
大数据在音乐推荐质量提升中的实践及应用
2014-02-28 06:12张玉忠袁立宇
电信科学 2014年10期
张玉忠,方 艾,金 铎,袁立宇
(中国电信股份有限公司广东研究院 广州510630)
1 引言
大数据时代下,每个人都是数据的消费者,也是数据的贡献者。IDC(International Data Corporation,国际数据公司)的调查数据显示,全球产生和复制的数据量到2015年将达到8 ZB,2020年甚至有望达到40 ZB[1]。以具体的例子来看,百度的大数据当前虽然已经达到EB级别,但其信息量占比却不足全人类所掌握信息量的百分之一。即使在游戏、电子商务、音乐应用等垂直领域,数据量级别虽然大大减少,但数据量依然非常惊人。因此如何高效地组织和利用大数据的分析结果,挖掘大数据蕴含的潜在价值,为用户提供个性化的精确推荐服务以避免大海捞针式的搜寻,在当前信息技术产业中掀起了一个大数据的热潮。正如《大数据时代》的作者维克托·迈尔·舍恩伯对大数据的洞见:“大数据时代最大的转变,就是放弃对因果关系的渴求,取而代之的是关注相关关系。”
数据推荐作为大数据应用的方向之一,其目的就是通过收集和整理用户的历史行为、消费习惯、社会属性等,把看似分散的、无关的、多样性的底层数据转化为用户知识图谱和用户兴趣画像,这些综合的、格式化的知识库提供了观察用户的立体化、全方位的视角,并通过应用平台以功能组件模式向终端用户输出。这些充分组合包装的信息,尽力避免了用户和产品之间不必要的交互,进而把信息向着用户服务的“私人定制”智能化目标推进,使得信息消费者只需知道“是什么”,而不需要知道“为什么”。
2 音乐推荐的框架及实践
音乐推荐是一种比较典型的互联网应用,但因为音乐类软件产品众多,各产品在功能、UI(用户界面)设计等方面相互借鉴和竞争,同质化现象越来越普遍。在这种音乐“红海市场”的互联网环境下,如何最大程度地发展和挽留用户?个性化的内容推荐服务和完美的用户体验无疑是重要的解决途径之一。
《埃森哲2014年技术展望》报告提出“无边界企业的崛起”概念:企业的劳动力资源不再只是企业的员工,还包括互联网上的所有用户,因为互联网时代的企业可以利用大数据技术把自己产品的用户(更广泛意义上还包含整个网络用户)视为自己的编外员工。充分发掘产品相关的“互联网用户”产生的数据价值,有助于从群体规律中提炼出用户的个性特点,以个性化和差异化的服务来帮助企业扩大用户规模,延长用户的产品生命周期。协同过滤正是上述“集体智慧”应用的典型推荐方法之一,主要分为基于用户(user-based)和基于项目(item-based)两类算法。协同过滤推荐算法在内容分类信息缺乏(如标签体系不完善)、具体内容难于量化表达(如用户音乐品味)等情境下的推荐效果较好,但是它面临的缺点也是很明显的,如系统规模过大时,系统性能会变差;项目数量变多后,会造成评分矩阵稀疏度过低、新用户的冷启动等问题[2,3]。
