
基于超混沌序列的数据库零水印算法
2013-10-22 03:22欧阳苗
陕西理工大学学报(自然科学版) 2013年2期
欧阳苗
(厦门理工学院应用数学学院,福建 厦门 361000)
0 引言
数字水印技术通过在不被察觉的条件下将版权等特定信息加密隐藏在要发布的数字媒体中,实现信息的隐秘传送或版权保护。在外包数据库服务模式中,由于数据库服务器由第三方提供,物理文件可能轻易地遭到复制,故而需要对数据库的版权进行保护。S.Khanna等于2000年提出利用数字水印控制数据库安全的方法[1],开启了数据库水印技术的探索之门。两年后,R.Agrawal等人在美国国家科学基金会技术资助下,提出在数据库的数值属性最低有效位嵌入水印的算法[2],R.sion等提出了通过构造项目集合嵌入有实际意义水印的方案[3],也带动我国学者开始了相关研究[4-6]。
与一般多媒体数据库对比,关系数据库水印在以下几方面有显著差异,如表1所示。

表1 关系数据库与多媒体数据库的区别
首先,现有的数据库水印方案的水印容量小,水印的鲁棒性很难达到要求;为此,本文引入零水印数据库。其次,现有水印方案未考虑如何筛选嵌入水印的数据项;事实上,数据项筛选在随机性、离散性、安全性上的不同会给后续各项流程带来类似蝴蝶效应的差异,本文将超混沌系统引入数据项筛选,旨在改良水印的鲁棒性。再者,现有算法倾向选取MSB(Most Significant Bit)或LSB(Least Significant Bit)上的数据构造水印,然而关系数据库的属性值域不相同的居多,不相同的数值型字段有效位数也不尽相同;因此,考虑到对不同的冗余空间,可以将重要比特位做更细致的分区,按需要从中选取数据来增强水印方案的鲁棒性和安全性。
1 基于混沌变换的零水印构造
1.1 基于混沌变换的数据项筛选
筛选前,先采用哈希函数SHA-1(Secure Hash Algorithm)为数据项进行标记:
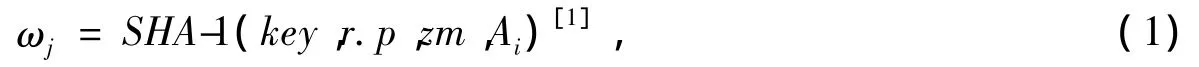
利用属性标记密钥key来计算每一条数值属性的hash值,ωj∈[ω1,ω2]作为这条数值属性的标记值。r.p为属性所在记录的主键,zm为属性名称,Ai为数值属性的值。
