
基于服务力向量的发布/订阅自动发现算法
2014-06-06 10:46翟海波
计算机工程 2014年9期
翟海波,庄 毅,霍 瑛
(南京航空航天大学计算机科学与技术学院,南京210016)
基于服务力向量的发布/订阅自动发现算法
翟海波,庄 毅,霍 瑛
(南京航空航天大学计算机科学与技术学院,南京210016)
由于SDPBloom自动发现算法无法预先在参与者发现阶段对端点QoS策略的兼容性进行判断,使得各节点和网络中均出现大量QoS不兼容的端点信息,从而消耗过多的内存和网络资源。为解决该问题,提出一种基于服务力向量(SAV)的发布/订阅自动发现算法,利用布隆过滤器向量和SAV对端点主题名、主题类型以及QoS策略进行匹配,以减少不必要信息的传输和存储。实验结果表明,与SDP_ADA和SDPBloom算法相比,该算法具有更低的网络负载和内存消耗。
服务力向量;发布/订阅;数据分发服务;自动发现算法;布隆过滤器;服务质量
1 概述
数据分发服务(Data Distribution Service, DDS)是一种以数据为中心的高性能网络数据交换中间件。国际对象管理组织(Object Management Group,OMG)先后在 2004年、2005年、2007年颁布了数据分发服务 Version 1.0[1], Version1.1[2]以及 Version1.2[3]规范。该规范为DDS中间件的设计提供了指南,以及为实现不同平台之间的信息交互提供了标准。DDS实体通信采用发布-订阅通信模式,该模式实现了时间、空间和同步关系3个方面的完全解耦,使得它成为现代分布式计算环境的理想选择[4]。目前,该技术已经被成功应用到航空控制系统、海军作战管理系统、自动股票交易系统、工业控制系统以及监测控制与数据采集系统[5]中。
为了支持在分布式系统中各节点能够动态加入和退出且不影响其他节点功能的特性,DDS中参与通信的所有实体间需要能够动态地发现对方,然后根据主题、数据类型以及服务质量(Quality of Service,QoS)策略进行匹配,只有匹配成功后才会建立通信连接[6-7]。本文重点研究和分析了发布/订阅自动发现过程,并提出一种新的自动发现算法。
2 相关研究工作
针对动态自动发现过程,国内外已相继提出大量自动发现算法。该动态发现过程既可以在网络层上完成,也可以在更高的应用层上完成。在网络层上完成该过程的主要有基于SLP,SSDP以及DNSSD等协议的自动发现算法[8]。近年来,更多的自动发现过程都是在应用层完成的,如文献[8]提出的一种基于普适发现协议(Pervasive Discovery Protocol, PDP)的自动发现算法,该算法集成了“推”和“拉”2种模型去发现对方。2010年 RTI(Real-time Innovations)根据RTPS标准2.1版本[9]给出了一种基于简单发现协议(Simple Discovery Protocol,SDP)的自动发现算法[10]。为了方便后续说明,本文用SDP_ADA(Simple Discovery Protocol Automatic Discovery Algorithms)表示该算法。SDP_ADA算法执行过程分为2个阶段:简单参与者发现阶段和简单端点发现阶段。简单参与者发现阶段实现参与者之间的相互学习,简单端点发现阶段实现数据写入者和数据读取者的信息匹配。文献[5]指出SDP_ ADA算法只适合中小型网络,存在可扩展性差等问题,并提出一种基于布隆过滤器的自动发现算法SDPBloom。该算法依然遵循SDP协议的阶段模型,但是该算法在参与者发现阶段将各个参与者包含的端点描述信息放到布隆过滤器向量(Bloom Filter Vector,BFV)中并通过参与者数据包一起发给其他远程参与者,这些端点描述信息主要包括端点的主题相关信息,但是不包括 QoS信息。由于SDPBloom算法将端点匹配部分操作提前,即在参与者阶段完成,因此一旦发现本地端点描述信息与远程端点信息不匹配,就不需要再将本地端点具体信息发送给远程参与者,从而减少网络负载和内存消耗。
