
汉语特征词研究的缘起、意义和方法
2013-11-03 03:28刘云
华中学术 2013年2期
刘 云
(华中师范大学文学院,湖北武汉,430079)
汉语特征词研究的缘起、意义和方法
刘 云
(华中师范大学文学院,湖北武汉,430079)
特征词指能够反映文本特征、分布差异较大的词语。特征词的研究缘于以下四个方面:信息论中关于熵的研究,情报学中关于反文献频率的研究,语料库统计中各种词表的建立,语言学研究中的方言特征词研究。特征词的研究具有较大的理论意义和现实意义,一个可行的研究方法是以国家语委通用语料库为对象来考察时代特征词和语体特征词。
特征词 语料库 词语分布
一、 引 言
所谓特征词,是指能够反映文本特征、分布差异较大的词语。由于词汇统计对语言研究、语言教学、词典编撰、信息处理等有较大的实用价值,世界上几种主要语言如英语、法语、俄语、西班牙语、日语、德语等都进行过较大规模的词汇统计研究,已有统计项目涉及字节数、形符数、类符数、类符形符比、平均词长、句子数、平均句长、段落数、平均段落长,等等。汉语的词汇统计主要通过“频率”“分布率”“覆盖率”等统计项来建立词频词典和常用词表,这种统计是把语料库作为一个整体进行统计;汉语特征词的统计与分析试图把通用语料库按时间、领域等分为子语料库分别进行统计,然后通过比较得出特征词,这种统计是把语料库分解为子语料库进行统计。特征词的统计需要一个高质量的平衡语料库,国家语委现代汉语通用语料库(以下简称“通用语料库”)是国家语委精心打造的国家级平衡语料库,主要服务于语言文字的信息处理、语言文字规范标准的制订、语言文字的学术研究、语文教学和语言文字的社会应用等方面。本文的统计对象就是国家语委现代汉语通用语料库。
汉语特征词的统计与分析的对象是通用语料库中那些分布上的特征词。在日常的语言使用中,我们时常会发现有这样一种现象:有些常用的特高频词(如“的”“了”“不”“在”“是”等)在不同领域(如“政治”“经济”“科技”“文化”等)和不同时期(如“解放前”“‘文革’期间”“改革开放后”等)的文档中出现的频率差别不大,也就是说,这些特高频词在不同领域和不同时期的文档中分布得比较均匀。同时,也有一些词语(如“跑道”“蛙泳”“裸绞”“预蹲”“叠兵”等)在某些特定类别(如“体育”)的文档中出现的频率会高于它们在其他类别文档(如“经济”“科技”“文化”等)的频率。这说明有些词语在区分文档类别方面的能力较强,这些分布上差异大的词就是需要研究的特征词。汉语特征词研究的内容主要有两大部分:一是利用数理统计的方法,把通用语料库中的年代特征词和语体特征词抽取出来并建立特征词表,同时,设计一些简单实用、易操作的语料库统计工具;二是结合时代文化背景和语体特征对这些特征词进行分析。语言与社会有着密不可分的关系,从语言与社会、语言与文化的角度分析年代特征词和语体特征词,例如不同时期、不同语体的人名、地名和机构名等特征词反映的社会文化意义。
二、 特征词研究的缘起和意义
(一) 特征词研究的缘起
汉语特征词的统计与分析缘于以下四个方面:信息论中关于熵的研究,情报学中关于反文献频率的研究,语料库统计中各种词表的建立,语言学研究中的方言特征词研究。
(1) 信息论中关于熵的研究。1850年,德国物理学家鲁道夫·克劳修斯首次提出熵的概念,用来表示任何一种能量在空间中分布的均匀程度,能量分布得越均匀,熵就越大。1948年,美国数学家香农(Claude E.Shanon)在BellSystemTechnicalJournal上发表了《通信的数学原理》(AMathematicalTheoryofCommunication)一文,将熵的概念引入信息论中。在信息论中,熵表示的是不确定性的量度。从信息论的角度看来,用自然语言交际的过程,就是从语言的发送者通过通讯媒介,传输到语言的接收者的过程,因此,也可以测定语言的熵。语言的熵就是在交际过程中语言符号出现的不定度,不定度的大小与语言的熵的高低一致。当语言的接收者接收到语言符号之后,不定度被消除,熵等于零,因而在交际过程中,语言接收者所得到的信息量恰恰等于被消除的熵[1]。特征词在不同的文本中分布差异较大,不确定性比非特征词要大,因此,特征词尤其值得关注。
