
基于RFID技术的监护系统数据实时处理研究
2013-10-17 13:29宋四云胡金炎喻德旷
制造业自动化 2013年20期
宋四云,胡金炎,林 霖,喻德旷,王 涛
SONG Si-yun,HU Jin-yan,LIN Lin,YU De-kuang,WANG Tao
(南方医科大学生物医学工程学院,广州 510515)
0 引言
无线射频识别技术(Radio Frequency Identification,RFID)利用电磁波在阅读器和带标签的物体或人之间进行非接触双向通信,它通过交换数据来达到自动识别被标识对象以及获取被标识对象相关信息的目的[1]。相比传统的条形码技术,RFID技术具有实时性好、穿透能力强、数据量大及可重复使用等诸多优点。近年来,RFID技术发展迅速,在交通、供应链管理、校园安全等领域得到广泛使用[2~4]。利用RFID技术,加强医院产科和新生儿科的安全,提高健康监护管理水平,是随着RFID技术的成熟和普及而产生的一个新的极具前景的应用领域。为此我们设计开发了一套基于RFID技术的母婴安全监护系统(Maternalinfant Safety and Surveillance,MISS)。
母婴安全监护系统应用于医院,具有监控新生婴儿生命体征,防止婴儿被盗及母婴配对等功能[5]。系统的拓扑结构如图1所示。它基于B/S架构,分为两部分,前台显示部分和后台服务软件部分。标签(Tag)佩戴在人体上,可通过传感器接入设备,它集成两个温度传感器和一个运动传感器,以1.5Hz采样率采集人体及周围环境参数。标签整合三个传感器的信号及自身识别属性形成66比特的字节数据,然后以射频(RF)信号发送给阅读器(Reader)。一个阅读器可以接收多个标签的数据并且内置防碰撞算法避免信号冲突。阅读器是具有RF信号发射与接收模块的微系统,将TCP/IP协议栈集成于微系统中,通过TCP协议与应用程序服务器双向通信。应用程序服务器按照通信协议接收标签的实时传感数据,合理解释引用之后过滤冗余信息将其存储在数据库中。用户通过浏览器访问系统,提取已经处理过的传感器采样数据,在页面上呈现母婴的实时状况,同时在出现异常情况时控制声光报警器与LED显示器的开关,为医护人员的决策提供支持。

图1 母婴安全监护系统拓扑结构
通过对系统的测试可知,系统存在数据量大,数据采集速率快等特点。而后台服务软件在线程、数据库连接对象的建立和数据逻辑运算上均比较耗时,数据处理消耗较大[6]。因而系统相对快速的数据采集过程与相对缓慢的数据处理过程的同步性得不到满足。新生婴儿作为母婴安全监护系统的主要应用对象,其佩带的标签将采集到的生命体征信息和位置状态信息传递给应用程序服务器,而应用程序服务器需经过一系列对原始数据的解析、回调以及事件处理后以应用数据作为媒介为我们提供婴儿安全监控。在标签采集信息具有高度时域性的情况下,系统对实时处理的要求高,当有标签信息丢失、漏报或者延时较大的情况发生时,应用程序服务器因不能及时处理并解读出此异常现象而会造成系统功能上的错误。
在当前研究中,解决数据实时处理一般有两种方法。一种为硬件拓扑结构的改进,通过使用服务器集群、数据库集群,增加硬件处理能力,利用负载平衡技术来避免系统负载过重;另一种为软件设计方法,通过建立一个适合于大量数据实时处理访问的模型,提高程序的并行处理能力以达到系统应用要求[7,8]。本文所研究开发的系统,考虑到实施成本及实际的负载强度等情况,选择使用软件设计方法。
基于以上考虑,提出了一种基于多线程及缓存技术的数据实时处理方法,把数据处理过程划分为两个阶段:数据采集阶段和数据处理阶段。阶段内以流水线进行数据操作,建立多线程,每个线程为数据处理的基本粒子;阶段间建立缓存容器,异步传输数据,消除阶段间的数据同步。实践证明,该方法能有效提高数据处理实时性。
