
统计机器翻译删词问题研究
2014-02-27 06:33何燕龙朱靖波
中文信息学报 2014年5期
李 强,何燕龙,栾 爽,肖 桐,4,朱靖波,4
(1. 东北大学 信息科学与工程学院,自然语言处理实验室,辽宁 沈阳 110819;2. 中国民族语文翻译中心,北京 100080;3. 辽宁大学 外国语学院,辽宁 沈阳 110036;4. 杭州雅拓网络技术有限公司,浙江 杭州 310012)
1 简介
基于短语的统计机器翻译模型(Phrase-based SMT)广泛地应用于当今真实的翻译任务中[1-2]。基于短语的统计机器翻译模型具有翻译模型原理简单、翻译性能优异等诸多特点,受到研究与应用人员的广泛青睐。短语翻译系统使用短语对作为翻译的基本单元。在短语对生成的过程中,传统短语对抽取算法抽取所有与词对齐保持一致的短语对[3]。在真实的自动词对齐结果中,由于双语语种间句子结构的不同以及词对齐的错误,很多源语言句子中的词汇在目标语言句子中并没有与之相对应词对齐结果,本文将这种源语言词汇定义为对空词汇。在双语训练数据中,由于对空词汇的存在,源语言的一个短语可能会有多个目标语言短语与之保持一致,反之亦然。由于词对齐的错误,一些源语言词汇被错误的对应到目标语言某个词汇上。在翻译过程中一旦选择这一错误翻译,从人工评价角度来看源语言词汇未被翻译,本文将这种源语言词汇定义为错译词汇。由对空词汇或错译词汇造成的源语言中某个词汇未被翻译的现象,本文定义为删词错误问题。
在人工对机器翻译结果评价的过程中,删词错误现象会严重影响评价人员对机器翻译结果的理解,与此同时,删词错误会严重影响句子的流畅度,对机器翻译结果的可用性造成非常大的影响。例如,当翻译“等待他搜集情报。”这一句子时,如果机器翻译系统给出“wait for it.”这样的翻译结果,而“搜集”与“情报”这两个源语言关键词汇没有进行翻译,那么用户将无法理解原文的意思。在现有的统计机器翻译架构上,为了快速完成翻译系统参数的优化,研究人员使用自动评价的方式对系统翻译性能进行评价,而这些自动评价指标没有特殊考虑删词错误问题。删词问题的研究需要使用人工评价方式对源语言句子中未被翻译的关键词汇进行判断,需要大量的人工操作,实验的可重复性较低。因此,在当前广泛应用、性能优异的统计机器翻译系统中,删词问题没有得到充分的分析与研究。Vilar等人证实在汉英翻译任务上,删词错误在所有翻译错误类型中占有近30%的比例,但目前鲜有工作对这一问题提出较优的解决方法[4]。
本文针对删词错误问题进行了深入研究,从人工评价的角度上将删词错误类型分成3类,即词汇翻译内容选取错误、边缘对空关键词汇翻空以及中间对空关键词汇翻空。在此基础上,设计了一种简单有效的方法对较为严重的删词错误类型进行求解。首先,给定一个源语言句子,本文将句子中出现的词汇分成两类,即: 关键词汇与非关键词汇。在这里,本文定义表达句子主要信息、不能译空的词汇为关键词汇,其他词汇为非关键词汇。本文提出了两种方法进行关键词汇的自动识别,即基于频次的方法与基于词性标注的方法。继而本文提出了一种受限的短语对抽取算法,即在短语对抽取的过程中,对边缘对空的关键词汇加以限制,以达到缓解删词错误的目的。最终,本文方法生成含有较少删词错误信息的短语翻译表。本文将提出的方法应用到当前性能优异的基于短语的统计机器翻译系统中,人工评价和自动评价证实,在汉英翻译任务和英汉翻译任务中,与基线系统相比本文提出的方法在翻译性能上有显著的提高。与此同时,翻译系统得到一个精简的短语翻译表。
2 本文方法
