
基于多层运动历史图像的飞行时间相机人体运动识别
2014-05-30 11:41张旭东胡良梅段琳琳
电子与信息学报 2014年5期
张旭东 杨 静 胡良梅 段琳琳
基于多层运动历史图像的飞行时间相机人体运动识别
张旭东*杨 静 胡良梅 段琳琳
(合肥工业大学计算机与信息学院 合肥 230009)
该文利用飞行时间(Time-Of-Fligh, TOF)相机提供的距离图像,在运动历史图像的基础上提出一种基于多层运动历史图像的人体运动识别方法。计算距离轮廓序列的运动能量图作为整体运动信息,同时根据距离变化量,计算前向、后向的多层运动历史图像作为局部运动信息,共同组成多层运动历史图像。为了解决Hu矩对不连续或具有噪声的形状较为敏感的问题,引入R变换对每层运动历史图像进行特征提取,串联形成特征向量送入SVM进行分类识别。实验结果表明,该识别方法可以有效识别人体运动。
人体运动识别;距离图像;多层运动历史图像;R变换
1 引言
人体运动识别是计算机视觉领域的一个重要研究课题,在视频监控、虚拟现实、人机交互等方面有广阔的应用前景。基于视频的人体运动识别的关键是如何从视频中提取可靠的特征表征人体动作。利用2D相机获取运动人体信息是过去几十年的研究重点。然而,2D相机自身的局限性使已有的2D相机运动识别方法[1]仅适用于运动平行于相机的情况,由于人体运动从本质上来说是3D的,距离信息的丢失使2D相机的运动表征方法识别能力大大降低。同时,2D相机运动识别易受光照和人体肤色等的影响。
随着相机和视频技术的发展,可以采用基于飞行时间(Time-Of-Flight, TOF)的3D相机[2]获取具有3维信息的距离图像。距离图像可以提供垂直于相机的运动信息,以较小的计算代价更加精确地描述和识别人体运动[3]。这样,由于2D相机将3维运动投影到2维图像平面上而产生的距离模糊就不复存在了。

本文方法归属上述3种方法中的第2种。利用TOF相机的距离信息,结合传统MHI和文献[11]的3DMHI,提出多层运动历史图像(Multi-Layered Motion History Images, MLMHI)的人体运动描述方法。MLMHI由运动能量图和前向、后向多层运动历史图像组成,包含了沿着距离方向变化的运动历史,能够体现运动的整体信息和局部信息,从而更加精确地描述人体运动。然后引入R变换对每层运动历史图像进行特征提取,串联形成特征向量送入SVM分类器中进行分类。
2 运动人体检测
运动人体检测是人体运动识别的基础。受光照、阴影等影响,利用2D相机进行运动人体检测仍然是具有挑战性的工作。本文利用距离信息,结合背景差分法[13]进行运动人体检测,以克服上述缺点。具体表达式如式(1)所示:

式中为检测到的运动人体的距离图像;为当前帧的距离图像;为预先设定的距离阈值;为背景帧的距离图像。为了构造背景模型,假设背景是静止的,采用平均背景法。记录没有运动人体时的背景距离图像序列,计算多幅背景距离图像的平均值作为背景距离图像。图1所示为提取出的运动人体的距离轮廓图像,这里取1.2。
3 多层运动历史图像及R变换
3.1 传统运动历史图像
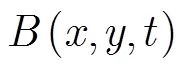
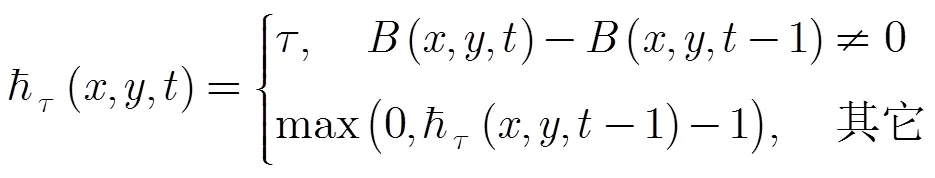
3.2 多层运动历史图像


