
基于子带可控响应功率的多声源定位方法
2013-07-20 02:34倪志莲蔡卫平张怡典
计算机工程与应用 2013年24期
倪志莲,蔡卫平,张怡典
九江职业技术学院电气工程学院,江西九江 332007
基于子带可控响应功率的多声源定位方法
倪志莲,蔡卫平,张怡典
九江职业技术学院电气工程学院,江西九江 332007
1 引言
基于麦克风阵列的声源定位技术根据接收信号估计声源的方位,在视频会议[1]、语音增强[2]、机器人听觉[3]等领域有着非常广泛的应用。在很多场合,需要对多个声源进行定位,如在视频会议中,可能有多个人同时说话。近年来,多声源定位技术已逐渐成为研究的热点。
在真实环境中,实现多声源定位是非常困难的,除了混响和噪声外,声源之间的相互干扰也将严重影响定位性能。多声源定位技术必须克服这些不利因素的影响。文献[4-5]提出的算法利用了语音信号的特点,可实现2~3个说话人的定位,但在混响较强的环境中,这类算法鲁棒性较差。相位变换加权的可控响应功率(Steered Response Power-Phase Transform,SRP-PHAT)声源定位算法[6]在混响环境中有较强的鲁棒性。该算法计算阵列接收信号的可控响应功率,在声源空间中寻找使SRP值最大的点作为声源位置估计。当有多个声源同时出现时,SRP函数将呈现出多个峰,每个峰对应一个声源,结合适当的聚类算法,SRP-PHAT也可实现多声源定位[7]。然而,由于声源之间的相互干扰,SRP函数中,较弱声源产生的峰可能远低于较强声源产生的峰,甚至完全被覆盖。因此,传统SRP-PHAT算法的多声源定位性能不高。文献[8]提出分两步定位多个声源的方法。该算法首先计算SRP函数并且估计出最强声源的位置,然后根据此位置引入一个衰减函数以抑制最强声源产生的空间谱峰,从而突出次强声源的谱峰,再次搜索SRP-PHAT函数的最强谱峰即可得到较弱声源的位置估计。该算法能大大提高第二个声源的定位成功率,但由于需要重复计算SRP函数,计算量较大,而且第二个声源的定位精度依赖于第一个声源的定位精度。
为了克服传统SRP-PHAT算法的缺点,本文提出一种基于子带SRP的多声源定位算法。该算法将语音信号频谱划分为若干个子带,并在每个子带分别计算SRP-PHAT函数,称为子带SRP函数。在声源空间中,寻找每个子带SRP函数的最大值,由此,每个子带可得到一个声源位置估计,称之为初始估计。尽管最强的源通常会抑制其他源,但根据语音信号在频域的稀疏性[9],同一个源不会在每个子带都是最强的,也就是说,某个源在一些子带是最强的,而其他源在另一些子带是最强的,因此子带SRP算法可突出较弱的声源。使用适当的聚类算法可从初始估计中得到最终的声源位置估计。
2 信号模型
用于语音声源定位的麦克风阵列通常在室内环境下使用,麦克风的接收信号中除了源信号外,还有背景噪声和混响。在有Ns个声源情形下,第m个麦克风(m=1, 2,…,M)的接收信号可表示为:
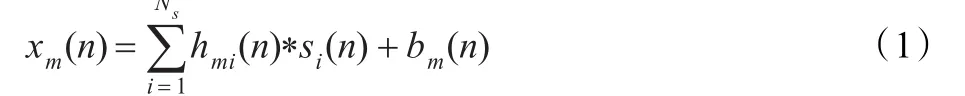