首先,本文通过对传统的短语对抽取方法的分析来阐述删词错误问题。对于给定的一个句对,图1中“传统”一列显示了传统的短语对抽取方法可能抽取噪声短语对的一个示例。在图1中,源语言词汇“孩子”在词对齐中没有与之对应的目标语词汇,即该词为对空词汇。对于传统的短语对抽取算法来说,源语言短语“属于 孩子”有多个与之保持一致的目标语短语。在这些短语对中,包含噪声短语对(属于 孩子 ,belongsto),即“孩子”在对应的目标语短语中并没有翻译结果。在机器翻译系统解码过程中,一旦选择了这一错误短语对,删词错误便隐含其中。

图1 传统短语对抽取方法与本文短语对抽取方法抽取的示例短语对
在短语对抽取的过程中,如果考虑关于源语言句子中词汇更多相关的统计信息或语言学信息,上述问题可以得到缓解。表1中显示图1所示句对中示例词汇在整个训练语料中的对空占比及对应词性情况。从 表1中 可 以 看 出,“孩 子” 的 对 空 占 比 为14.45%,也就是说,在绝大多数情况下,“孩子”被确定的翻译为目标语言中的某个词汇。与此同时,“孩子”的词性为名词,在一个好的翻译结果中,名词基本不可以被翻译为空。通过对表1的观察,“孩子”可以被定义为表达源语言句子信息的关键词汇。通过对源语言关键词汇进行识别后,可以在短语对抽取过程中对关键词汇加以约束来缓解删词错误问题。

表1 示例词汇对空占比与词性统计
2.1 删词错误分类
本文的主要内容是对删词问题进行分析与研究。通过使用人工评价的方式对真实机器翻译结果删词错误现象进行分析,本文将删词错误类型分为以下3类。
1) 词汇翻译内容选取错误。在这种错误类型中,源语言句子中词汇在目标语中有对应的翻译结果,但该翻译结果并不是当前词汇的正确翻译。该错误由自动词对齐错误造成,传统短语对抽取的过程回避了这一错误,导致错误蔓延。从人工对翻译结果进行评价的角度来看,源语言词汇没有被翻译。
2) 边缘对空关键词汇翻空。在短语对抽取的过程中,一个与词对齐保持一致的短语对的源语言短语的边缘存在对空词汇,而该词汇为表达源语言句子句义信息的关键词汇,该词汇没有进行翻译,造成错误的删词现象。
3) 中间对空关键词汇翻空。在短语对抽取的过程中,一个与词对齐保持一致的短语对的源语言短语的中间某个词汇对空,从该词汇向两边扩展存在含有词对齐信息的词汇,同时该词汇为关键词汇,该词汇没有进行翻译。
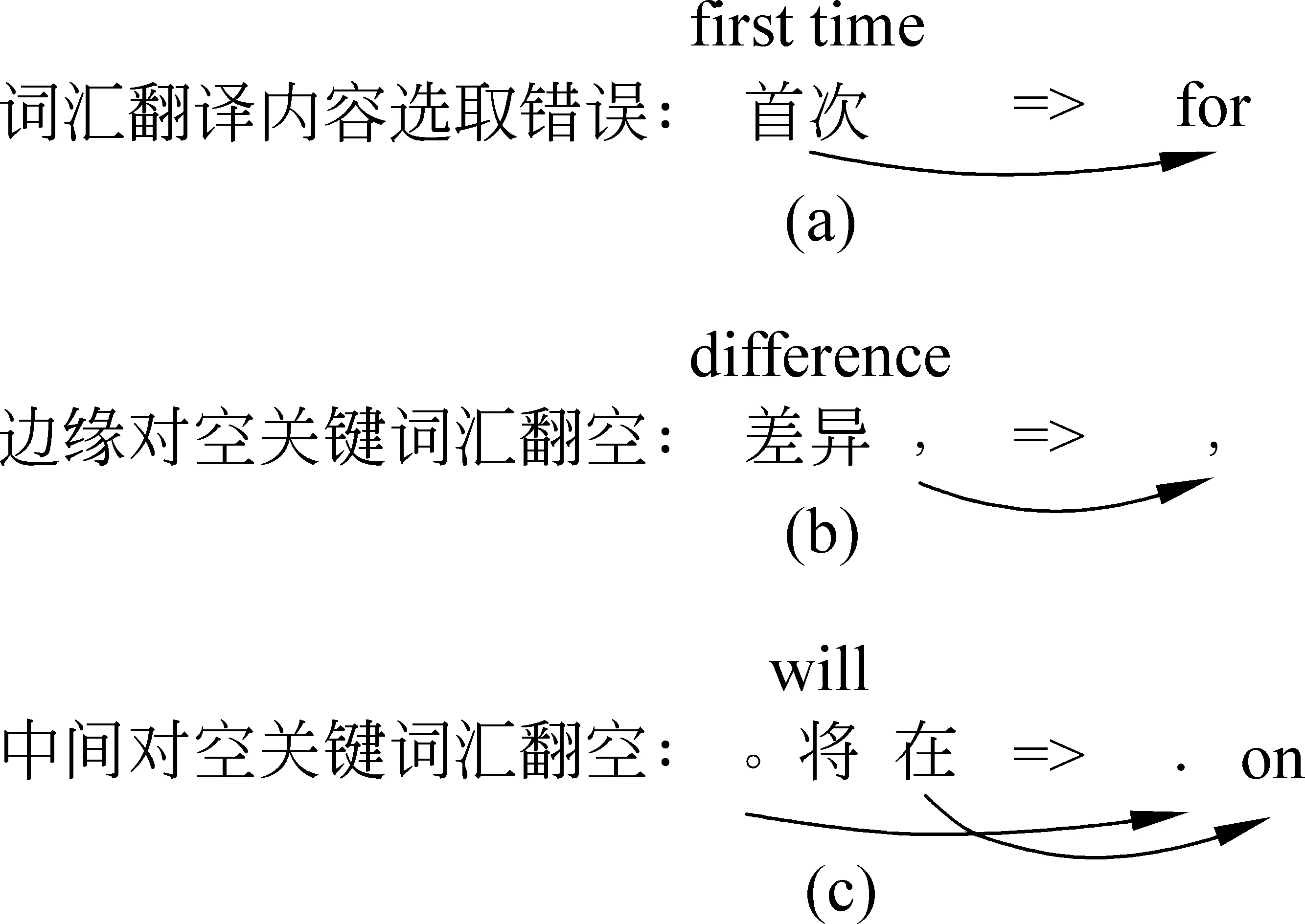
图2 3种删词错误类型实际情况
图2为3种删词错误类型的真实情况。在图2(a)中,源语言短语中词汇“首次”被错误的翻译为“for”,该问题由于自动词对齐的错误造成;在图2(b)中,源语言短语中词汇“差异”为短语“差异 ,”的边缘对空关键词汇,在目标语中没有与之对应的翻译结果;在图2(c)中,源语言短语中关键词汇“将”对空,同时该词汇两边的词汇在目标语中有对应翻译结果,词汇“将”没有对应翻译结果。
表2中显示上文所列3种删词错误类型的错误分布情况。从表2中可以看出,在3种错误类型中,词汇翻译内容选取错误与边缘对空关键词汇翻空错误总数占所有错误类型的98%以上。然而,词汇翻译内容选取错误涉及到整个翻译框架中的“择词”问题,该问题较为复杂,非传统删词问题,本文不对这种错误类型进行讨论。本文主要对图2(b)情况进行分析与讨论,继而提出合理的缓解该类删词错误的解决方案。图3中内容为机器翻译系统输出的真实的删词错误示例。在图3中,对于源语言短语“搜集 情报 .”,翻译系统为其提供错误的翻译结果“.”,而在使用的短语对(搜集 情报 . ,.)中,“搜集”和“情报”两个词汇并没有词对齐,即边缘对空词汇“搜集”与“情报”翻空造成了该类删词错误。