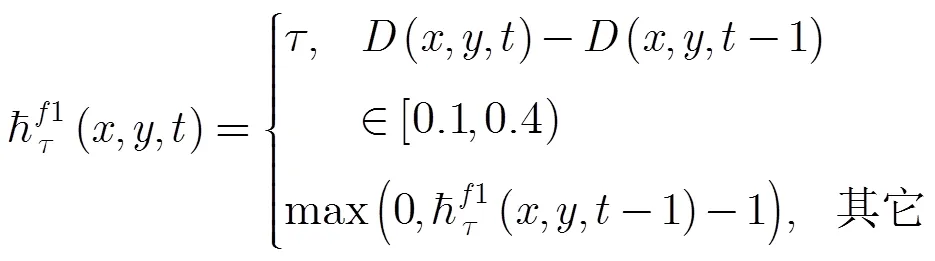
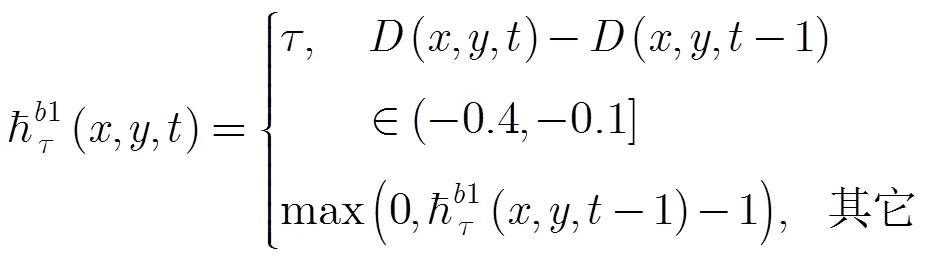
3.3 R变换
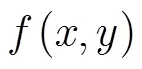
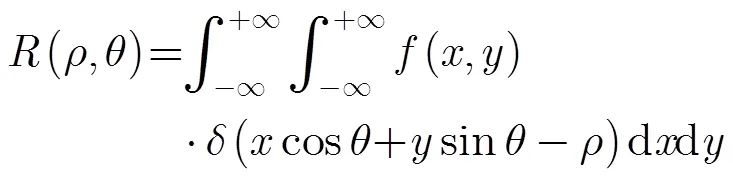

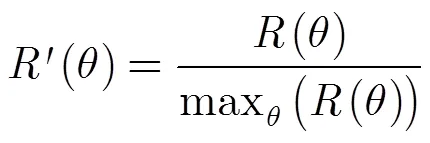
文献[15]验证了在标准大小的图像中,R变换具有平移和尺度不变性。对每层MLMHI进行R变换,得到180维的特征向量。这样,每个运动序列共得到900维的特征向量。
4 实验结果与分析
本文分别在自己建立的数据库与MSR Daily 3D运动数据库[12]上进行了实验并与其他方法进行了比较。采用支持向量机[16]进行运动数据的训练与测试。实验中使用LibSVM工具包,并且分别选用线性核函数与RBF核函数。同时采用10次10倍交叉验证法,即数据被随机划分为10份,轮流将其中9份作为训练数据,1份作为测试数据,取这10次结果的平均值作为这次划分的结果,再将这种随机划分做10次,取10次划分的实验结果平均值作为最终的识别率。
4.1自建的运动数据库对比实验
本文利用基于TOF原理的PMD相机[17,18]建立自己的数据库。数据库中包含以下6种动作:喝水(drink)、鼓掌(clap),坐下(sd),起立(su),走近(come),走远(go)。如图2所示,所有动作都垂直朝向PMD相机。每种动作由10个人分别完成,每人做15遍。PMD相机帧率为25 fps,每个运动序列约为75帧。实验中,时间窗口长度选择70帧。
4.1.1 3DMHI分类结果 文献[11]提出的3DMHI包括MHI,前向运动历史fDMHI和后向运动历史bDMHI。在本文数据库上进行实验,图3所示为喝水动作的3DMHI及其R变换。图4所示为线性核函数的识别结果,可以看到,3DMHI+R变换的平均识别率比3DMHI+Hu矩的平均识别率高,R变换的引入在一定程度上提高了识别率。
4.1.2 MLMHI分类结果 图5所示为喝水动作的MLMHI。从图中可以看出,在运动历史的距离变化量上进行分层可以更好地表征运动的3维特性,既能突出其在距离方向上变化量较小的局部信息,又能体现其距离变化较大的局部信息。利用线性核函数的识别结果如图6所示。表1为3DMHI和MLMHI两种方法在不同核函数下的识别结果对比。从表1可以看到,本文提出的MLMHI比3DMHI识别率有明显的提高,识别效果更好。

