
基于语义推理的学习资源推荐
2014-02-09 07:47徐守坤孙德超
计算机工程与设计 2014年4期
徐守坤,孙德超,石 林,李 宁
(常州大学信息科学与工程学院,江苏常州213164)
0 引 言
如今互联网上的学习资源呈爆炸式增长,用户如何去分辨那些与自己相关或不相关的学习资源也变得越来越困难,因此个性化服务[1]越来越多的被人们提起,用户希望借此来获得与自己兴趣偏好相关的资源。传统的个性化推荐方法主要有基于内容过滤[2,3]和协同过滤推荐。前者受到相似性标准的限制,只有与用户偏好有相同属性的内容才会被加入最终的推荐集[4,5];后者的缺陷[8-10]主要有:数据稀疏问题;可测量性问题:资源的增加导致用户权向量规模的扩大,计算用户权向量之间的相关性更费时费力;“潜伏”问题:只有被用户邻居评价的资源,协同过滤方法才会向目标用户产生推荐;如果新的、有用的资源并未存在于用户模型中,则无法完成推荐。鉴于以上两种方法各有优缺点,有人[10-12]提出将基于内容与协同过滤推荐方法结合起来使用,但效果并不是很显著(协同过滤方法虽然能改善最终的推荐结果,但其自身缺陷依然存在)。
本文通过引入本体构建学习资源,从而使各种学习资源存在语义描述。通过对用户偏好进行语义推理取代用户邻居的发现,丰富最终的推荐集,从而克服协同过滤方法的不足。本文的推荐方法主要得益于语义Web的应用,具体有如下3个方面:①通过元数据对资源进行语义描述;②用本体对领域知识概念及其之间关系进行规范表示;③对领域本体进行语义推理,获得已被标注资源之间的语义联系。总得来说,该方法不仅能获得与用户偏好有相同属性的推荐结果,更能提供与用户偏好有语义联系的内容。
1 学习资源本体及用户模型构建
1.1 本体概念
目前,本体公认的定义可以参考文献[13]。本体通过对概念的严格定义和概念之间的关系来确定概念的精确含义,从而解决语义Web存在同一概念有多种词汇表示和同一词汇有多种概念(含义)的问题。本体是解决语义层次上Web信息共享和交换的基础。
1.2 学习资源本体的构建
本文中学习资源的本体构建可以用斯坦福大学开发的Protégé4.1,为了本文后面论述的需要,图1、图2是用Microsoft Visio Office 2007构建的学习资源本体示意图。图1是本文所需的所有类及其实例,本文中学习资源:书籍,被我们定义为某些类(即classes,例如Resource_1、Resource_2等)的具体实例(即instances,例如A1_book、B1_book等)。而图2则是有关实例书籍的属性示意图,本文中假设书籍只有四种不同的对象属性(object properties),分别为hasAuthor、isAbout、hasPublishing House、hasReader,它们分别表示实例书籍与其它类的实例之间的关系,比如书籍A2_book与Job_1类的实例People_a之间通过对象属性hasReader联系在一起。根据图1、图2,我们可以知道,学习书籍C2_book是关于主题Subject_b的,它曾经的学习者有People_c;学习书籍A2_book是作者Author_A2写的,曾经的学习者有People_a。
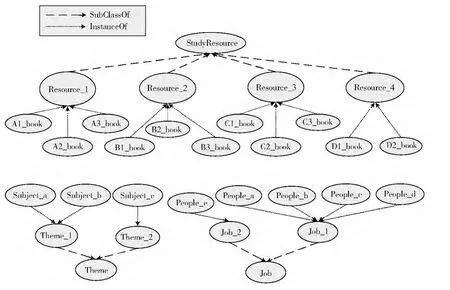
图1 学习资源本体构建
