
基于粗糙集与关联规则的道路运输管理信息数据挖掘方法*
2014-03-15 08:44郑晓峰王曙
华南理工大学学报(自然科学版) 2014年2期
郑晓峰 王曙
(华南理工大学土木与交通学院,广东广州510640)
我国的道路交通运输发达,占综合运输的65%以上.针对道路交通运输管理复杂的特点,近年来各省级道路运输管理机构积极开发和实施道路运输管理信息系统,用科技的手段去规范管理、提供便民服务.道路运输企业的质量信誉考核和道路运输车辆准入核查作为道路运输管理的两项主要措施,所遇到的数据挖掘问题在整个道路运输管理信息数据挖掘研究中具有普适性与代表性.数据挖掘[1]过程又称知识发现过程,1989年在国际会议IJCAI(International Joint Conference on Artificial Intelligence)上被首次提出,经过20多年的发展,目前已成为数据库领域的热门学科,其理论研究和实际应用均取得了丰硕的成果,在交通运输领域的数据挖掘研究成果主要有:运用聚类分析方法研究车辆卫星定位数据挖掘[2-3],运用关联规则方法分析交通事故原因[4-5],运用时空数据挖掘、关联规则等方法研究交通规划[6-7],综合运用分类、聚类和关联规则等数据挖掘方法研究交通流控制[8-9].但截至目前,关于海量道路运输管理信息数据挖掘方法的研究鲜见报道.
数据关联是数据库中一类可被发现的重要知识,若两个或多个变量的取值之间存在某种规律性,就称为关联.道路运输管理所需的决策分析信息大部分涉及关联问题.关联规则数据挖掘自Agrawal等[10]提出后已被广泛研究,其传统算法Apriori也在原有基础上不断得到优化[11],但是目前仍然存在许多用算法不能解决的问题,例如因数据库的决策目标和关联属性未规划清楚而造成的庞大的关联规则挖掘的运算量,由于支持度和置信度等参数设置不适当而产生的大量无用规则等.因此,准确地规划挖掘目标,做好数据的约简等预处理和合适地配置参数对关联规则数据挖掘来说意义重大.近年来,关联规则方法在交通运输领域的最新应用研究成果集中在对时空数据的挖掘上[[4-7,12].这些成果所应用到的数据本身具备明显的时间序列性质,而道路运输管理信息多是无序的非结构化数据,挖掘其规律性规则难度更大,挖掘过程中会遇到更多的上述问题,因此探索关联规则在道路运输管理数据上的新的应用思路和方法具有重要的现实意义.
粗糙集理论是Pawlak[13]于1982年提出的一种数据挖掘工具.它的基本思想是通过关系数据库分类归纳形成概念和规则,通过等价关系的分类以及分类对于目标的近似来发现知识.粗糙集能够支持知识获取的多个步骤(如数据预处理、数据约简、规则生成和依赖关系获取等),而无需提供所需处理的数据集合之外的任何先验信息,所以对问题不确定性的描述或处理可以说是比较客观的[14].道路运输管理信息多为不一致、不精确和不完整的数据,而且其数据挖掘的目的多为决策分析类型,因此粗糙集分析方法适用于此类信息的数据挖掘.粗糙集理论发展30多年来,在理论研究和应用研究方面均取得了大量代表性成果[14-15],但有关粗糙集方法应用于道路运输管理信息数据挖掘的研究在国内外却鲜见报道.
针对道路运输管理信息数据的特点,文中利用粗糙集属性约简方法,研究关联规则传统理论与粗糙集理论的结合问题,提出粗糙集分析与经典关联规则相结合的数据挖掘方法,利用粗糙集方法分析规则条数与支持度、置信度之间的关系,并针对质量信誉考核问题验证了粗糙集分析和关联规则的综合方法,研究了属性约简方法在道路运输车辆准入核查中的应用.
1 相关理论知识
1.1 关联规则
设I={I1,I2,…,Im}是文字属性,称为项.给定一个事务数据库D,D={t1,t2,…,tn}.其中每个事务ti(i=1,2,…,n)都对应I的一个子集,满足tn⊆I.每一个事务都有一个标识符TID.如果项集α⊆I、β⊆I,并且α∩β=∅,则形如式(1)的蕴涵式称为关联规则:

如果D中有s的事务包含α∪β(其中s=D中包含α∪β的事务个数/D中所有事务个数 × 100%),那么规则α⇒β的支持度为s,其计算表达式为
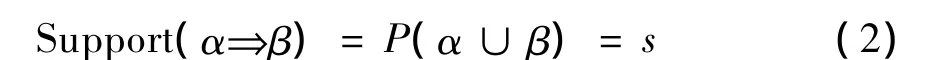
如果包含α的事务有c也包含β(其中c=既包含α又包含β的事务个数/包含α的事务个数× 100%),那么规则α⇒β的置信度为c,其计算表达式为

设定最小支持度θ和最小置信度ω,如果s≥θ且c≥ω,则α⇒β为强关联规则.
1.2 粗糙集
1.2.1 信息系统的抽象
粗糙集理论把客观世界抽象为一个信息系统[13].一个信息系统S是一个四元组,记为

其中:U是对象(或事例)的有限集合,也称为论域,U={u1,u2,…,um};A是对象属性的有限集合,记为A={a1,a2,…,am};V是属性的值域集,记为V=∪Vi,Vi是A中元素ai的值域;f是信息函数,记为f:U×A V,f(ui,ai)∈Vi,他为每一个对象的每一个属性赋予一个值.
1.2.2 不可分辨关系
设G={g1,g2,…,gn}⊆A,可以定义G上的一个不可分辨关系:

1.2.3 等价类和划分
对于ui∈U,可用集合[ui]g来表示包含元素ui的等价类,.所有得到的等价类的并集构成了论域U的划分,记为U/ind(G),也称为U的基本知识或概念.
1.2.4 约简
如果属性集合G⊆A满足ind(G)=ind(A),且对于任意gk∈G均满足式(5):
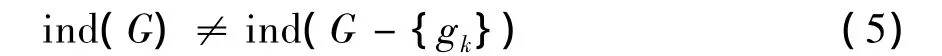
则G是A的一个约简,记为G=RED(A).A的所有约简的交集构成A的属性约简的核,记为CORE(A)=∩RED(A).
2 基于粗糙集理论的关联规则挖掘
2.1 基本思想
传统的关联规则挖掘有4个重要的步骤[16]:
步骤1数据预处理;
步骤2 根据最小支持度找出数据集中的所有频繁项集;
步骤3 根据频繁项集和最小置信度产生关联规则;
步骤4 评估规则.
传统关联规则挖掘的研究重点在产生关联规则的算法求解和改善上.但事实上,关联规则挖掘的数据预处理是非常关键的,粗糙集理论在描述数据系统和简化待挖掘数据系统关联项问题方面有独到的作用.此外,如果最小支持度和最小置信度两个关键阈值设置不当,会产生大量的频繁项集和大量的冗余规则,影响用户的决策,这是规则评估的关键问题.因此可尝试运用粗糙集理论和方法,对规则条数与最小支持度和最小置信度之间的关系问题进行求解.
2.2 关联规则和粗糙集融合解决方法
2.2.1 归纳关联规则
按照粗糙集方法的信息系统抽象方法,大多数关联规则挖掘问题可归纳为求解实例中以决策目标确定的关键数据项集和其余数据项集之间关联规则的问题.
定义1 式(4)中的对象属性A通常可以划分为两个集合E和F,A=E∪F,E∩F=∅.E称为条件属性集,F称为决策属性.将一个数据库中待求解关联规则的数据项集划分为粗糙集表述的信息系统中A的条件属性集和决策属性,表达为求解S=〈U,A,V,f〉(A=E∪F,E∩F=∅)中E⇒F的问题.这里的U指关联数据库所有记录的集合(即为式(4)中所称的论或),这时的S也称为决策表.
通过定义1的归纳,待求解关联规则的数据项集即可先根据粗糙集理论的约简方法做预处理以减少冗余数据项.
2.2.2 约简条件属性集
粗糙集理论的约简的典型算法是根据式(5)衍生得到的.文献[17]介绍了通过构造差别矩阵对条件属性集E进行约简的方法.该方法的差别矩阵M是一个的矩阵,其中的每一个元素mij⊂ E,做进一步整理得到式(6):

M为主对角线为∅的对称矩阵,在实际应用中只计算它的上三角阵.约简的计算过程是对mij中每个元素进行“或”运算,然后再对所有的mij进行“与”运算,最后的结果就是M约简的组合.
2.2.3 粗糙集方法与Apriori算法的结合
定义2 设集合L是条件属性集E的子集,以L得到的等价类称为特征集,记为[X],其中X是特征集[X]的描述.如果L有k个元素,那么称[X]为k元特征集,记为[Xk].Xk称为k元特征描述,用式(7)表述:

定义3 令θ是关联规则的最小支持度,如果规则Xk⇒F的支持度大于θ,那么称由Xk确定的k元特征集为频繁k-项集.令Tk表示频繁k-项集的集合,Rk是k元特征集的集合,称为k元候选集.则有Rk⊇Tk,主要方法总结为算法1,描述如下:
待挖掘的数据库用粗糙集方法处理后,归纳成决策表S,S=〈U,A,V,f〉(A=E∪F,E∩F=∅).E1为条件属性集E的约简,F为决策属性,设θ为最小支持度,ω为最小置信度.
结合Apriori-new算法[18],得到E1⇒F的关联规则,如图1所示.

图1 粗糙集应用于关联规则挖掘的算法流程Fig.1 Algorithm process of association rule mining using rough set
2.2.4 关联规则条数与参数配置的关系
上述方法中,最小支持度和最小置信度的设置对关联规则的产生条数有重大的影响.通过设置一定范围的最小支持度和最小置信度,得到一定范围内的规则条数,它们之间的关系可能也存在一定的规律.文献[19]用回归分析的方法研究这一关系.但事实上这一个关系是不确定的,针对特定领域的应用,可运用粗糙集的方法来求解它们的关系.
根据粗糙集理论,得到另一个决策表P,P=〈U2,A2,V2,f2〉(A2=E2∪F2,E2∩F2=∅).U2是关联规则运算记录集,θ2是最小支持度,ω2是最小置信度.设θ2∪ω2=E2,F2是规则条数.通过上述方法可求解形如E2⇒F2的关联规则.
3 应用研究
3.1 道路运输企业质量信息考核验证
文中提出的粗糙集和关联规则综合应用方法,已在广东省道路运政管理信息系统中的客运企业质量信誉考核数据库得到验证.
3.1.1 决策属性与决策表
客运企业质量信誉考核评分表中有4个要素:运输安全、经营行为、服务质量和社会责任.每个要素对应各自的得分档次,道路运输管理部门组织专家对每个企业按照评分表就各要素进行打分,然后综合各要素得分情况,再结合专家意见得到最后的评定结论.可以看出,管理部门需要知道的是评定结论与哪些要素的取值结合较为紧密,哪些要素在实际操作中可以忽略.因此,可设评定结论为决策属性,评定要素为条件属性,评定记录为论域.为了说明问题,选择9条记录建立如表1所示的决策表,其中{运输安全、经营行为、服务质量,社会责任}为条件属性集,评定结果为决策属性.

表1 道路运输企业质量信誉考核决策表Table 1 Decision table of quality credit assessment for road transport ation enterprise
3.1.2 数据预处理
为了构造差别矩阵来对决策表进行约简,使用字母a、b、c、d、e来代替各属性,其中a、b、c、d代表条件属性,e代表决策属性;同时为简化文中的计算过程,各属性值合并划分为两个档次,好用“1”表示,中和差合并为一个档次,用“0”表示,得到表2所示的概化表.

表2 概化后的决策表Table 2 Generalized decision table
3.1.3 条件属性集的约简
按照前文所提到的差别矩阵约简方法得到差别矩阵M:

对矩阵中各元素进行“或”运算,然后进行“与”运算,最后得到a∧b∧c,则得到一个约简{a,b,c},约简后的决策表如表3所示.

