
基于AdaBoost算法特征提取的人体动作识别方法
2014-01-22 14:04姬晓飞李一波
沈阳航空航天大学学报 2014年2期
姬晓飞,周 路,李一波
(沈阳航空航天大学自动化学院,沈阳110136)
基于视觉的人体运动分析在智能视频监控、高级人机交互、虚拟现实和基于内容的视频检索分析等方面有着广泛的应用前景和潜在的经济价值,已经成为计算机领域中备受关注的研究方向之一[1]。
目前存在多种运动特征表示的方法,如基于人体侧影和轮廓[2]的静态特征表示、基于光流和运动轨迹[3]的动态特征表示、基于时空体数据的时空特征[4-5]表示等等。其中基于时空体数据的时空特征中最常用的是基于时空兴趣点的特征,其对噪声、遮挡等影响具有较强的鲁棒性,对于相机运动和低分辨率的视频输入等更具适应性,因此应用较广。但基于兴趣点的原始特征往往维数过高,影响识别速度。因此大量的研究工作着力于如何在不降低识别率的基础上,合理降低特征维数。文献[5]提出了一种基于兴趣点的静态、动态、时空特征的表示方法。该方法首先提取运动序列的兴趣点特征,并在训练样本特征空间中利用K-means聚类的方法构造时空码本分类器,然后将测试样本的所有兴趣点特征表示为基于时空码本的统计直方图用于分类识别。此类方法证明了基于兴趣点时空特征(3D SIFT)的优越性,利用K-means聚类的方法对原始特征进行聚类,生成码本来降低特征空间的维数,减少识别的复杂度。但聚类初始参数和聚类的维数只能凭经验确定,很难得到一个准确的值,聚类参数的选取对识别结果的影响较大。文献[6]提出利用改进的方法检测时空兴趣点并提取3D SIFT描述子特征,然后在单帧和所有帧之间分别进行主成分分析降维的处理。这种方法成功的解决了大多数兴趣点描述子维数过高的问题,但是用于识别过程的训练样本数量还是相当大的,导致后续的基于最近邻的识别仍要花费大量的时间。文献[7]提出将视频序列分割成许多个子块,同时提取每个子块的3D SIFT特征,然后统计一个视频序列的所有子块特征作为视频序列的原始特征,最后用AdaBoost算法对原始特征进行提取,筛选出少量的对识别最有意义的特征。这种方法通过AdaBoost算法在大量的样本特征中选取有效的样本数据用于识别,能够减少识别过程的计算量,提高了识别的速度。但是该方法在获取原始特征之前需要对视频数据做复杂的预处理,这将大大影响算法的应用。
针对以上存在的问题,本文提出将经过降维处理的基于时空兴趣点3D SIFT描述子特征与AdaBoost算法进行特征提取的方法相结合。先后通过特征降维和特征提取两个层次的特征处理,力图得到一个低维的少量的训练样本空间,在保证较好识别率的基础上,提高识别的速度,达到实时性检测的目的。具体的实现过程,如图1所示。首先,用3D SIFT描述子对检测出的时空兴趣点进行表示,并在横向和纵向上分别对特征数据进行降维处理,初步从减少特征维数的角度减少识别过程的计算量。接下来运用AdaBoost[7]算法对降维后的训练视频序列的特征数据进行进一步提取,提取出关键的训练样本数据,这样很大程度上减少了应用在识别阶段的样本数,进一步提高识别速度。最后,选取了对于少量的训练样本能够达到快速识别的最近邻分类器,将未经过Ada-Boost提取的测试序列样本数据,与提取出的关键训练样本数据做距离,识别出测试样本的类别,结果表明在保证一定识别率的基础上,识别的速度大幅度提高,验证了所提方法的有效性。
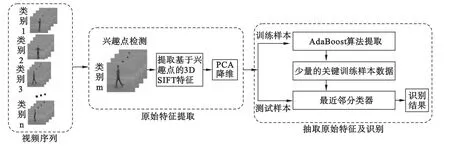
图1 基于AdaBoost算法特征提取的人体动作识别过程
1 原始特征表示
1.1 兴趣点检测及3D SIFT描述子
为了克服Dollar[8]兴趣点检测方法存在的易受人体阴影和背景噪声影响从而检测出伪兴趣点的现象,本文运用改进的兴趣点检测方法[9],使用不同方向的滤波模板获得时间和空间维上的联合滤波响应,检测出更准确的时空兴趣点,并采用文献[6]的方法计算3D SIFT描述子特征表征人体动作的视频序列。
1.2 特征数据的降维
上面得到的数据中,表示每帧图像信息的数据量是很大的,大量的特征数据将会增加识别过程的计算量。本文对得到的3D SIFT描述子特征进行降维处理[6],初步的减少计算复杂度。具体的方法如下:
(1)纵向降维:即单帧图像的降维,将每帧的N×256大小的数据初步降到1×256,将单帧中所有兴趣点的3D SIFT描述子主成分都聚集在一起,构成的单一向量如图2中(a)所示。