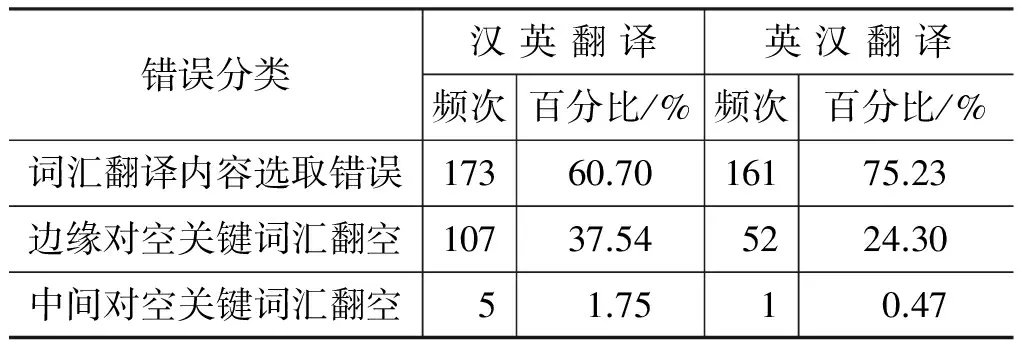
表2 三种删词错误类型错误分布统计
注: 错误统计数据来源于随机选取的200行训练数据
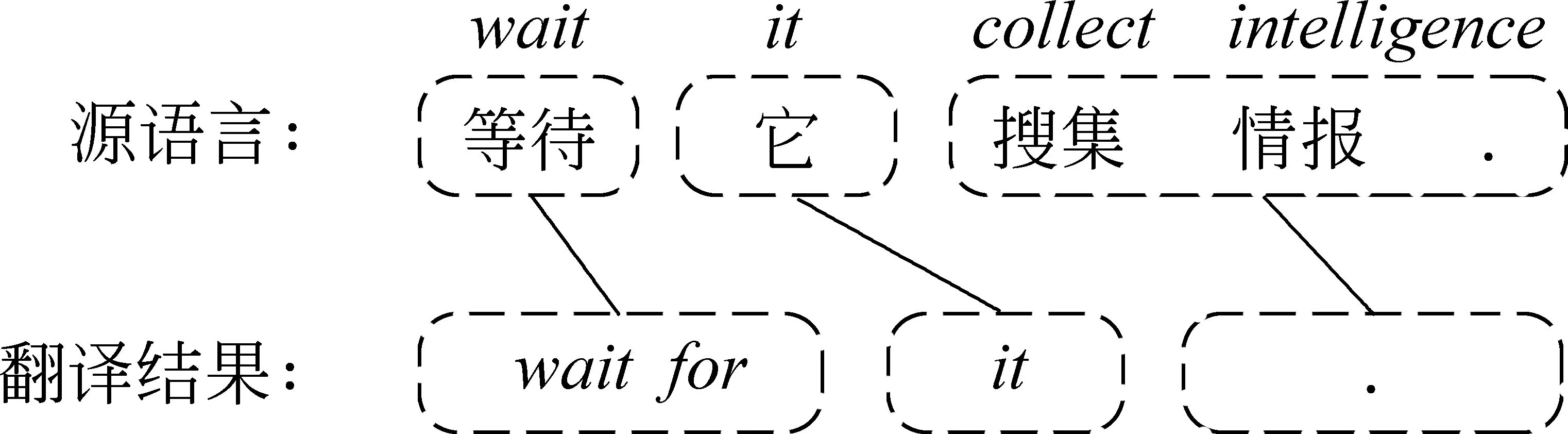
图3 删词错误示例
2.2 关键词汇与非关键词汇
对于表达待翻译文本关键信息、不能译空的词汇,本文称之为“关键词汇”,其他词汇则为“非关键词汇”。本文通过两种方法对关键词汇和非关键词汇进行识别。
第一种方法为基于频次的关键词汇识别方法。受到Li等人相关工作的启发,本文使用源语言词汇的对空占比作为指标来定义关键词汇[5]。给定一个源语言词汇w,该词汇的对空占比定义如式(1)所示。
(1)
在式(1)中,count(wunalign)表示在双语训练数据中源语言词汇w被对空的次数,count(w)表示源语言词汇在源语言数据中出现的次数。如果源语言词汇w为关键词汇,那么对空占比Pr(wunalign)应当小于等于阈值τ。相对频率大于阈值τ的源语言词汇被定义为非关键词汇。表1中对一些示例词汇的对空占比进行统计。从表1中可以看出,对于关键词汇与非关键词汇的识别,Pr(wunalign)是一个非常有效的指标。例如,中文词汇“就”与英文词汇“to”的对空占比很高(>35%),这两个词汇应该被定义为非关键词汇。在本文工作中,τ值默认设置为0.2。
第二种方法为基于词性标注的方法。表3为对不同词性删词错误进行人工评价的统计情况。从表3中可以看出,在训练数据中,名词和动词删除错误所占比例超过80%。因此,本文定义源语言词性为名词或动词的词汇为关键词汇,其他词汇为非关键词汇:

表3 不同词性删词错误统计
注: 统计数据来源于训练数据中随机抽取的100个句子
在这里,KEY表示关键词汇,USUAL表示非关键词汇。
2.3 受限的短语对抽取方法
上文方法可以对源语言句子中关键词汇与非关键词汇进行识别,在本节中,通过使用源语言非关键词汇列表对短语对的抽取过程加以限制,本文提出一种受限的短语对抽取算法,算法详细内容见图4。算法内容解释如下: 给定双语平行句对的词对齐以及源语言的非关键词汇列表SUEL,该方法抽取所有与词对齐保持一致的短语对(图4中行4),同时确保短语对中源语言短语边缘对空词汇在非关键词列表SUEL中(图4中行5)。图1中“本文”一列显示本文提出的方法抽取的示例短语对集合。如前文所述,(属于 孩子,belongsto)是与词对齐保持一致的短语对,但该短语对隐含删词错误。在使用受限的短语对抽取算法时,由于边缘对空词汇“孩子”没有在本文定义的非关键词汇列表SUEL中,该短语对不会被抽取。该算法的主要目的是在抽取与词对齐保持一致的短语对的过程中,过滤掉可能隐含删词错误的短语对,从而缓解翻译过程中的删词错误问题。

图4 受限的短语对抽取算法
3 评价
本文使用NiuTrans开源统计机器翻译系统中基于短语的统计机器翻译模型构建实验平台,方法的有效性在汉英翻译任务与英汉翻译任务上同时进行验证[6]。
3.1 实验设置
