
一种基于频率的多核共享Cache替换算法
2014-05-30 11:41李成艳姚治成
电子与信息学报 2014年5期
方 娟 李成艳 王 帅 姚治成
一种基于频率的多核共享Cache替换算法
方 娟*李成艳 王 帅 姚治成
(北京工业大学计算机学院 北京 100124)
LRU替换算法在单核处理器中得到了广泛应用,而多核环境大都采用多核共享最后一级Cache(LLC)的策略,随着LLC容量和相联度的增加以及多核应用的工作集增大,LRU替换算法和理论最优替换算法之间的差距越来越大。该文提出了一种平均划分下基于频率的多核共享Cache替换算法(ALRU-F)。该算法将当前所需要的部分工作集保留在Cache内,逐出无用块,同时还提出了块粒度动态划分下基于频率的替换算法(BLRU-F)。该文提出的ALRU-F算法相比传统的LRU算法缺失率降低了26.59%, CPU每一时钟周期内所执行的指令数IPC(Instruction Per Clock)则提升了13.59%。在此基础上提出的块粒度动态划分下,基于频率的BLUR-F算法相比较传统的LRU算法性能提高更大,缺失率降低了33.72%,而IPC 则提升了16.59%。提出的两种算法在性能提升的同时,并没有明显地增加能耗。
多核处理器;共享Cache;划分;替换算法
1 引言
随着制造工艺的发展和体系结构的进步,单核环境已经无法满足人们对高性能计算的追求,片上多核(Chip Multi-Processor, CMP)已成为主流发展趋势。目前绝大多数的主流CMP处理器都使用私有一级(或一级和二级)Cache,共享二级(或三级) Cache的片上存储结构来提供快速的资源访问[1]。通过共享最后一级Cache结构,最大限度地提高了资源利用率,降低访问开销。有效地管理最后一级Cache将会提高各个核的利用率,同时提高各个核之间的公平性[2]。
LRU替换算法及其改进算法一直是单核处理器下的默认标准替换算法,该算法与其它算法相比能更好地提高命中率。但是最近的研究显示,多核系统中LLC呈现出更大容量及更高相联度的发展趋势,这使得LRU替换算法和理论最优替换算法之间的差距越来越大,尤其是Cache缺失次数严重增加[3, 4]。但是在多核条件下,LRU并没有将各个核之间的相互干扰以及各个核访问Cache的访问频率信息考虑在内[5],这使得多核下的Cache利用率越来越低。
针对LRU不适应多核环境的问题,学者们提出了很多改进策略,主要分为3个部分:路粒度的Cache划分[6,7],动态插入推举策略[8],以及改进的替换算法[9,10]。其中大部分研究集中体现在以下3个环节:信息的收集,策略的选取以及策略的实施。信息收集给出提高性能的关键突破点,策略的选取通过收集的信息给出提高性能方法,最后给出实施方案,通过实验验证策略的有效性。
本文主要探讨如何将Cache划分,Cache插入推举和Cache访问频率信息有效地结合起来,综合考虑各个方面去获得更好的性能提升。为了充分考虑各个核的访问模式差异,本文提出了基于频率的多核共享Cache替换算法ALRU-F;并在此基础上提出了块粒度动态划分下基于频率的替换算法BLRU-F。
2 平均划分下的基于频率的ALRU-F替换算法
2.1 算法评估模型