本文以音乐产品的歌曲推荐为例,介绍大数据技术如何应用在音乐产品中,特别是如何通过多种推荐方式的组合以提高推荐质量的过程和方法。与众多关注具体单一算法的实现及准确度的推荐系统不同,本文所述的推荐系统侧重于解决准实时的在线运营产品面临的如下困难:既要考虑推荐的准确性,也要考虑算法的复杂度和高效率,从业务角度还要考虑系统维护和内容调整的方便性、实时性。因此在解决方案上采用“协同过滤+业务规则+标签内容体系等”多种模式相结合的混合推荐算法,经过一年左右的线上运营,相比于单一的推荐算法和推荐方式,本方案的推荐效果要理想很多。
系统运行的逻辑框架如图1所示。本推荐系统以Cloudera提供的CDH开源分布式计算框架作ETL处理平台,以Mahout工具集作为协同过滤算法的实现框架,通过海量原始数据的收集和处理、用户音乐评分归一化、初步歌曲推荐列表产生、内容标签体系建立和二次过滤规则等多个步骤搭建了一个实时歌曲推荐系统。
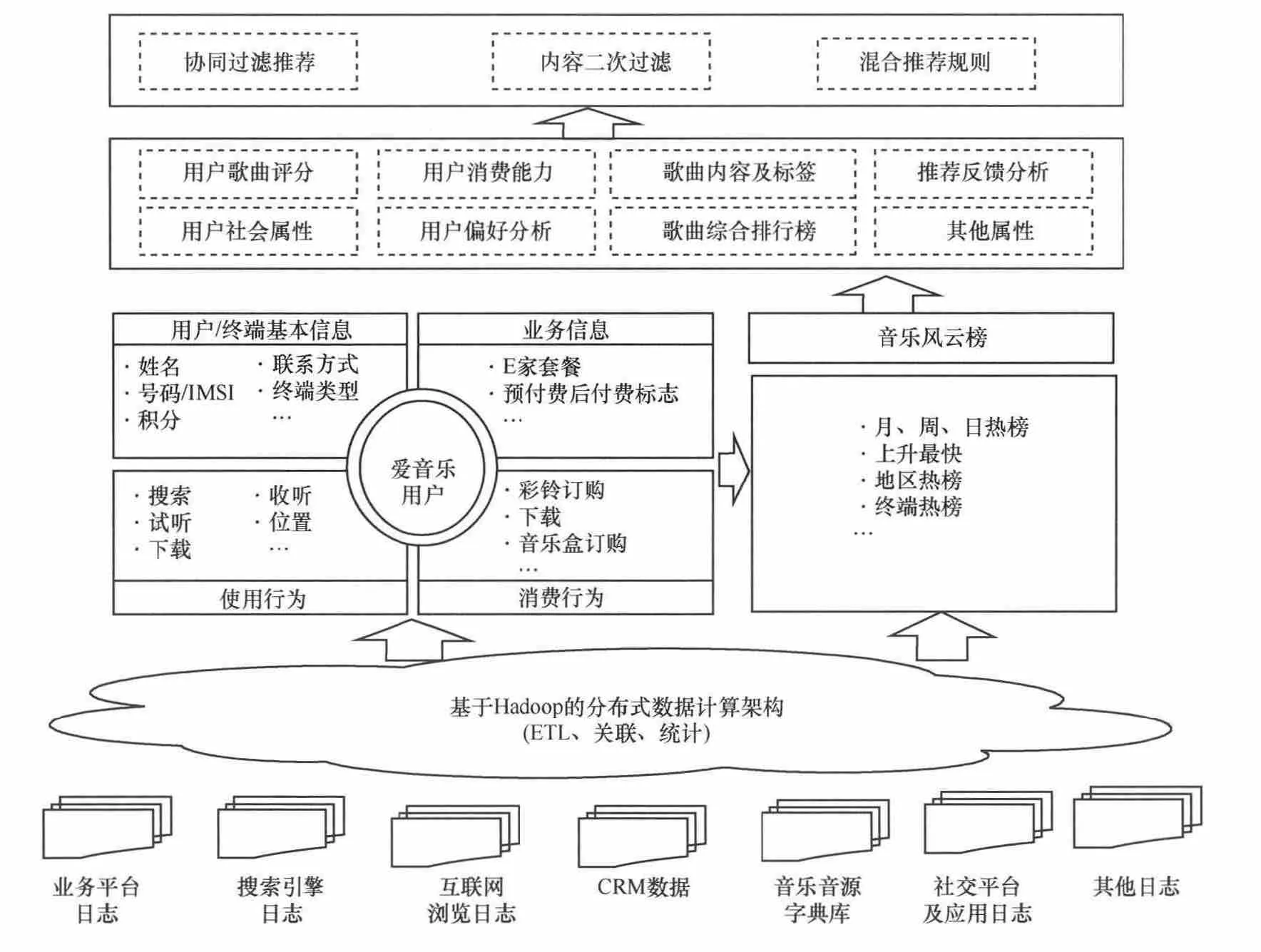
图1 系统运行的逻辑框架
在推荐模型的算法调整和优化时采用如下方法:在用户歌曲评分上参考RFM(指最近一次消费(recency)、消费频次(frequency)、消费金额(monetary))模 型,建立考虑多个维度的综合评分;在推荐算法上,引入项目稀疏度、重叠度、可信度概念;混合推荐时引入飙升词、内容标签和二次规则过滤等方式,具体分为以下5个步骤。
2.1 收集大数据
用户的音乐数据从形式上来说有格式化/半格式化数据,甚至有非格式化数据;从来源来看有歌曲的浏览、试听、下载、购买、搜索、收藏等纯粹的音乐偏好行为,还有评论、分享、转发等社交性质的行为,这些信息可以从产品平台日志或通过互联网设备捕捉用户上网的URL清单获得。
还有一些信息如终端信息、消费能力、电信套餐及增值业务、移动支付能力等可以从电信CRM系统获得,其社交关系图谱等可以从电信话单、短信以及SNS类社交软件日志获得。
音乐的内容和标签可以从产品的字典库获得,如曲风、歌手、歌词,甚至可以依靠爬虫软件从互联网补充字典库所缺失的必要信息。
2.2 评分归一化
用户的评分数据有很多种类:如1~5分的5级数字评分表;差(差评)~好(点赞)的描述性阶梯等级,但这两种方式的评分多依赖于用户个人的主观判断,也就是说对同一首歌曲,评分为3分的用户A并不见得比评分为2分的用户更欣赏这一首歌曲。要解决这类问题,可以采用归一化的方式,以用户A对其所有歌曲的评分均值为标准,其他分数相对该均值的比值作有效评分,并二次转化为相应的可度量值。
对于没采用评分数据的系统来说,可以通过用户在浏览歌曲的相对驻留时长、对歌曲试听或下载的完整程度以及业务权重(如付费购买>免费下载>免费试听)相结合的方式作综合评价。
最终的评分结果是对上述两类评分,再做一次处理。因为用户对歌曲的偏好,单独考虑“用户评分”这个维度并不能完整表述其偏好程度,因此参考数据挖掘的RFM模型,以周或天为时间单位,以离当前日期的周期值作R,以该周期内对同一首歌曲的试听次数作F,以听歌的完整程度或业务权重作M,构建用户对歌曲的综合评分。
