
基于拟合特征分布的垃圾网页检测方法
2013-09-11 03:20张化祥
计算机工程与设计 2013年8期
刘 阳,张化祥
(1.山东师范大学 信息科学与工程学院,山东 济南250014;2.山东省分布式计算机软件新技术重点实验室,山东 济南250014)
0 引 言
信息检索 (IR)[1]是帮助用户找到与需求相匹配的信息。由于网络包含惊人的信息,用户通常通过搜索引擎查询有用的网页。给定一个查询,搜索引擎可识别在网络上的相关网页和链接,一旦用户看到相关的链接,可以点击一个或多个链接以访问页面。研究表明[2],80%的搜索引擎使用者查看返回结果不超过三页,因此在搜索引擎返回结果中,排名越高带来的利润越大,很多网页通过欺骗搜索引擎的手段获得较高的排名,这类网页被称为垃圾网页[3]。垃圾网页损害搜索引擎的声誉,削弱了其用户对搜索引擎的信任,检测垃圾网页已是搜索引擎面临的重大的挑战之一。
目前垃圾网页的作弊方法主要分为3种:第一种是基于网页内容的作弊方法,主要作弊手段为重复重要的关键词和堆砌大量不相关的关键词。通过分析正常网页与垃圾网页的内容特征可以检测出基于内容作弊的垃圾网页,例如文献 [4]中分析网页内容特征文本单词数量、网页标题字数、锚文本比例等分布信息,利用决策树分类器进行分类;第二种作弊方法基于网页链接结构,垃圾网页通过添加多余的网页链接或误导其他网页链接指向它以此欺骗搜索引擎的排序算法。PageRank算法[5,6]是著名的网页排序算法,PageRank算法根据网页之间互相链接的贡献值对网页进行排名。越重要的网页得分越高,排名越靠前。Wang等[7]介绍了一种新的页面排序算法DirichletRank,解决了PageRank算法的zero-one gap问题;Caverlee等[8]利 用页面信任得分改进HIST算法对基于链接作弊的垃圾网页进行检测;Gyongyi[9]提出了一种基于初始信任种子集合的信任传播模式,经过多次传播之后每一个网页产生一个信任值,根据信任值的大小对网页排序检测垃圾网页。Jacob等[10]则使用了基于网络图的正则化对垃圾网页进行检测;第三种作弊方法为隐藏技术,垃圾网页通过隐藏垃圾句子、关键词和链接达到作弊目的。一个简单的方法是使垃圾关键词的颜色与背景色相同,垃圾网页还可以为用户和网络爬虫提供不同的HTML文件达到隐藏的目的。
基于内容特征的垃圾网页检测方法只考虑了网页的文本内容特征,没有考虑网页的链接结构,很难适应不断发展的网页作弊技术,而基于链接结构的垃圾网页检测方法则忽略了网页的内容信息,如果只考虑网页的拓扑结构,很难检测出那些拓扑结构与正常网页十分相似的垃圾网页。文献 [11]提出将内容特征与链接信息结合起来建立分类器垃圾网页检测。在文献 [11]中,通过对数据集的统计分析,根据正常网页与垃圾网页内容特征与链接特征分布的差异利用决策树对垃圾网页进行检测。对于某一特征,如果网页的特征值小于阈值,决策树将网页判定为垃圾网页,因此特征值小于阈值的正常网页被误判为垃圾网页。为了减少将正常网页误判为垃圾网页的错误率,本文在分析数据集网页特征分布的基础上,用各种分布函数拟合网页的特征分布,根据网页特征值与拟合函数的差值利用决策树检测垃圾网页。在后面的数据集网页特征分析中,我们可以看到正常网页的特征分布比较有规律,而垃圾网页的特征分布混乱,因此用分布函数拟合之后求差值,正常网页差值较小而垃圾网页差值较大。
1 数据集
本文采用的数据集是由yahoo实验室发布的UK-2007[12]。志愿者标注集合标记为主机级别,其中,主机名被人工标注为三类: “non-spam”、 “spam”、 “undecided”。标记为主机而非单个页面的好处是能够获得一个大的覆盖范围,这意味着样例包含了各种各样的垃圾网页以及它们之间有用的链接信息。我们只选取了 “non-spam”与 “spam”作为数据集用例。标记数据集共有5797个数据,其中spam 321个,non-spam 5476个。spam与non-spam比例为1∶17。
2 网页内容特征
2.1 文本单词数量
网页内容与查询关键词的匹配程度通常作为网页排名的一个重要因素。垃圾网页堆砌大量的流行关键词,因此在查询时可以匹配上很多关键词,排名就会靠前。本文统计了数据集中正常网页与垃圾网页的文本单词数量特征分布,结果如图1和图2所示。