多核处理器的产生是人们追求高性能的最终结果,其性能可由式(1)得出,因此提高处理器性能可以从两方面出发,一是提高主频,另一个是提高CPU每一时钟周期内所执行的指令数IPC (Instruction Per Clock)。
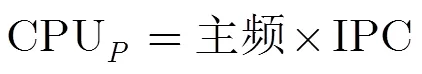



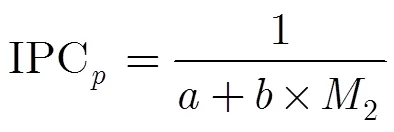
2.2 Cache划分策略
本文采用平均划分策略,即将Cache路平均分划分给每个核,保证每个核拥有属于自己的Cache路空间。
2.3 插入推举策略
在LRU替换算法中,Cache缺失时,选择最近最久未使用的Cache块逐出。由于一级Cache的过滤,0重复利用块所占的比例很大,几乎可以达到50%[11],再加上相联度的提高,死时间会越来越长,严重影响了Cache空间的有效利用率。在ALRU-F中,使用插入/推举策略去平衡无用块长期占用Cache空间这一问题。如图1所示,Cache含有16列,逻辑上从左到右优先级逐渐降低。本文算法中,Cache块的优先级就是访问的顺序。
图1(a), 1(b)为传统LRU和学者提出的SIP (Speculative Insertion Policy)的逐出策略。图1(c)假设O为综合考虑各种因素选出的逐出块。其中是综合考虑LRU信息以及Cache访问信息提出的候选列数。越大考虑的LRU信息越少,为0,则相当于LRU替换算法。
2.4 基于访问频率的策略
文献[11]提出,访问频率也是Cache访问的重要参考信息,因此将Cache访问频率信息考虑在内,通过一个计数器来记录每个Cache块的访问频率信息,Cache块每次被访问相应的计数器进行自增操作。针对每一组维护个候选块,在进行Cache替换时,将从个候选块中进行选择。
2.5 ALRU-F替换算法
综合以上介绍的基于访问频率的策略,基于Cache划分的策略以及插入推举策略,提出多核Cache平均划分下基于频率的Cache替换算法ALRU-F流程如下:

图1 插入策略对比
(1)初始化
(b)当处理器核core发出一个L2 Cache的访问请求时,根据所要访问的地址确定地址所映射的Cache组和core的列划分信息表确定属于core的Cache存储单元集合,并在存储单元集合中判断是否命中:如果命中,存取Cache存储单元,命中单元即为请求所要访问的单元,执行步骤(3);否则执行步骤(2);
(2)Cache替换
(a)根据Cache组对应的候选路信息M,核core的列划分信息选择逐出单元:
如果候选路信息M对应的存储单元存在属于core的存储单元C,则C为逐出单元,继续执行步骤(2)(b);否则选择候选路信息M中访问频率最低的存储单元作为逐出单元;
(b)将要存取的数据块插入到Cache组中优先级为的存储单元中,更新的访问频率信息,执行步骤(4);
(3) 提升优先级
(a)如果命中的存储单元属于候选路M,则将命中的存储单元的优先级提升一级;
(b)将命中的Cache存储单元的优先级提升为最近访问的列的优先级;
(4)回溯阶段:程序运行时间后,如果程序没有结束,清除所有Cache存储单元访问频率信息表,并返回步骤(1)(b);否则,输出运行结果,分析缺失率、功耗以及整体IPC。
3 块粒度Cache划分下基于频率的BLRU-F算法