2.3 相似度计算
随着推荐系统规模越来越大(以本音乐产品为例,仅版权歌曲数量就超过了30万首,互联网歌曲达90万首,更不要说淘宝这样的在线商品数超过8亿件的巨型系统),庞大的商品数目必然会导致两个用户之间选择的重叠非常少,因此评分矩阵的稀疏性问题也是推荐面临的难题之一。
目前解决稀疏性通常采用算法改进,以提高推荐效果,如矩阵降维、聚类等,本文引入“可信度”概念以调整用户相似度取值,具体如下:假设用户A和用户B的歌曲历史记录分别为M和N,其歌曲空间维度值为Q,相同歌曲数目为P,则取可信度为:可信度=稀疏度×重叠度=(M/Q×N/Q)×(P/Q),因此以前的用户相似度计算也要调整为:可信度×用户相似度,按照这种修正算法,常用的Pearson模型可变为如下计算式:
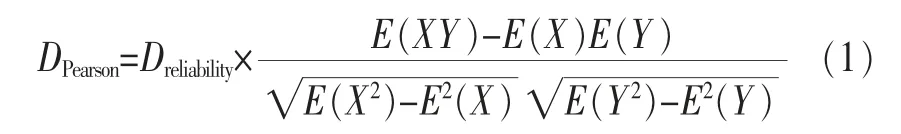
其中,Dreliability是新引入的可信度值。
“稀疏度”反映了用户的向量距离远近程度,如果两个用户之间的歌曲交集差异越大,那么这两个用户的距离就越远,反映在计算式中,他们的稀疏度值接近于0。
“重叠度”从另外一个维度反映了用户的向量距离远近程度,如果重叠度接近于1,则表示两个向量都在某些相同的属性上具有实际值,那么得到的距离就具有较高的可靠性。
“可信度”是向量的相对稀疏度和重叠度的乘积,共同影响用户距离的计算。可信度的概念实际是对现有传统协同过滤算法中计算距离方法的一种改进,可以降低因计算距离过程中的随机性导致的距离偏差。由于在用户相似度的计算中新引入了上述“可信度”变量因子,这使得在计算用户邻居的时候更准确,降低原算法中因为缺失值导致的用户邻居发现错误的可能性,由于计算这些值都可以在很短的时间内完成,因此对原算法的性能、计算速度影响不大,都在可接受的范围内。
2.4 内容分类
上述用户评分矩阵通过协同过滤算法得到推荐歌曲列表后,有时效果仍然不是很理想。其中部分原因是用户在听歌的过程中被一些外界原因干扰而出现了偏好噪音:若用户听歌过程被打断后忘记进行“暂停”操作,但音乐产品却随机向用户播放音乐;也有可能是用户被动地接受了音乐产品的歌曲列表,而实际并没有按照自己的偏好过滤和选择。针对这种情况,分析歌曲的内容分类可以进一步提高推荐质量。
内容分类在数据挖掘领域有很多分类算法,对音乐产品来说,有基于歌词分词的文本内容分类,也有基于音符或音律的语音学分类。本文在实践中以歌词分类的方式,采用朴素贝叶斯算法,以互联网音乐分类较好的典型分类和样例歌词归类为种子,对字典库的所有歌词做了分类处理,整体效果可以达到40%~60%的匹配率。
另外一种分类是基于统计计数的分类,例如飙升词、热榜等。本文在使用这些统计数据的时候,没有采用简单的计数方式,而使用了用户归一化评分的累积方式。以飙升词为例,定时统计每个时段的统计指标后,跟上一个时段的指标值相比较,如果相对比值超过一定的阈值,则认为该指标发生了飙升,从而指导运营人员快速响应,更新产品的相关推荐列表。