综上所述,DDS是一种以数据为中心的网络中间件,一个很重要的特点是有丰富的QoS策略支持。然而,基于PDP协议的自动发现算法是一种完全分布式的服务发现协议,更多的适用于以服务为中心的移动自组网络。尽管SDP_ADA算法可实现DDS中发布-订阅者的自动发现,但如文献[5]所述SDP_ ADA自动发现算法的可扩展性较差,只适用于中小型网络。然而,SDPBloom算法虽然在可扩展性方面做了一些改进,但是SDPBloom算法在参与者发现阶段完全不考虑QoS,会带来一些不必要信息的传送,造成网络负载的增加。
3 ISDPBQ_ADA算法
数据分发服务(DDS)中发布/订阅通信双方除了需要主题匹配外,QoS的相互兼容也是双方建立通信的必要条件之一。针对SDPBloom算法无法在参与者发现阶段对端点QoS的兼容性进行判断所引起的较高网络负载和内存消耗,在该算法的基础上提出一种新的算法:ISDPBQ_ADA,该算法能够在参与者发现阶段对端点QoS的兼容性进行粗判,从而进一步减少网络负载和内存消耗。
3.1 布隆过滤器
Bloom Filter[11]是由Bloom在1970年提出的二进制向量数据结构,是一种节省空间的高效数据表示和查询过滤器。它利用位数组简洁地表示一个集合,并能以很高的概率判断一个元素是否属于这个集合。Bloom Filter利用K个相互独立的哈希函数Hi(key)(其中,0<i≤k),将集合S={x1,x2,…,xn}中的元素映射到一个m位的数组向量BFV中;开始时BFV中的元素被初始化为0,当Hi(xj)=Ri(0<i≤k,0≤Ri≤m-1)时,那么BFV中第Ri位被置为1[12]。自从Bloom在20世纪70年代提出 Bloom Filter后,Bloom Filter就被广泛用于拼写检查和数据库系统中,主要应用于能够容忍低错误率的场合。
与经典哈希函数相比,Bloom Filter最大的优势是它的空间效率,另一方面,由于Bloom Filter不用处理碰撞,无论集合中元素有多少,也无论多少集合元素已经加入到位向量中,Bloom Filter在增加或查找集合元素时所用的时间都为哈希函数的计算时间。但是,Bloom Filter在判断某一元素Xi是否属于集合S时可能会把不属于S中的元素误认为属于S,这种情况称为误报率(False Positive, FP),因此不适合那些零错误的应用场合。在标准的Bloom Filter中对于使用k个哈希函数,向m位长的Bloom Filter中装入n个元素后,误报率可以由式(1)[5]估算得到:
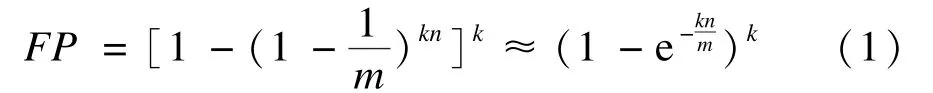
3.2 服务力向量
在ISDPBQ_ADA算法的设计过程中,为了能够在参与者发现阶段对端点QoS的兼容性进行粗判,本文引入服务力(Service Ability,SA)的概念。
定义1 在Request vs Offered(RxO)模式中,只有当offered类型值大于等于requested类型值,请求方与提供方才能建立通信连接。将[requested类型值,offered类型值]区间长度定义为服务力,其中, SA越大表示服务力越强。