在汉英翻译任务与英汉翻译任务的实验中,使用NIST MT 2008机器翻译评测提供的4.46M双语平行句对进行翻译模型的训练。使用GIZA++工具对双语训练数据进行双向词对齐,使用grow-diag-final-and启发式算法对双向词对齐结果进行对称化处理[7]。此外,两个翻译任务的实验中分别使用使用GIGAWORD中英语、汉语的Xinhua部分和双语数据的英语、汉语部分训练5元语言模型。使用最小错误率训练(MERT)方法对统计机器翻译模型的系统参数进行优化[8]。关于开发集和测试集,汉英翻译任务使用NIST 2006 Newswire的测试集作为翻译系统权重调优的开发集(1 181句),将NIST 2004,2005和2008 Newswire的测试集进行合并,作为评价实验系统翻译性能的测试集(3 561句)。对于英汉翻译任务,使用SSMT2007测试集作为翻译系统参数优化的开发集(995句),使用NIST 2008测试集作为评价机器翻译系统翻译性能的测试集(1 859句)。关于使用数据更多的信息详见表4与表5。翻译性能通过使用大小写不敏感(case-insensitive)的IBM版本的BLEU以及翻译错误率(TER)评价指标进行评价[9-10]。
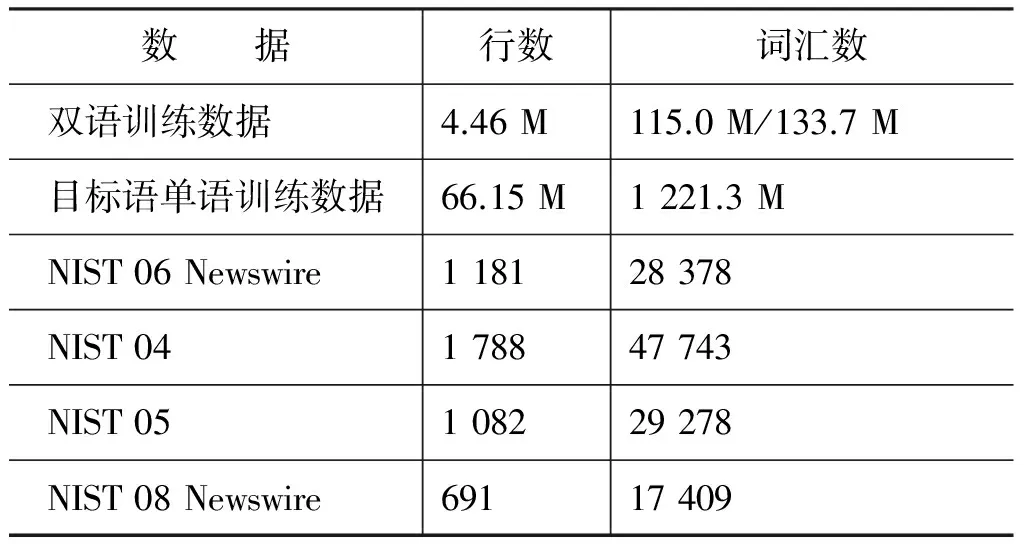
表4 汉英翻译任务使用数据
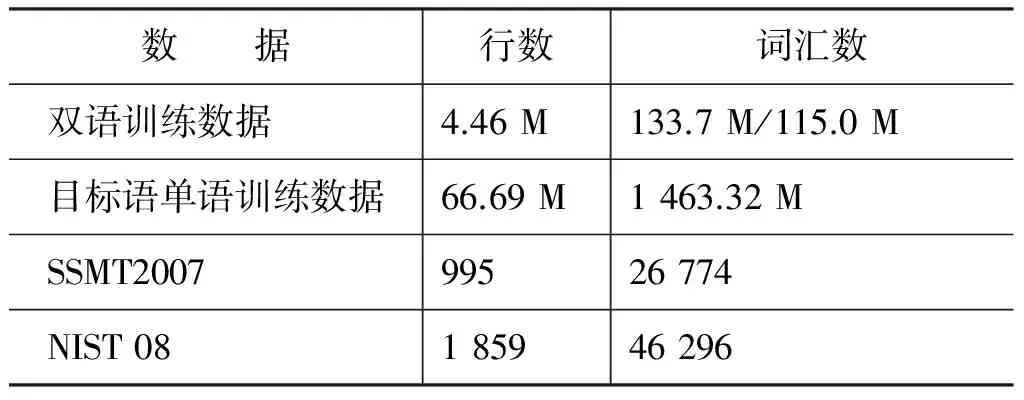
表5 英汉翻译任务使用数据
3.2 实验结果
表6和表7分别为汉英翻译任务与英汉翻译任务中,基线翻译系统与使用本文方法的翻译系统在开发集与测试集上的BLEU值和TER值。由于TER指标较好的体现了删词错误现象的严重程度,所以,本实验的主要目的是保证BLEU值在不发生较大波动的情况下,翻译结果在TER指标上的性能取得明显的改善。在表6和表7中,“*”表示在p<0.05的情况下,显著优于基线系统的实验结果。

表6 汉英翻译任务中,短语翻译表大小、BLEU4值以及TER值
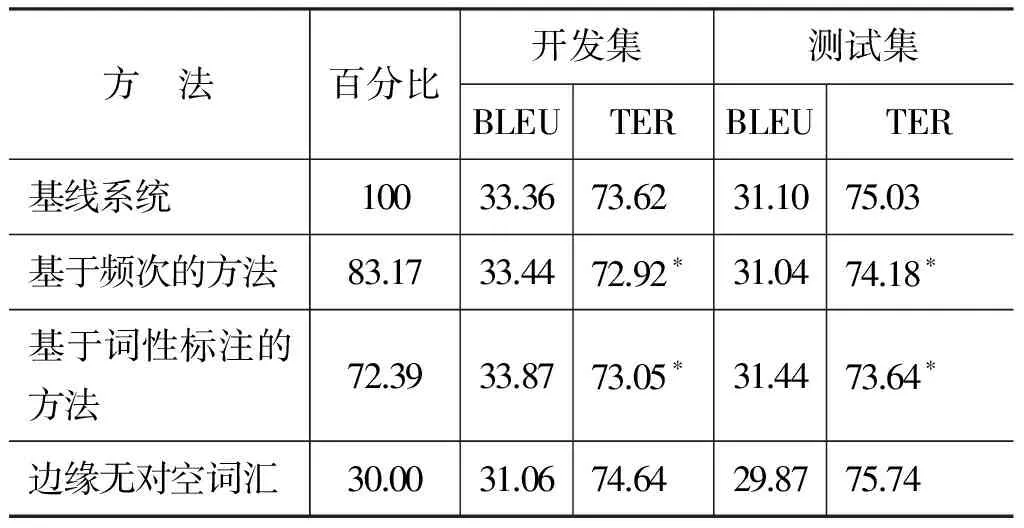
表7 英汉翻译任务中,短语翻译表大小、基于字的BLEU5值以及TER值
在表6中,本文提出的基于频次的方法在测试集上得到与基线系统可比的BLEU值;与此同时,在TER评价指标上,本文方法在测试集上翻译结果质量获得显著的改善,即取得1.21个TER点的下降(TER值越低,错误率越低,翻译性能越好)。更有趣的是,与基线翻译系统的短语翻译表相比,基于频次的方法可以有效的减小短语翻译表的大小,即短语翻译表的大小下降了26.31%。表6中“边缘无对空词汇”行实验结果表明,有效的处理好边缘对空词汇是统计机器翻译系统成功的关键之一。如果在短语对抽取的过程中,与词对齐保持一致的短语对的源语言和目标语言的边缘词汇不允许对空,虽然短语翻译表的大小可大幅度减小71.04%,但是在测试集上的翻译性能下降了3.19个BLEU点。该实验结果表明,允许源语言句子中某些词汇翻空对于构造好的机器翻译结果来说非常必要。除此之外,表6中同样给出基于词性标注方法的实验性能。基于词性标注的方法与基线系统相比,短语翻译表的大小下降了30.01%,同时翻译结果在TER指标上获得0.59个点的降低。
在英汉翻译任务上,实验结果与汉英翻译任务类似,具体实验结果见表7。在表7中,基于频次的方法使用的短语翻译表的大小相比基线翻译系统减小16.83%,与此同时,在TER指标上获得0.85个点的降低。基于词性标注的方法使用的短语翻译表的大小减小27.61%,同时获得1.39个TER点的降低。边缘无对空词汇的方法短语翻译表的大小大幅度减小了70.00%,但是在测试集上的翻译性能下降了1.23个BLEU点。