表3 约简后的决策表Table 3 Reduced decision table
3.1.4 关联规则的获取
设最小支持度θ=30%,最小置信度ω=80%,利用算法1得到以下4条关联规则.
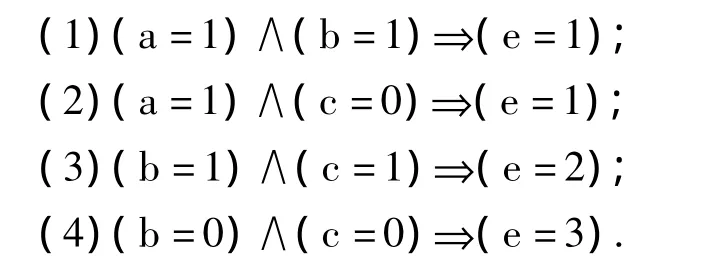
其现实意义是运输安全性好且经营行为好的则质量信誉好,运输安全性好且服务质量中等的则质量信誉好,经营行为好且服务质量好的则质量信誉中等,经营行为差且服务质量差的则质量信誉差.
3.1.5 规则条数与支持度、置信度的关系
在上述计算过程中,采用多个最小支持度θ2和最小置信度ω的组合,得到规则条数F2的对应值,组成决策表P.再用决策表P及算法1可得到最小支持度θ、最小置信度ω和规则条数F2的关系如下:
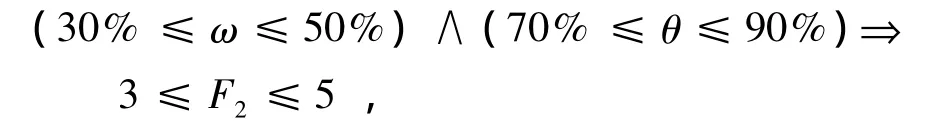
即当最小置信度ω在30%≤ω≤50%区间取值,且最小支持度θ在70%≤θ≤90%区间取值时,可使规则条数稳定在3到5条.
3.2 道路运输车辆准入验证
3.2.1 燃料限值核查制度的主要问题
燃料限值核查制度是指各地交通主管部门根据国家颁布实施的达标车型表去核查道路运输车辆是否达标.表里的核查项目是需要核查的达标车型表中公布车型的具体参数.对照检查公布车型的具体参数与实际车辆的具体参数是核查工作的主要内容,因此核查项目的多少直接决定了实施部门的工作量.研究究竟真正需要核查多少具体参数,既能保证数据能够判断实际车辆是否满足达标车型的要求,又能最大限度地减少核查内容、减少地方道路运输管理部门的工作量,是实施燃料限值核查工作遇到的主要问题.实际工作中遇到的是如表4所示的数据表.

表4 计算示例数据表Table 4 Data table of calculation example
3.2.2 核查项目约简解决方法
目前燃料限值制度的核查项目有12项,设为核查项目的集合{车辆型号,载客人数(含驾驶员),外形尺寸,整备质量,总质量,发动机型号,底盘型号,驱动型式,轮胎规格,货箱栏板内尺寸或容积,牵引座最大允许承载质量,准拖挂车总质量},用字母代替表示为{C,H,J,K,L,N,O,P,Q,R,T,W},Y代表结论.
广东省自2010年3月1日全面实施燃料限值核查制度后,核查新增道路运输营运车辆共12814辆,其中核查结论为通过的有12649辆,不通过的有165辆.
通过广东省道路运输管理信息系统后台数据库取得已具有12814条记录的数据表,以表4的定义生成决策表,如表5所示.