图2 数据库中的6种运动

表1 MLMHI与3DMHI的对比(%)
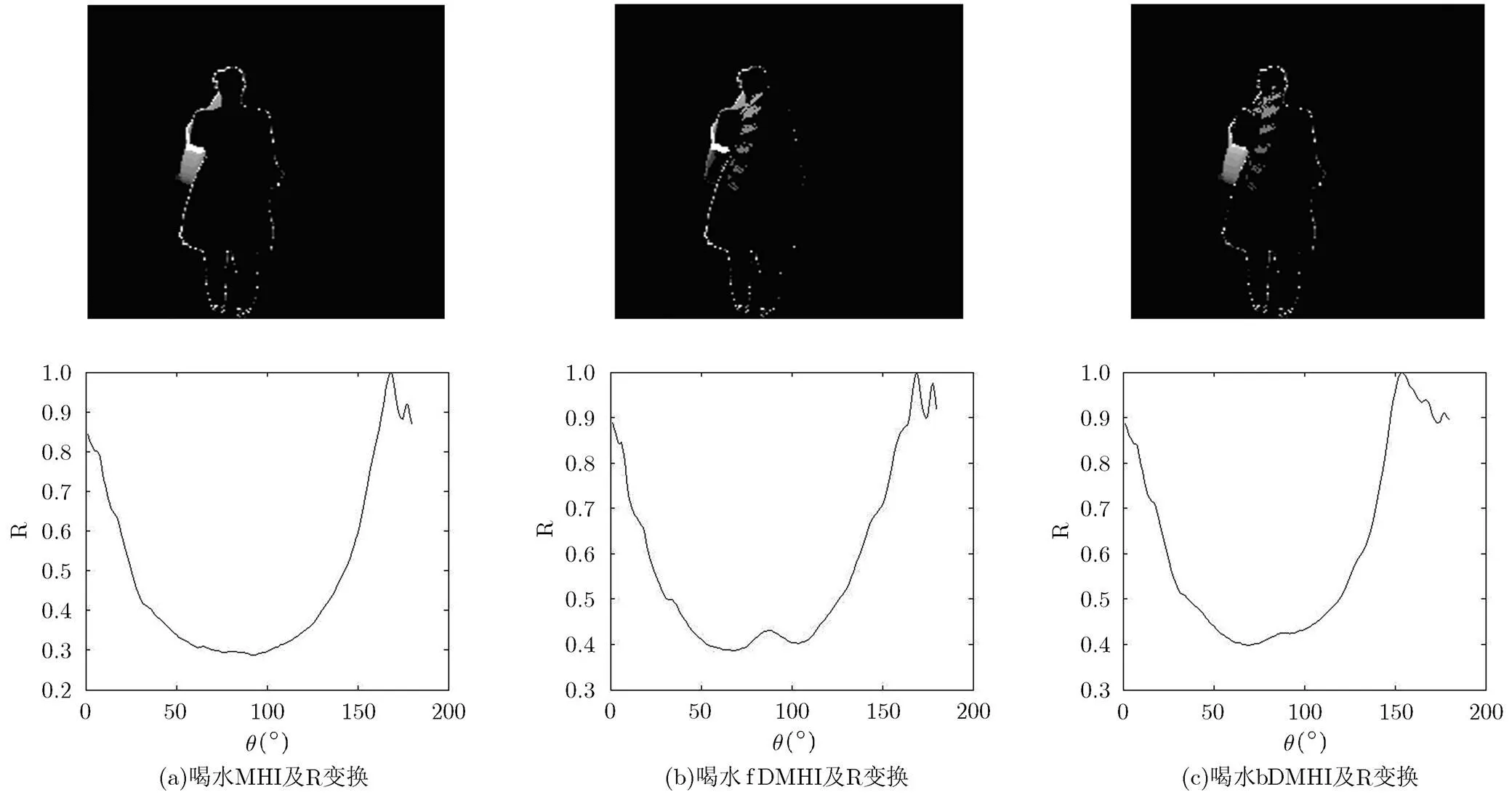
图3 喝水动作的3DMHI及R变换示意图