ALRU-F算法是基于Cache列的平均划分,粒度较大,本文在此基础上提出基于Cache块的划分BLRU-F,更细粒度的划分,旨在提高各个核对共享Cache的利用率,尽可能地降低缺失率,提高性能。
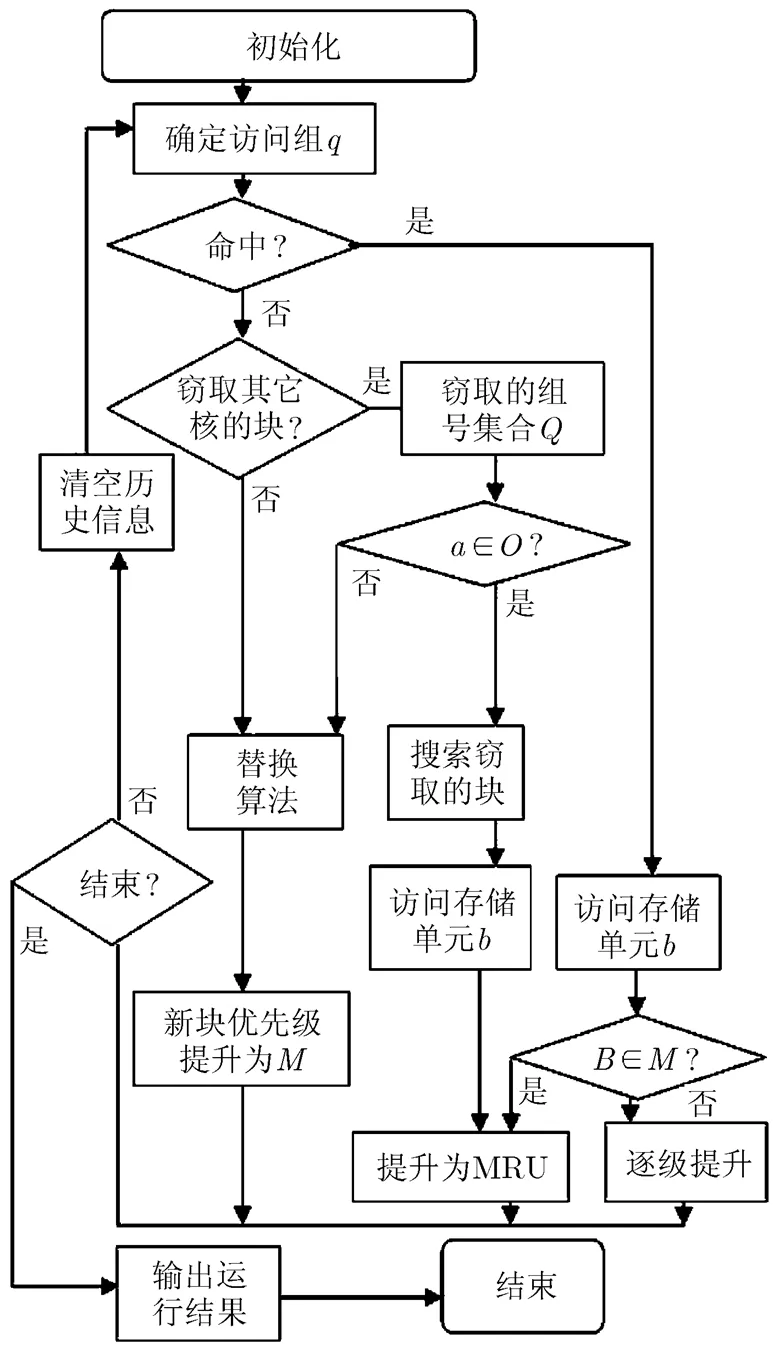
图2 BLFU-F算法访问存储过程流程图
当出现Cache缺失时,若该核的Cache列未命中,则判断核core是否窃取了其它核的列;如果核core窃取了核core的列,根据路窃取信息表确定被窃取的核core的存储单元对应的组号集合;若属于,搜索组中核core对应的存储单元;判断是否命中;若命中,存取Cache单元,继续步骤(4);若不属于并且未命中,执行步骤(2);若核core未窃取其它核的列,执行步骤(2);
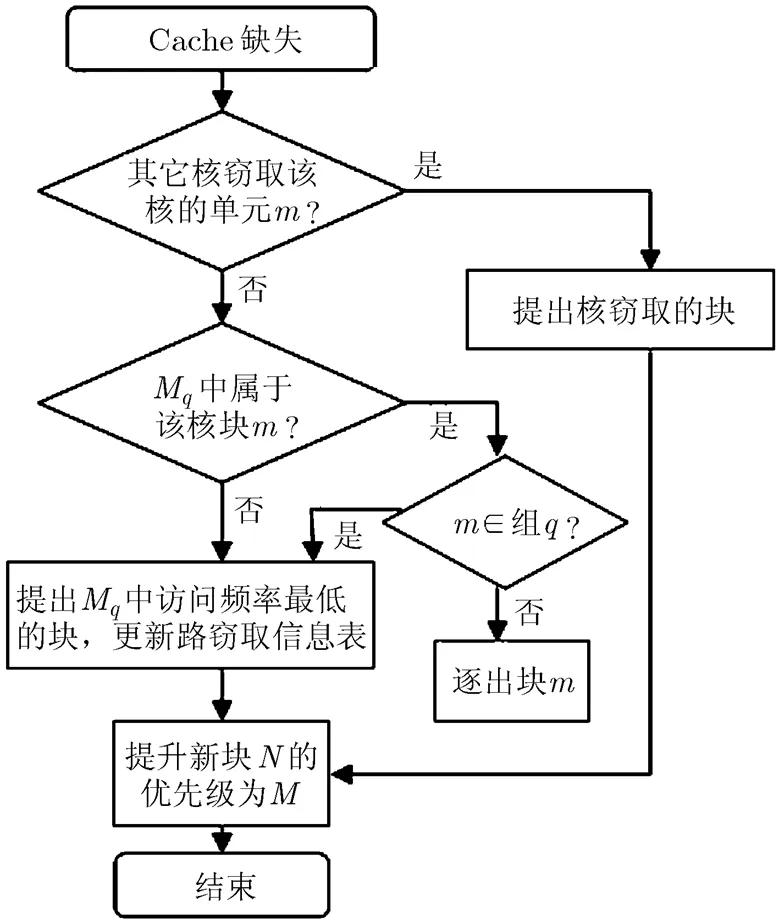
图3 BLFU-F算法Cache缺失流程图
在进行逐出单元的选择时,判断是否有核core窃取了核core的存储单元;如果存在core窃取了核core的存储单元,且窃取的是组中的Cache存储单元,将组中所对应的存储单元选为逐出单元,更新路窃取信息表,执行步骤(2)(b);
如果窃取的不是组中的Cache,或不存在core窃取核core的存储单元,那么如果候选路信息M对应的存储单元属于core的存储单元C,则C为逐出单元,继续执行步骤(2)(b);否则根据路窃取信息表,选择候选路信息M中访问频率最低的单元逐出,更新路窃取信息,执行步骤(2)(b);其余步骤与FLRU-A相同。
4 实验结果及分析
4.1 实验环境
实验使用的系统模拟器为Virtutech Simics,它是一个灵活的全系统模拟器,可以模拟多种目标平台的体系结构。GEMS(General Execution-driven Multi-processor Simulator)是Virtutech Simics的一组模块,它使Virtutech Simics能更详细地模拟多处理器系统。实验选取了4核,8核,16核,并分别选取了8路,16路,32路,64路进行了实验。表1是实验环境配置。

表1 实验环境配置
4.2 实验结果
实验共模拟了3个替换策略:ALRU-F, BLRU- F和LRU。选取了SpecOMP[12]的wupwise_m, swim_m, grid_m, applu_m, equake_m, apsi_m, fma3d_m, art_m作为测试程序,分别对比了各个算法在性能、功耗和二级Cache缺失率3方面的效果。
图4是4核下缺失率,IPC和功耗变化对比图。图4(a)给出了缺失率对比,由图得出,ALRU与LRU相比缺失率降低了9.52%。
图5是8核下缺失率,IPC和功耗变化对比图。从图5(a) 8核下缺失率对比可得,整体缺失次数有所降低,ALRU-F与LRU相比平均价低了14.04%;BLRU-F与LRU相比平均降低了26.41%;图5(b)是8核下IPC对比图,可得出IPC提升7.81%, ALRU-F与LRU相比平均提升了12.5%。