在图1与图2中我们可以看出垃圾网页与正常网页的文本单词数量均在0-50之间所占比例最多。在图2中,84.7%的正常网页的文本单词数量小于500,只有3.06%的正常网页的文本单词数量大于1000,而由于堆砌大量流行关键词,在图1中超过7.5%的垃圾网页文本单词数量大于1000。正常网页的文本单词数量分布在100之后近似指数分布,垃圾网页分布散乱没有规律。我们用指数分布拟合正常网页的文本单词数量,指数分布的密度函数为

式中:λ——指数分布的参数,θ——权重,控制p(x)的值。由于文本单词数量值过大,所以将文本单词数量x值除以1000。经过实验测试,λ=3.6,θ=4.5时能够很好的拟合正常网页文本单词数量分布。,由于正常网页文本单词数量分布近似指数分布,所以网页比例与指数分布的差值较小,而垃圾网页的文本单词数量分布散乱,差值较大,因此我们把文本单词数量网页比例与指数分布概率密度函数的差值ω作为决策树的一个阈值。差值计算公式为

式中:y(x)——网页文本单词数量为x时网页所占的比例。
2.2 网页标题单词数量
搜索引擎查询结果时根据网页标题中出现的关键词返回结果,一些搜索引擎对标题中出现的查询关键词给予额外的权重,所以出现了网页标题中的关键词堆砌。正常网页标题单词数量分布与垃圾网页标题单词数量分布如图3和图4所示。

由图3和图4可知,正常网页与垃圾网页的标题字数为2时所占比例最多,网页所占比例均为13.7%,正常网页中标题字数大于15的网页所占比例为4.10%,而垃圾网页为了获得较高的排名,在网页标题中恶意填充或者大量重复目标关键词,网页标题字数大于15的网页所占比例高达10.40%。正常网页标题字数大于2时,其网页比例分布近似正态分布,而垃圾网页的网页标题分布没有规律。正态分布的概率密度函数为
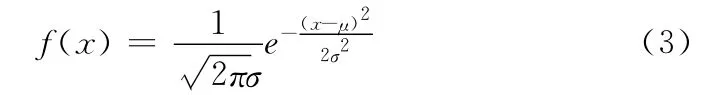
式中:μ——服从正态分布的随机变量的均值,σ——随机变量的标准差。经过实验测试μ=4,σ=3.96时函数拟合正常网页标题字数分布最佳。我们同样计算网页标题字数特征分布函数与网页比例的差值作为决策树的阈值之一。
2.3 网页压缩率
如果一个网页多次包含同一查询关键词,搜索引擎将对此网页给予较高的排名。例如,对于给定的一个查询关键词,出现十次的网页要比只出现一次的网页排名高。压缩比指未压缩的网页与压缩之后的网页的比值。数据集中正常网页与垃圾网页的网页压缩率分布如图5和图6所示。

通过图5与图6的对比可以发现正常网页与垃圾网页的压缩率均在2.1-2.2之间网页比例最大,所占比例分别为12.39%和14.5%。正常网页压缩率大于2.8的网页比例骤减,比例为6.0%,而垃圾网页压缩率大于2.8的网页所占比例为14.5%,远远高于正常网页,正常网页压缩率的网页比例在最高峰之前递增而在最高峰之后递减近似泊松分布,泊松分布的概率分布列为

