
基于云计算和量子粒子群算法的电力负荷曲线聚类算法研究
2014-06-09 08:26张少敏王保义
电力系统保护与控制 2014年21期
张少敏,赵 硕,王保义
(华北电力大学控制与计算机工程学院,河北 保定 071003)
0 引言
电力系统负荷分类就是利用各种聚类算法对选取的负荷数据样本进行分类,从而挖掘不同类型负荷的特性,辅助电力系统决策。随着电网智能化程度的加深,一线城市在用电高峰期间,面临数百万条记录的电力数据采集规模,一年的数据存储规模将从目前的GB级增长到TB级,甚至PB级[1]。同时,为了保证精细化、准确化控制,数据维度也从几十向上百过渡。近年来,许多的学者将数据挖掘算法[2-3]、群体智能算法[4]和机器学习算法[5]引入到电力负荷预测中,这些改进算法几乎都是通过大量迭代方式达到算法优化的目的,算法复杂度相当高。但在海量多维的智能电网数据上运行串行算法时将遭遇单机计算资源不足的瓶颈。
云计算技术在2003年由Google推出后,就作为一种新兴的商业计算模型得到了人们的广泛关注,智能电网的云存储模型也在不断发展。但针对智能电网云存储中的海量电力数据的聚类分析算法研究却很少。Prahastono等人[6]利用模糊C均值聚类算法,采用印度尼西亚的真实电力数据进行负荷特性分类研究。何晓峰等人[7]将PSO粒子群算法引入到模糊C均值聚类算法中,在一定程度弥补了模糊C均值聚类算法的不足,但PSO算法的微粒飞行速度难以控制,容易飞跃最优解,导致无法收敛于全局最优。
本文围绕上述问题,将量子粒子群群体智能算法引入到传统模糊C均值聚类算法中,提出了一种基于云计算的电力负荷曲线聚类的并行量子粒子群优化模糊C均值聚类算法,充分利用QPSO较强的全局搜索能力,克服了模糊C均值聚类算法的缺陷;并利用云计算MapReduce框架对聚类算法进行并行化改进,解决聚类海量高维电力负荷数据时单机运算资源不足的瓶颈,最后,在实验室搭建云集群上测试改进算法的并行性和聚类质量,并验证改进算法在实际应用中的性能。
1 模糊C均值聚类算法
1.1 算法描述
模糊C均值聚类算法(Fuzzy C-Means,FCM)[8],按数据对象间的相似度,将整个数据集合分为C个模糊聚簇中,使得类内加权误差平方和达到最小值。FCM聚类算法采用模糊划分,对每个数据对象采用[0,1]之间的隶属度表示其属于各个聚簇的程度。根据标准化规定,一个数据对象对于C个聚簇中心的隶属度之和等于1,即
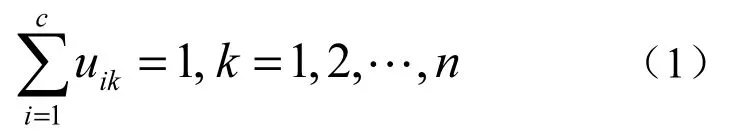
FCM聚类算法的目标函数为

其中:μik∈[0,1]为第k个数据对象属于第i个聚类中心的程度;Pi为聚类i的聚类中心;m∈[0,2]为加权指数;dik为第i个聚簇中心与第k个数据对象的欧氏距离(Euclidean Distance),公式为