(1)生成混沌序列
混沌变换有确定性、遍历性、伪随机性、初值敏感性等特性,借助混沌序列筛选出的数据项不依赖于其他的元组,呈离散的分布状态,增强了水印的鲁棒性、安全性。这里用Logistic函数生成混沌序列,

0≤μ≤4称为分支参数,Xi∈(0,1)。在3.5699457≤μ≤4时(2)式进入混沌状态,初值 X0,经过 n次迭代,产生长度为n的一维混沌序列{Xi|i=1,2,…,n}。
(2)线性变换
由线性函数
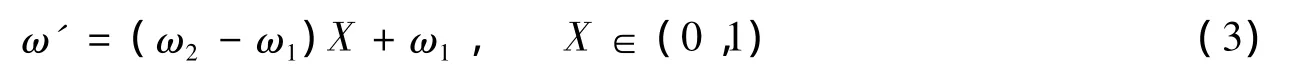
把混沌序列{Xi|i=1,2,…,n}约束到 ωi的取值范围[ω1,ω2]内,得到集合 ω':{ωi'|i=1,2,…,n}。
(3)判定标记值是否存在
从集合ω'中取得ωi',从数值属性标记值集合ω中取得的ωj,将ωi'与ωj依次判断是否相等,相等则提取标记值ωj,表明该数据项被选中;不相等,则取下一个i=i+1,进行判断。通常我们可以增大生成的混沌序列数据项,用来筛选出满足待提取水印位数的数据项。
1.2 不同比特位数值的提取
现有数据库零水印方案通过提取数值属性值的最高有效位的最高比特位来构造零水印[7],这样产生的水印鲁棒性不高。毕竟数据特征权重长度FWL越大,FSB(第一重要比特位)越能代表数据的特征,然而FWL越小,FSB和TSB(第二、三重要比特位)对于数据所代表的特征性越接近,因此可以用TSB代替FSB提取零水印,并不会降低水印质量。
(1)数据分类
利用筛选出的数据项数值确定分类长度L1,L2(L1>L2)。L1为筛选出的数据项数值特征权重长度均值:
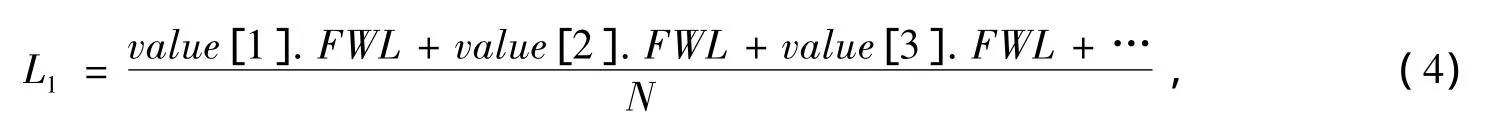
L2为筛选出的数据项数值小于0的特征权重长度均值(m为特征权重长度小于0的数据项个数):
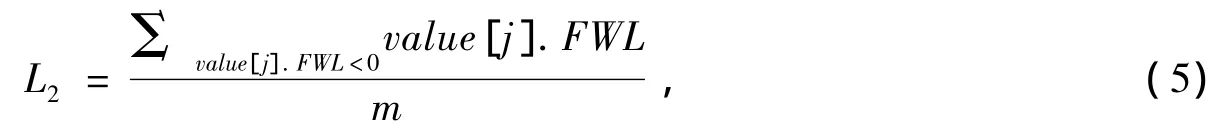
找出筛选出的数据项按ρ的长度与L1,L2(L2<L1)的大小关系,依表2所示确定提取水印的位置。

表2 筛选出的数据项类型及对应提取水印位置
(2)提取初始水印
分别对不同类属的数据进行相应比特位的提取,作为初始水印序列ω':{ωi'|i=1,2,…,n}。
1.3 混沌置乱