1 方法与技术
1.1 模型结构
数据实时处理方法面对的是一个前端分布式标签进行信号采集,后端集中式应用程序服务器进行信号处理的离散模型。为了搭建模型,需对几个数据指标进行评估。1)标签采集数据大小、采样频率,系统使用标签和阅读器的个数;2)系统理解完成功能,需要多大窗口的历史感知数据;3)实时传感数据与历史感知数据的比较运算耗时大小;4)应用程序服务器与数据库服务器的数据传输延时等。对此我们进行测试,系统测试环境为:
处理器:Intel(R)Core(TM)2 Duo CPU 2.94GHz
内存:2.00GB
系统类型:Windows7 32位操作系统
开发IDE:Eclipse-java-helios-SR2-win32
数据库:Mysql5.5.24
测试方法根据单一变量原则,每个过程只测试一个指标,量化的指标值是系统迭代20万次取平均值。测试结果表明,系统使用标签50个,标签每0.6s采集一条记录,每条记录大小66B,系统一天接收的数据量大约450M,共计720万条记录,所有的采集数据医院都需进行留档备份。新建一个线程平均耗时3750.2μs,线程上下文切换平均耗时2.532μs,新建一个数据库连接平均耗时15983.63μs;应用程序服务器完成实时传感数据与历史感知数据的比较运算平均耗时10227.3μs;系统理解完成功能,需要的时间窗口为10s,即当前时刻往前10s内的历史记录都有可能用到。
通过上面测试结果可知,我们需要设计一个数据实时处理方法来满足系统要求,应重点解决如下三个问题:
1)阅读器转发数据速度很快,应用程序服务器需要准确实时地接收标签数据,最小化数据丢失和延迟;
2)数据处理过程涉及到大量的数据库及逻辑操作,需要提高数据查询处理效率,满足系统的实时性要求;
3)数据采集过程和数据处理过程应该相互独立,以模块化的原则设计一个接口来通信,避免数据间同步所带来的开销。
基于上述的考虑,我们设计的模型结构如图2所示。整个数据处理流程划分前后两个阶段,数据采集阶段和数据处理阶段。缓冲队列为前后两个阶段的连接桥梁。数据采集阶段专于标签数据的采集。它维护着多个长连接线程,每个线程以TCP Socket方式与阅读器通信,接收到的实时传感数据直接存入缓冲队列中而不作其它任何逻辑处理。数据处理阶段专注于标签数据的业务逻辑运算。根据系统测试结果,在标签数据的处理周期中真正进行业务处理的时间只占整个周期的一部分(10227.3μs),大部分时间用在线程的建立与销毁(3750.2μs)、数据库连接的获取与关闭(15983.63μs)上。为了提高数据处理效率及实现对象资源共享,我们利用池化技术维护着一个线程池和一个数据库连接池来避免大量对象频繁初始化及回收过程中的开销。缓存队列设计成FIFO(First In First Out)形式避免数据采集线程与数据处理线程所需的读写同步,数据采集线程从队列尾部插入标签数据,而数据处理线程从队列头部读出标签数据。

图2 模型结构
1.2 多线程技术
应用程序服务器在数据采集阶段和数据处理阶段均使用到了多线程技术,但数据采集多线程与数据处理多线程存在显著差别。数据采集多线程中的线程以TCP Socket方式与阅读器通信,其生存周期与Socket链路连接周期相同,因而生存周期长。数据处理多线程设计的目的是利用并发提高数据处理的效率,单条标签数据的处理周期往往比较短,可以通过采用线程池技术来实现资源复用。当缓冲队列中有数据需要处理时,从线程池中提取线程进行业务操作,操作结束线程则返回线程池中,这样避免了线程的频繁建立与回收所带来的开销。
1.2.1 数据采集