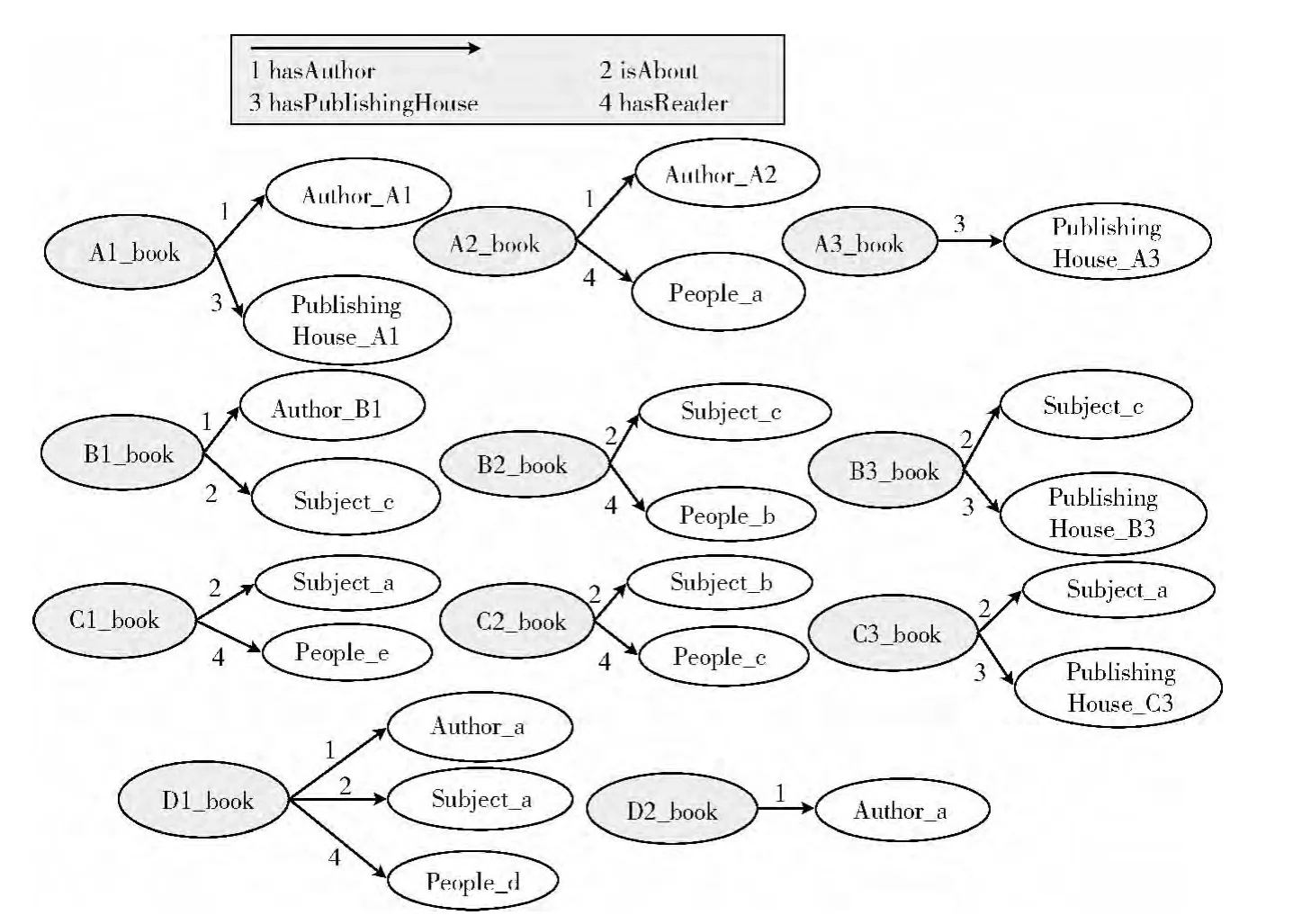
图2 实例属性
图3是根据图1、图2用Protégé4.1生成的本文中所有类、实例及它们属性(object properties)之间的本体关系图(Thing类是Protégé软件自动生成的父类),从图中我们可以更清楚的看出各个类之间的关系。

图3 类、实例及属性关系
1.3 用户模型
文献[14]指出,用户模型的创建对个性化服务有着至关重要的作用。本文中,为了能对用户偏好进行语义推理,每个用户兴趣偏好模型的建立都是基于已经存在的学习资源本体,这样用户模型中的兴趣偏好(本文中指用户喜欢或不喜欢的书籍)才存在语义描述,而这些语义描述则可以帮助我们完成语义推理功能。基于已存在本体资源建立的用户模型主要包括以下3个方面:
(1)用户感兴趣或不感兴趣的内容;
(2)这些内容的属性;
(3)在本体建模示意图中,这些内容属于哪些类别(class);
此外,本文还定义一个兴趣程度(degrees of interest,DOI)指数,规定其值的变化范围从[-1,1],依次代表着用户对该书籍从不喜欢到喜欢的程度。这个指数可以在用户模型初始化时由用户自己设定,也可以根据用户的行为记录自动生成(例如,用户对所推荐书籍的接受或拒绝,或用户对所推荐书籍的浏览时间等)。DOI指数的设定在某种程度上可以帮助我们初始化下文提及到的结点活跃水平(activation level),结点的DOI指数越大,则其活跃水平也越大,反之亦然。
当然,DOI指数也可以通过以下公式进行计算,假设类Ψ有N个子类Ψ1,…,ΨN:
文献[9]给出了每个子类Ψi对其父类Ψ影响的计算公式,如式(1)所示,从式(1)中我们可以发现,领域本体中,子类Ψi的兄弟类越少、DOI(Ψi)越大,则其对父类Ψ的影响越大
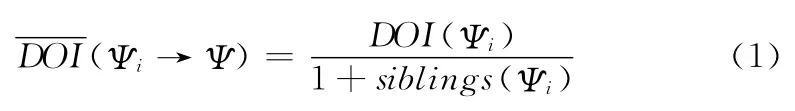
然后将所有子类Ψi的DOI值用以计算DOI(Ψ),结合式(1),该值即是所有子类DOI指数累加的平均值,如下所示

由于用户模型中的书籍及其相关属性在学习资源本体中已被定义,那么在领域本体中,就可以对与用户偏好相关的书籍进行语义推理,从而得到更多与用户兴趣偏好相关的内容,使个性化推荐的结果在传统推荐方法的基础上具有更多的选择。
2 语义推理
2.1 语义联系
语义联系描述的是领域本体中实例之间的关系,为了能对这些联系进行分类,可以借助一个称之为PS(property sequence)[4]的结构图,该结构图中通过各种属性将不同类的实例联系在一起。PS中第一个实例称之为原始结点(origin),最后一个实例称之为最终结点(terminus),PS中属性的个数决定了其长度,具体如图4所示。
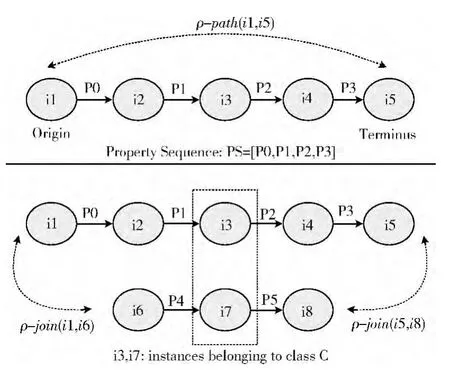
图4 语义推理中的语义联系
ρ-path联系:如果能找到一个PS,它的原始结点是i1,最终结点是i5,则称实例i1和i5是具有ρ-path联系的。显然,两个实例之间的PS越长,即它们之间的中间结点越多,则其之间的联系越不紧密。
ρ-join联系:如果两个实例是两个PS的原始结点(例如i1,i6)或者最终结点(例如i5,i8),并且这两个PS中存在属于同一类的实例(例如i3,i7),则这两个实例之间联系就被称为ρ-join。
接下来我们需要做的如下:
首先,在学习资源领域本体中寻找与用户偏好有语义联系的相关内容。具体标准设定如下(由于本文学习资源本体的局限,存在语义联系的PS长度都未超过2。实际应用中,PS的长度远不止2):
(1)两种书籍是同一个类的实例,这是最简单的语义联系(例如,图1中书籍A3_book与A2_book都是Re-source_1类的实例);
(2)领域本体中的两种书籍由一条属性(attribute)链相连,即ρ-path语义联系(如,图1中书籍C3_book和D1_book通过属性Subject_a相连);
(3)两种书籍的某些属性(attribute)属于同一类的实例,即ρ-join语义联系(例如,图1中C3_book的属性Subject_a与C2_book的属性Subject_b都属于Theme_1类的实例);
通过语义联系,即可把与用户偏好相关的所有内容表示成一张网状图,结点即代表各种书籍以及书籍的属性(attribute)实例,而书籍的对象属性则用连线表示,这样就可以将所有有语义联系的书籍表示出来。
2.2 Spreading Activation(SA)技术
SA技术[15]主要用来发现网状图中存在内在联系的结点。其工作机制如下:
(1)首先给最初选定的结点初始化其活跃水平(activation level),用以确定其在网状图中的相关性。除此之外,结点之间的联系还有一个权重值,两个结点之间关系越紧密,权重值相应越大。最初,一些结点被选中,这些结点因其活跃水平找到与其有内在关联的邻居结点。
(2)被“找到”结点的活跃水平(图5中结点R的活跃水平AR)由它的邻居结点(N1,N2,N3和N4)的活跃水平以及它与邻居结点之间的权重值计算所得,具体如公式(3)所示。对于某个结点,如果其邻居结点在网状图中相关性越大(即活跃水平越高),并且它与邻居结点的关系越紧密(即它们之间联系的权重值越大),则该结点在网络中的相关性越大。
(3)结点扩展过程一直持续至遍历完网状图中的所有结点。例如,在图5中,结点R因其活跃水平找到其邻居结点A、B、C。最终,活跃水平最高的那些结点即是与最初选定结点关联性最大的结点

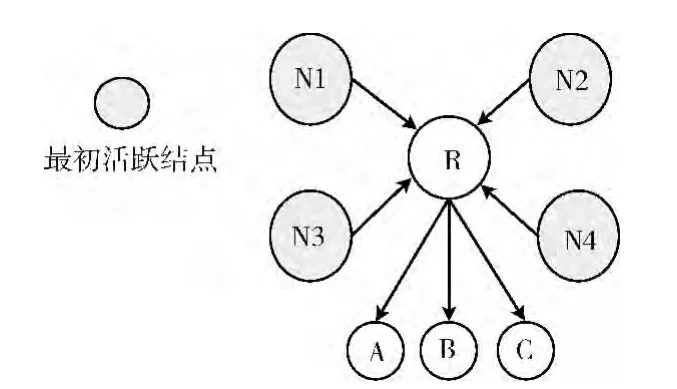
图5 网状图中结点扩展过程
从以上过程可以看出,扩展过程最终可以发现最初没有被选中的结点,即SA技术可以发现更多满足用户需要的资源。为了能够进一步加强推理能力,还可以利用神经网中的Hopfield Net算法帮助我们进行扩展过程,具体可参考文献[18]。由最初结点的活跃水平扩展邻居结点直至遍历完网状图中的所有结点,最后具有较高活跃水平的结点(对应被推荐的书籍)会被作为最终结果推荐给用户。
3 实例模型
这里,本文采用的学习资源本体模型如图1所示(该学习资源本体模型仅适合本文的理论说明需要),用户偏好模型如表1所示。这张表包括了用户喜欢与不喜欢的书籍、该书籍的DOI指数以及它们在领域本体中所属的类,这就符合了第二部分对用户模型的论述。

表1 用户偏好模型
根据表1的用户偏好模型,结合图1中的学习资源本体模型,传统的推荐方法向用户U推荐的结果只有D2_book和C1_book,因为它们和用户模型中的用户偏好D1_book、C3_book有相同的属性(属性Author_a将书籍D2_book和D1_book联系起来,属性Subject_a将书籍C1_book和C3_book联系起来)。