根据定义1,将所有需要满足RxO模式的QoS策略的服务力SA所构成的集合定义为服务力向量(Service Ability Vector,SAV)。文献[1-3]指出需要满足RxO的QoS策略少于16种,因此,只需给SAV分配2个字节(16位)的大小空间,每一位标记端点相关QoS服务力,初始化时将这2个字节的16位全部置为0。然后,同样定义一个哈希函数并给各个需要满足RxO模式的QoS策略赋予唯一的关键值。当用户试图减弱端点某些QoS时,即对于发布方来说意味着offered类型值减小,对于订阅方来说意味着requested类型值增大,将这些QoS对应的哈希地址置为1;同理,当用户试图加强端点某些QoS时,即对于发布方来说意味着offered类型值增大,对于订阅方来说意味着requested类型值减小,就将这些QoS对应的哈希地址重新置0。因此,当本地参与者收到远程参与者数据包时,得到最后2个字节与本地参与者数据包最后2个字节段进行逻辑“与”操作,结果不为0表示本地端点与该远程端点QoS不兼容,那么该本地端点信息就不需要在网路上进行传播,也就不会在远程节点上进行存储,从而减少内存消耗和降低网络负载。
3.3 ISDPBQ_ADA算法描述
由于SDPBloom算法无法预先在参与者发现阶段完成对端点QoS策略兼容性的判断问题,因此可能使得各节点和网络中都出现大量QoS不兼容的端点信息,从而造成不必要的内存浪费和网络传输。为了能够进一步减少内存消耗和降低网络负载,本文提出一种改进的自动发现算法: ISDPBQ_ADA。该算法的主要设计思想是在SDPBloom算法的参与者数据包后面加上一个服务力向量,利用BFV和SAV向量对端点主题名、主题类型以及QoS进行匹配。BFV和SAV的构造过程如图1所示,其中,E表示一个端点;T0,T1,…,Tk表示该端点上的主题;X1,X2,…,Xm表示主题名、主题类型等;Q表示主题的服务质量集,集合中的每一个元素q1,q2,…,qn表示需要满足RxO模式的QoS(少于16种)。
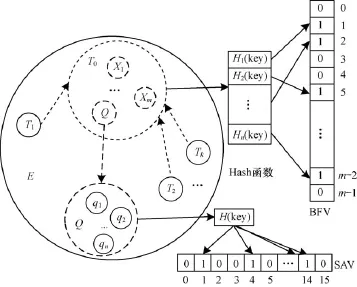
图1 BFV与SAV的构建过程
ISDPBQ_ADA算法的参与者发现阶段具体步骤如下:
Step1 构建Bloom Filter向量(BFV)以及服务力向量(SAV)。
Step2 将所有本地端点描述信息加入到BFV和SAV中;BFV存放相关端点的主题名和主题类型的描述信息,SAV存放端点的QoS标记。
Step3 向所有远程参与者发送本地参与者数据包,同时接收远程参与者发来的数据包信息。
Step4 当收到远程参与者发来的数据包时,获取BFV和SAV字段,与本地端点信息进行比较;若与本地端点相匹配,则将该远程参与者信息加入到本地信息库,并进入到端点发现阶段。
Step5 整个参与者发现过程中,当参与者或参与者创建的端点信息发生变化时,将转到Step3继续执行。
从上述执行步骤来看,参与者发现阶段主要完成本地参与者数据包的发送和远程参与者数据包的接收。与SDP_ADA和SDPBLoom算法不同之处主要在于参与者数据包的变化,它既包含端点的主题信息又包含QoS标记信息,其主要目的是为了减少不必要的数据传输和存储。
ISDPBQ_ADA算法的端点发现阶段具体步骤如下:
Step1 当发现过程进入端点发现阶段后,向所有本地信息库中的远程参与者发送本地端点数据包,并接收远程端点数据包。
Step2 当本地参与者接收到远程端点数据包后,将与本地端点信息进行再匹配;如果匹配成功则执行Step3,否则执行Step4。
Step3 将远程端点信息加入到本地信息库,建立双方之间的数据通信。
Step4 向远程参与者发送类似于“本地没有相关的端点”的信息,说明发生误报情况。
从上述步骤可以看出,端点发现阶段主要完成对端点具体信息的再匹配。由于BFV本身存在误报率的问题,以及SAV无法检测发布方和订阅方服务力同时加强或减弱的情况,因此为了防止漏报,本文针对端点QoS服务力同时加强或减弱,认为双方的QoS仍是相互兼容的,所以,存在误报率的问题。