其中si(n)为第i个声源,hmi(n)为第i个声源到第m个麦克风之间的房间冲激响应,“*”表示线性卷积,bm(n)是第m个麦克风的噪声,假定各麦克风的噪声不相关,噪声与信号也不相关。
3 基于SRP-PHAT的多声源定位算法
SRP-PHAT算法根据麦克风阵列接收的一帧数据估计声源位置。仍然用xm(n)表示第m个麦克风接收的一帧数据,Xm(k)表示其DFT。用r,θ,ϕ分别表示球坐标系统中的距离,水平角和仰角,则相位变换(Phase Transform,PHAT)加权的导引响应可表示为:

其中q=(r,θ,ϕ)为假想声源的球坐标,τml(q)为第m个麦克风的导引时延(麦克风l为参考基元),ω为模拟角频率,M为麦克风的个数。在远场假设下,麦克风阵列接收信号为平面波,τml(q)与距离r无关,其值可用下式来计算:

其中ζ为声源的单位方向矢量,其表达式为:

rm=[x y z]T为第m个麦克风在直角坐标系中的坐标矢量,c为空气中的声速(约为342 m/s)。则PHAT加权的导引响应功率,即SRP-PHAT,可表示为:

其中Q表示声源空间。在多声源情况下,PˆPHAT(q)呈现出多个峰,理想条件下,每个峰对应一个声源,使用聚类算法可找到这些峰的位置。文献[7]根据此原理提出了基于SRP-PHAT的多声源定位算法。该算法首先随机选取声源空间中足够多的点,计算这些点的SRP-PHAT函数值,然后在这些点中选取SRP值最高的N个点,使用会聚聚类(Agglomerative Clustering,AC)来估计每个声源所在的区域,并在每个区域使用随机区域收缩(Stochastic Region Contraction,SRC)最优化方法得到声源位置估计。文献[7]的算法考虑了三维定位情况,使用SRC的目的是为了减少计算量,但可能会降低定位性能。本文只考虑远场情形,因此仅估计声源的到达方向角(Direction Of Arrival,DOA)。本文将在第5章详细描述提出的多声源定位算法,然后进行仿真和实验,并将结果与文献[7]中的算法进行比较。为保证公平的比较,修改文献[7]的算法,用全网格搜索代替SRC,即在整个声源空间计算SRP-PHAT函数,然后找出最高SRP值的N个点,用AC聚类方法将这些点分为若干类,找出每个类中SRP值最高的点即得到声源位置估计。
4 AC聚类算法
如引言中所述,本文定位算法根据各子带得到声源位置的初始估计,其中靠近的几个点对应某个声源,这就需要利用聚类算法将初始估计分为Nc类,每个类可能对应一个声源。在这个问题中,Nc是未知的。AC算法不需要知道类的个数,因此正好用于解决本文的问题。对于一个N点的数据集,AC聚类算法流程可用图1来描述。
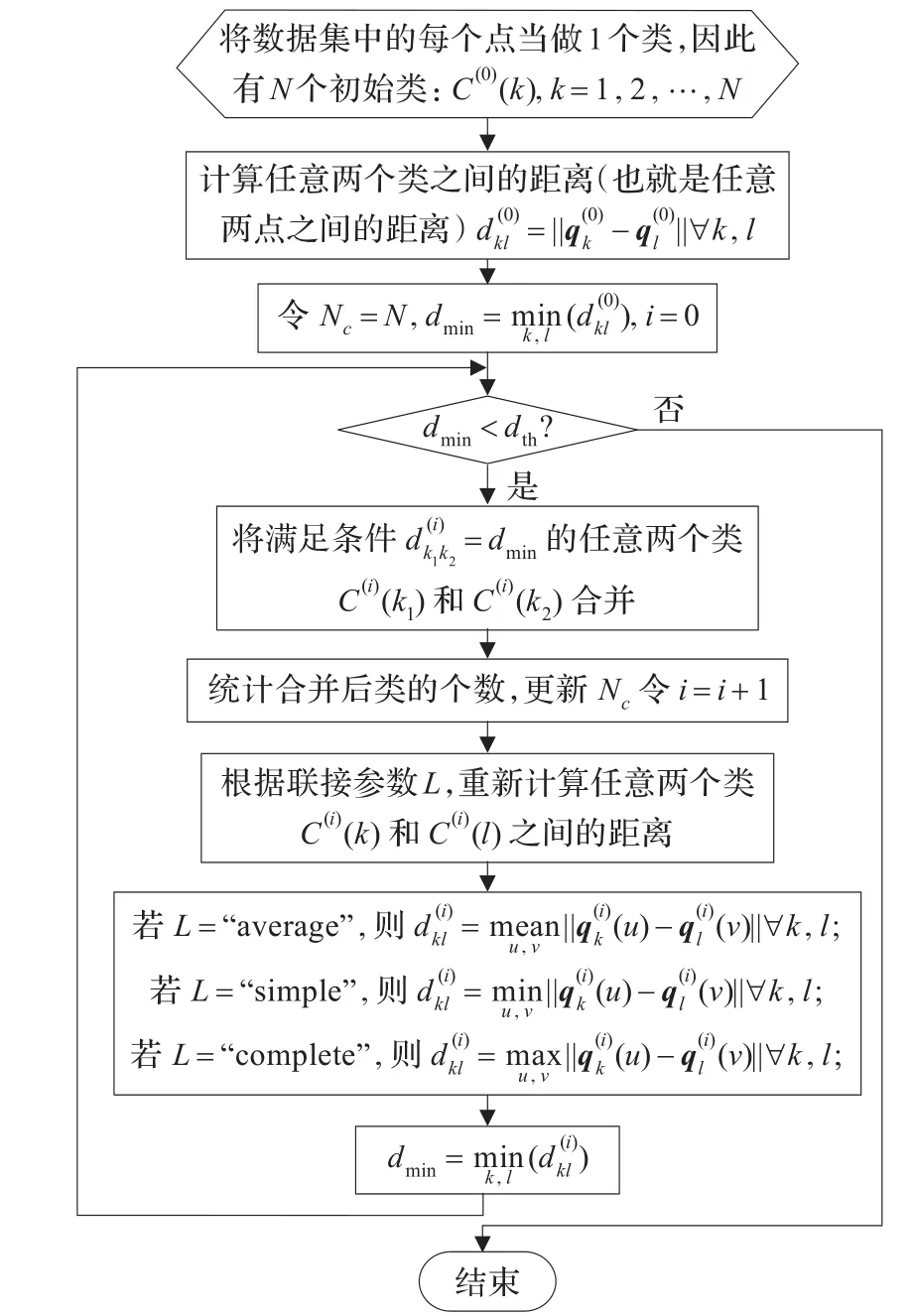
图1 AC聚类算法流程图
图1中,i表示迭代次数,C(i)(k)表示第i次迭代中得到的第k个类,(u)表示类C(i)(k)中的第u个点。此外,运算符‖·‖表示求欧氏距离(Euclidean distance),dth为欧式距离门限。考虑声源靠近的程度,设置dth为10°。