其中参数ε>0。k的取值为网页压缩率除以0.2之后的整数部分,ε=10,δ=80时能够较好的拟合正常网页压缩率的分布。
为了提供更相关的搜索结果,一些搜索引擎提供网页中HTML元素的信息,例如,网页内容的注释,分配给图像的ALT属性,标题中META标签,这些元素被用于提示网页或图片的性质,但却被垃圾网页当作可视目标作为关键词堆砌。因此我们分析了可视文本比例的分布。网页中一个链接的锚文本用来对目标网页的内容注释,例如一个网页A有一个锚文本为 “电脑”的链接指向B,我们可以认为网页B的内容与 “电脑”有关,尽管网页B的关键词没有 “电脑”。有的垃圾网页仅仅是为其他页面提供锚文本,因此我们计算锚文本比例的分布。我们一共分析了包括平均单词长度、语料库前100精确度等在内的24个网页内容特征分布,并用近似的分布函数拟合求差值。
3 网页链接特征
3.1 PageRank值
PageRank算法根据网页之间互相链接的贡献值对网页进行排名。越重要的网页得分越高,排名越靠前,而那些垃圾网页往往得分较低。PageRank值的计算公式为

式中:α——衰减系数,r(q)——网页q的PageRank值,o(q)——网页q的出度。网页p的分数由两部分组成:一部分来源于那些指向网页p的网页,另一部分是全部网页对p所做的贡献。对于所有的网页,其PageRank值计算方式为
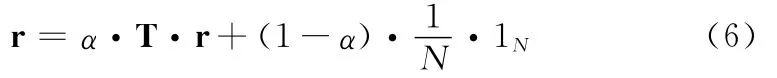
其中T为整个网络图的跃迁矩阵。T的计算方法为
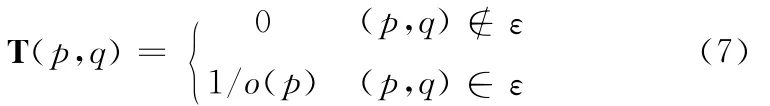
式中:o(p)——网页p的出度,(p,q)——网页p和网页q之间是否存在链接关系。
3.2 TrustRank值
TrustRank算法在PageRank算法的基础上利用信任传播的方式对每一个网页赋值一个信任值,根据信任值的大小对网页进行排名。TrustRank算法首先人工选择好的网页作为种子集合,并赋初始值,然后在web图中以信任衰减或信任分裂的方式传播直至图中每一个网页都有一个信任值。TrustRank算法认为如果一个网页有较高的PageR-ank值但是没有被好的网页指向,则这个网页很有可能是垃圾网页。TrustRank值计算公式为
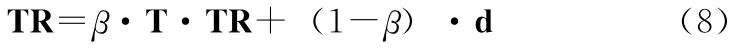
式中:β——衰减因子 (通常取值为0.85),T——web图的跃迁矩阵,d——种子集合中好网页的初始信任值。由于式(8)收敛,所以经过n(通常取值为20)次迭代后,TR值即为web图中网页的信任值。
通过计算web图中的网页链接结构得到网页的PageR-ank值与TrustRank值。网页的PageRank值和TrustRank值越大,表示该网页是正常网页的概率越大,因此我们直接把PageRank值与TrustRank值作为决策树的阈值,PageRank值与TrustRank值小于阈值的网页判定为垃圾网页。我们还考虑了数据集中主机的入度、出度、与邻居的距离等21个网页链接特征分布,用分布函数拟合并计算差值。
4 实验结果
4.1 度量标准
为了检测实验结果,我们使用web spam的准确率、召回率和F值作为实验结果的衡量标准。
表1中,TP表示垃圾网页被正确分类的网页比例,TN表示垃圾网页被错分为正常网页的比例,FP表示正常网页被误分为垃圾网页的比例,FN表示正常网页被正确分类的比例。
准确率是指预测的垃圾网页中真实垃圾网页的比例,准确率越大,算法将正常网页误判为垃圾网页的概率就越小