根据FCM聚类准则构造如下Lagrangian函数
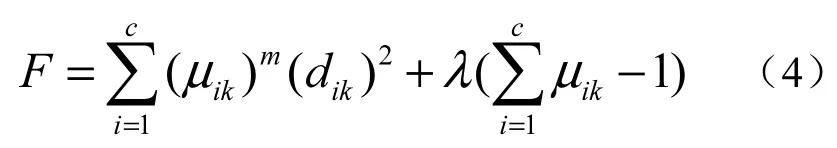
根据Kuhn-Tucker定理对输入变量求导,求得Jm(U,P)取最小值时的必要条件为
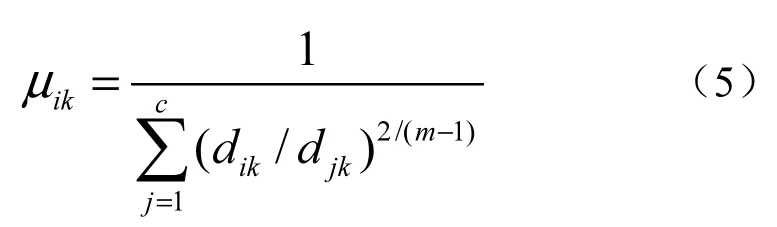

1.2 FCM算法的不足
从FCM算法描述中可以发现,式(5)和式(6)的计算量相当大,而针对海量、高维的数据,单机运行FCM算法进行电力负荷聚类分析需要很高的内存空间,运算效率较低,不能满足电力控制实时性要求。运用云计算的MapReduce对算法进行并行化改进,以解决单机运算资源不足的问题。
此外,FCM算法是一种局部搜索算法,其迭代序列必收敛到目标函数的某个极小值或鞍点,易陷入局部最小值,影响最终聚类质量。为此,本文提出一种并行量子粒子群模糊C均值聚类算法(Parallel Quantum-Behaved Particle Swarm Optimization Fuzzy C-Means,P-QPSO-FCM)。
2 基于云计算的P-QPSO-FCM算法设计
2.1 量子粒子群算法
粒子群算法(Particle Swarm Optimization,简称PSO)是基于种群的进化搜索技术,但其不能保证算法的全局收敛,从基本粒子群算法模型可以得出,粒子的飞行速度相当于搜索步长,全局收敛性受其速度大小直接影响[5]。针对PSO算法的收敛性问题,Sun等人从量子学的角度提出了具有量子行为的粒子群算法(Quantum-Behaved Particle Swarm Optimization,QPSO)。其将每个粒子的飞行速度由粒子的飞行最优值和群体的飞行最优值动态调整。QPSO算法不仅参数少,并且搜索能力上优于PSO算法,并且收敛性有了很大的改进。QPSO算法中的粒子群将按照以下三个公式进行动态调整位置。

其中:mbest为粒子群各个粒子最优位置的中间位置;pgbest为粒子群全局最优位置;pid为pid和pgbest的随机加权点。α是QPSO的收缩扩张系数,随着式(10)线性变化。
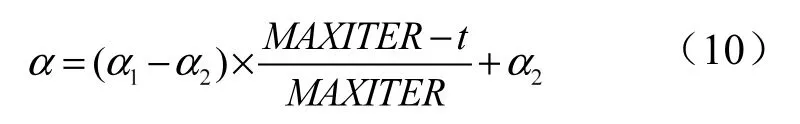
其中:α1和α2为α的初始值和最终值;t是当前的迭代次数;MAXITIER是初始设定的最大迭代次数。通过线性改变α值,本文将范围设置为1.2到0.7,此时QPSO可以实现比较好的性能。
2.2 FCM算法改进思想
FCM算法是一种基于梯度下降的局部搜索算法,易陷入局部最小,且随机选取初始聚类中心,不同的初始聚类中心导致不同的聚类结果。QPSO具有全局搜索能力,不易陷入局部最小。因此本文QPSO算法代替FCM的迭代过程,防止FCM陷入局部最优,以获得比较好的整体聚类质量,而且可减少算法迭代次数,节省计算资源,提高聚类质量。
2.3 P-QPSO-FCM算法设计
2.3.1 数据预处理
首先对各维数据进行规范化,映射到[0,1]内。
2.3.2 粒子编码和适应度函数设计
在QPSO中,每个粒子都是由C个聚簇中心组成,数据对象的维度为D,因此每个粒子表示为C×D维向量,粒子位置Xp构造如下。
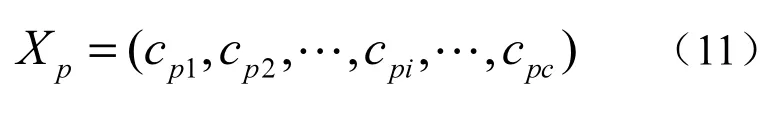
其中,cpi为第p个粒子的第i个聚簇中心。
定义粒子群适应度函数为目标函数Jm(U,P),如式(2)所示。
2.3.3 P-QPSO-FCM算法执行步骤
P-QPSO-FCM算法具体步骤如下。
(1)初始化聚簇数目C、数据对象维度D、量子粒子群规模N和最大迭代次数runtimes。
(2)在样本数据集上运行一次FCM算法,将获取的聚类中心按粒子编码规则构造粒子个体X1,即为第一个粒子位置;然后,利用获取的聚类中心按欧氏距离完成一次粗聚类,得到C个粗聚簇:……,其中。
(3)从每个粗聚簇中随机取出一个数据对象,获取C个数据对象,按粒子编码规则构造粒子个体X2;迭代上述步骤,直到获取N个粒子个体。
(4)初始化粒子群的各个粒子局部最优位置pbest和全局最优位置pgbest。
(5)对每个粒子按照适应度函数Jm(U,P)计算适应度,并由每个粒子的适应度值按式(12)、式(13)更新粒子群的pbest、pgbest,根据式(7)获取各个粒子最优位置的中间位置mbest。