5 基于子带SRP的多声源定位算法
传统的SRP-PHAT算法难以克服声源之间的干扰,为了改善定位性能,提出基于子带SRP的多声源定位算法。SRP-PHAT函数可以看成是Nsub个子带SRP函数之和,即式(5)可写成:
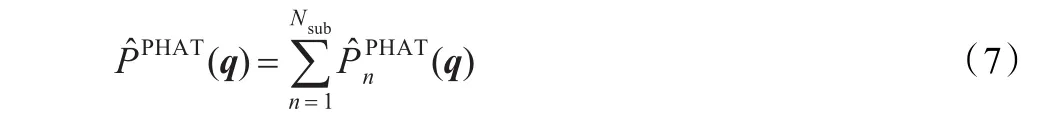
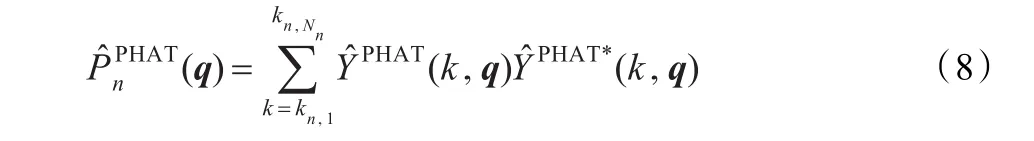
上式中,k=kn,1kn,2…kn,Nn为第n个子带的频率点。在声源空间中搜索使子带SRP值最大的点即为初始估计。
根据稀疏性假设,这些初始估计对应多个源,因此,运用AC聚类可以得到多个声源的方位估计。
如何划分子带是一个关键的问题。应遵循的原则是高频处的子带较宽以避免相位缠绕,而低频处的子带较窄以区分不同的源。但是低频子带不宜分得过细,否则容易出现错误的估计。在本文的工作中,信号采样频率为16 kHz,信号频谱分为7个子带。子带划分情况如图2所示,其中,0~2 kHz均匀地分为4个子带。为便于描述,将这些子带编号为1~7。

图2 子带划分示意图
AC聚类将初始估计分为Nc个类,但并非每个类都对应一个声源。与单声源情况类似,在一些子带,由反射声产生的虚假谱峰可能高于真实声源产生的谱峰,这将导致错误的估计。为尽量排除这些错误估计,只保留元素个数不低于γth的类,因此,类的个数减少为N′c。在本文的算法中,将γth设置为2。
在多声源定位问题中,通常假定说话人个数Ns是已知的。然而,由于语音信号时间上不连续的特点,即使知道说话人个数,一帧数据中活动说话人Na的个数仍然是未知的。也就是说只知道活动说话人的个数至多为Ns。综上所述,提出的基于子带SRP的多声源定位算法流程如图3所示。该图中,|·|表示类的势,即类中元素的个数,为Na的估计值。
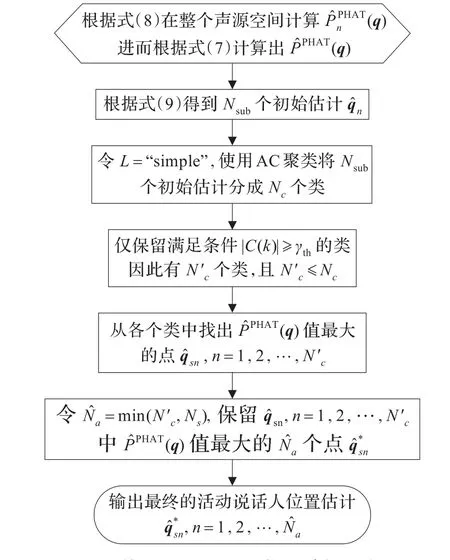
图3 基于子带SRP的多声源定位算法
6 仿真与讨论
为验证本文提出算法的性能,模拟室内环境做了不同信噪比(Signal-to-Noise Ratio,SNR)和不同混响时间(通常用T60来表示)下的计算机仿真。房间大小为5 m×4 m×3 m,麦克风阵列如图4所示。
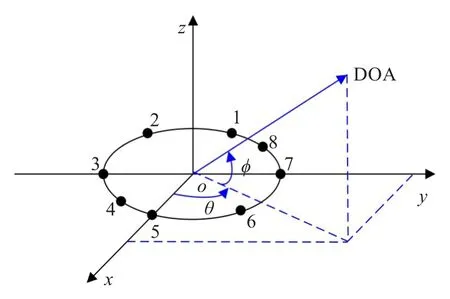
图4 麦克风阵列与DOA矢量
该阵列为均匀圆阵,半径为0.1 m,图中黑点表示麦克风,编号1~8。需要说明的是,本文提出的算法对阵形并无特定要求。如前文所述,除了仿真外,还使用了一批真实数据来进行实验。这批数据就是用图4所示的小孔径均匀圆阵采集的,为便于对照,仿真中仍使用相同的阵形。阵列放置于房间地面中心位置,坐标原点即为该阵列圆心。DOA矢量由坐标原点指向声源。在远场情形下,该矢量即为式(4)所表达的ζ。说话人个数为2,声源位置qs1= (1.5 m,70°,20°),qs2=(1.5 m,-10°,21°)。声源信号为两段女声英语语音,采样频率为16 kHz。房间冲激响应用image法[10]产生,麦克风接收信号可由式(1)得到。信号帧长512点(32 ms),帧之间不重叠,加汉宁(Hanning)窗。去除静音帧后,共有141帧数据用于定位。