数据采集多线程维护着一个管理线程和多个与阅读器通信的连接线程。连接线程作为上位机终端以TCP Socket长连接方式介入阅读器通信。在Socket通信中,阅读器作为通信的服务端(Server),上位机作为通信的客户端(Client),并管理连接。上位机与阅读器以TCP长连接方式通信,一个连接链路上可以持续发送、接收标签采集数据包。在TCP连接保持期间,为了避免链路断开,采取在客户端发送心跳包的方式。如果上位机5分钟没有收到阅读器转发的数据,则上位机给该阅读器发送一个心跳包,然后等待阅读器的返回信息。如果80秒内收不到阅读器的应答,再发送第二个心跳包,如此连续8次,仍然没有阅读器的应答信号返回,则判断此链路已经断开,管理线程进行链路重连并将此链路异常写入日志文件中。
1.2.2 数据处理
数据处理多线程维护着一个管理线程和一个线程池。管理线程创建、监控线程池,扫描缓冲队列,当缓冲队列中有标签数据时,则提取标签数据分配给线程池中空闲的线程执行。其工作时序如图3所示。

图3 数据处理多线程时序图
相比于数据采集阶段中相对固定的线程数目,阅读器与连接线程个数比例为1:1,数据处理阶段中线程池的线程个数具有很大伸缩空间。如果线程池太大,则池中线程不能充分利用,系统处理器及内存资源将因被用来维护线程池而非做实际业务操作造成资源的浪费;如果线程池太小,会出现缓冲队列过长造成系统延迟严重,或者标签数据来不及处理超出队列长度,系统发生漏报甚至崩溃现象。基于此,我们提出了一个具体的优化方法来确定线程池的最佳大小。
用C1代表单个线程创建的开销,用C2代表线程间切换的开销,利用线程池技术能有效提高系统性能的理论基础在于C1>> C2[9]。当线程池中线程个数比较小时,增加线程能有效提高系统并发数据处理的能力,但如果线程数目过多,线程间切换开销也随之增大。Yibei Ling等人[10]研究表明,线程池中最佳线程数满足如下关系:

上式中p(r)代表并发数据流的概率密度分布,n为线程池大小,最佳线程池大小不仅同C2与C1的比值相关,还同系统实际负载分布情况相关。
我们开发的母婴安全监护系统标签个数N =50,标签采样间隔Ts = 0.6s,单个标签在采样周期内发射的时间点记为X,它是一个随机变量服从均匀分布X ~ U(0,0.6),期望值E(X)= 0.3,方差D(X)= 0.03。由于随机变量X1,X2,…,Xn…相互独立且服从同一分布,在N相对较大的情况下,根据中心极限定理,随机变量之和 的标准化变量:

服从正态分布Yn~ N (0,1),即,由系统测试结果可知,C1等于3750.2us,C2等于2.532us,C2与C1的比值为,因而(1)可以重新表达为:

通过查表可知N1=3.20,N2=3.21代入(3)式中,可知n为14,即线程池的最佳大小为14。
1.3 方法的缓存技术
本文研究的方法中使用两种缓存技术,针对数据缓存的缓冲队列和针对对象缓存的数据库连接池。
1.3.1 缓冲队列
为了消除阶段间数据同步,实现数据采集过程与数据处理过程异步数据传输,我们建立了一个缓存容器。同时为了正确实时处理采集的数据,保证数据处理与数据采集的同序性。我们把缓存容器设计成队列形式[11],队列是一种运算受限的线性数据结构,它只能从一端插入数据从另一端提取数据,满足FIFO原则,其特性与数据采集处理特性相符合。缓冲队列的主要属性包括队列长度,数据逗留时间,其管理图如图5所示。
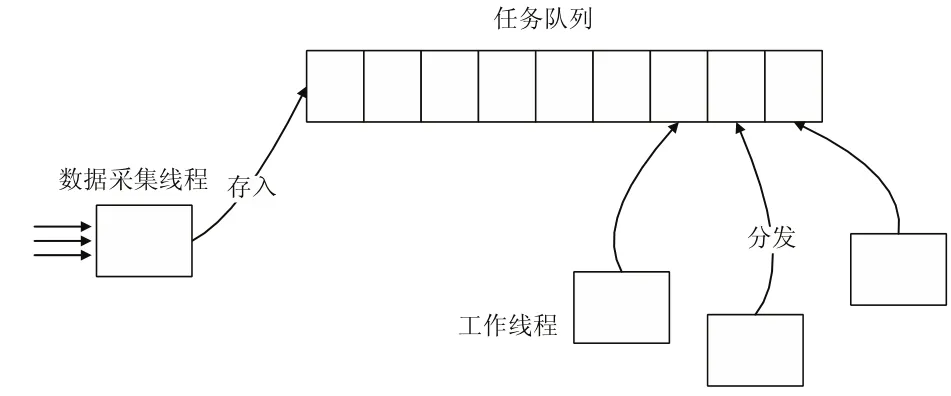
图4 FIFO缓存队列管理图
通过启用一个管理线程实时监控队列的长度变化,当缓冲队列长度达到最大阈值,管理线程增加处理线程数,当缓冲队列长度到最小阈值时,管理线程会释放多余的处理线程,此方法不仅能控制缓冲队列的长度在最小阈值与最大阈值之间变化,还能满足实时数据处理的实效性,提高系统的动态调控能力。