表5 广东省燃料限值工作决策表Table 5 Work decision table of fuel limits set by Guangdong Province
利用上述方法来求条件属性的约简,利用C++语言编程并在Windows 7平台进行“与”和“或”运算,最后得到该决策表的一个约简{C,H,J,N,O,P,R,T},即车辆型号、载客人数、外形尺寸、发动机型号、底盘型号、驱动型式、货箱栏板内尺寸或容积、牵引座最大允许承载质量为必须核查的项目,可将原12项的核查项目减少为8项,即决策表的条件属性减少33%,对应的工作量也减少了33%,有重要的实际应用价值.
4 结语
文中针对道路运输管理信息数据的特点,将粗糙集理论方法运用到经典关联规则数据挖掘中,提出了粗糙集分析与经典关联规则相结合的数据挖掘方法,利用粗糙集方法分析了规则条数与支持度、置信度之间的关系;通过道路运输管理的实际案例验证了该方法的科学有效性,证明该方法对于解决道路运输管理的实际问题切实可行.但由于关联规则带有一定的主观判断,因此在挖掘目标不明显的数据挖掘应用中有一定局限性.该方法较为适用于推测评定结果和评定指标之间关系的关联规则数据挖掘.
[1] 李思男,李宁,李战怀.多标签数据挖掘技术:研究综述[J].计算机科学,2013,40(4):14-15.Li Si-nan,Li Ning,Li Zhan-huai.Multi-label data mining:a survey[J].Compute Science,2013,40(4):14-15.
[2] 唐亮.信息化条件下营运车辆安全监管关键技术研究[D].重庆:重庆大学自动化学院,2012.
[3] 刘卫宁,曾婵娟,孙棣华.基于DBSCAN算法的营运车辆超速点聚类分析[J].计算机工程,2009,35(5): 268-272.Liu Wei-ning,Zeng Chan-juan,Sun Di-hua.Clustering analysis of overspeed spots for commercial vehicles based on DBSCAN[J].Computer Engineering,2009,35(5): 268-272.
[4] Xiao Juan,Ye Feng,Xie Yafen,et al.Association rule mining and application in intelligent transportation system[C]∥Proceedings of the 27th Chinese Control Conference.Kunming:Beihang University Press,2008.
[5] Tian Rui,Zhao-sheng Yang,Zhang Mao-lei.Method of road traffic accidents causes analysis based on data mining[C]∥Proceedings of 2010 International Conference on Computational Intelligence and Software Engineering.Changchun:IEEE,2010.
[6] Lee Wei-Hsun,Tsenga Shian-Shyong,Tsaia Sheng-Han.A knowledge based real-time travel time prediction system for urban network[J].Expert Systems with Appli-cations,2009,36(3):4239-4247.
[7] Zhou Guo-qing,Wang Lin-bing,Wang Dong,et al.Integration of GIS and data mining technology to enhance the pavement management decision making[J].Journal of Transportation Engineering,2010,136(4):332-341.
[8] 夏英,张俊,王国胤.时空关联规则挖掘算法及其在ITS中的应用[J].计算机科学,2011 38(9):173-176.Xia Ying,Zhang Jun,Wang Guo-yin.Spatio-temporal association rule mining algorithm and its application in intelligent transportation system[J].Compute Science,2011,38(9):173-176.
[9] Chen Shu-yan,Wang Wei,Zuylen van Henk.A comparison of outlier detection algorithms for ITS data[J].Expert Systems with Applications,2010,37(2):1169-1178.
[10] Agrawal R,Imielinski T,Swami A.Mining association rules between sets of items in Large databases[C]∥Proceeding of the ACMSIGMOD International Conference on Management of Data(ACMSIGMOD'93).Washington:IEEE,1993.
[11] 曾安平.多类关联规则生成算法[J].计算机应用,2012,32(8):2198-2201.Zeng An-ping,Muti-class association rule generation algorithm[J].Journal of computer applications,2012,32 (8):2198-2201.
[12] 夏英.智能交通系统中的时空数据分析关键技术研究[D].成都:西南交通大学计算机与通信工程学院,2012
[13] Pawlak Z.Rough sets[J].International Journal of Parallel Programming,1982,11(5):341-356.
[14] 王国胤,姚一豫,于洪.粗糙集理论与用研究综述[J].计算机学报,2009,32(7):1229-1246.Wang Guo-yin,Yao Yi-yu,Yu Hong.A survey on rough set theory and applications[J].Chinese Journal of Computers,2009,32(7):1229-1246.
[15] 王学恩,韩崇昭,韩德强,等.粗糙集研究综述[J].控制工程,2013,20(1):1-8.Wang Xue-en,Han Chong-zhao,Han De-qiang,et al.A survey of rough sets theory[J].Control Engineering of China,2013,20(1):1-8.
[16] Agrawal R,Srikant R.Fast algorithms for mining association rules[C]∥20th International Conference on Very Large Databases.San Francisco:IEEE,1994.
[17] 唐建国,谭明术.粗糙集理论中的求核和约简控制与决策[J].控制与决策,2003,18(4):449-452.Tang Jian-guo,Tan Ming-shu.On finding core and reduction in rough set theory[J].Control and Decision,2003,18(4):449-452.
[18] 程岩,黄梯云.信息系统中一种面向粗糙集的数据挖掘方法[J].情报学报,2001,20(1):90-99.Cheng Yan,Huang Ti-yun.A method of rough-set oriented data mining in information system[J].Journal of The China Society For Scientific and Technical Information,2001,20(1):90-99.
[19] 邸书灵,陈娜,马新娜.回归分析在关联规则挖掘中的应用研究[J].微计算机信息,2008,24(1/2/3): 171-172.Di Shu-ling,Chen Na,Ma Xin-na.Regression analysis and application in association rules mining[J].Microcomputer Information,2008,24(1/2/3):171-172.
猜你喜欢
舰船电子工程(2022年4期)2022-05-11
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
测控技术(2018年11期)2018-12-07
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
计算机与数字工程(2016年11期)2016-12-13
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
电测与仪表(2015年13期)2015-04-09