水平角θ的搜索范围为-180°~180°,仰角ϕ的搜索范围为0°~90°,步长均为1°。由于小孔径均匀圆阵对仰角的估计精度较低,定位算法的性能仅根据水平角的估计结果来评价[11]。对于每帧数据,若对某个源的水平角估计误差不超过5°,则该次估计为正确的(correct)估计,否则为额外的(extra)估计[7]。统计所有帧的估计结果,得到估计的正确率和额外率。这两项指标被用来评价多声源定位算法的性能[7]。正确率定义为:

在上述两式中,I为用于仿真的信号帧数,αc(i)和αe(i)分别表示由第i帧数据得到的正确的估计次数和额外的估计次数,Na(i)为第i帧数据中活动说话人个数的真值(该值可由源信号得到)。
用本文提出的算法和文献[7]中的算法作了两组仿真。第一组固定信噪比为10 dB,混响时间为100~600 ms;第二组固定混响时间为600 ms,信噪比为5~25 dB。为便于描述,将本文提出的算法记为SRP-sub,文献[7]中的算法记为SRP-PHAT。仿真结果如图5所示。
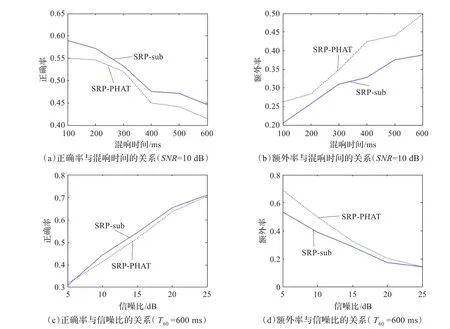
图5 不同混响时间和不同信噪比下,两种算法的定位性能比较
由图5(a)和图5(b)可见,在不同的混响时间下,SRP-sub算法比SRP-PHAT算法均有更高的正确率和更低的额外率。当混响时间大于400 ms,前者的额外率有更为明显的降低。由图5(c)可见,在信噪比为10 dB以下,20 dB以上,SRP-sub算法和SRP-PHAT算法的正确率比较接近,而在信噪比为10~20 dB之间,前者的正确率明显高于后者。由图5(d)可见,信噪比低于10 dB时,SRP-sub算法的额外率比SRP-PHAT有较大幅度降低,随着信噪比升高,二者的额外率逐渐接近。以上分析表明,在中等信噪比,较强混响环境下,本文提出的SRP-sub算法比传统的SRP-PHAT算法有较好的多声源定位性能。
7 真实环境中的实验
为进一步验证本文提出算法的有效性,使用取自瑞士IDIAP研究所的真实数据[12]来作多声源定位实验。IDIAP提供了单声源、多声源、静态和动态等多种情景的录音。取其中编号为“seq37-3p-0001”的一组数据。该组数据是在一个小型会议室中录制的,麦克风阵列如图4所示。录制时,麦克风阵列放置于会议桌上,3个说话人坐在桌旁,面对阵列。3个说话人的位置分别为:q~s1=(0.92 m,74°,21°),q~s2=(0.69 m,-7°,24°)和q~s3=(1.19 m,-50°,14°)。录制过程中,说话人成对同时说话,即s1和s2,s1和s3,s2和s3。每种情况,取6.25 s的数据,总共有18.75 s的数据。这些数据的采样频率、帧长、帧重叠度、窗函数以及搜索范围和步长均与第6章中的相同。去除静音帧后,总计有442帧数据用于声源定位实验。