2.5 混合推荐
协同过滤推荐算法在满足个性化需求方面虽然能起到较好的作用,但是在实际应用时通常需要混合的方式做歌曲推荐[4],也就是要采用多种推荐方式相互交叉和补充,这主要是由于以下几种情况的存在。
首先,第一次使用音乐产品的用户或者信息量过少的用户,推荐系统需要处理冷启动问题。这类用户一种常用的解决办法是利用引导性的文本信息进行辅助推荐,亦可通过在首次使用或者注册时通过导航机制获得用户的关键属性信息,如年龄段、居住地/地域方言、教育程度、性别、行业等;另外音乐的标签系统(如语种、曲风、影视剧、歌手、热榜榜单、首发/经典)的广泛应用也是解决冷启动问题的可选方案,这些标签的分类整理本身就是商品内容的萃取,同时也可以视为收集用户个性化偏好的初始种子。
其次,协同过滤虽然在推荐算法上效果较好,但也会碰到多样性、新颖性和覆盖率问题。具体表现为推荐的歌曲范围太窄,特别是用户使用一段时间之后会出现重复推荐,而且容易导致曲库字典的大量歌曲成为“僵尸”,这种缺陷带来的恶果就是用户吸引力和满意度下降,甚至导致用户的留存率降低或用户流失。
再次,从业务运营的角度来看,收费歌曲、上线新歌、主推歌曲、节假日应景音乐也需要一定的人工干预和展示途径。这些运营元素的引入,可以在一定程度上弥补单一算法带来的新颖性不够等缺陷,扩大“长尾”,获得规模效应。
3 音乐产品的实践应用及效果
利用上述的大数据平台框架及推荐处理流程,项目团队在实际的运营支撑中进行了一系列的音乐产品研发运营实践,包括建立个性化用户知识库、差异化歌曲推荐、开发和运营流程优化、用户体验及反馈分析等。
以某款手机的定制播放器为例,它是音乐运营中心与手机终端设备供应商之间约定的应用预装产品,经过一年半的运营,到2014年上半年止,该产品的注册用户数达到2 500万户,日UV(unique visitor)突破100万户,产品功能包括听歌、搜索、收藏、下载、分享、订购等。这些用户产生的原始日志量每日可达50 GB,有效数据超过5 000万条,再加上超过2亿条CRM历史记录以及其他终端、评论、SNS数据,这些用户行为数据以日为单位,定期经过大数据平台收集、整理、更新,最终导入用户歌曲评分矩阵为推荐备用。
当用户登录后,首页显示的是一系列通过复杂、大规模、实时的算法得到的差异化信息,同时还有一些热榜、专辑介绍等信息。以图2为例,当用户搜索并播放歌曲《高山流水》时,在用户界面的左上部以列表的形式显示经过混合推荐处理过的Top10歌曲,而在左下部显示推荐的少量音乐专辑及图片,在歌曲的播放过程中通过开关切换来控制是否显示源于互联网的歌词或者歌手图片(这些信息是爬虫定期更新和运营人员人工整理的);右半部分的用户界面以tab bar(选项卡)切换视图的形式显示Top10的热榜/新榜/飙升榜3类不同维度的歌曲以满足新用户的选择。整体来看,在这个用户界面设计里,个性化推荐歌曲、热榜歌曲、业务运营所需的人工干预歌曲都体现了出来,在一定程度上解决了冷启动和新颖性不足等缺点,可以满足不同用户的音乐品味,收到了较好的效果。