为了便于实验验证和分析改进后的ISDPBQ_ ADA算法在网络负载和内存消耗方面的性能,本文引入2个概念:主题匹配率(Topic Match Ratio, TMR)和 QoS兼容率(QoS Compatibility Ratio, QCR),定义如下:

定义2 主题匹配率是指在系统中实际主题名、主题类型相匹配的端点数占总体端点数量的比率,可由式(2)得到:其中,SucMTname,type(E)表示主题名和主题类型都匹配成功的事件;Sum(E)表示系统中所有的端点数量。
定义3 QoS兼容率是指在主题名、主题类型都匹配的情况下,主题QoS相互匹配的端点占所有端点数量的比率,可由式(3)得到:

其中,SucMTname,type(E)表示主题名和主题类型都匹配成功的事件;SucMTQoS(E)表示系统中主题QoS成功匹配的事件。
4 仿真实验与分析
本文实验应用场景如表1所示,分为4组实验,每组实验中有5个应用程序,每个应用程序上分布10个端点,共50个端点数。TM表示主题名和主题类型匹配成功的端点个数,QC表示QoS相互兼容的端点个数,TMR表示主题匹配率,QCR表示QoS兼容率。如第1组中设置10个主题相匹配的端点,即TM=10、TMR=0.2,在匹配成功的10个主题中,只有2个端点的主题QoS相互兼容,即QC=2、QCR=0.2。实验结果如图2所示。
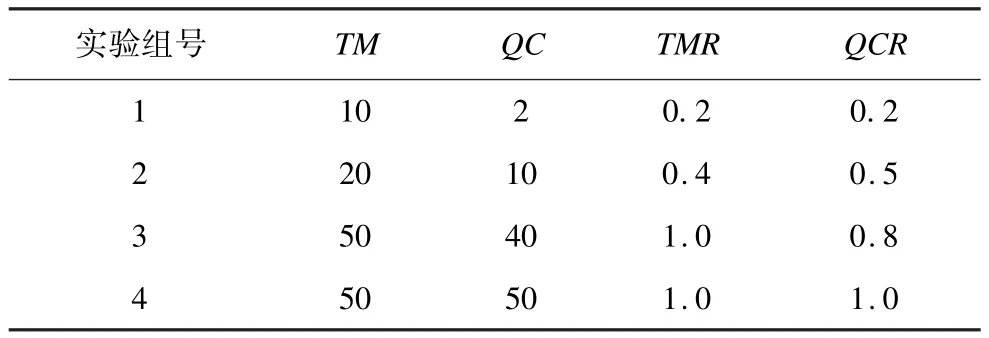
表1 实验应用场景设置
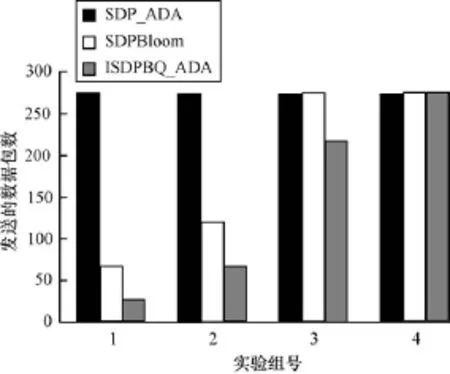
图2 3种发现算法对比结果
图3给出SDP_ADA,SDPBloom以及ISDPBQ_ ADA 3种自动发现算法在发现过程中发送的数据包个数在TMR∈[0,1]上的变化趋势,以及理论值与实验值的对比,其中虚线表示理论值。
从图2、图3可以看出:
(1)SDP_ADA算法在整个发现过程中发送的发现数据包数据量较SDPBloom和ISDPBQ_ADA算法大,且发送的发现数据包不随TMR的变化而变化。因此,SDP_ADA算法较后2种算法需要较大的内存来存储远程端点信息,且系统具有较高的网络负载。TMR越小,SDPBloom和ISDPBQ_ADA算法的优势越明显。
(2)ISDPBQ_ADA和SDPBloom算法发送的数据包会随着TMR的减小而减小,由于TMR减小表示本地端点与远程端点匹配变少,因此需要发送的本地端点数据包就会较少,且 ISDPBQ_ADA较SDPBloom算法在网络中需要传输的数据包更少,因此该算法具有更低的网络负载和内存消耗。QCR越小,ISDPBQ_ADA算法较SDPBloom算法的优势越明显。
(3)通过实验可以看出,SDPBloom和ISDPBQ_ ADA算法实际发送的发现数据包数量较理论值低,主要是因为这2个算法都存在误报情况,TMR和QCR都是在忽略误报率的情况下得到的,所以端点的实际匹配率较TMR和QCR值都要高。因此,实际传输数据量要大于理论值,而如何缩小实际值与理论值的差值是进一步研究的重点。

图3 算法随主题匹配率的变化趋势
5 结束语
本文针对DDS中相关自动发现算法进行研究,提出一种改进的自动发现算法ISDPBQ_ADA,该算法能够在参与者发现阶段对端点的服务质量的兼容性进行判断。通过实验验证了该算法的正确性和有效性,并且在同等条件下,与 SDP_ADA和SDPBloom算法相比,本文算法具有更低的网络传输量和内存消耗。下一步将研究降低或消除误报率,使得实际发送的网络数据包个数趋于理论值,从而进一步降低网络负载和内存消耗。
[1] Object Management Group.Data Distribution Service for Real-time Systems Specification Version1.0[EB/OL]. (2004-11-07).http://www.omg.org/spec/DDS/1.0.