与仿真的情况类似,仍然使用式(10)和式(11)来评价两种算法的定位性能。值得一提的是,在录制“seq37-3p-0001”数据时,除了会议桌上的麦克风阵列外,每个说话人衣领处还别了一支麦克风。衣领麦克风与阵列同步录音,其采集的数据称为“lapel recordings”。由于衣领麦克风与说话人靠得很近,因此可将“lapel recordings”当做是单个说话人的纯净语音。根据“lapel recordings”,可得到第i帧真实数据的Na(i)。
实验结果如表1所示。由表1可见,相比文献[7]中的算法,本文提出的算法将正确率提高了约4%,将额外率降低了约7%。这充分说明本文提出的算法在真实环境中能有效地实现多声源定位。
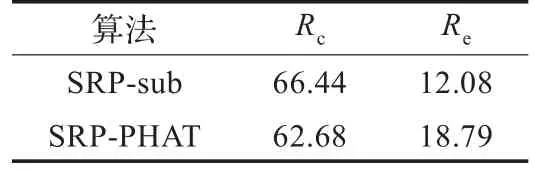
表1 真实环境中两种算法的定位性能比较(%)
8 结论
在多声源定位中,由于声源之间的相互干扰,传统的SRP-PHAT算法定位性能不高。本文提出基于子带SRP的多声源定位算法。该算法将语音信号频谱划分为7个子带,计算每个子带的SRP函数,然后在声源空间搜索其最大值得到初始估计。根据语音信号频率的稀疏性,同一个源不会在每个子带都是最强的,因此划分子带可突出较弱的源,即初始估计中包含不同的声源位置,利用AC聚类可得到最终的声源位置估计。仿真和实验表明,在两个说话人的情况下,本文提出的算法比传统的SRP-PHAT算法定位性能更好。
[1]Zhang Cha,Florencio D,Ba D E,et al.Maximum likelihood sound source localization and beamforming for directional microphone arrays in distributed meetings[J].IEEE Transactions on Multimedia,2008,10(3):538-548.
[2]Cheng Ning,Liu Wenju,Li Peng,et al.Microphone array speech enhancement based on a generalized post-filter and a novel perceptual filter[C]//Proceedings of the 9th International Conference on Signal Processing(ICSP),Beijing,China,2008:370-373.
[3]Markovic I,Petrovic I.Speaker localization and tracking with a microphone array on a mobile robot using von Mises distribution and particle filtering[J].Robotics and Autonomous Systems,2010,58(11):1185-1196.
