecture,CUDA)对该分离方法进行设计,实现该方法的并行加速处理。实验结果表明,此加速方案可以有效降低该盲分离方法的时间复杂度。
盲分离;高斯混合模型;统一计算设备架构
0 引言
信号盲分离技术在工程界有广泛的应用,如语音混合信号分离、孕妇与胎儿心电信号的分离以及通信中多用户检测等。一般而言,盲分离按混合条件可以分为卷积混合与瞬时混合两种情况。
对于卷积混合信号,如语音信号的反响听觉混合,有的采用时域分离方法[1-2]。更常用的处理方法是通过频域变换,将卷积化为乘积再分离。这样可以采用瞬时混合来分离信号[3],但是频域变换后再分离会产生排列问题。瞬时盲分离方法是卷积频域盲分离方法的一部分,对其进行工程研究更具有普遍作用。
已有的瞬时盲分离方法一般对源的统计分布有严格的假设要求,如基于累积量方法[4],在求解过程中对一些参数的选值仅凭经验[5],这些局限不利于工程应用。近年来,学者对高斯混合模型(Gaussian mixture model,GMM)应用于盲分离进行了研究[6],利用期望最大(expectation maximization,EM)算法估计源分布参数与混合矩阵,但源分布的阶数难以选择,对初始化依赖比较大,实现非常复杂。
最近,提出了一种基于GMM描述源分布的BSS方法[7]。该方法分为两步:首先通过EM算法估计观察信号的分布参数,获得分离矩阵的对数似然函数的紧下界;然后通过最大化该紧下界求得分离矩阵。该方法不需要初始化,复杂度相对较低,但同样用到EM算法求GMM分布参数,仍有较大的运算量。由于用GMM表示源信号与观察信号的统计分布,GMM的求解EM算法是个迭代运算,多个GMM的求解的运算量对于一般PC的CPU而言耗时过长。
目前,CUDA技术受到学术界的重视,可应用于智能算法,如神经网络的实现[8]。本文将GMM参数求解计算在NVIDIA的CUDA平台并行设计,由于符合CUDA计算的显卡具有约百个并行计算单元,得以大大缩减运算时间。
1 基于GMM 的盲分离[7]
瞬时盲分离问题可以表示为:

其中,mμ表示为均值;Cm表示为方差;mω表示权重;M为高斯阶数;N为数据点数。在t时刻观察信号xt的联合PDF为:
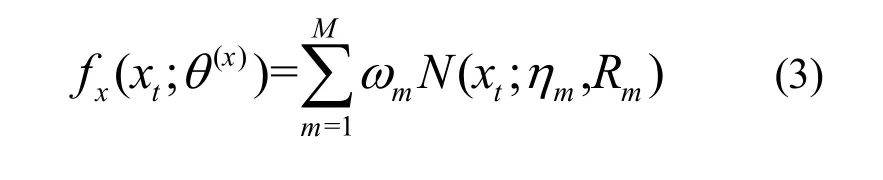

2 CUDA加速实现
2.1 CUDA简介
支持CUDA的GPU可以并行处理大量线程,如GT240显卡可以并行处理96个线程。如图1所示,线程在CUDA中以线程网格的形式被分割为多个大小相等的线程块,一块里面有许多线程,块与块之间不联系,但线程块内可以使用共享内存。
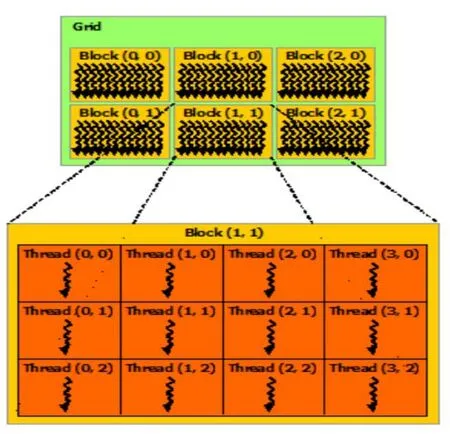
图1 CUDA编程模型
由于GPU没有快速缓存,CUDA要达到较高的计算速度,就需要合理地访问存储器,使GPU在少次访问显存时完成尽量多的计算,即提高运算密集度,将计算分割为相互独立的并行线程,合理地利用共享内存、常量内存等快速存储器,详细情况请参看文献[9]。
2.2 GMM加速
在CUDA中写主机函数和核函数,主机函数由CPU执行,负责初始化,复制数据到GPU,启动核函数,最后复制数据回到CPU,核函数在GPU上以线程网格的形式执行。
EM算法有2部分:E步建立数据模型并计算数据点的似然值;M步计算GMM的3类参数。EM算法在迭代的似然值之差小于某个给定的常数时结束计算。图2是EM算法的CUDA核函数部分代码,下面结合代码描述EM算法的并行设计。

