
一种基于局部二值模式的关键帧提取方法
2013-10-15 07:38谢毓湘栾悉道
计算机与现代化 2013年11期
张 芯,谢毓湘,栾悉道
(1.国防科学技术大学信息系统工程重点实验室,湖南 长沙 410073;2.长沙大学信息与计算科学系,湖南 长沙 410073)
0 引言
视频摘要,即以自动或半自动的方式对视频的结构和内容进行分析,从原视频中提取出有意义的部分,并将它们以某种方式进行组合,形成简洁的、能够充分表现视频语义内容的概要[1]。它是对长视频内容的简短总结,通常用一段静态或者动态的图像序列来表示,并对原始信息予以保留。视频摘要技术可以粗略的分为2大类型:静态摘要和缩略视频[2]。静态摘要最常用的生成策略是从原始视频中提取出一帧或多帧图像序列来表示视频的原始内容,如文献[3-5]中使用的方法。静态摘要通常是基于较底层的特征信息[2,5](颜色、纹理等)进行关键帧选取,而缩略视频是基于视频中重要片段的选取[10],所选取的片段通常为小的视频片段。
近年来,视频摘要技术快速发展,研究人员提出了很多视频摘要生成方法。文献[3]将主成分分析法和颜色直方图混合来构建三维的特征空间,使用2D-KD树对特征信息进行索引查询,提取出最优的视频关键帧;文献[4]中使用颜色直方图作为图像特征,利用改进型的k均值算法对特征进行聚类,提出了一种面向多类型快速视频摘要方法。文献[5]使用FPF(最远点开始)和M-FPF(改进型最远点开始)方法来进行视频摘要的生成。文献[6]中使用DC图像和ZNCC(零均值归一化互相关方法)建立帧图像之间的相似度模型,通过图像间的差异确定GOP(图像组)的个数,最终选取每个图像组中的中间帧作为关键帧。文献[7]为克服使用一种图像特征内容表现不强的缺点,对局部特征的提取和使用方法进行改进,将局部特征和全局特征进行融合,利用聚类思想提取视频中的关键帧。文献[8]针对动画视频自身的特点,对视频进行结构分析和内容重要度计算,提出一种面向动画视频的摘要方法。
目前,大部分研究均是基于底层图像特征(如颜色、纹理等)[3-8],采用聚类等方法选出视频代表帧或片段,利用故事板等表现技术生成浏览型或播放型的视频摘要。这些方法的特点是视频摘要生成效率较高,但摘要信息量较低,对原始视频内容表现能力较差。特别是针对长视频,由于其内容变化多,很难在保证视频摘要生成速度的同时,具有很强的内容表现力。
针对上述问题,本文提出一种信息量和摘要生成速度均衡的视频摘要方法。第一步,使用预采样技术对视频进行预处理,降低视频处理帧数量;第二步,提取视频帧的旋转不变均匀局部二值模式特征,使用该特征来表示视频的主要内容;第三步,使用改进型k均值算法对特征集合进行聚类,将具有相同语义的帧分布在同一个聚类中。第四步,使用“重要度”函数判定不同语义聚类的“重要度”,从“重要”聚类中选取距聚类中心最近的帧作为关键帧。第五步,使用故事板表现方式将选取出的关键帧按照时间顺序排序,生成静态浏览型的视频摘要。视频摘要算法结构如图1所示。

图1 视频摘要算法结构图
1 基于局部二值模式的视频摘要模型
1.1 问题描述
在静态摘要方法中,给定具有N帧的视频片段,需要求解出最优的采样M(M<N)来对N帧视频内容进行表现,同时需要保证视频的失真率最小[9]。

假设X为初始样本集合,表示为:其中,xt(1 ≤t≤N)表示特征向量集合中第t帧图像特征。
X的一部分可以表示为Q:

其中 Qi(1 ≤i≤M)表示第i个帧聚类集合。Qi∩Qj= φ,∀i,j且 i≠j。
1.2 视频预处理
视频预处理是视频摘要生成的第一步。通过视频预处理可以将视频分割成镜头片段或帧序列集合,以方便对视频操作。视频预处理技术可以粗略分为2类[10],视频边界探测技术和预采样技术。最常用的视频预处理技术是视频边界探测技术,其原理是对视频进行时间序列上的分析。预采样技术不需要对视频进行时间序列上的分析,它只需要对视频进行单独的帧提取,通过调节预抽样率来降低待分析视频帧数量。由于视频边界探测方法对镜头探测技术依赖性较大,而镜头切换的自动检测一直是视频分析领域技术难点,所以本文选取预抽样技术来对视频进行预处理。
对于时间较长的视频片段,视频分析采用预抽样方法较好,这在很大程度上降低了需要计算的帧数量。但是,一个不可忽视的因素是,抽样率的大小会直接影响最终生成摘要对视频内容的表现能力。所以需要在摘要信息量和摘要生成速度上均衡,选取合适的抽样率对视频进行预处理。经过试验分析,本文采用的抽样率为N=1/30。
1.3 视频帧特征提取
全局特征如颜色特征,由于其提取速度较快且对图像内容有一定表现能力,所以在特征提取过程中应用较为广泛,文献[3-6]均采用颜色特征来对视频内容表示。虽然全局特征提取速度较快,但对视频内容表现能力较差。文献[7]尝试将全局特征与局部特征融合,使用融合后的混合特征表示视频内容,该方法需要对2种特征分别进行提取并融合。融合后的特征在内容表现上得到加强,但摘要生成效率降低。针对这种情况,本文提出基于局部二值模式(Local Binary Pattern)的均匀模式[11-12]对视频内容进行表现。
LBP算子为一种灰度尺度不变的纹理算子,是从局部邻域纹理的普通定义得来的。其基本思想是:用其中心像素的灰度值作为阈值,与它的邻域相比较得到的二进制码来表述局部纹理特征。图像区域LBP特征描述如图2所示。
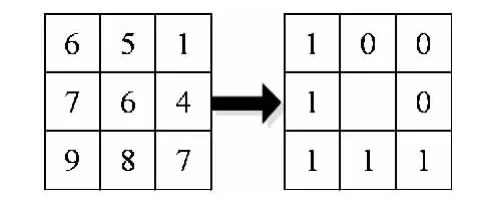
图2 LBP算子示意图
基本的LBP特征是对一个3×3邻域的二进制进行描述,其计算过程如下:
Step1 将图2所示的某3×3邻域的周围8个像素点的灰度值分别与中心像素点的灰度值进行比较,根据其大小关系对这8个像素点进行二值化。如果该像素点的灰度值大于中心像素点的灰度值,则将其置为0,否则置为1。
Step2 由图2可知,该图的 LBP模式为11110001,即1+2+4+16+128=151。
为了提高基本LBP特征的表达能力,Ojala等[11]对基本LBP特征进行了扩展,计算LBP特征时不再局限于3×3邻域,而是设定一个采样半径R和采样点数P,并以中心点为圆心,R为半径的圆周上等间隔地采样P个点。这P个点的灰度值通过与中心点的灰度值比较大小进行二值化。现在以P=8,R=1的情况为例,说明扩展LBP特征的计算过程。假设中心像素点的灰度值为gc,8个采样的像素点的灰度值分别为 g0,g1,...,g7,则中心像素点周围区域的LBP特征计算公式为:
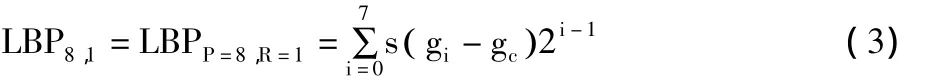
考察LBP的定义,发现LBPP,R可以产生2p种不同输出,对应了局部近邻集中P个像素形成的2p个不同的二进制形式。很显然,图像发生旋转时,圆形邻域的灰度值gi在以gc为中心半径为R的圆周上移动。由公式(3)可以看出,只要s( gi-gc)不全为0或者不全为1,图像的旋转就会得到不同的LBP值,因此,Ojala等人又对LBP算法进行了扩展,提出了具有旋转不变性的 LBP(Rotation Invariant LBP)[11],即不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值:


其中,gp=g0。满足U≤2的所有模式称为均匀模式。在P邻域中,满足 U≤2的所有模式的个数为P( P-1)+2,再进一步将它们旋转到最小值后,具有旋转不变性的均匀模式(Rotation Invariant Uniform Pattern)的个数则为P+1。因此,任何均匀模式的LBP值都可以通过统计二值编码中l的个数得到,而非均匀模式的LBP值均等于P+1:

LBP算子是一种无参数的方法,所以在应用过程中不需要对它的分布进行预先假设。与传统的全局特征如颜色直方图相比,LBP特征具有尺度不变,灰度不变性,对内容表现较强等优点;与局部特征例如经典的SIFT特征相比,LBP特征具有结构简单,提取速度快的特点,很好地克服了全局特征内容表现力差,局部特征提取速度慢等缺点。相比于LBP特征,旋转不变均匀模式LBP特征二进制模式的种类大大减少,而不会丢失任何信息。由于原始的LBP算子对纹理特征的描述有限,而旋转不变均匀模式不仅可以有效地描述出图像的大部分纹理特征,而且能明显减少特征的数量。综合分析,本实验采用尺度为(8,1)的旋转不变均匀模式LBP算子。
1.4 特征聚类
获取帧图像颜色特征信息后,需要对图像特征信息进行语义层面的分析,本文拟使用聚类方法对图像特征信息进行处理。k均值聚类方法是一种简单的无监督学习算法,它聚类速度快,但k均值方法聚类效果对初始聚类数目要求较高。例如,聚类初始个数k=5,那么k均值算法会将特征点迭代的放入这5个聚类中,直到满足聚类的终止条件。因此,聚类初始数目的设定,直接影响最终聚类效果。为了克服k均值聚类方法这一缺点,优化聚类结果,本文根据视频内容不同[4],动态的生成聚类数目k。

其中1≤i≤N,τ表示帧图像内容变化阈值。
通过公式(7)可以动态确定聚类数目k。如果连续2帧图像之间LBP特征的欧式距离大于阈值τ,聚类数目k则加1;如果小于τ,聚类数目k不变(初始聚类数目k=1)。因此,聚类数目k的仅仅依赖于阈值τ,经过实验测试,本文设定阈值τ为0.5。在实验过程中,对不同时长、内容的视频,通过进行帧图像特征距离计算获取聚类k数目。
1.5 关键帧提取
通过上一步的计算之后,确定聚类数目k,并对获取到的LBP特征进行聚类。为了描述获取聚类的“重要度”,本文引入聚类重要度函数I( i)对聚类的“重要度”进行评测[13]。其计算公式是:

其中xi表示第i个聚类所包含的帧数目;m表示聚类包含的平均帧数目;σ是聚类帧数目的偏差,其计算公式为:

利用式(8)和式(9)计算每个聚类的“重要度”值,求取所有聚类的“重要度”平均值,再根据聚类“重要度”平均值设置一个阈值。如果聚类“重要度”值大于该阈值,则提取距聚类中心最近的帧作为关键帧,生成最终的视频摘要。最后,将选取的关键帧按照时间序列排序,利用故事板表现技术生成静态浏览型视频摘要。
2 实验结果分析
为了与不同视频摘要方法进行对比,本文采用与文献[4-6]统一的实验数据和评价标准。实验所用数据为开放视频项目(Open Video Project)库中的50个视频片段,这些视频片段所采用数据相同,对比性强。OV库中视频统一为 MEPG-1格式(30 fps,352×240pixels),选取出来的视频片段有以下几种:纪录片、教育片、历史片、演讲。
本文使用用户摘要对比方法来对自动生成的视频摘要质量进行评价,该用户摘要由50个用户手动生成。其中,每一个用户观看5个视频片段并手动生成视频摘要,即每一个视频都有5个用户摘要用来进行对比。在与其它3种方法进行对比之前,首先对本文2种不同的方法进行对比。L1方法在每个聚类选取出一个关键帧,L2方法在每个“重要”聚类中选取一个关键帧,将这2种方法与其它3种自动摘要方法[4-6]进行对比分析。使用正确率(CUSA)和错误率(CUSE)两个指标进行评价对视频摘要的质量评价方法。