[4]Lathoud G,Magimai-Doss M.A sector-based,frequency-domain approach to detection and localization of multiple speakers[C]// IEEEInternational Conference on Acoustics,Speech,and Signal Processing(ICASSP),Philadelphia,PA,USA,2005:265-268.
[5]Kepesi M,Ottowitz L,Habib T.Joint position-pitch estimation for multiple speaker scenarios[C]//IEEE Hands-Free Speech Communication and Microphone Arrays(HSCMA),Trento,Italy,2008:85-88.
[6]Dibiase J H.A high-accuracy,low-latency technique for talker localization in reverberant environments using microphone arrays[D].Providence:Brown University,2000.
[7]Do H,Silverman H F.A method for locating multiple sources from a frame of a large-aperture microphone array data without tracking[C]//IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP),Las Vegas,NV,USA,2008:301-304.
[8]Brutti A,Omologo M,Svaizer P.Localization of multiple speakers based on a two step acoustic map analysis[C]//IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP),Las Vegas,NV,USA,2008:4349-4352.
[9]Zhang Wenyi,Rao B D.A two microphone-based approach for source localization of multiple speech sources[J].IEEE Transactions on Audio,Speech,and Language Processing,2010,18(8):1913-1928.
[10]Allen J B,Berkley D A.Image method for efficiently simulating small-room acoustics[J].Journal of Acoustical Society of America,1979,65(4):943-950.
[11]Souden M,Benesty J,Affes S.Broadband source localization from an eigenanalysis perspective[J].IEEE Transactions on Audio,Speech,andLanguageProcessing,2010,18(6):1575-1587.
[12]Lathoud G,Odobez J M,Gatica-Perez D.AV 16.3:an audiovisual corpus for speaker localization and tracking[R].Martigny:IDIAP Research Institute,2004.
NI Zhilian,CAI Weiping,ZHANG Yidian
School of Electrical Engineering,Jiujiang Vocational and Technical College,Jiujiang,Jiangxi 332007,China
To improve localization performance of microphone array in the case of multiple speakers,a method for multiple speech source localization based on sub-band steered response power is presented.In this method,speech signal is divided into seven sub-bands in frequency domain,and the steered response power-phase transform functions are computed in each sub-band. Then initial estimations of source location are generated by searching the maximum value for each function in the source space. According to the frequency sparsity characteristic for speech signal,these initial estimations include multiple source locations. The final source location estimations are produced from them using agglomerative clustering.Simulation and experiment results show that the proposed algorithm facilitates about 4%increase in localization correct rate and about 7%reduction in localization extra rate compared with the conventional algorithm under the conditions of two speakers,10 dB signal-to-noise ratio and moderate reverberation.
microphone array;multiple speech source localization;sub-band steered response power;clustering
为了提高多个说话人情况下麦克风阵列的定位性能,提出基于子带可控响应功率的多声源定位算法。该算法将语音信号频域分为7个子带,在每个子带计算相位变换加权的可控响应功率函数,在声源空间搜索其最大值得到声源位置的初始估计。根据语音信号频率的稀疏性,这些初始估计包含多个声源的位置,运用会聚聚类算法得到最终的声源位置估计。仿真和实验表明,在有2个说话人,10 dB信噪比,较强混响的条件下,该算法比传统算法的定位正确率提高了约4%,额外率降低了约7%。
麦克风阵列;多声源定位;子带可控响应功率;聚类
A
TN912.3
10.3778/j.issn.1002-8331.1205-0133
NI Zhilian,CAI Weiping,ZHANG Yidian.Method for multiple speech source localization based on sub-band steered response power.Computer Engineering and Applications,2013,49(24):205-209.
国家自然科学基金(No.60971098)。
倪志莲(1973—),女,副教授,主要研究领域为自动控制;蔡卫平(1973—),男,博士,讲师;张怡典(1972—),女,副教授。E-mail:cwp0826@sohu.com
2012-05-17
2012-07-16
1002-8331(2013)24-0205-05
CNKI出版日期:2012-08-16http://www.cnki.net/kcms/detail/11.2127.TP.20120816.1045.013.html
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
空间电子技术(2021年4期)2021-11-10
电子制作(2019年22期)2020-01-14
复旦学报(自然科学版)(2019年3期)2019-07-19
电子制作(2019年23期)2019-02-23
电子测试(2018年23期)2018-12-29
小学科学(2016年12期)2017-01-06
噪声与振动控制(2016年5期)2016-11-09
系统工程与电子技术(2016年2期)2016-04-16
做人与处世(2015年19期)2015-09-10