(2) 情报学中关于反文献频率的研究。1972年,Spark Jones提出计算文献频率有助于计算词权重,从此反文献频率(Inverse Document Frequency,简称IDF)公式在信息检索中占据重要地位,是信息检索中计算词与文献的相关权重的经典计算方法,它不仅可以用于计算关键字检索中关键字与相关文献的相关权重,而且可以用于计算文献自动分类中主题词与相关文献的相关权重。IDF基于这样一个假设:稀有词比常用词包含更新的信息。构成文本的词的数据量是相当大的,因此在进行文本特征抽取时,如果把所有的词都作为文本特征,计算量会非常大,而且不同的词对文本分类的贡献差别很大,因此在文本分类时优先选择的是更有效的特征词语,这些特征词语选择的标准就是要最大限度地区分不同的文档,其特征选择的依据就是词语在文章中的权重,包括该词语在文本中出现的频率和该词语在文本集合中的分布情况。在反文献频率的研究中,特征词占有重要地位。
(3) 语料库统计中各种词表的建立。随着计算机技术和网络技术的迅猛发展,学界为了服务于语言研究、语文教学、中文信息处理和辞书编纂等工作,建立了一大批语料库。随着研究和统计手段的提高,先后建立了十多个有影响的词表。这些词表对语言研究、语文教学、中文信息处理和辞书编纂等工作起到了极大的推动作用,仔细观察这些词表可以发现,各个词表的规模、性质、作用与目的各不相同,对统计项的选择也不相同。所凭借的统计项不一样导致部分词语有的词表收了有的词表没有收,其中就有一些特征词。对特征词的进一步深入研究,还可以反观这些词表的优劣。
(4) 语言学中方言特征词的研究。方言特征词是不同方言词汇之间的区别特征,是表现该方言词汇特征的最重要的方言词。李如龙编《汉语方言特征词研究》共收录12篇研究特征词的文章,它们从内部和外部分别研究了官话方言、山东方言、晋语、北部吴语、徽语、赣语、客家方言、闽方言、闽东方言、粤语、雷琼闽语等方言的特征词。李如龙先生把“方言特征词”界定为:方言特征词是一定地域里一定批量的、区内大体一致、区外相对殊异的方言词[2]。此外,辛世彪《关中方言特征词概说》(钱曾怡、李行杰主编《首届官话方言国际学术讨论会论文集》,青岛出版社,1997年)、张振兴《闽语特征词举例》(《汉语学报》2004年第1期)等也都对方言特征词进行了探讨。方言特征词从某种意义上说是词汇在地域上的分布特点,如果探讨词汇在年代和语体上的分布特点,相应的也会有年代特征词和语体特征词[3]。
(二) 特征词研究的意义
汉语特征词的统计与分析是一个值得下大力气认真研究的课题,具有较大的理论意义和现实意义。
(1) 推进语料库语言学的研究。近年来语料库语言学得到了迅猛发展,在多个领域取得了丰硕的成果。语料库语言学是语言研究中的一种重要方法,通过对语言的结构、分布、使用、变迁等要素进行数量分析来揭示语言的状态、性质和特点。特征词的统计与分析试图深入语料库的内部,通过比较各子语料库词汇的频率差、频率比、频序比、独用词、出现文本数等得出特征词;反过来,通过子语料库的频差分析、相似性对比分析和信息熵计算等来考察通用语料库的建设质量,进而反思语料库的建设。
(2) 推进计量词汇学的研究。判断成词与否一般有三个标准:结构、意义和音节,除此之外还有频率标准[4]。特征词的研究表明频率标准不能仅以频率高低为依据,还要结合分布率,因为频率高不一定分布率高,频率的高低只是在整个语料库中的总体表现,而分布率则需综合考察词汇在子语料库中的表现。目前的语言研究主要还是定性研究,科学研究的方法除了定性研究的方法外,还有一种是定量方法。定量方法运用数学方法对客观事物及其现象进行测量,并通过获得的数据对事物的属性进行研究,从而从本质上把握该事物。对汉语词语的研究是否也能进行计量研究,以及从何种角度进行研究,是值得尝试的课题。
(3) 推进社会语言学的研究。通过比较各子语料库词汇的频率差、频率比、频序比,可以得出年代特征词和语体特征词,进而结合时代背景和语体风格考察这些特征词反映的时代特征和语体特征。通过特征词的考察,可以把语言中的词汇同社会、文化等背景结合起来进行研究。
(4) 推进中文信息处理研究。特征词研究使用的统计方法可以用于文本数据挖掘、文本自动分类、自动文摘、全文检索等。以领域特征词为例,领域特征词的获取是基于内容的文本处理中的基础关键技术,文本分类和主题分析等需要庞大的领域词表支撑,在信息抽取和信息检索中抽取和检索的对象很大程度上也依赖于领域特征。中文信息处理迫切需要在特征词的提取上取得突破性的进展,要求特征词能够确实标识文本的特征内容,具有将目标文本与其他文本相区分的能力,而且特征词的分离要比较容易实现。
三、 特征词研究的方法
(一) 基本思路