图4 3DMHI在线性核函数下识别结果

图5 喝水动作的MLMHI 从左到右依次为MEI,,,,

图6 MLMHI在线性核函数下的识别结果
4.2 MSR Daily 3D运动数据库对比实验
MSR Daily 3D运动数据库是由微软研究小组用Kinect相机建立的数据库。共包含16种运动:“drink”,“eat”,“read book”,“call cellphone”,“write on a paper”,“use laptop”,“use vacuum cleaner”,“cheer up”,“sit still”,“toss paper”,“play game”,“lay down”,“walk”,“play guitar”,“stand up”,“sit down”。每种运动由10个人完成,每人做2遍:一遍站立完成,一遍坐在沙发上完成,涵盖了起居室可能发生的日常行为。数据库中已经用距离阈值法去除了复杂的背景。
由于数据库中的每种运动视频帧数从50到300不等,为了得到最佳的时间窗口长度,在每种运动中选取帧数为80到300的序列分别进行实验。若视频中的帧数小于所选帧数,则选择其视频中的全部帧。在不同时间窗口长度下的识别率如图7所示,由图7可知在帧数为270左右时识别效果最佳,其分类混淆矩阵如图8所示,平均识别率为83.125%。由实验可知,对于不同的数据库,运动识别率有所不同,本文建立的数据库较为简单,只包含了6种动作,因此识别率相较于MSR Daily 3D运动数据库要高。
为了验证本文方法对哪类动作更有效,根据前后距离变化大小将MSR Daily 3D运动数据库中的动作分为AS1和AS2两类,分别对其进行识别,选择时间窗口长度为270时,在R变换和线性核函数下的分类混淆矩阵如图9和图10所示。本文方法对“lay down”和“walk”等前后距离变化较大的动作识别率较高,而对“sit sitll”,“play game”等距离几乎没有变化的动作识别率略差,这是由于前后距离变化较小时不能获取更多有用的距离信息。
最后,将本文的识别结果与使用MSR Daily 3D运动数据库的其它方法进行了对比,并且将文献[11]提出的3DMHI在此数据库上进行了实验,如表2所示。本文方法比文献[11]的3DMHI方法识别率有明显的提高。文献[4]和文献[7]用关节点位置作为特征,受噪声的影响和人体与其它物体交互的影响较大,平均识别率较低。文献[12]同样采用关节点位置作为特征,但考虑到数据库中有多种运动是人体与环境中其它物体的交互,又设计了基于关节点周围3D点云的局部占有信息(LOP)作为特征,同时提出了傅里叶时序金字塔FTP特征描述方法。由于文献[12]对人物交互做了单独处理,使得关节点位置特征与LOP的联合特征平均识别率高达85.75%。对比可知,本文方法优于单独使用关节点位置的方法,但识别率略低于文献[12]中联合特征的方法。