[2] Object Management Group.Data Distribution Service for Real-time Systems Specification Version1.1[EB/OL]. (2005-12-04).http://www.omg.org/spec/DDS/1.1.
[3] Object Management Group.Data Distribution Service for Real-time Systems Specification Version1.2[EB/OL]. (2007-01-12).http://www.omg.org/spec/DDS/1.2.
[4] 刘旭军,马 跃.发布/订阅通信模式的实时性能分析与评估[J].计算机工程,2010,36(20):229-231.
[5] Sanchez-Monedero J,Povedano-Molina J,Lopez-Vega J M, et al.Bloom Filter-based Discovery Protocol for DDS Middleware[J].Journal of Parallel and Distri-buted Computing,2011,71(10):1305-1317.
[6] 欧阳军,蔡志明,王希敏.基于DDS中间件的性能测试[J].舰船电子工程,2011,31(11):136-139.
[7] 张 珺,尹逊和.基于RTI DDS的数据分发中间件的升级设计[J].北京交通大学学报,2011,35(5):31-37.
[8] Campo C,García-Rubio C,Lopez A M,et al.PDP:A Lightweight Discovery Protocol for Local-scope Interactions in Wireless Ad Hoc Networks[J].Computer Networks,2006,50(17):3264-3283.
[9] Object Management Group.The Real-time Publishsubscribe WireProtocolDDS Interoperability Wire Protocol Specification Version 2.1[EB/OL].(2009-01-05).http://www.omg.org/spec/DDSI/2.1.
[10] Real-time Innovations,Inc..RTI Connext Core Libraries and Utilities User's Manual Version 5.0[EB/OL]. (2012-08-10).https://support.rti.com/.
[11] Bloom B H.Space/time Trade-offs in Hash Coding with Allowable Errors[J].Communications of the ACM, 1970,13(7):422-426.
[12] Ahmadi M,Wong S.A Memory-optimized Bloom Filter Using an Additional Hashing Function[C]//Proceedings of Global Telecommunications Conference.New Orleans, USA:IEEE Press,2008:1-5.
编辑 陆燕菲
Publish/Subscribe Automatic Discovery Algorithm Based on Service Ability Vector
ZHAI Hai-bo,ZHUANG Yi,HUO Ying
(College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China)
The SDPBloom automatic discovery algorithm can not judge Quality of Service(QoS)compatibility of endpoints in the participants discovery phase in advance,and it makes probably a large number of QoS incompatible endpoints information on the each node and the network,which consumes too much memory and network resources.To solve this problem,this paper proposes an automatic discovery algorithm based on Service Ability Vector(SAV),which can judge whether the topic name and type of endpoints are matched and QoS compatibility by the Bloom Filter Vector
(BFV)and SAV to reduce unnecessary information transmission and storage.Experimental results show that the algorithm has lower memory resource and network transmission consumption than SDP_ADA algorithm and SDPBloom algorithm.
Service Ability Vector(SAV);publish/subscribe;Data Distribution Service(DDS);automatic discovery algorithm;Bloom filter;Quality of Service(QoS)
1000-3428(2014)09-0051-04
A
TP393
10.3969/j.issn.1000-3428.2014.09.011
航空科学基金资助项目(2010ZC13012);江苏省普通高校研究生科研创新计划基金资助项目(CXZZ13_0171)。
翟海波(1987-),男,硕士研究生,主研方向:分布式计算,并行计算;庄 毅,教授、博士生导师;霍 瑛,博士研究生。
2013-09-26
2013-10-25E-mail:zhb_2011_nuaa@126.com
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
数学物理学报(2022年2期)2022-04-26
华人时刊(2022年21期)2022-02-15
中学生数理化·教与学(2019年8期)2019-09-18
网络安全和信息化(2018年4期)2018-11-09
现代营销(创富信息版)(2018年10期)2018-10-12
数学物理学报(2017年1期)2017-06-05
华人时刊(2016年13期)2016-04-05
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
深圳信息职业技术学院学报(2013年3期)2013-08-22