图2 CUDA核函数部分代码
初始化权重、均值与方差后,E步计算似然。似然公式为:
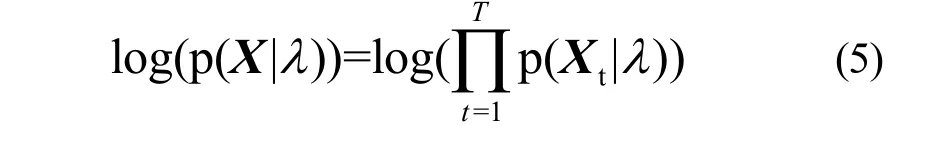
结合CUDA的架构,图2中代码[3]先求各阶T点的高斯函数,然后用代码[4]求式(6):
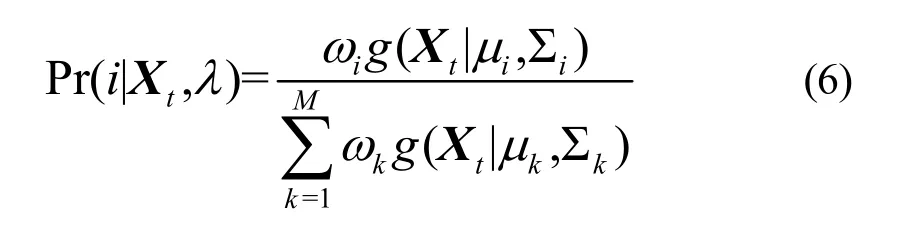
图2中代码[5]、[6]、[7]并行求线程块的对数和,并保存在loglike变量中,最后返回CPU。由CPU完成对所有线程块结果的求和,得最大似然值。
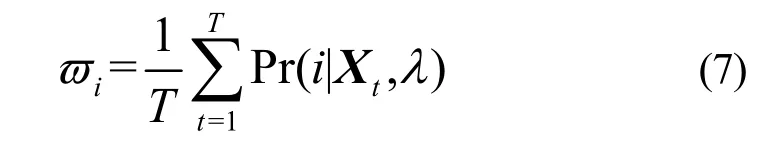
M步通过式(7)、式(8)、式(9)分别计算权重、均值与方差。权重为:其中,Xt是观察向量;λ是参数。由式(7)的特性可看出,T点可以并行求和,再结合E步算出来的式(6)数据,很容易由图2中代码[10]并行求和T点的Pr(i|Xt,λ),最后由代码[11]、[12]就可以计算权重。均值为:
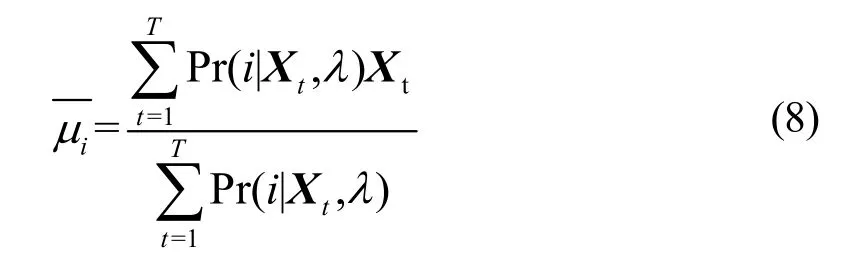
式(8)与式(7)相比只是多乘了一个矩阵Xt,图2中代码[13]中,分子乘了一个矩阵Xt再并行求和,然后利用求式(7)过程中的数据,最终由代码[14]、[15]求出均值。
xt是Xt的任意元素,μi是均值中的任一元素,方差为:
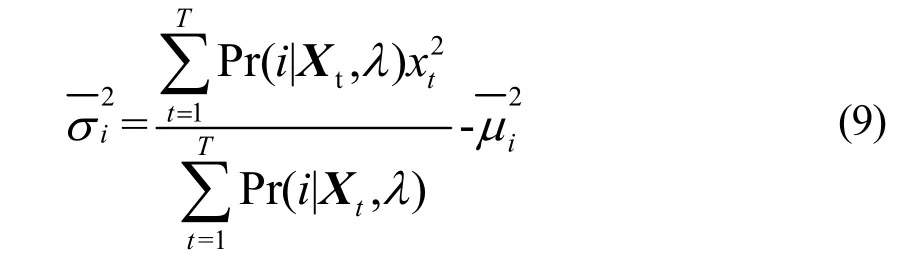
式(9)与式(8)差了一个减法与分子的乘以xt的元素,在图2中代码[16]中分子Pr(i|Xt,λ)乘以xt的元素后再并行求和,再减去均值,结合式(6)数据,再由代码[17]算出方差。
图3是核函数线程块内并行求和parallelSum函数代码。其中代码[3]行计算线程块中各线程的索引,代码[6]中用循环来控制并行,代码[7]中各线程并行两两求和,这样一次就完成了16个元素与另外16个元素的“同时”相加。代码[8]是线程块内线程同步函数,保证各个线程完成了计算,代码[9]中各相应的寄存器再把结果读入相应的线程,代码[10]再一次同步,保证线程完成“读”,然后再执行循环。经过8次循环就可完成一块线程块里256个元素的求和。

图3 parallelSum函数的代码
REDUCE(N, CODE, RESULT)是宏定义函数,里面调用了parallelSum函数,构成了一个先对所有线程块求和,再求线程块结果的总和的函数。
图4为核函数发射代码。EM算法外面用for循环来控制,待M步完成之后,再返回E步,不断进行EM迭代,求出最大似然对数值,最后比较是否收聚,迭代完后并把相应的均值、方差、权重返回CPU。CUDA程序接口是用Mex函数来完成,编译得到.MEXW32。

图4 核函数发射代码
2.3 对角加速
对角化运算过程中计算量大的运算部分都必须换为CUDA函数。其中奇异值分解(sigular value decomposition,SVD)运算在数据较大时,SVD计算量比较大,因此本文调用CULA库的SVD程序,用Mex函数将其封装为Matlab函数。对角化中存在的矩阵相乘运算。当矩阵维数较大时,计数量也比较大,所以调用CUDA库里的矩阵相乘函数,再用Mex函数将其封装成Matlab函数。
3 盲分离的性能测试
