
基于均衡7×2交叉验证的模型选择方法
2013-11-21 10:37杜伟杰王瑞波李济洪
太原师范学院学报(自然科学版) 2013年1期
杜伟杰 王瑞波 李济洪
(1.山西大学 数学科学学院,山西 太原030006;2.山西大学计算中心,山西 太原030006)
0 引言
模型选择是统计机器学习中的重要研究领域.模型选择的主要目标就是选择到真模型.在传统的回归问题中,通常使用留一交叉验证(LOO,Leave-one-out Cross-validation)方法来进行模型泛化误差的估计,并且早期的一些工作也已证明留一交叉验证估计是渐进无偏的[1].但是,基于留一交叉验证方法却不具有模型选择的一致性[2].为此,Shao[2]的工作指出,当且n1→∞(n1,n2为训练集及测试集容量,n为样本总容量)时,交叉验证方法才会保证模型选择的一致性.在此基础上,他提出了基于均衡不完全组块的交叉验证方法(BICV,Balanced Incomplete Cross-validation).不过,并未给出满足上述条件的BICV的构造方法.
对于分类问题,Yang[3]研究了分类器选择的一致性问题.他指出,由于分类模型的性能收敛速率与回归模型的性能收敛速率完全不同,因此,分类器选择的一致性并不需要满足Shao[2]提出的条件.他给出了分类器选择的一致性的充分条件,并特别指出当高维分类数据中相应收敛率满足一定条件时,标准2折交叉验证方法是具有分类器选择的一致性的.
标准2折交叉验证虽然计算量较小,但受到样本划分的影响较大.对于样本容量为n的数据集,总共可以得到个不同的2折交叉验证划分.而标准2折交叉验证只随机地取其中一次.为了弥补这个缺陷,一些研究者提出使用多次重复结果的平均值来提高性能,并构造出m组2折交叉验证方法.本文称之为随机m×2交叉验证(R m×2CV),也有文献称之为多次对折分割方法(RHS,Repeated Half Splitting)[4].
Smyth[5]提出使用MCCV的方法来选取混合模型中的份数K.他的试验结果表明,MCCV中设置时可以得到较好的结果.他的这种设置可以看作是随机m×2交叉验证中的一种简单的变形.另外,Nason[6],Celeux[7]等的模拟结果均表明在某些情况下,使用随机m×2交叉验证方法可以得到模型参数的最优估计值.
在检验问题中,Dietterich[8]针对两个分类模型性能差异的检验问题,提出了5×2交叉验证t检验.他的模拟实验结果证明,5×2交叉验证t检验比一些其他的检验具有更优的势.Alpaydn[9]对Dietterich[8]的检验方法进行了改进,提出了5×2交叉验证F检验.
尽管随机m×2交叉验证方法使用了多次独立的重复划分来减小标准2折交叉验证估计的波动,但由于多次重复都是针对同一数据集进行的,这导致不同切分的训练集之间存在共同样本.因此,m次独立的2折交叉验证之间的结果并不完全独立.m次标准2折交叉验证的平均结果与各次划分后训练集和测试集的共同样本有关,共同样本个数会影响最终m×2交叉验证估计的方差.因此,本文针对m=7的情形,提出了一种均衡的7×2交叉验证方法,它使得2次独立划分后训练集和测试集之间的共同样本个数相同(称此为均衡性),并给出了均衡7×2交叉验证的构造方法.
本文的主要目的在于考察分类问题中均衡7×2交叉验证对最优模型选择的性能.为此,本文将其与常用的标准5折交叉验证、标准10折交叉验证以及最近提出的组块3×2交叉验证方法进行对比.模拟实验结果表明,本文提出的均衡7×2交叉验证方法比其余的三种交叉验证方法具有更高的选到真模型的概率.
1 模型选择的交叉验证方法
交叉验证方法(如5折、10折交叉验证)常用于模型选择任务中.但不同的交叉验证方法在选到真模型的概率上会有差异.本节将介绍两种基于交叉验证策略的模型选择方法.
1.1 组块3×2交叉验证
组块3×2交叉验证方法由李济洪等[10]提出,主要的思想是使用3次重复的2折交叉验证来进行泛化误差的估计,但与随机3×2交叉验证不同,他将均衡设计的思想融合到重复实验的构造中,提高了2折交叉验证估计的精度.组块3×2交叉验证具体的构造方法是首先将数据集随机分成4份,不失一般性,可将其设为(1)、(2)、(3)、(4),使用其中任意2份作为训练集,其余2份作为测试集,这样便可做3组2折交叉验证,见表1所示的3组实验.