图7 MLMHI在不同时间窗口长度下的识别率
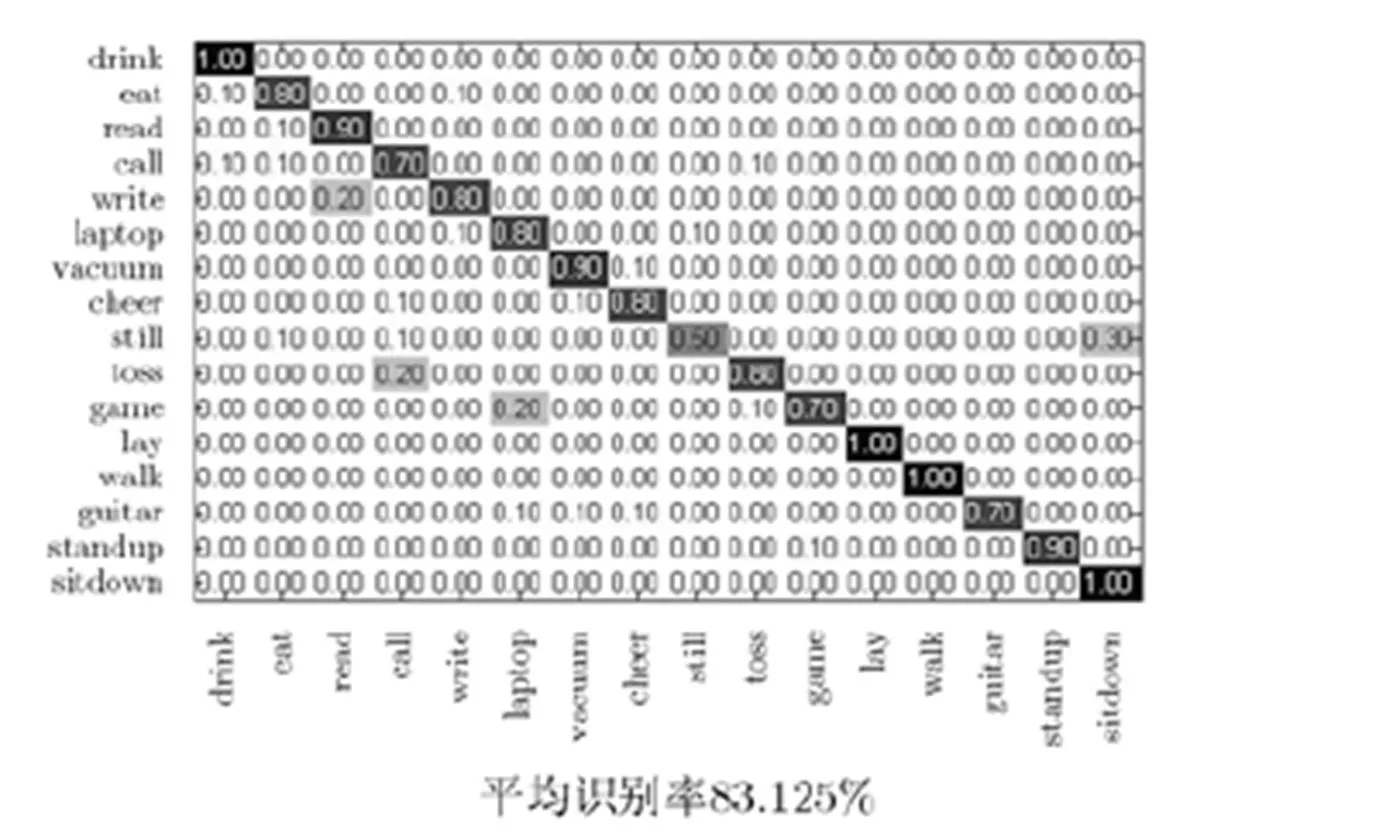
图8 帧数为270时R+线性核函数的分类混淆矩阵

图9 AS1分类混淆矩阵

图10 AS2分类混淆矩阵
表2本文方法与各方法的识别率(%)