依照图1提取了初始序列信息后,引入二维超混沌变换系统,将其混沌置乱。
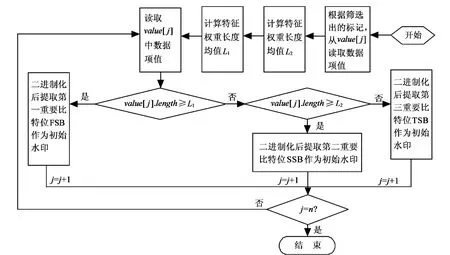
图1 提取不同比特位处理流程
(1)混沌序列的生成
从实际需要出发,将二维伪随机序列进行降维,给定初值(x0,y0)生成一维超混沌伪随机序列{Lp|p=1,2,…,n}。
(2)初始序列的置乱
得到{Lp|p=1,2,…,n}后,将1.2中提取出来的初始序列通过混沌系列置乱处理。生成的混沌序列与初始的水印序列{ωi'|i=1,2,…,n}通过下标对应起来,将Lp排序(冒泡法),即将混沌序列Lp按大小顺序排列好,同时依照使ωi'的下标排列顺序与Lp下标顺序相同的规律调整ωi'。
1.4 零水印的生成
零水印的性能测度一般关注两个指标:峰值信噪比和归一化互相关系数[8]。为计算零水印的相似度,需要对其作转换,通过映射:
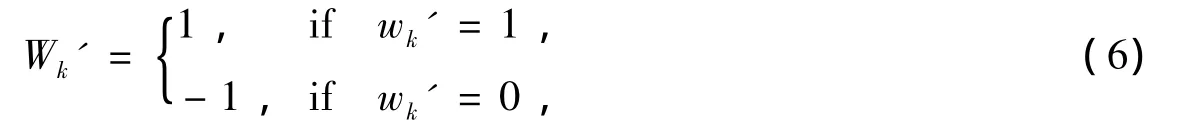
提取的初始序列转换成后续待用的零水印。
2 基于混沌变换的零水印检测
当版权纠纷发生时,我们需要检测发生纠纷的数据库。它包含从ZWMC[7](Zero-watermarking Manage Center)中获取、重构零水印,以及相关性计算;其中零水印的重构算法优劣直接关系到水印的构造、嵌入、获取之后能否被检测出来,是研究重点。
2.1 零水印证书的获取
零水印证书由ZWMC[7]通过数字签名和加密技术颁发,记录了版权所有者信息以及注册的零水印信息,因此零水印检测过程需要零水印证书作依据,文献[9]详细记载了获得过程,这里从零水印重构开始。
2.2 重构零水印
水印的检测会使得原始数据库发生改变,甚至某些属性值也遭到删改。重构过程可以采用提取初始水印之前的构造过程,因此主要讨论提取了初始水印之后的环节。
(1)提取初始水印
标记待提取的数据项并保存在数组team中,标记重构过程中筛选的数据项并存在数组team’中,提取初始序列的过程如图2所示,算法流程图如图3所示。
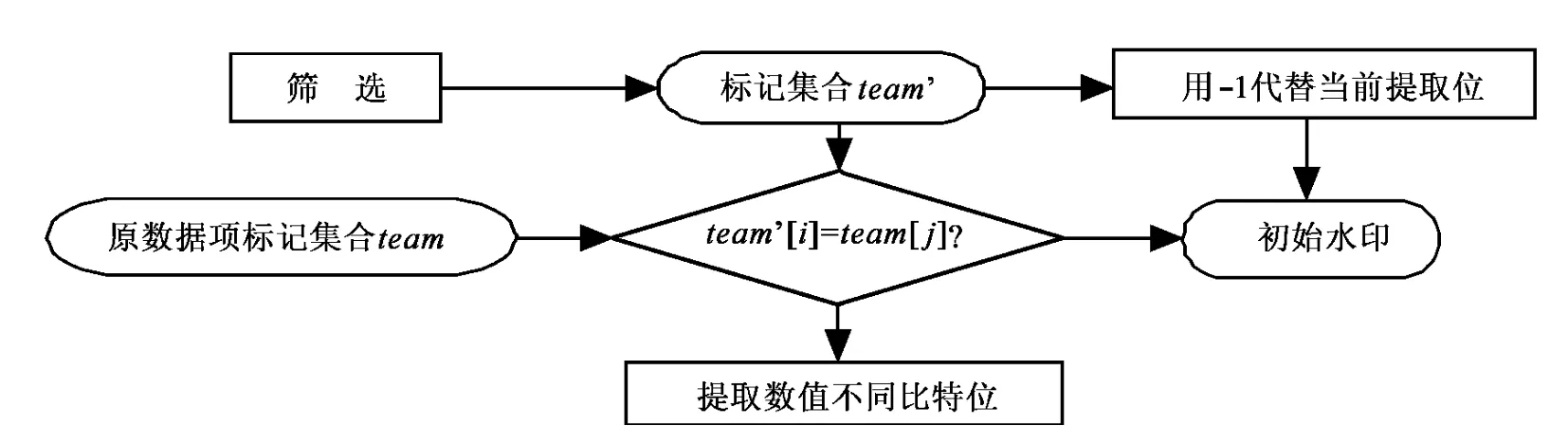
图2 重构时提取初始水印过程
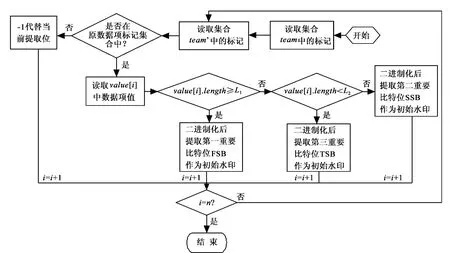