在汉英翻译任务以及英汉翻译任务上,除使用BLEU和TER自动评价指标外,本文同时在100个随机选取的句子中进行人工评价来证实本文方法的有效性。本文通过专业翻译人员对机器翻译结果进行打分来评价翻译结果翻译质量的好坏。在人工评价的过程中,同时提供基线系统、基于频次的方法、基于词性标注的方法的翻译结果,翻译结果隐藏来源标签。翻译人员通过对翻译结果的选词准确度以及流畅度进行打分,分数范围在0至10之间。如果翻译结果与待翻译句子完全不相关,则为0分;如果翻译结果能够如实的表达待翻译文本的原意,同时在翻译结果中覆盖所有待翻译句子中关键词汇的内容,则为10分。由于篇幅有限,这里对人工评价标准的具体细节不做介绍。在人工打分的过程中,同时对待翻译句子中关键词汇的删词现象进行标注,对于句子中的非关键词汇,本文不做分析。表8中的人工评价结果表明,在人工评价分数以及删词错误个数的评价中,本文提出的方法优于基线翻译系统。表9中实验结果显示不同词性删词错误的个数以及比例的统计。从表9中可以看出,与表3中结果相比,本文方法明显降低了名词和动词删词错误的个数。
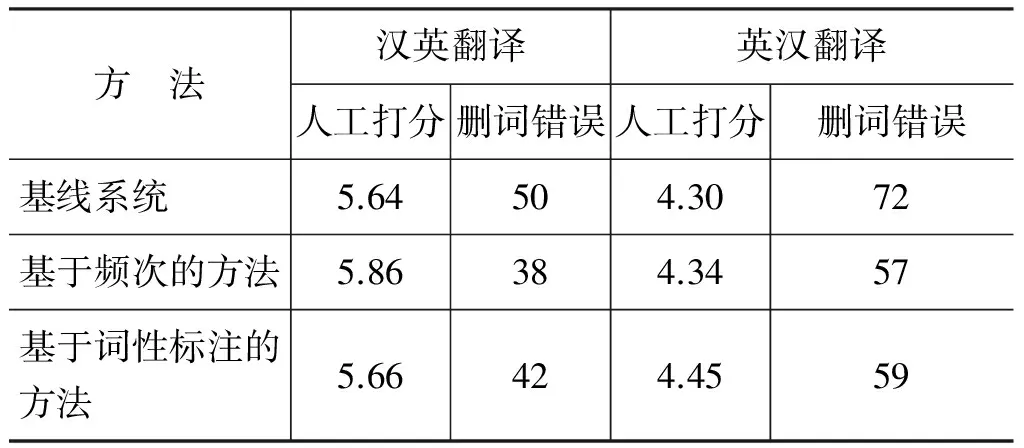
表8 汉英翻译任务以及英汉翻译任务中,人工打分及删词错误个数统计结果

表9 翻译过程中,不同词性的错误个数和百分比的统计结果。↓表示与表3中结果相比下降的个数
本文通过比较基线系统与本文方法的1-best翻译结果的解码路径来说明本文方法之所以有效的原因。图5给出基线系统与本文方法的一个真实的翻译结果对比。在图5(a)中,对源语言短语“搜集情报 .”来说,“搜集”和“情报”是源语言句子的边缘对空词汇,传统的短语对抽取方法抽取(搜集 情报.,.)这一与词对齐保持一致的短语对。在解码过程中,针对源语言待翻译短语“搜集 情报 .”,解码器从众多的短语对中选择(搜集 情报.,.)这一短语对来进行翻译,从而导致表达句义的关键词汇“搜集”和“情报”在目标语中对应的翻译结果不存在,造成了严重的删词错误问题。在图5(b)中,由于边缘对空关键词汇“搜集”和“情报”不在本文方法定义的非关键词列表SUEL中,所以短语对(搜集 情报.,.)并没有被本文方法所抽取,在翻译的过程中不存在这样一条短语对供解码器选择,从而在源头上避免了在翻译过程中使用隐含删词错误的短语对。所以在针对源语言关键词汇的删词错误问题上,本文方法明显优于基线翻译系统。
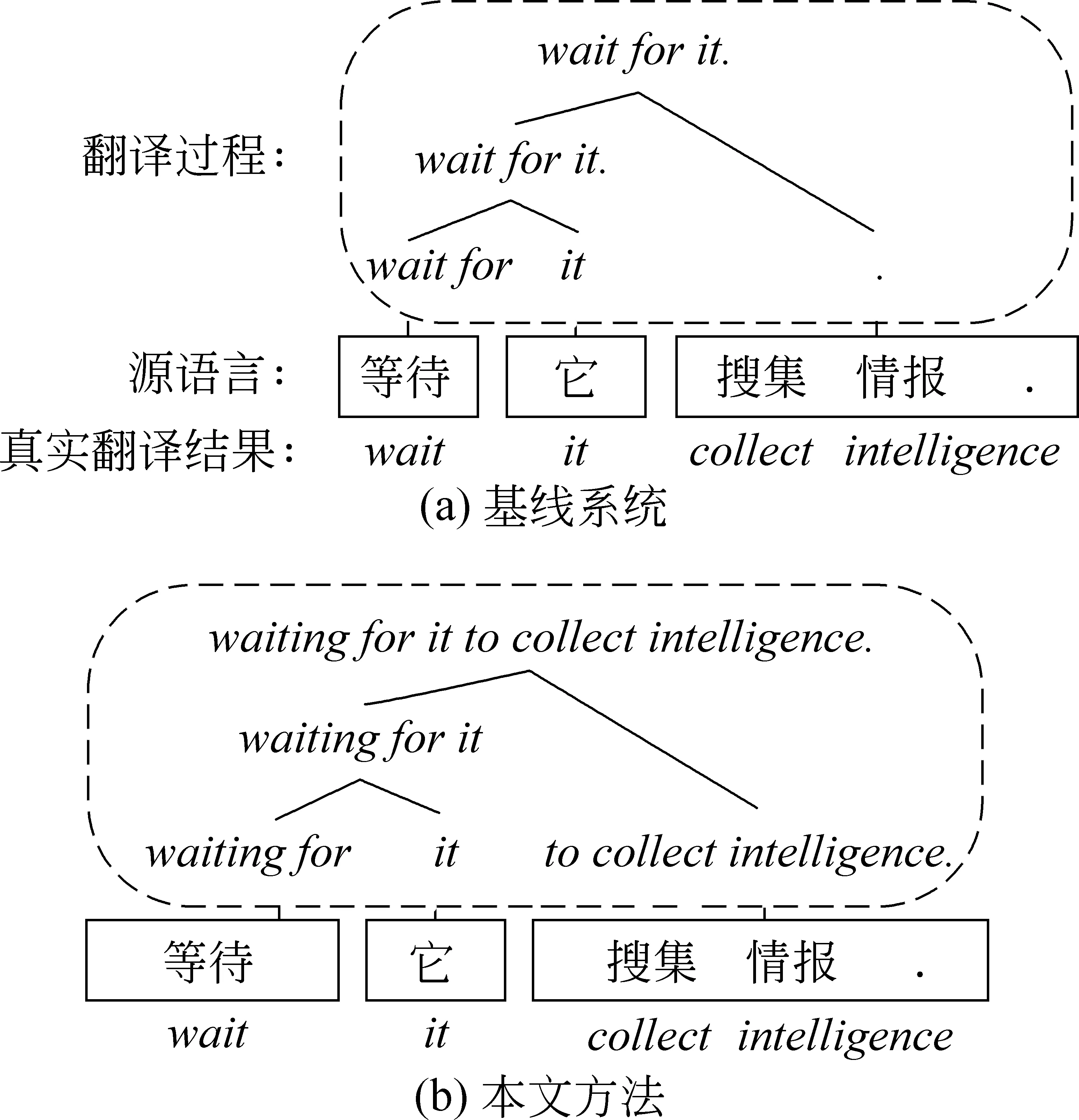
图5 基线系统(a)与本文方法(b)的1-best解码路径对比
上文提出的方法是对传统短语翻译表中隐含删词错误信息的短语对进行过滤,可称上文方法为“硬约束”方法。使用硬约束方法有一个不可回避的问题,即在过滤噪声短语对的同时,正确的短语对有可能被同时过滤。在这里,本文将提出的方法使用“软约束”的方式进行实验。为了达到软约束的目的,在实验的过程中通过在短语翻译表中加入一个新的指示性特征,用以指示当前短语对是否可以被本文提出方法进行抽取。表10为本文方法在软约束的实验设置下得到的实验结果,该组实验在汉英翻译任务上进行。与基线系统相比,基于词性标注的软约束方法在测试集上获得1.26个TER点的降低,基于频次的方法获得0.35点的降低。基于频次的软约束方法从翻译性能角度来看,效果不如硬约束方法;但是在基于词性标注的方法中,软约束方法的实验性能明显优于硬约束的方法,在BLEU和TER指标上,分别获得0.68点提高和0.67点的降低。从这组实验结果来看,在基于词性标注的方法中,硬约束方法过滤掉很多质量较好的短语对。