实验采用Intel I3-530 CPU和NVIDIA GT 240显卡硬件平台,在Matlab 2012环境下分别调用CPU程序和GPU的CUDA函数运行信号盲分离耗时评测。选定信号源信号的个数、高斯的阶数、数据点数进行实验比较。实验设定数据点个数N=1000,高斯的阶数为3,源信号个数分别为2、3、4。
实验得到盲分离的分离效果数据,如表1、表2、表3所示,可以看出,GPU盲分离与CPU盲分离的效果一样,由GPU做的评估矩阵A与CPU做的评估矩阵A是一样的,都很近似地恢复了原混合矩阵A。
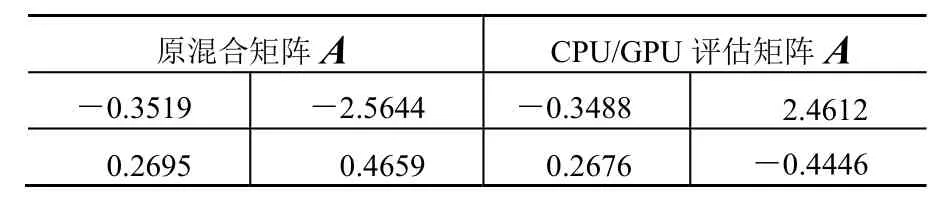
表1 源信号个数为2时的分离数据
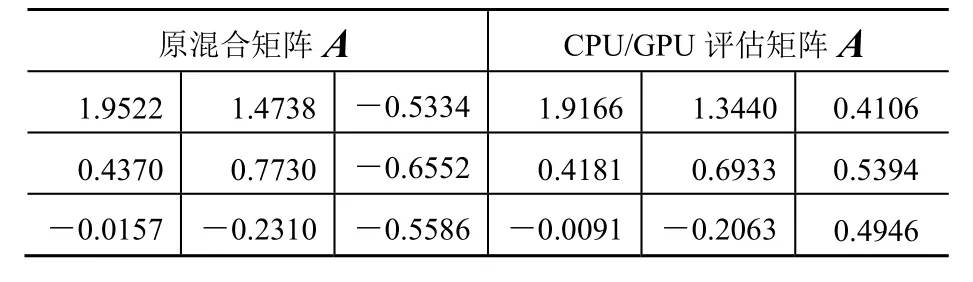
表2 源信号个数为3时的分离数据
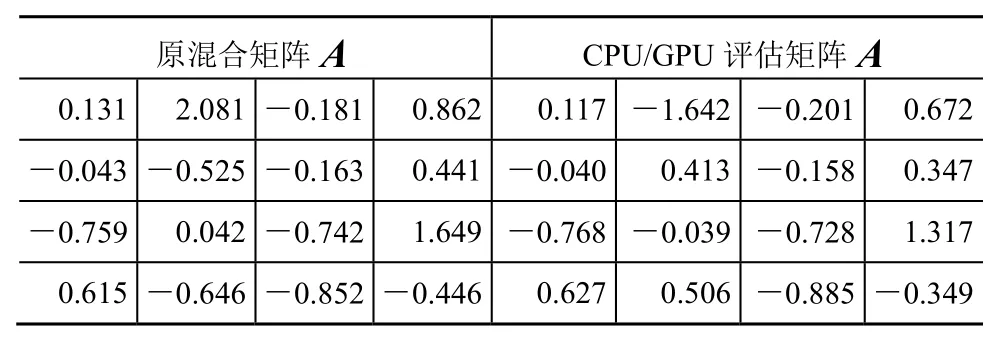
表3 源信号个数为4时的分离数据
但由表4看出,GPU做盲分离的速度更快,可以取得4.7305倍加速比。通过实验可以看出,用GPU与CPU平台盲分离的结果相同,但GPU平台节省计算耗时。在一定范围内,随着数据点和源信号的增大,加速比将继续增大。
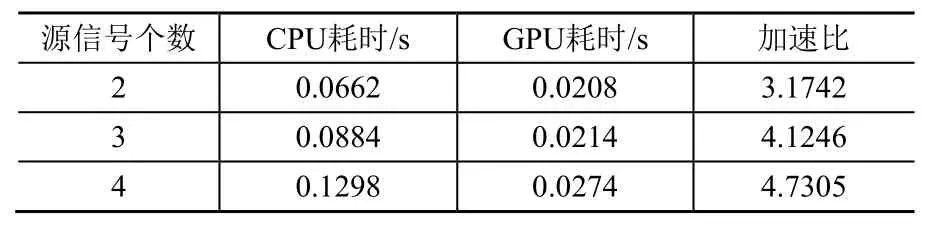
表4 CPU与GPU盲分离的运算时间对比
4 结束语
利用CUDA架构设计高斯混合模型盲分离方法,运算速度提高数倍,可以很好地发挥GPU的并行处理特点,节省运算时间。依靠GPU的并行计算,盲分离这一类计算复杂度高的科学计算问题将得到具有实际工程意义的解决。
[1] S C Douglas, H Sawada, S Makino. Natural gradient multichannel blind deconvolution and speech separation using causal FIR flters[J]. IEEE Trans, Speech and Audio Processing, 2005,13(1):92-104.
[2] R Aichner, H Buchner, S Araki, et al. Online time-domain blind source separation of nonstationary convolved signals[C]. In Proc. 4th International. Symposium,2003.
[3] S-I Amari, A Cichocki, H H Yang. A new learning algorithm for blind signal separation[J]. In Advances in Neural Information Processing Systems, 1996,8:757-763.
[4] J F Cardoso. High-order contrasts for independent component analysis[J]. Neural Computation, 1999,11(1):157-192.
[5] H Attias. Independent factor analysis with temporally structured sources[J]. Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 1999, 11(4):803-851.