图3 重构时提取初始水印处理流程
比较集合team’与集合team,若team’内的标记已经存在于在team中,则取数值不同比特位来生成初始水印;若team’中的标记不存在于team中,说明筛选的标记没在原数据项标记集合中,为了便于计算最后零水印相似度,我们用“-1”代替提取的初始序列值。
(2)混沌置乱和相关转换
接着利用构造时的混沌系统与初值混沌置乱初始水印,进行重排。由于重排过的水印序列会出现“-1”,“1”,“0”,而提取时初始序列只包含“1”,“0”,故将置乱后的序列再按下式转化,以便利用相关性计算公式计算水印的相似度:
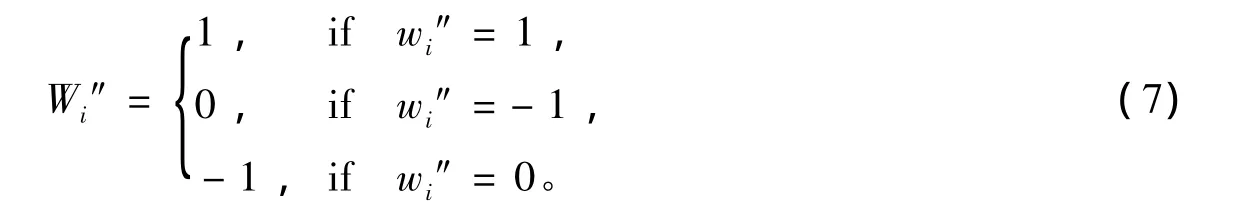
(7)与(6)中的转换本质相似,唯一区别在于“-1”到“0”的转换。重构水印提取的初始序列中包含“-1”,说明有一位的零水印没有被检测出来;对应这位零水印的数值属性可能遭到删改,于是在检测过程中用“0”表示。
2.3 相关性计算
相关性计算是判断版权归属的重要方法,通常将从版权纠纷的数据库中重构出的零水印与从ZWMC中获取的零水印比对给定的阈值,来确定版权归属。
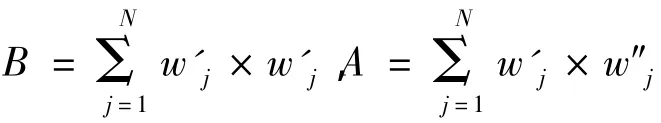

其中W'和W″分别表示注册的零水印和检测时重构的零水印。理论上,阈值的确定应经过尽可能多的实验来观测,笔者做的实验数量上显然不够;考虑到原始数据库提取出的水印为二值序列,它们将以0.5的概率完全匹配,可以粗略的预期计算得出的η也应在0.5左右。若相关性检测的结果大于0.5时,认定含有指定水印。
3 实验结果与分析
最常见的三种数据库水印攻击为:子集增加攻击、子集更改攻击和子集删除攻击。以下实验分析针对这三种攻击展开,不失一般性,选取阈值π=0.5,水印序列长度N=100。
3.1 子集增加攻击
我们在5000条实验记录数据的基础上依次增大添加比例模拟攻击,给出本文算法对比文献[10]算法的子集增加攻击值曲线图,如图4所示。