表1 不同方法之间的平均准确率CUSA和平均错误率CUSE

表2 不同方法在置信区间为98%条件下,平均准确率CUSA的差异

表3 各种方法在置信区间为98%条件下,平均错误率CUSE的差异
表1实验结果表明,L1方法的摘要准确率最高,L2方法的摘要错误率最低。为了验证这些结果的数据有效性,分别计算2种方法的置信区间。如果该置信区间包含0,那么这2种方法在该置信水平差异不明显;如果置信区间不包含0,则表明2种方法中一种比另外一种要好。表2和表3给出了方法L1与其它方法的对比,其中表2为L1方法与其它方法准确率的对比,表3表示L1方法与其它方法错误率对比。从表1中可以发现L1方法较L2方法准确率较高,而L2方法的错误率较L1错误率更低。在实际应用中,若要求高准确率可以选择L1方法,对错误率有严格限制,则可以选择L2方法进行摘要生成。图3为OV数据库摘要,VSUMM摘要方法以及本文L1方法3种不同方法生成的视频摘要。

图3 视频Drift Ice as a Geologic Agent,segment 8使用不同方法生成的视频摘要
3 结束语
针对静态视频摘要信息量和生成速度问题,本文提出了一种基于旋转不变均衡局部二值模式的摘要方法。该方法首先对视频进行预处理,降低分析处理数据量。使用旋转不变均衡局部二值模式特征对帧图像进行描述,利用改进的k均值算法动态得到聚类数目k,获取到相对应的语义相关聚类,根据引进的“重要度”函数从聚类集合中选取“重要聚类”。选取距聚类中心最近帧作为关键帧,将关键帧按照时间序列排序,使用故事板表现方式生成浏览型的视频摘要。基于Open Video Project项目数据来对实验方法效果进行验证,实验结果表明,该方法生成的视频摘要在摘要信息量和生成速度上表现较好,用户满意程度较高。
[1]Truong B T,Venkatesh S.Video abstraction:A systematic review and classification[J].ACM Transactions on Multimedia Computing, Communications and Applications,2007,3(1):3.
[2]Cotsaces C,Nikolaidis N,Pitas I.Video shot boundary detection and condensed representation:A review[J].IEEE Signal Processing Magazine,2006,23(2):28-37.
[3]Jiang Junfeng,Zhang Xiaoping.Gaussian mixture vector quantization-based video summarization using independent component analysis[C]//IEEE International Workshop on Multimedia Signal Processing(MMSP'10).2010:443-448.
[4]De Avila Sandra Eliza Fontes,Lopes Ana Paula Brandão,da Luz Jr Antonio,et al.VSUMM:A mechanism designed to produce static video summaries and a novel evaluationmethod[J].Pattern Recognition Letters,2011,32(1):56-68.
[5]Furini Marco,Geraci Filippo,Montangero Manuela,et al.STIMO:STIll and MOving video storyboard for the Web scenario[J].Springer Netherlands,2010,46(1):47-69.
[6]Almeida Jurandy,Leite Neucimar J,Torres Ricardo da S.VISON:Video summarization for online applications[J].Pattern Recognition Letters,2012,33(4):397-409.
[7]Guan Genliang,Wang Zhiyong,Yu Kaimin,et al.Video summarization with global and local features[C]//IEEE International Conference on Multimedia and Expo Workshops.2012:570-575.
[8]袁志民,吴玲达,陈丹雯,等.一种面向动画视频的摘要方法[J].软件学报,2009,20(z1):51-58.
[9]Jiang Junfeng,Zhang Xiaoping.A novel vector quantization-based video summarization method using independent component analysis mixture model[C]//IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).2011:1341-1344.
[10]Cernekova Z,Pitas I,Nikou C.Information theory-based shot cut/fade detection and video summarization [J].IEEE Trans.Circuits Systems Video Technol,2006,16(1):82-91.
[11]Ojala T,Pietikinen M,Maenpaa T.Multiresolution grayscale and rotation invariant texture classification with local binary patterns[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2002,24(7):971-987.
[12]王玲.基于LBP的特征提取研究[D].北京:北京交通大学,2009.
[13]曹建荣,蔡安妮.基于支持向量机的视频关键帧语义提取[J].北京邮电大学学报,2006,29(2):123-126.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
高技术通讯(2021年3期)2021-06-09
现代电子技术(2021年1期)2021-01-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
大连理工大学学报(2017年4期)2017-08-07
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年1期)2016-11-07
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