表1 度量单位定义
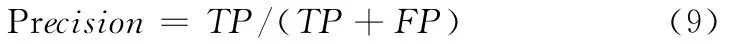
召回率是指真实垃圾网页中预测正确的比例

F值实际上是准确率和召回率的调和平均,它将准确率和召回率综合为一个指标

4.2 实验结果及分析
我们使用的分类方法为C4.5决策树。C4.5决策树分类算法的工作原理如下:给定该算法的数据集和数据集特征,C4.5决策树创建一个类似流程图的树结构。树的每个内部接点对应一个特定特征的值的测试,并且该接点的每个后继分支对应该特征的一个可能值,树叶即为对应的分类结果。对于每一个内部节点,C4.5决策树用基于信息增益的熵挑选特征,能够越好的分离训练样例的特征 (即分离后的类熵越小)放在树中的位置越高。
为了训练C4.5决策树,本文采用十折交叉验证方法。十折交叉验证算法将数据集随机的分为十等份,并执行十次训练、测试步骤,其中每次步骤使用九份作为训练数据集,剩余的一份作为测试数据集。最后取十次测试结果的平均值作为实验结果。
通过使用C4.5决策树和十折交叉验证算法对网页的每一个特征测试,实验显示用指数函数拟合文本单词数量分布的效果最好,图7为阈值的选择与实验结果的关系。
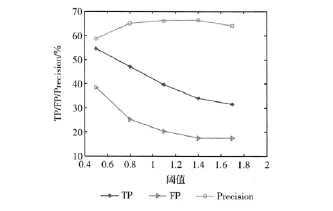
图7 阈值的选择与实验结果
当文本单词数量分布与网页比例差值选择为1.4时准确率最高,为0.662,能够识别33.9%的垃圾网页,误分页面为17.4%。
使用上述所有特征后,C4.5决策树的准确率为0.928,召回率为0.579,F值为0.713。
5 结束语
本文通过分析数据集中网页内容特征与链接特征的分布,用近似的分布函数对其拟合并计算差值,使用C4.5决策树和十折交叉验证算法根据差值对垃圾网页进行检测。实验结果表明,使用分布函数拟合网页特征分布能够减少被错误分类的正常网页,提高准确率。下一步的工作是进一步结合更多的网页内容特征分布和链接特征分布,以期获得更好的检测结果。
[1]Bing Liu.Web data mining:Exploring hyperlinks,contents,and usage data[M].Berlin,Heidelberg:Springer-Verlag,2007.
[2]Janden B,Spink A.An analysis of web documents retrieved and viewed [C]// The 4th International Conference on Internet Computing,2003:65-69.
[3]Metaxas P T.On the evolution of search engine rankings[C]//Proceedings of the WEBIST Conference,2009.
[4]Ntoulasa M,Najork M Manasse.Detecting spam WebPages through content analysis [C]//Proceedings of the 15th International Conference on World Wide Web.New York:ACM,2006:83-92.
[5]Lin Yiqin,Shi Xinghua.On computing PageRank via lumping the google matrix [J].Journal of Computational and Applied Mathematics,2009,224 (2):702-708.
[6]Oren K T,Lillian L,Cornell U.PageRank without hyperlinks:Structural reranking using links induced by language models[J].ACM Transactions on Information Systems,2010,28(4):18.
[7]Wang X,Tao T,Sun J T,et al.DirichletRank:Solving the zeroone gap problem of PageRank [J].ACM Transactions on Information System,2008,26 (2):10.
[8]Asano Y,Tezuka Y,Nishizeki T.Improvements of HITS algorithms for spam links [G].LNCS 4505:APWeb/WAIM,2007:479-496.
[9]Gyongyi Z,Molina H G,Pedersen J.Combating web spam with TrustRank[C]//Proceedings of the 30th VLDB Conference.ACM Press,2004:576-587.
[10]Jacob Abernethy,Olivier Chapelle.Graph regularization methods for Web spam decetion [J].Mach Learn,2010,81 (2):207-225.
[11]Carlos Castillo,Debora Donato,Aristides Gionis,et al.Know your neighbors:Web spam detection using the web topology[C]//Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2007.
[12]Yahoo.Research:Web spam collections[EB/OL].http://Barcelona.research.yahoo.net/web spam/datasets/,2007.
猜你喜欢
小学生学习指导(高年级)(2021年3期)2021-04-06
成都信息工程大学学报(2021年6期)2021-02-12
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
红土地(2016年7期)2016-02-27
郑州大学学报(医学版)(2015年1期)2015-02-27