1.3.2 数据库连接池
在数据流实时处理系统中,不可避免的涉及到大量的数据库操作,应用程序服务器访问数据库分为四个步骤:1)应用程序服务器加载驱动程序;2)驱动程序管理器识别加载的驱动,获取数据库连接;3)根据获取的数据库连接对数据库进行操作;4)关闭连接,释放相关资源[12]。由我们的测试可知,数据库连接的建立与关闭上耗时15983.63μs,比数据的比较运算10227.3μs还多。为了避免消耗大量资源的过程重复进行,我们使用数据库连接池作为缓存对象池来解决大量线程频繁访问数据库所带来的效率问题。
数据库连接池的技术原理如图5所示。应用程序服务器在系统初始化时建立一些空闲连接放入连接池中备用,当线程有数据库连接访问请求时,直接从连接池申请一个数据库连接,调用完成之后,把数据库连接重新放入连接池中而不实际关闭。数据库连接池中同样存在管理器,当并发访问量持续增加时,管理器建立一些新的数据库连接放到连接池中。当访问减少时,管理器则关闭一些空闲连接,避免空闲期间维护大量连接所带来的资源消耗。
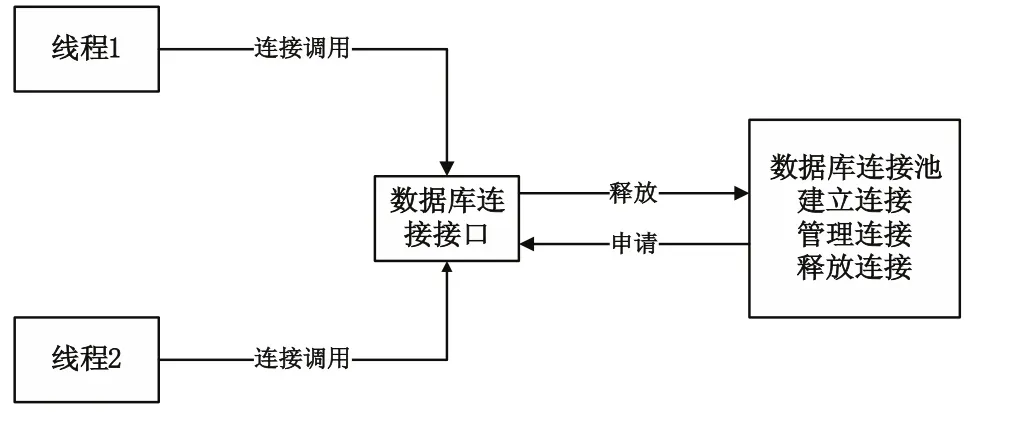
图5 数据库连接池技术原理图
2 结果
为了评价数据实时处理方法的性能,我们对系统进行了仿真测试。使用三台计算机搭建仿真测试平台。应用程序服务器环境为上节中的系统测试环境。数据库服务器的硬件配置为Intel Pentium D 2核2.8GHz CPU、2G内存、250G硬盘,操作系统为Centos 6.1、使用Mysql5.5.24作数据持久化数据库。另外在一台双核4GB内存、Intel(R)Core(TM)i5 2.5GHz CPU的计算机模拟标签数据流。仿真系统共有10个阅读器、50个标签,标签间隔0.6s发送一条记录,记录大小为66B,标签发送数据的起始时刻服从均匀分布。仿真测试平台连接在局域网内。
应用程序和测试程序都使用Java语言开发,JDK版本为1.7.0,使用Eclipse IDE作为集成开发工具。在测试某个方法的优化效果时,根据单一变量的原则,将测试代码插入测试目标中,比较使用该方法和不使用该方法在同样配置的计算机上前后性能指标的差异。我们主要比较了缓冲队列、线程池和数据库连接池三种技术,通过采用性能测试工具Java VisualVM来测量查看CPU及内存的使用率[13]。

表1 方法的性能测试
表1是方法的性能测试结果,我们从发射/接收数据包、接收成功率等性能指标进行评价。从上表中的测试结果可以看出:未使用三种技术时,CPU和内存的使用率都比较小,数据接收成功率很低,数据的转发能力弱。由于标签传感数据发射速度很快,服务线程需要完成数据接收、数据处理、数据持久化等一系列工序,致使发射数据从Socket缓冲堆栈中溢出导致丢包。当我们在方法中加入缓冲队列后,由于数据采集线程专于标签数据的接收,数据的接收成功率有了大幅度提高。然而缓冲队列中每一条数据都需要新开一个线程进行处理,线程处理完成该数据后又要进行资源回收,使得系统负荷大为增加,从而导致程序稳定性很差,接收的标签数据大部分都存入缓冲队列中而来不及处理,延时非常厉害,从实用的角度来看,只使用缓冲队列明显不符合实际要求。为了避免资源重复分配、回收所带来的开销,利用对象资源池技术建立一个线程池,线程池中线程可以复用进行数据处理,从上面的测试结果可以看到,数据处理时间大为缩短,方法的实时性得到了明显改善,缓冲队列的长度也减小,数据转发能力得到质的提高。基于同样道理,为了避免数据库连接建立与关闭的开销,我们引入数据库连接池。使用数据库连接之后,系统负荷(CPU峰值、CPU均值和内存均值)得到下降,数据包转发能力接近理想值(83.33),缓冲队列的长度也减小,证明了系统实时性得到了进一步提高。