(2)横向降维:将视频序列中的每帧图像对应的特征按(1)降维,得到整个视频的特征数据M×256(M为此动作的所有视频帧数)再进行横向的降维处理到M×50,如图2(b)、(c)所示。最终对于每个视频序列采用M×50维的时空特征进行表示。

图2 特征数据的降维过程
2 AdaBoost算法对原始特征提取
上一节中已经将3D SIFT表示的特征数据进行了维数上的减少,这里再利用AdaBoost算法进行关键帧的提取,得到少量的可分性高的低维训练样本数据。
传统的AdaBoost算法[10]作为一种高精度的分类方法,本文将传统的AdaBoost算法[10]加以改进,最终不是实现强分类器的构造,而是在众多的样本中根据每个样本被赋予的权值大小提取出关键的特征数据具体的方法如下:
总的训练样本集:(x1,y1),…(xi,yi),…(xN,yN),yi∈{1,-1};xi为样本数据,yi为样本标记;
(2)迭代过程(循环 t=1,2,…,T):
i.在N个训练样本中,随机选取一部分样本数据作为已知样本,使用最近邻分类器作为弱分类器,将每个训练样本得到一个假设ht(xi)∈{1,-1},并计算样本错误率εt=PDi(ht(xi)≠yi);(第t次循环中,分类错误样本对应的取值PDt)
ii.计算弱分类器的权值:
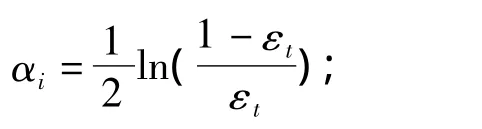
iii.更新训练样本的权值:
(3)选取权值小的特征数据。
由于传统的AdaBoost算法只能处理两类动作识别问题,所以本文中使用1对多的方法,将N个训练样本中要提取的动作类别标记为1,其他所有类别标记为-1,在每次的迭代中,随机选择部分训练样本作为标记样本,使用最近邻分类器作为弱分类器,进而训练样本中的每个特征数据都有一个假设,根据每个样本中特征数据分类的正确率和所有样本的所有特征数据的准确率,更新每个样本特征的权值分布,依照每个样本特征数据拥有权值的大小,选取拥有权值小的特征数据,作为最终的训练样本。重复以上的操作就可以实现多类动作训练样本的提取。
3 分类器设计
本文使用的最近邻分类器在处理小数量的训练样本的情况下,实现简单,且识别速度较快。具体的方法如下:
(2)通过投票的方式,统计每个测试视频序列中占票数最多的类别即为该动作的识别结果。
4 实验验证与结果分析
4.1 数据库介绍
实验过程选取了人体动作识别数据库中应用最广泛的KTH数据库来验证本文所提出方法的有效性。该数据库包括6类行为(walking,jogging,running,boxing,hand waving,hand clapping),分别在四个场景下由25个不同的人执行,一共有599段视频,背景相对静止,除了镜头的拉近拉远,摄像机的运动比较轻微。如图3所示:

图3 KTH数据库中的不同场景下的不同人的视频帧图像
4.2 实验及结果分析
首先,提取数据库中视频的原始特征,即每个视频可以用M×50维的特征进行表示(M为每个视频图像的帧数。然后采用AdaBoost算法对原始特征进行提取,为每个视频序列提取出最易于识别的30帧图像的特征数据(30×50维数据)进行表示。实验过程采用留一法,每次提取一类动作,进行6次提取。依次循环,将每个动作都将作为测试样本进行测试,并统计识别结果。使用最近邻的分类方法进行分类。
表1为原始特征与本文所提特征使用留一法在最近邻分类器下的识别结果比较。
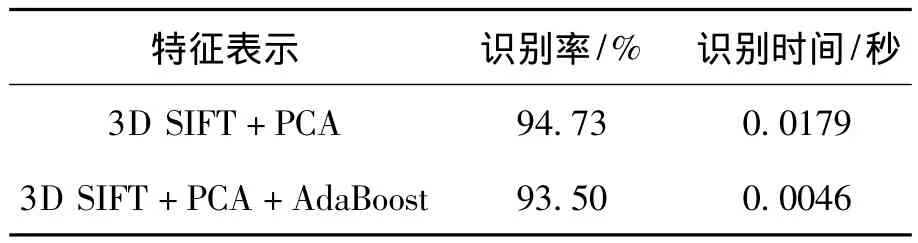
表1 特征提取前后的识别效果比较
从表1中的识别率可以看到,本文方法得到了较高的识别率。使用AdaBoost算法对原始特征进行筛选相比没经过筛选之前的特征识别率有略微的降低,但是每个视频帧图像的识别处理时间却有显著的减少,在内存2 GB和CPU 3.0G Hz的电脑上应用matlab2009b版本测试,处理一帧数据仅仅用了0.004 6 s。经过AdaBoost算法对原始特征进行处理后,训练样本的数量显著减少,相应的测试样本与训练样本比对的时间也缩短,因此大大的提高了识别的速度。