图6是16核下缺失率,IPC和功耗情况变化对比图。如图6(a)可以得出,BLRU-F与ALRU-F相比缺失率平均降低了20.32%,与LRU相比缺失率降低了32.88%。图6(b)给出了16核下IPC对比,BLRU-F相比ALRU-F相比较IPC平均提升了3.26%,与LRU相比IPC平均提升了14.46%;图6(c)展示的是16核下功耗对比图,由图6看出,功耗基本没有变化。
本文提出的BLRU-F改进了划分策略,在列划分的基础上,根据多核访存需求变化以块为单位进行重分配,并且在Cache替换时通过逐出的方式回收Cache块资源。这种基于列划分的块粒度的动态重分配,既节省了开销又达到了细粒度的动态划分。
5 LLC共享时的算法效率分析
本文提出的两种算法都采用了相应的划分策略,这主要是针对多核竞争访问最后一级共享Cache的情形,将Cache空间进行划分,消除竞争带来的性能降低问题。尤其是第2种算法BLRU-F采用了更细粒度的划分,同时巧妙利用块窃取方法来平衡各个核的访问差异,使得各个核更加充分地利用有限的Cache资源。算法都考虑到了Cache路的访问频率信息,将该信息与LRU信息相结合,采用了插入/推举策略,尽量保留当前工作集在Cache空间,消除了多核环境下Cache工作集大带来的Cache抖动现象,以及研究表明的0重复利用Cache块占比相当大带来的Cache空间浪费,更加有利于多核环境下的Cache命中率的提升。

图4 4核下LRU, ALRU-F和BLRU-F效果对比图

图5 8核下LRU, ALRU-F和BLRU-F效果对比图

图6 16核LRU, ALRU-F和BLRU-F效果对比图
6 结束语
本文综合考虑Cache划分,访问频率信息以及多核之间的干扰,提出了一个改进的多核共享Cache替换算法。该算法结合当前的研究热点Cache划分,将Cache访问频率信息作为替换块选择的重要参考,同时将LRU信息作为关键参考信息,采用Cache路插入推举策略,最终选择最合适的替换块进行替换。同时,算法还实现了块粒度的动态重分配。实验结果表明,这种改进的Cache替换算法能够很好地提高命中率,降低运行时间。下一步工作将考虑两个方面,一方面改进Cache划分策略,采取更有效的划分方案,另一方面将当前多核研究的另一个热点,Cache路预测技术与当前算法相结合,并进行改进,以获得更好的效果。
[1] Hammond L, Nayfeh B A, and Olukotun K. A single-chip multiprocessor[J]., 1997, 30(9): 79-85.
[2] HuangZhi-bin, Zhu Ming-fa, and Xiao Li-min. Analysis of allocation deviation in multi-core shared cache pseudo-partition[C]. Proceedings of 2011 International Conference on Electronic Engineering, Communication and Management, Beijing, China, 2012:463-470.
[3] Mazen Kharbutli and Rami Sheikh. LACS: a locality-aware cost-sensitive cache replacement algorithm[J]., 2013, 6(3): 1-29.