待构造水印的数据项由二维超混沌序列筛选产生,因此有效的抵抗了元组重排,减弱通过加入元组对重构水印的影响。从图4中可以看出η在增加比例不超过80%时,都能检测出水印信息。而文献[10]的方法则不能有效的抵抗子集增加攻击的影响。当增加比例到达30%时,η为0.57,而且随着增加比例的上升,η的衰减速度很快。实验结果表明,本文算法对子集增加攻击的抵抗性更好。
3.2 子集更改攻击
显然对数据库数据更改比例越大,攻击越显著,但同时破坏程度也越大。现实情况中,过多的对数据施加更改攻击将导致盗用者得到的数据库价值大大降低,一般更改比例不高于整个数据比例的40%。
本组实验选取全部数据中按比例进行随机的抽取后,更改其属性值;依次增大更改比例,以观察随着更改比例的加大,验证水印算法的抗攻击能力变化并计算相应的相似度。
如图5所示,攻击比例高达40%时,η为0.55,依然可以检测出零水印的存在,不难看出,本文算法对更改攻击表现出较好的抗攻击性。
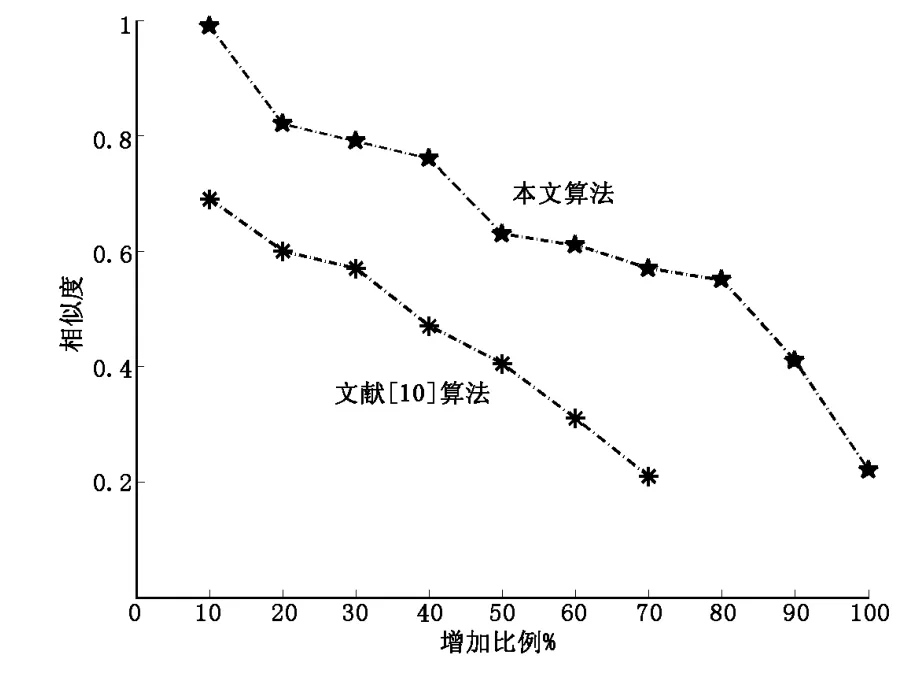
图4 子集增加攻击
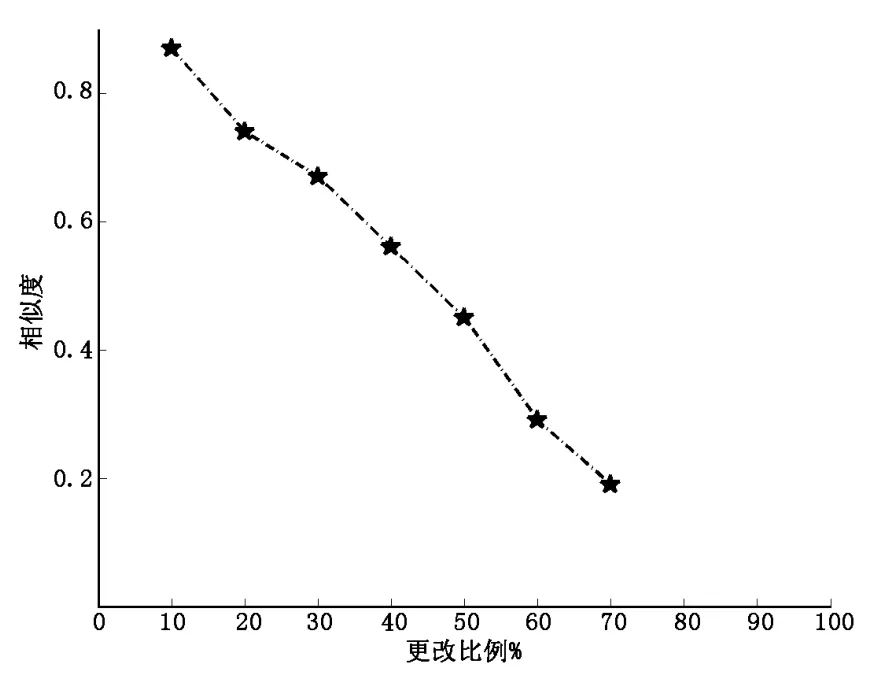
图5 子集更改攻击
3.3 子集删除攻击
子集删除分三种情形处理:数据库首删除,数据库尾删除、随机删除,结果如图6所示。

图6 子集删除三种攻击
实验表明:从首部删除比例达到45%时,从尾部删除比例达到50%时,随机删除比例达到60%时,仍能检测出水印的存在。
对关系数据进行子集删除攻击实验时,水印信息随着删除比例的加大而减弱,但这三类攻击下的水印检测指数η的曲线比较接近,说明了嵌入水印的位置与数据前后顺序关系不大。随机删除攻击的抵抗效果好于首、尾大块删除的抵抗效果,因为构造水印时筛选过数据项,使得水印信息均匀分布开,因此随机删除时大比例丢失水印信息的概率减小了;相对而言,无论从首部还是尾部开始的大块删除则使水印数据丢失比例偏高。
综上所述,本文算法的鲁棒性能较好,即使数据删除比例达到40%,水印相似度依然在55% ~63%之间。
4 结束语
本文设计了一种基于混沌变换的数据库零水印模型:把混沌变换引入数据库零水印构造或检测过程中,借助混沌序列筛选待构造水印的数据项。在不同数据项冗余空间嵌入水印,通过分析数值型数据项有效位,依据特征权重均值对数据项进行分类,提取不同比特位生成水印。实验结果表明本方案算法对添加攻击、删除攻击、更改攻击显示出较强的抗攻击性。