表10 汉英翻译任务中,软约束方法实验结果
4 相关工作
在机器翻译任务中,删词问题的分析研究已经取得了一些相关成果。例如,Zhang等在原始训练语料中移除对空频次较高的词汇,使用处理后的语料进行模型的训练[11]。虽然该方法简单、易于实现,但是该方法也同时向短语翻译表中引入新的噪声。Zhang等人的工作同时证明,在处理删词错误这类问题上,通过在短语对抽取的过程中过滤噪声短语对的方法在效果上明显优于提高词对齐质量的方法[12-15]。Menezes和Quirk提出基于treelet翻译方法的扩展,该方法在源语言中通过引入结构化的词汇插入和删除的调序模板对删词问题进行讨论[16]。Parton等人提出了一种混合的方法APES来解决翻译结果充分性错误[17]。Li等人提出了3种方法来处理源语言中冗余的词汇,使用多种方法对短语翻译表中短语对的翻译概率重新进行估计[5]。
虽然此前的工作提出了几种方法来缓解机器翻译任务中的删词错误问题,但是之前的工作没有对删词错误造成的原因进行分类。本文将删词错误分为3类,即词汇翻译内容选取错误、边缘对空关键词汇翻空和中间对空关键词汇翻空。针对这3类删词错误类型,本文选择较为严重的边缘对空关键词汇翻空进行解决,提出了针对这个问题一系列的解法,同时获得较好的实验结果。本文提出的方法与语言无关,可以将本文方法应用到任意语言对上来缓解删词错误问题。同时,在图4提出的受限的短语对抽取算法中,可以同时加入目标语言非关键词汇列表的约束,从而缓解翻译过程中目标语言冗余词汇的插入问题。本文提出的方法简单且易于实现,可有效缓解源语言句子中关键词汇的删除错误问题。
5 总结与展望
本文针对删词问题作了详细的研究与分析。本文通过人工分析的方法将删词错误类型划分为3类。针对3类删词错误问题,本文选择较为严重的边缘对空关键词汇翻空进行解决。首先,本文提出两种方法,即基于频次的方法与基于词性标注的方法,来对源语言句子中的关键词汇与非关键词汇进行识别;继而,本文方法使用源语言非关键词汇列表对短语对抽取的过程加以约束,提出受限的短语对抽取算法。本文方法同时在硬约束与软约束条件下进行实验,人工评价与自动评价均证实,本文提出的方法在汉英翻译任务和英汉翻译任务上,显著的提高了机器翻译系统的翻译质量,与此同时,硬约束的方法可以获得一个精简的短语翻译表。本文提出的方法有效的缓解了删词错误问题。
在未来的工作中,我们还将研究更为有效的模型和方法来对源语言句子中关键词汇与非关键词汇进行识别,同时也将对获取高质量的短语翻译表的短语对抽取算法进行研究,从而达到进一步缓解删词错误的目的。
[1] Philipp Koehn, Fran J Och, Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1. Association for Computational Linguistics, 2003: 48-54.
[2] Franz J Och, Heymann Ney. The alignment template approach to statistical machine translation[J]. Computational Linguistics, 2004, 30(4): 417-449.
[3] Franz J Och, Christoph Tillmann, Heymann Ney. Improved alignment models for statistical machine translation[C]//Proceedings of the 1999 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 1999: 20-28.