[4] Zhang Xi and Li Chong-min. A cache replacement policy using adaptive insertion and re-reference prediction[C]. International Symposium on Computer Architecture and High Performance Computing, Petrópolis, Brazil, 2010: 95-102.
[5] Ding Shan and Li Yuan-yuan. LRU2-MRU collaborative cache replacement algorithm on multi-core system[C]. Computer Science and Automation Engineering(CASE2012), Zhangjiajie, China, 2012: 395-398.
[6] Huang Zhi-bin, Zhu Ming-fa, and Xiao Li-min. LvtPPP: live-time protected pseudopartitioning of multicore shared caches[J].2013, 24(8): 1622-1632.
[7] Sui Xiu-feng, Wu Jun-min, Chen Guo-liang,.. Augmenting cache partitioning with thread-aware insertion/promotion policies to manage shared caches[C]. Proceedings of the 7th ACM International Conference on Computing Frontiers, Bertinoro, Italy, 2010: 79-80.
[8] Kron J D, Prumo B, and Loh G H. Double-DIP: augmenting DIP with adaptive promotion policies to manage shared L2 caches[C]. Proceedings of the Workshop on Chip Multiprocessor Memory Systems and Interconnects, Beijing, China, 2008: 1-9.
[9] Kharbutli M and Solihin Y. Counter-based cache replacement algorithms[C]. IEEE International Conference on Computer Design, San Jose, USA, 2005: 61-68.
[10] John T and Ademola T. Dynamicly self-adjusting cache replacement algorithm[J]., 2013, 6(1): 25-34.
[11] Qureshi MK and Patt YN. Utility-based cache partitioning: alow-overhead, high-performance, runtime mechanism to partition shared caches[C].Proceedings of the 39th Annual IEEE/ACM International Symposium on Micro Architecture, Washington DC, USA, 2006: 423-432.
[12] Aslot V,Domeika M J, Eigenmann R,.. SpecOMP: a new benchmark suite for measuring parallel computer performance[C]. WOMPAT’01 Proceedings of the International Workshop on OpenMP Applications and Tools: OpenMP Shared Memory Parallel Programming, London, UK, 2001: 1-10.
方 娟: 女,1973年生,副教授,研究方向为计算机系统结构、多核计算.
李成艳: 女,1988年生,硕士生,研究方向为多核计算.
王 帅: 男,1986年生,硕士生,研究方向为多核计算.
姚治成: 男,1989年生,硕士生,研究方向为多核计算.
A Frequency Based Cache Replacement Algorithm with Partition of CMPs
Fang Juan Li Cheng-yan Wang Shuai Yao Zhi-cheng
(,,100124,)
LRU has been widely used in single-core processor, while Chip Multi-Processors (CMP) employ a large Last-Level Cache (LLC) which is shared among the multiple cores. With the increasement of the LLC capacity and associativity, and the grows of working set of multicore’s applications, the performance gap between the LRU and the theoretical optimal replacement algorithms gets wider and wider. This paper proposes an Average partition LRU algorithm based on Frequency (ALRU-F). The algorithm has maintained the working set at Cache and drive out the ignore block. Also, a Cache line stealing strategy is proposed to realize a Block partition LRU replacement algorithm based on Frequency (BLRU-F). The result of experiments shows that comparing to the traditional LRU algorithm, the proposed ALRU-F algorithm reduces the miss rate by 26.59%, and improves the Instruction Per Clock (IPC) by 13.59 % with little change of power consumption. Comparing to the traditional LRU and BLRU-F algorithms, the proposed algorithm reduces the Cache miss rate by 33.72% and improves the IPC by 16.59%.
Chip Multi-Processors (CMP); Shared Cache; Partition; Replacement algorithm
TP393
A
1009-5896(2014)06-1229-06
10.3724/SP.J.1146.2013.01030
方娟 fangjuan@bjut.edu.cn
2013-07-16收到,2013-11-07改回
国家自然科学基金(61202076 )和北京市教委科技计划面上项目(KM201210005022)资助课题
猜你喜欢
现代应用物理(2022年1期)2022-05-17
粉末冶金技术(2021年3期)2021-07-28
科技创新与应用(2020年29期)2020-10-20
天天爱科学(2020年6期)2020-09-10
软件导刊(2019年4期)2019-06-09
科教导刊·电子版(2018年2期)2018-06-05
探索科学(2017年4期)2017-05-04
系统工程与电子技术(2016年12期)2016-12-24
浙江大学学报(工学版)(2016年11期)2016-06-05
应用海洋学学报(2015年3期)2015-11-22