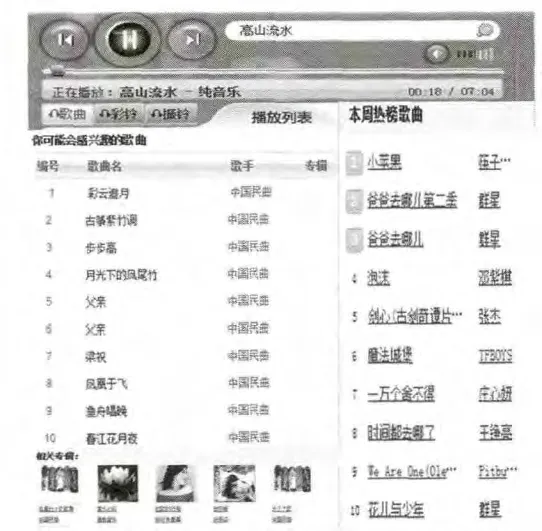
图2 用户界面示例
4 结束语
由于Hadoop等开源项目的发展及应用,特别是CDH等开源平台及生态系统的稳定以及相关工具如Hive、Impala、Machine Learning等的广泛使用,解决了早期的推荐系统在数据量过大时面临的内存、CPU等计算瓶颈的难题。基于分布式并行计算的算法改良可以充分发挥云计算的特点,提高大规模数据分析的效率,推动基于大数据的推荐系统的发展[5];同时由于分布式计算架构也降低了大数据处理的预算成本和技术门槛,IT部门可以较高的性价比进行大数据项目的研发和实践,近来以Spark为基础的基于内存的迭代式计算框架与以MapReduce为基础的文件流模式的计算框架互为补充,也为机器学习(ML)和数据挖掘(DW)提供了技术保障。但就目前而言,大数据的应用及产生的效益还处于起步阶段,缺乏成熟的大规模的商业模式,信息内容最终还是需要转化为以结构化信息为主,未来随着挖掘工具和算法的进一步发展和成熟,大数据在应用智能化和商业模式创新等方面必定会起到更大作用。
未来,互联网推荐类应用可以通过跨域行业应用数据和互联网海量数据的深度整合,建立多维的、综合的统一用户视图,勾勒一个比较全面的用户画像。这种360度全方位的客户洞察系统的建立,可以打造一个面向用户本身及其衍生的社会网络、生活消费等多层面的个性化知识库,通过深入分析用户在不同业务中的行为及关系并挖掘其中的潜在用户价值,可以进一步促进不同行业领域的跨域业务协同发展,同时也会为用户带来更好的体验,形成一个良性循环的生态圈。
1 大数据就在你身边.http://info.secu.hc360.com/2014/01/201838764677.shtml,2014
2 大数据应用之个性化推荐的十大挑战.http://www.kddchina.com/article-49-1.html,2014
3 个性化推荐十大挑战.http://blog.sciencenet.cn/blog-3075-588779.html,2014
4 张瑶,陈维斌,傅顺开.协同过滤推荐研究综述.微型机与应用,2013(6)
5 李改,潘嵘,李章凤等.基于大数据集的协同过滤算法的并行化研究.计算机工程与设计,2012,33(6)
猜你喜欢
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
商用汽车(2016年11期)2016-12-19
东方艺术·大家(2016年6期)2016-09-05
商用汽车(2016年6期)2016-06-29
现代防御技术(2016年1期)2016-06-01
商用汽车(2016年4期)2016-05-09
创业家(2015年5期)2015-02-27
数位时尚·环球生活(2009年8期)2009-11-19