[4] David Vilar, Jia Xu, Luis Fernando D’Haro, et al. Error analysis of statistical machine translation output[C]//Proceedings of International Conference on Language Resources and Evaluation. 2006: 697-702.
[5] Chi-Ho Li, Dongdong Zhang, Mu Li, et al. An empirical study in source word deletion for phrase-based statistical machine translation[C]//Proceedings of the Third Workshop on Statistical Machine Translation. Association for Computational Linguistics, 2008: 1-8.
[6] Tong Xiao, Jingbo Zhu, Hao Zhang, et al. NiuTrans: an open source toolkit for phrase-based and syntax-based machine translation[C]//Proceedings of the ACL 2012 System Demonstrations. Association for Computational Linguistics, 2012: 19-24.
[7] Franz J Och, Hermann Ney. Improved statistical alignment models[C]//Proceedings of the 38thAnnual Meeting on Association for Computation Linguistics. Association for Computational Linguistics, 2000: 440-447.
[8] Franz J Och. Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1. Association for Computational Linguistics, 2003: 160-167.
[9] Kishore Papineni, Salim Roukos, Todd Ward, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40thAnnual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2002: 311-318.
[10] Matthew Snover, Bonnie Dorr, Richard Schwartz, et al. A study of translation edit rate with targeted human annotation[C]//Proceedings of the 7thConference of the Association for Machine Translation in the Americas. 2006: 223-231.