3 结束语
本文研究开发的数据实时处理方法应用于医院母婴安全监护系统,在实验阶段取得比较理想的结果,本文实现了如下创新:
1)分开数据采集过程与数据处理过程,整个流程划分为前后两个阶段,阶段内执行流水线型操作,阶段间使用缓冲队列实现数据异步传输;
2)测试了系统创建线程、线程间切换和建立数据库连接等操作的开销,为系统进行模型设计打下数据基础;
3)为了避免对象重复创立、回收带来的系统开销,我们设计实现了线程池,数据连接池,并从理论和实践上证明了其有效性。
[1] 孙基男,黄雨,黄舒志,等. 一种基于 Petri 网的 RFID 事件检测的形式化方法[J].计算机研究与发展,2012,49(11):2334-2343.
[2] 倪霖,钟辉,段超.汽车制造生产线上RFID应用模式研究[J].计算机工程,2012,38(4):224-226.
[3] 廖燕.基于RFID的供应链管理信息系统集成[J].武汉理工大学学报: 信息与管理工程版,2010,32(004):610-613.
[4] 胡洋.RFID和AJAX 相结合的校园安全管理系统[J].计算机应用与软件,2010,27(6):183-185.
[5] 于楠,胡金炎,邹岸,王涛,等.一种母婴安全监护系统数据库的设计和实现[J].计算机应用与软件,2013,5(30):200-202.
[6] 袁文明,王东.网络化RFID系统的复杂事件处理模型研究[J].计算机应用与软件,2010,27(12):48-50.
[7] 亓开元,赵卓峰,房俊,等. 针对高速数据流的大规模数据实时处理方法[J].计算机学报,2012,35(3):477-490.
[8] 丁振华,李锦涛,罗海勇,等.RFID系统与传感器网络中的数据处理综述[J].计算机应用研究,2008,25(3):660-664.
[9] KWAK H,LEE B,HURSON A R,et al.Effects of multithreading on cache performance[J].IEEE Transactions on Computers,1999,48(2):176-184.
[10] LING Y,MULLEN T,LIN X. Analysis of optimal thread pool size[J].ACM SIGOPS Operating Systems Review,2000,34(2):42-55.
[11] 崔慎智,陈志泊.基于多代理和多优先队列的短信实时并发算法[J].计算机工程,2011,37(3):278-280.
[12] 梁清翰,沈占锋,骆剑承,等.构建LBS系统的数据库连接池技术研究[J].计算机工程,2006,32(12):40-41.
[13] JUNEAU J,DEA C,GUIME F,et al. Debugging and Unit Testing[M].Java 7 Recipes. Apress,2011:213-236.
猜你喜欢
电子设计工程(2022年15期)2022-08-17
山西电子技术(2021年3期)2021-06-28
英语世界(2020年10期)2020-11-06
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
英语世界(2020年2期)2020-03-08
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
军营文化天地(2018年2期)2018-12-15