表2是本文方法与近期相关方法基于KTH数据上的识别结果比较,可以看出文献[11-12]都选取了基于兴趣点的描述子特征与其它特征相结合的表示方法,且使用基于词袋和支持向量机结合的方式,识别率均低于本文提出的方法。主要原因是构造词袋过程中的不确定因素影响了识别率。文献[7]同样用AdaBoost算法进行特征提取和采用最近邻方法用于识别,不同之处在于文献[7]提取视频序列的全局3D SIFT特征,没有经过降维处理,最终在原始特征中提取200个易识别的特征,作为最终的特征数据。显然本文的方法拥有的样本数据的个数更少、维数更低,且识别结果优于文献[7]。通过比较可以看出,本文的方法拥有较高的识别率的同时能够达到快速识别,进一步证明本文方法的有效性。

表2 不同方法对应的识别率
5 总结
本文提出了用AdaBoost算法在表征运动信息的大量原始特征数据中提取出有效特征数据的方法,先后使用PCA和AdaBoost算法,分别对视频序列基于兴趣点的3D SIFT特征进行初步的降维及进一步的提取,得到低维数的易于识别的少量训练样本特征数据,从而在保证识别率的同时达到快速识别。实验证明本文的方法在KTH数据库上得到了93.5%的识别率,识别速度达到0.0046秒/帧,充分的证明了该算法的有效性和可行性。目前本文使用的特征单一、并且视频数据库相对简单,接下来的工作是研究合理的特征融合方法,并在现实场景的环境下对算法进行测试。
[1]王亮,胡卫明,谭铁牛.人运动的视觉分析综述[J].计算机学报,2002,25(3):225 -237.
[2]阮涛涛,姚明海,瞿心昱,等.基于视觉的人体运动分析综述[J].计算机系统应用,2011,20(2):245 -254.
[3]郭利,姬晓飞,李平,等.基于混合特征的人体动作识别改进算法[J].计算机应用研究,2013,30(2):601-604.
[4]凌志刚,赵春晖,梁彦,等.基于视觉的人行为理解综述[J].计算机应用研究,2008,25(9):2570-2578.
[5]雷庆,李绍滋.动作识别中局部时空特征的运动表示方法研究[J].计算机工程与应用,2010,46(34):7-10.
[6]姬晓飞,吴倩倩,李一波.改进时空特征的人体异常行为检测方法研究[J].沈阳航空航天大学学报,2013,30(5):42 -46.
[7]Li Liu,Ling Shao,Peter Rockett.Human action recognition based on boosted feature selection and naive bayesnearest-neighbor classification[J].Signal Processing,2013,93(6):1521 -1530.
[8]Dollor P,Rabaud V,Cottrell G,et al.Behavior recognition via sparse spatio-temporal features[C]//Visual and Performance Evaluation of Tracking and Surveillance,2005:65 -72.
[9]Bregonzio M,Gong S,Xiang T.Recognising action as clouds of space- time interest points[C]//Computer Vision and Pattern Recognition,2009:1948 -1955.
[10]宋静.SVM 与 AdaBoost算法的应用研究[D].大连:大连海事大学,2011.
[11]Kishore K.Reddy·Mubarak Shah.Recognizing 50 human action categories of web videos[J].Machine Vision and Applications,2013,24:971 -981
[12]Laptev I,Marszalek M,Schmid C,et al.Learning realistic human actions from movies[J].Computer Vision and Pattern Recognition,2008:1 -8.
猜你喜欢
车主之友(2022年4期)2022-08-27
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
海峡姐妹(2019年12期)2020-01-14
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中国交通信息化(2016年2期)2016-06-06