[11] Yuqi Zhang, Evgeny Matusov, Hermann Ney. Are unaligned words important for machine translation?[C]//Proceedings of the 13thAnnual Conference of the EAMT. 2009: 226-233.
[12] Ulf Hermjakob. Improved word alignment with statistics and linguistic heuristics[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2009: 229-237.
[13] Jingbo Zhu, Qiang Li, Tong Xiao. Improving syntactic rule extraction through deleting spurious links with translation span alignment[J]. Natural Language Engineering, 2013: 1-23.
[14] Yang Liu, Qun Liu, Shouxun Lin. Discriminative word alignment by linear modeling[J]. Computational Linguistics, 2010, 36(3): 303-339.
[15] Yonggang Deng, Bowen Zhou. Optimizing word alignment combination for phrase table training[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers. Association for Computational Linguistics, 2009: 229-232.
[16] Arul Menezes, Chiris Quirk. Syntactic Models for Structural Word Insertion and Deletion[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2008: 735-744.
[17] Kristen Parton, Nizar Habash, Kathleen McKeown, et al. Can Automatic Post-Editing Make MT More Meaningful?[C]//Proceedings of the Conference on EAMT. 2012: 111-118.
猜你喜欢
中老年保健(2022年1期)2022-08-17
江苏钢铁(2022年9期)2022-07-02
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
海峡姐妹(2016年2期)2016-02-27
考试周刊(2015年36期)2015-09-10
科学中国人(2014年22期)2014-07-23
中国商人(2013年1期)2013-12-04
中国商人(2013年1期)2013-12-04