表1 组块3×2交叉验证实验设置
记表示第i组中第k折交叉验证得到的泛化误差.表示第i组中2折交叉验证的泛化误差的均值,即.这样,可以得到组块3×2交叉验证泛化误差的估计如下:

组块3×2交叉验证方法中,不同组的任意两份之间的样本交叉个数均为n/4.与随机3×2交叉验证中不同组之间任意两份交叉个数不相等且随机变化的情况不同.组块3×2交叉验证体现了试验中均衡设计的思想.
1.2 均衡7×2交叉验证
沿用组块3×2交叉验证的思想,我们这里考虑将数据集切分为8份,提出均衡7×2交叉验证,即针对标准2折交叉验证构造7次不同的重复,每2次重复之间要保证样本的交叉个数为.但如何将这8份数据组合来满足均衡设计交叉验证的要求,这里与组块3×2交叉验证不同,因为只有7组实验满足均衡设计的思想,这里不再是C48的完全组合.为了快速找到满足组块7×2交叉验证的7组实验,我们提出了正交表选择法.我们选取L8(27)正交表见表2.但与一般正交表使用方法不同的是,正交表中的7列代表了7组2折交叉验证试验,其中每列里“+”代表这份数据属于训练集,“-”代表这份数据属于测试集.具体的构造方法如下,首先把数据集平均分为8份,不失一般性可设为(1),(2),…,(8),然后按照上述方法得到表3所示的7个分组,将8份数据集组合形成7组不同的标准2折交叉验证.
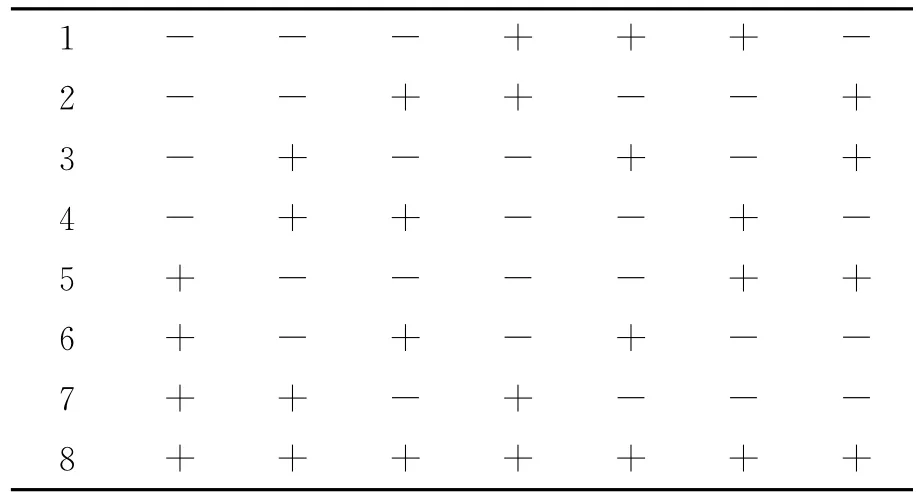
表2 L8(27)正交表

表3 组块7块2交叉验证实验设置
根据表2所示的构造方法,可以得到均衡7×2交叉验证泛化误差的估计如下:

从构造均衡7×2交叉验证的方式来看,对于不同组的数据集之间重叠的样本数相同,均为n/4.Nadeau和Bengio[11]证明了对于任意两次独立的划分,两个训练集中相同的样本个数是一个随机变量且服从期望为n/4的超几何分布.我们提出的均衡7×2交叉验证方法正好满足n/4这个理想值,这就是均衡设计的思想.直观上这种设计可能会得到较小的方差,从而得到性质更优良的交叉验证估计.以下通过模拟来比较几种交叉验证的方差.
参照文献[3]模拟试验的设置,产生500个样本,重复100 000次模拟试验得到分类回归树(CART)模型下泛化误差的4种交叉验证估计的真实方差.由表4的试验结果可以看出均衡7×2交叉验证的真实方差明显小于标准5折、10折交叉验证.另外,相对于组块3×2交叉验证来说,由于重复次数增多,均衡7×2交叉验证可以有效地降低估计的方差,因而在模型选择中可能会有较好的结果.

表4 几种交叉验证方差的模拟比较
2 模拟实验
本节以分类回归树(CART)为分类模型,通过各种模拟来比较5折交叉验证、10折交叉验证、组块3×2交叉验证和均衡7×2交叉验证在模型选择中的表现.特别地,考虑到均衡7×2交叉验证的计算量大于标准10折交叉验证,为了比较在相同计算量下均衡设计的交叉验证与标准交叉验证之间的模型选择性能的好坏,我们从均衡7×2交叉验证的7组试验中随机抽取5组,构成均衡5×2交叉验证,并通过模拟试验与其他几种交叉验证在模型选择中的表现进行了对比.
2.1 模拟试验的设置
考虑一个两类分类问题,设模拟数据为Z=(X,Y),其中Y~b(1,p),实验假定共有10个特征,自变量系数取值非0的特征组成了真模型,为了减少试验复杂度,不失一般性,假设前5个特征的系数非0,即β=(β1,β2.β3,β4,β5,0,0,0,0,0,),其中p由 Logistic模型产生:

对于β中的非0项,借鉴了文献[7]模拟试验中的设置,即从(-1)u(α+|2|)中随机产生,其中α=.通过这样的数据设置既可以保证真模型中的特征对响应变量的影响是显著的,又可以使产生的模型有比较合适的信噪比.由于α是由N决定的,因此当给定N的时候,便可以为真模型产生一组系数值,并将其固定.本文共选择了包含真模型在内的6个模型作为候选模型,分别为s0:前5个特征(即真模型);s1:前6个特征;s2:前7个特征;s3:前8个特征;s4:前9个特征;s5:前10个特征.
产生模拟数据时,假定10个特征独立且都服从标准高斯分布N(0,1),随机产生N个独立同分布的样本,则可以得到一个N×10的特征矩阵X,将X带入真模型s0中,得到相应的Y值.以Z为观测数据,分别计算6个候选模型在5种不同的交叉验证策略下得到的泛化误差的估计值,以最小的泛化误差的估计值为目标得到每种交叉验证策略所选出的最优模型.重复试验1 000次,计算每种交叉验证下选到真模型的频次,并以此来比较不同的交叉验证模型选择方法性能的优劣.这里应当注意,每个候选模型所对应的特征矩阵是不同的,如s3只含有前8个特征,其特征矩阵应为X的前8列.依照上述实验设置,样本量N分别取值为500,1 000,1 500,2 000,得到4组实验结果,见表5.
从表5的试验结果可以得到如下结论:
1)在4种交叉验证方法中,均衡7×2交叉验证模选到真模型的概率明显高于其余3种交叉验证.这说明本文提出的均衡7×2交叉验证方法更适用于进行模型选择.

表5 试验结果
2)通过选取不同样本量的实验结果可以看出,当样本容量减小时,5种交叉验证模型选择性能均有所提高,而且均衡7×2交叉验证模型选择性能更加突出.所以在样本容量较小时我们提出均衡7×2交叉验证模型选择方法更加有效.但随着样本量的增加,几种交叉验证策略之间的差异逐渐减小.
3)通过均衡5×2交叉验证和标准10折交叉验证之间的比较来看,两者计算量基本相同,但是在小样本的情况下,我们提出的带有均衡设计的交叉验证选到真模型的概率更大,在模型选择中的表现更好.另外,均衡5×2交叉验证比均衡7×2交叉验证选到真模型的概率小,那么在计算能力允许的前提下,采用均衡7×2交叉验证进行模型选择会获得更好的结果.
3 总结和展望
本文通过模拟实验证明了均衡7×2交叉验证在小样本分类问题下,模型选择的性能高于组块3×2交叉验证和标准5折、10折交叉验证.下一步,我们可以将组块7×2交叉验证模型选择方法进一步推广至高维数据下,验证其是否在高维数据模型选择任务中仍然具有更好的性能,同时可以进一步验证在高维情形下是否可以具有模型选择的一致性.另外,本文通过对组块3×2交叉验证的推广提出了均衡7×2交叉验证,下一步将提出一种均衡m×2交叉验证的构造方法,验证其在模型选择方面是否会得到了更好的性能.我们推测,随着m的增大,这种组块m×2交叉验证会具有更好的性能.在未来的研究中可以在这些方面做进一步工作.
[1]Li Ker Chau.Asymptotic optimality for Cp,CL,cross-validation and generalized cross-validation:discrete index set[J].Ann.Statist.,1987,15(3):958-975
[2]Shao Jun.Linear model selection by cross-validation[J].Amer.Statist.Assoc.,1993,88(422):486-494
[3]Yang Yuhong.Comparing learning method for classification[J].Statist.Sinica.,2006,16(2):635-657
[4]Hafidi B,Mkhadri A.Repeated half sampling criterion for model selection[J].The Indian Journal of Statistics,2004,66(3):566-581
[5]Smyth P.Clustering using monte-carlo cross-validation[C].Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining.USA:AAAI Press,1996:126-133
[6]Nason G P.Wavelet shrinkage using cross-validation[J].JRSS,1996,58(2):463-479
[7]Celeux G,Durand JB.Selecting hidden markov model state number with cross-validation likelihood[J].Comput Stat,2008,23(4):541-564
[8]Dietterich T G.Approximate statistical tests for comparing supervised classification learning algorithms[J].Neur.Comp.,1998,10(7):1 895-1 924
[9]Alpaydin E.Combined 5×2CVFtest for comparing supervised classification learing algorithms[J].Neur.Comp.,1999,11(8):1 885-1 892
[10]李济洪,王瑞波,王蔚林,等.汉语框架语义角色的自动标注研究[J].软件学报,2010,30(4):597-611
[11]Nadeau C,Bengio Y.Inference for the generalization error[J].Machine Learning,2003,52(3):39-281
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
中学课程辅导·教师通讯(2020年22期)2020-02-04
中文信息学报(2019年12期)2019-12-30
初中生世界·八年级(2019年6期)2019-08-13
知识经济·中国直销(2018年8期)2018-08-23
锦州医科大学学报(社会科学版)(2018年4期)2018-02-12
数学学习与研究(2017年3期)2017-03-09
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
中国海上油气(2016年1期)2016-06-09