为了能改善这种推荐,发现更多与用户需要有“潜在”联系的内容。本文借助于本体、语义网等相关技术,对用户的兴趣偏好进行语义推理,争取获得更多与用户偏好相关的推荐结果。
3.1 选择与用户偏好相关的实例
(1)根据上文语义联系标准,实例Subject_a、Author_a、Subject_c将被选中。它们与用户偏好都有直接的联系,具体参见实例属性示意图2。
(2)实例Subject_b同样与用户偏好是有联系的。因为它与用户偏好C3_book的属性实例
Subject_a都是主题Theme_1类的实例。
(3)结合图1、2,因为用户偏好D1_book属性实例People_d的存在,实例People_a、People_b、People_c也会出现在图6中。
通过以上论述,本文为用户选择的内容可形成如下结点图。
3.2 推断语义联系
结合图1的学习资源本体图,推理与用户偏好有语义联系书籍的过程如下:
首先,C2_book与用户的兴趣偏好存在语义联系。一方面,C2_book与C3_book都是Resource_3类的实例,这符合语义联系的第一条标准;另一方面,我们还可以发现C2_book与C3_book、D1_book之间都存在ρ-join联系(C2_book的属性Subject_b、People_c与C3_book的属性Subject_c、D1_book的属性People_d分别是Theme_1类、Job_1类的实例,这符合语义联系的第三条标准)。

图6 与用户偏好相关的结点

图7 与用户偏好相关的网状
其次,Job_1类的存在使得书籍A2_book与D1_book之间存在ρ-join联系(通过Job_1类的实例People_a,People_d);此外,根据学习资源本体图1,A2_book与用户偏好A1_book、A3_book都是类Resource_1的实例,这是语义联系的第一条标准。
最后,与用户不喜欢书籍有语义联系的内容也会被发现。在用户模型中,用户不喜欢书籍B1_book的DOI指数为-0.9,B3_book的DOI指数为-1。因为:语义联系第一条标准,书籍B2_book与B1_book、B3_book都是Resource_2类的实例;属性实例Subject_c的存在使得书籍B2_book与B1_book、B3_book之间存在ρ-path联系,根据语义联系第二条标准;这说明书籍B2_book应该不会被用户喜欢。然而,Job_1类使得书籍B2_book与用户喜欢的书籍D1_book之间存在ρ-join的语义联系(书籍B2_book、D1_book的属性实例people_b、people_d分别是Job_1类的实例)。这种情况下,SA技术必须对这种“模棱两可”的关系进行抉择,确定B2_book最终是否推荐给用户。为了能实现这个目的,我们需要构建所有与用户偏好有语义联系内容的网状图,如图7所示。
3.3 推理阶段:通过SA进行语义推理
如图7所示,网状图7中包括了所有与用户偏好相关的结点,接下来就要运用SA技术找出与用户偏好相关、活跃水平最大的结点作为推荐结果。
首先,在用户模型中,用户偏好C3_book、D1_book的DOI指数分别为1和0.9,这说明了它们的初始化活跃水平相应也比较大;而通过图7可以知道,书籍C2_book与C3_book、D1_book之间的联系比较紧密(即权重值较大)。那么根据结点活跃水平计算式(3),可知C2_book在网状图中的活跃水平很高。