[1]Hakan Hacigumus,Bala Iyer,Shared Mehrotra.Providing Database as a Service[C].Proc of ICDE,2002.
[2]Sanjeev Khatma,Francis Zane.Watermarking maps hiding information in structured data[C].SODA,2000:596-605.
[3]Sion R.Proving ownership over categorical data[C].Proceedings of IEEE International Conference on Data Engineering,2004:584-596.
[4]黄敏,张浩,黄加恒.一种基于数据库的水印技术[J].计算机工程与应用,2005,41(10):153-156.
[5]姜传胜,孙星明,易叶青,等.基于JADE算法的数据库公开水印算法的研究[J].系统仿真学报,2006,18(7):1781-1784.
[6]彭沛夫,林亚平,张桂芳,等.基于有效位的数据库的数字水印[J].计算机工程与应用,2006,42(11):166-168.
[7]蒙应杰,吴超,苏仕平,等.一种关系数据库零水印方案的探讨[C].中国第22届数据库学术会议论文集,2005.
[8]张桂芳,孙星明,肖湘蓉.基于中国剩余定理的数据库水印技术[J].计算机工程与应用,2006,42(7):135-137.
[9]蒙应杰,吴超,张文,等.数据库零水印注册方案的研究[J].计算机工程,2007,33(2):133-135.
[10]蒙应杰,吴超.关系数据库零水印的构造算法[J].兰州大学学报:自然科学版,2007,43(6):51-55.
[11]李帅,王卫星.基于超混沌迭代的双重零水印算法[J].计算机工程,2008,34(17):158-161.
[12]王丽娜,司颖,季称利.基于数字签名的安全零水印方案[J].计算机科学学报,2010,37(7):55-56.
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