方法LOP特征[12]DTW[4]关节点位置特征[12]NBNN[7]3DMHI+Hu[11]FTPF[12]LOP+关节点位置特征[12]MLMHI+R(本文方法) 识别率42.554.068.07073.1378.085.7583.12
5 结束语
本文对利用TOF相机提供的距离图像进行人体运动识别开展了研究。在传统运动历史图像的基础上,提出了多层运动历史图像的人体运动描述方法,多层运动历史图像由运动能量图、前向多层运动历史图像和后向多层运动历史图像组成。然后引入R变换对每层运动历史图像进行特征提取。分别在我们自建的数据库和MSR Daily 3D运动数据库上进行了实验。结果表明,本文提出的MLMHI及引入R变换进行特征提取的方法,优于同类方法及只使用关节点位置进行识别的方法,但略差于联合特征的方法。因此,将本文方法与关节点位置特征相结合,进一步提高识别率,是本文下一步的研究重点。
[1] Weinland D, Ronfard R, and Boyer E. A survey of vision-based methods for action representation, segmentation and recognition[J]., 2011, 115(2): 224-241.
[2] Lange R. 3D time-of-flight distance measurement with custom solid-state image sensors in CMOS/CCD- technology[D]. [Ph.D. dissertation], University of Siegen, 2000.
[3] Chen L, Wei H, and Ferryman J M. A survey of human motion analysis using depth imagery[J]., 2013, 34(15): 1995-2006.
[4] Müller M and Röder T. Motion templates for automatic classification and retrieval of motion capture data[C]. Proceedings of the 2006 ACM SIGGRAPH/Eurographics Symposium on Computer Animation. Eurographics Association, Switzerland, 2006: 137-146.
[5] Xia L, Chen C C, and Aggarwal J K. View invariant human action recognition using histograms of 3D joints[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, 2012: 20-27.
[6] Yang X and Tian Y L. Eigenjoints-based action recognition using naive-bayes-nearest-neighbor[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, 2012: 14-19.
[7] Seidenari L, Varano V, Berretti S,.. Weakly Aligned Multi-part Bag-of-Poses for Action Recognition from Depth Cameras[M]. Springer Berlin Heidelberg: New Trends in Image Analysis and Processing, 2013: 446-455.
[8] Shotton J, Sharp T, Kipman A,.. Real-time human pose recognition in parts from single depth images[J]., 2013, 56(1): 116-124.
[9] Li W, Zhang Z, and Liu Z. Action recognition based on a bag of 3D points[C]. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, 2010: 9-14.
[10] Yang X, Zhang C, and Tian Y L. Recognizing actions using depth motion maps-based histograms of oriented gradients[C]. Proceedings of the 20th ACM International Conference on Multimedia, New York, 2012: 1057-1060.
[11] Ni B, Wang G, and Moulin P. RGBD-HuDaAct: a color- depth video database for human daily activity recognition[C]. 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, 2012: 1147-1153.
[12] Wang J, Liu Z, Wu Y,.. Mining actionlet ensemble for action recognition with depth cameras[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, 2012: 1290-1297.
[13] Haritaoglu I, Harwood D, and Davis L S. W4: real-time surveillance of people and their activities[J]., 2000, 22(8): 809-830.
[14] Bobick A F and Davis J W. The recognition of human movement using temporal templates[J]., 2001, 23(3): 257-267.
[15] Wang Y, Huang K, and Tan T. Human activity recognition based on R transform[C]. IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, 2007: 1-8.
[16] 高隽. 人工神经网络原理及仿真实例[M]. 北京: 机械工业出版社, 2003: 76-86.
[17] Schwarte R. Smart Pixel-photonic Mixer Device (PMD)[C]. Proceedings of International Conference on Mechatronics and Machine Vision, 1998: 259-264.
[18] 张旭东, 沈玉亮, 胡良梅, 等. 改进的PMD距离图像超分辨率重建算法[J]. 中国图象图形学报, 2012, 17(4): 480-486.
Zhang X D, Shen Y L, Hu L M,.. Improved super- resolution reconstruction algorithm for PMD range image[J]., 2012, 17(4): 480-486.
张旭东: 男,1966年生,博士,教授,硕士生导师,研究方向为机器视觉、传感器技术、智能信息处理以及相关应用系统的开发.
杨 静: 女,1990年生,硕士生,研究方向为智能信息处理.
胡良梅: 女,1974年生,博士,副教授,硕士生导师,研究方向为信息融合、图像处理、图像理解、模式识别、智能信息处理.
Human Activity Recognition Using Multi-layered Motion HistoryImages with Time-Of-Fligh (TOF) Camera
Zhang Xu-dong Yang Jing Hu Liang-mei Duan Lin-lin
(,,230009,)
A new method extended from motion history image called Multi-Layered Mmotion History Images (MLMHI) is proposed to the representation and recognition of human activity using depth images provided by Time-Of-Fligh (TOF) camera. Firstly, the motion-energy image of the depth silhouettes is computed as the global motion information. Then, the forward-MLMHI and backward-MLMHI is computed as the local motion information based on the variable of depth. The global and local motion information constitute the MLMHI lastly. Since the Hu moments are sensitive to disjoint shapes and noise, R transform is employed to extract features from every layered-MHI and concatenated to form a feature vector. The feature vector is used as the input of Support Vector Machine (SVM) for recognition. Experimental results demonstrate the effectiveness of the proposed method.
Human activity recognition; Depth image; Multi-Layered Motion History Images (MLMHI); R transform
TP391
A
1009-5896(2014)05-1139-06
10.3724/SP.J.1146.2013.01003
张旭东 xudong@hfut.edu.cn
2013-07-10收到,2013-09-29改回
国家自然科学基金(61273237, 61271121)和安徽省自然科学基金(11040606M149)资助课题
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
基层中医药(2021年5期)2021-07-31
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
特别健康(2018年3期)2018-07-04
中国交通信息化(2018年3期)2018-06-13
军营文化天地(2017年6期)2017-06-28