同理我们可以得出书籍A2_book也会作为一个推荐结果呈现给用户。结合图7,与A2_book存在语义联系的3种书籍分别是A1_book(DOI指数为0.85)、A3_book(DOI指数为0.8)和D1_book(DOI指数为0.9),这3种书籍的初始活跃水平都比较大;通过图7,我们可知A2_book与它们之间的权重值也比较大。因此,根据式(3),A2_book在网状图中活跃水平也很高。
最后是对书籍B2_book的选择。根据本文第3阶段论述,书籍B2_book与用户偏好D1_book(DOI指数为0.9)之间存在ρ-join的语义联系。如网状图7所示,结点B2_book的邻居结点除了结点D1_book外,还有结点B1_book、B3_book。而用户偏好B1_book、B3_book在表1中的DOI指数分别是-0.9,-1,这说明了结点B1_book、B3_book在网状图中活跃水平很低,也可以认为它们的存在会降低其邻居结点B2_book的活跃水平。这里我们参考Hopfield Net算法,为系统中SA技术的运用设定一个阈值,当对某个结点计算所得的活跃水平低于该值时,则该结点不作为推荐结果,同时该结点在网状图没有能力扩展其邻居结点,从而保证推荐的效率。系统设定阈值后,书籍B2_book自然就被排除在最终的推荐集之外。
从以上过程可以看出,本文中的推荐策略在学习资源个性化推荐方面主要有2个优势:
(1)由于语义联系、SA技术在语义推理过程中的使用,本文的推荐方法能够发现与用户偏好有“隐藏”语义联系的内容C2_book和A2_book。因此,在传统推荐方法(推荐结果仅为D2_book和C1_book)的基础上增加了更多与用户需求相关的内容。
(2)推荐策略中的语义推理过程既考虑到用户感兴趣的内容,这些内容可以帮助我们发现用户的潜在兴趣;又考虑到了用户不感兴趣的内容,这些内容可以帮助我们剔除与之相关的邻居结点,从而保证推荐的质量。例如将B2_book排除在最终的推荐结果之外。
4 结束语
传统基于内容的推荐系统由于匹配标准的限制,只有和用户偏好有极大相似性的内容才会被加入推荐集呈现给用户,为了克服这一限制,同时避免出现协同过滤方法中的数据稀疏、冷启动等问题。本文结合领域本体,利用语义推理去发现与用户偏好有隐藏联系的内容。为了能发现与用户偏好有语义联系的学习资源,语义推理过程中结合了语义联系、SA技术的应用:语义联系帮助发现与用户偏好有隐藏语义联系的内容,从而丰富最终的推荐结果集;SA技术一方面用于发现邻居结点,另一方面可以根据用户偏好的变化更新推荐结果,增强系统的适应性。最后本文中的方法还从用户的角度保证了推荐的质量。当然本文中还存在不足之处,如一个具有更多语义联系学习资源本体的构建以及最初选定结点活跃水平的初始化等问题都是我们以后研究的方向。
[1]LI Chun,ZHU Zhenmin,YE Jian,et al.Survey on research in personalization service[J].Application Research of Computers,2009,26(11):4001-4005(in Chinese).[李春,朱珍民,叶剑,等.个性化服务研究综述[J].计算机应用研究,2009,26(11):4001-4005.]