就基本思路而言,特征词的研究可以采用间接式和直接式两种方式。间接式是以已有的词语研究为基础,例如《现代汉语词典》从1965年的试用本迄今已有近半个世纪,也先后出版了多个版本,由于不同版本的收词都有一些变化,有增词也有减词,正好可以用来研究各个不同时期的特征词。这种方法的优点是工作量比较小,但间接式的特征词研究最大的问题在于其研究不是基于真实语言生活,是建立在研究基础之上的研究,难免会有较大的误差;而且,《现代汉语词典》没有给每个词标注语体,这样就没办法考察语体特征词。直接式的特征词研究是以真实的语言生活为材料,考察各个阶段和各个领域的特征词,这种方法最大的优点是尽可能地接近真实的语言生活,缺点是工作量较大,考虑到计算机的强大处理能力,这种方法还是值得尝试的。因此,汉语特征词的统计与分析以国家语委通用语料库为对象来考察时代特征词和语体特征词。
首先按照不同的分类方式把整个通用语料库分为若干子语料库。三种分类方式为:(1)以“大事件”为节点的社会阶段分期,即以“建国”、“改革开放”为节点划分为三个子语料库:1919—1949年、1950—1978年、1979—2000年;(2)以“十个自然年”为节点的时间分期。即:以10个自然年为节点,划为六个阶段:1919—1949年、1950—1959年、1960—1969年、1970—1979年、1980—1989年、1990—2000年;(3)以语体划分,即按通用语料库的一级分类划分为四个子语料库:报纸、人文社会科学、自然科学和综合类。
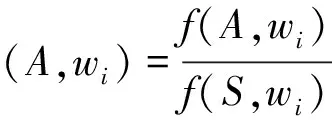
再次,给这三种统计量设定一个阈值,把待筛选的特征词自动抽取出来。综合频率差、频率比和频序比三种统计量抽出的待筛选特征词,出现三次的可以确认为特征词,出现两次的可以基本确认为特征词,出现一次的则需考虑统计量的具体数值,必要时进行人工筛选。
最后,结合社会文化背景和语体特征分析这些特征词,包括言语词和语言词。
(二) 具体方法
具体研究方法拟采取先易后难、先试验后全面展开的方法。以年代为例,比较而言,新中国成立前子语料库与改革开放后子语料库语言差异要大一些,容易提取特征词,所以先比较这两个子语料库;而两者与新中国成立到改革开放之间的子语料库的差异要小一些,放在后面比较。在进行全面统计之前,先抽取一定数量的样本进行试验,以比较各种统计量之间的优劣,初步试验表明频率差、频率比、频序比各有所长,频率差的优点是直接了然,缺点是对高频词容易误判;频率比的优点是准确率高,缺点是有些低频词的比值差异相当细微难以发现;频序比的优点是准确率高,缺点是由于各子语料库词语总数不同导致少数低频词的可比性低。因此,特征词的统计综合考虑频率差、频率比、频序比这三个统计量,试图抽出一个尽可能完整的待筛选特征词表,最后结合时代文化背景和语体特征分析这些特征词。
主要使用定量分析方法和结合社会文化的方法。所谓定量分析方法,就是“将处于随机状态的某种语言现象给予一定的数量统计,然后通过频率、频度、频度链等量化形式来揭示这类随机现象背后所隐藏的规律性”,也就是借鉴自然科学的方法,用统计数字说话[5]。词汇研究长期以来以定性研究方法为主,“所谓定性式研究方法,即研究主要评介的是研究者对材料的主观感受与判断”[6]。在定性研究中,个人的判断起着重要作用,研究所依据的主要是个人熟知的部分语料以及研究者的个人语感,因此不可避免地会带来个别结论与普遍规律、个人判断与普遍占有材料之间的矛盾。尤其是词汇的研究中,个人的主观感知往往会对客观的评判产生深刻的影响。所以,有必要运用定量分析方法这种自然科学的常用方法,对词汇进行研究。社会生活的各个方面,诸如政治、军事、法律、习俗、工商业、教育等的发展变化,无不影响着词语的产生、发展、演变。只有将词汇研究置于社会发展的大环境中,才能把握词汇分布、发展的历史动因。特征词直接反映了社会的发展变迁、民族的文化传统,从词汇与社会政治、经济、文化教育、社会意识形态等的发展相联系的角度出发,探究和把握词汇发展史的外部历史原因。
(三) 采用的统计项目
统计的对象主要是词语,统计项目主要有频次、频率、出现文本数、覆盖率、词性分布、词类分布、独用词、共用词、频差、频比、使用度、通用度、语料相似度和熵。汉语特征词的统计与分析先统计出词语出现的次数,然后计算出这些词出现的频率,再在此基础上统计其他项目。其中频次、频率、出现文本数、覆盖率是比较常用的概念,不需赘述,其他项目相关方法的描述如下[7]:
(1) 频率差
假设总语料为S,A为S的一个子库,相对于S和A,任一词汇wi的频率差(简称频差)的计算公式为:
频差(A,wi)=f(A,wi)-f(S,wi)
(1)
其中,f(S,wi)表示频率,即词语wi在分类语料中的频率与在总语料中的频率之差。
频差一般反映了某一个词语在分阶段语料和在总语料中的分布差异性,能够凸显子语料库的一些语言特征。
(2) 频率比
假设总语料为S,A为S的一个子库,相对于S和A,任一词汇wi的频率比(简称频比)的计算公式为:
(2)
相对频差而言,频比更能反映出分类语料的特色,频比高的词语一般是分类语料的独用词,而且使用较频繁。
(3) 使用度
使用度用来刻画字或词语在应用上的广泛性、平衡性,是压缩后的频次,在相同频率下,词频分布越均匀,则压缩越少,使用度越高。
使用度的计算涉及另外两个参数:变异系数与扩散率。
词语wi变异系数的计算公式为:

(3)
其中D为wi的方差,E为期望,n为分类语料的数目。
扩散率的计算公式为:

(4)
使用度的计算公式则为:

(5)
其中C(Aj,wi)表示词语wi在语料Aj中出现的频次。
(4) 通用度
与使用度类似,通用度也是用来刻画词语在应用上的广泛性和平衡性。尹斌庸、方世增在《语言文字应用》1994年第2期的《词频统计的新概念和新方法》中提出了通用度的概念。所谓词语的“通用度”,是指词语在语言应用的各个领域里常用性的综合指标。简单地说,通用度就是词语在语言应用的各个领域里通用的程度。通用度兼顾了词语的分布率和频率两个方面,并且把两者有机地结合起来了。通用度概念中所说的“领域”,既可以指“空间”,也可以指“时间”,它既可指一个词在共时的语言应用中各领域里的通用程度,也可指一个词在历时的各个时期里的语言应用中的通用程度。
通用度的计算公式为:

(6)
其中C(Aj,wi)表示wi在子语料库Aj中出现的次数。
(5) 语料相似度
将每个语料A表示成向量:
Corpus(A)=(w1,w2,w3,…,wi,…,wn)
其中,wi为语料中出现的词语的频次,然后使用VSM计算语料之间的相似度,相似度计算公式如下:

(7)
(6) 熵比较
按信息论的理论,熵表示信息量的多少。如语料用A表示,则其熵的计算公式为:
(8)
其中f(wi)表示语料库A中某一对象wi在A中的频率。
本文为教育部新世纪优秀人才支持计划(NCET-11-0655);国家社会科学基金项目(批准号:08BYY059)。
注释:
[1]冯志伟在国内首先测定了汉字的熵,认为从汉语书面语文句的总体来考虑,在浩如烟海的全部现代汉语书面语文句中,包含在一个汉字中的熵为9.65比特,因而每当我们从汉语书面语文句中读到一个汉字时,我们就获得9.65比特的信息量。参见冯志伟:《汉字的熵》,《语文建设》,1984年第4期。
[2]参见李如龙:《中国语言学报》,2001年第10期。
[3]国外的语言学研究中早就关注到特征词的问题,例如Halliday, M. A. K., A. McIntosh & P. Strevens.TheLinguisticScienceandLanguageTeaching.(London: Longman1964)认为语域之间的不同主要表现在形式上,即表现在词汇和语法上,其中词汇方面的区别表现得最明显,以英语为例,cleanse(清扫)主要用在广告里,probe(探查)主要用在报纸上,特别是报纸的标题上。
[4]参见刘云、李晋霞:《论频率对词感的制约》,《语言教学与研究》,2009年第3期。
[5]参见唐钮明:《定量方法与古文字资料的词汇语法研究》,《海南师范学院学报》,1991年第4期。
[6]参见苏新春:《汉语词汇计量研究》,厦门:厦门大学出版社,2002年,第14页。
[7]这些常见统计项目的解释可参见国家语言资源监测与研究中心编:《中国语言生活状况报告》(2007),商务印书馆,2007年。书中收录的《语言资源监测与研究相关术语(2008版)》公布了108条相关术语。
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
海外华文教育(2016年1期)2017-01-20
中国修辞(2016年0期)2016-03-20
长江学术(2016年4期)2016-03-11
当代教育理论与实践(2015年9期)2015-12-16
中文信息学报(2015年4期)2015-04-21
中国修辞(2015年0期)2015-02-01
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