[6] M Welling , M Weber. A constraint EM algorithm for independent component analysis[J]. Neural Computation,2001, 13(3):677-689.
[7] K Todros , J Tabrikian . Blind separation of independent sources using gaussian mixture model[J]. IEEE transactions on signal processing,2007,55(7):3645-3658.
[8] 张佳康,陈庆奎.基于CUDA技术的卷积神经网络识别算法[J].计算机工程,2010,36(15):179-181.
[9] NVIDIA CUDA Compute Unified Device Architecture Programming Guide Version 5.0.
A CUDA Implementation of Gaussian Mixture Model Based Blind Signal Separation Method
Su Jiehong Li Yu
(School of Medical Information Engineering, Guangdong Pharmaceutical University)
For a group of instantaneous linear mixing signals, the complexity of the blind separation method using Gaussian mixture model to fit their probability density functions becomes higher as either of the number of independent signal sources or the order number of Gaussian mixture model increases respectively. In this paper parallel implementation is proposed for this method on NVIDIA's CUDA platform to get accelerated processing. Experiment results show that our accelerating scheme can reduce time complexity of it.
Blind Source Separation; Gaussian Mixture Model; CUDA
苏洁洪,男,1991年生,在读本科生,研究方向:CUDA并行程序设计。
李宇,男,1977年生,讲师/博士,研究方向:语音与医学信号处理。E-mail:liyu33@gmail.com
广东省质监局科技项目(2013PT05),广东省科技项目(2012A090200005,2011B031200002,2011B020401011),越秀区科技项目(2011-GX-031),国家质检总局科技项目(2010QK085,2012QK065)。
猜你喜欢
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
电影故事(2015年16期)2015-07-14