[2]XIE Fuding,AN Na,HUANG Dan,et al.Trust model based on content similarity and recommendation feedback[J].Computer Science,2009,36(4):215-217(in Chinese).[谢福鼎,安娜,黄丹,等.一种基于内容相似度和推荐反馈的信任模[J].计算机科学,2009,36(4):215-217.]
[3]Zenebe A,Norcio A.Representation,similarity measures and aggregation methods using fuzzy sets for content-based recommender systems[J].Fuzzy Sets and Systems,2009,160(1):76-94.
[4]Yolanda Blanco-Fernández,Martín López-Nores,Alberto Gil-Solla,et al.Exploring synergies between content-based filtering and spreading activation techniques in knowledge-based recommender systems[J].Information Sciences,2011,181(21):4823-4846.
[5]ZHENG Hua,PENG Xin.Personalized information recommendation system for third party E-commerce[J].Computer Engineering and Design,2009,30(12):2981-2984(in Chinese).[郑华,彭欣.第三方电子商务的个性化信息推荐系统[J].计算机工程与设计,2009,30(12):2981-2984.]
[6]HUANG Guoyan,LI Youchao,GAO Jianpei,et al.Collaborative filtering recommendation algorithm based on user clustering of item attributes[J].Computer Engineering and Design,2010,31(5):1038-1041(in Chinese).[黄国言,李有超,高建培,等.基于项目属性的用户聚类协同过滤推荐算法[J].计算机工程与设计,2010,31(5):1038-1041.]
[7]HUANG ChuangGuang,YIN Jian,WANG Jing,et al.Uncertain neighbors’collaborative filtering recommendation algorithm[J].Chinese Journal of computer,2010,33(8):1369-1374(in Chinese).[黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1374.]
[8]WU Yueping,ZHENG Jianguo.Improved collaborative filtering recommendation algorithm[J].Computer Engineering and Design,2011,32(9):3019-3021(in Chinese).[吴月萍,郑建国.协同过滤推荐算法[J].计算机工程与设计,2011,32(9):3019-3021.]
[9]Yolanda Blanco-Fernández,JoséJ Pazos-Arias,Alberto Gil-Solla.Exploiting synergies between semantic reasoning and personalization strategies in intelligent recommender systems:A case study[J].Journal of Systems and Software,2008,81(12):2371-2385.
[10]YU Hong,MENG Lingmin.Collaborative filtering recommenda
tion method considering asymmetry of items’dependence level[J].Computer Engineering and Design,2013,34(1):299-302(in Chinese).[于洪,孟令民.考虑项目依赖不对称性的协同过滤推荐方法[J].计算机工程与设计,2013,34(1):299-302.]
[11]LI Zhongjun,ZHOU Qihai,SHUAI Qinghong.Recommender system model based on isomorphic integrated to content-based and collaborative filtering[J].Computer Science,2009,36(12):142-144(in Chinese).[李忠俊,周启海,帅青红.一种基于内容和协同过滤同构化整合的推荐系统模型[J].计算机科学,2009,36(12):142-144.]
[12]Salter J,Antonopoulos N.CinemaScrean recommender agent:Combining collaborative and content-based filtering[J].IEEE Intelligent System,2006,21(1):35-41.
[13]DU Xiaoyong,LI Man,WANG Shan.A survey on ontology learning research[J].Journal of Software,2006,17(9):1837-1847(in Chinese).[杜小勇,李曼,王珊.本体学习研究综述[J].软件学报,2006,17(9):1837-1847.]
[14]CHEN Yuan,GOU Guanglei.Study on user model of personalized service[J].Computer Engineering and Design,2008,29(9):2413-2416(in Chinese).[陈媛,苟光磊.个性化服务用户模型的研究[J].计算机工程与设计,2008,29(9):2413-2416.]
[15]Katifori A,Vassilakis C,Dix A.Ontologies and the brain:Using spreading activation through ontologies to support personal interaction[J].Cognitive System Research,2010,11(1):25-41.
[16]Ue-Pyng Wen,Kuen-Ming Lan,Hsu-Shih Shih.A review of Hopfield neural networks for solving mathematical programming problems[J].European Journal of Operational Research,2009,198(3):675-687.
猜你喜欢
齐鲁艺苑(2022年1期)2022-04-19
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
哈哈画报(2021年10期)2021-02-28
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