(6)根据式(8)~式(10)得到新一代粒子个体xid。
(8)全局最优位置对应的聚类中心作为FCM算法的初始聚类中心,执行FCM算法。
这里,在确定QPSO的初始N个粒子个体位置时进行了一定的算法优化,传统粒子群算法的初始粒子个体位置是随机生成的,本文提出的改进算法则是通过一次FCM聚类后,分别从生成的C个粗聚簇中随机选取数据集构造粒子个体,在不增加算法复杂度的前提下,所选取的N个粒子个体位置在一定程度上代表了该样本数据集的真实分布,从而降低P-QPSO-FCM算法的迭代次数。
2.4 基于MapReduce的P-QPSO-FCM算法设计
在Hadoop平台上实现P-QPSO-FCM算法需要四个阶段,分别用四个MapReduce任务实现。算法分布式流程图如图1 所示,其中,Job2和Job3为简化的分布式流程,实际分布式流程与图中Job1和Job2相似。

图1 P-QPSO-FCM分布式运行流程图Fig.1 Flow chart of P-QPSO-FCM algorithm
3 实验与算例分析
3.1 实验准备
实验室搭建的Hadoop平台由9个节点组成,每个节点机器配置为Intel(R)Core(TM)i5-2400 4-core CPU@2.60 GHz,4 GB RAM,网络带宽为100 Mbit/s Hadoop版本为0.20.2,HBase版本为0.90.6。
在进行map函数操作之前,底层框架需要对输入进行分片,以便多个map同时工作,而分片默认是64 M。由于真实负荷数据有限,实验将首先测试QPSO-FCM算法性能,然后通过人工扩展真实数据集,测试P-QPSO-FCM并行算法的并行性能。
3.2 测试数据集描述
所用数据为国际通用测试数据库UCI[9]上的Wine、Iris和Breast-Cancer测试数据集。其次,进行电力系统算例分析。选用2001年欧洲智能技术网络(EUNITE)组织的中期电力负荷预测竞赛提供的某地区97、98年真实负荷数据作为算例分析数据集,在此数据集上运行P-QPSO-FCM算法以获取相似日曲线,并验证该算法与FCM算法相比具有性能优越性。
3.3 聚类质量对比实验
比较FCM算法、自适应模糊聚类 (Adaptive FCM,AFCM)[10]与提出的QPSO-FCM算法的聚类质量。AFCM中引入了自适应度向量 W 和自适应指数 p,文献[10]经过大量实验表明AFCM可以得到更好的聚类质量。FCM算法随机选取C个数据对象作为初始聚类中心,所以聚类质量波动较大。
采用适应度函数值和聚类正确率来测试聚类质量,适应性函数值越小、聚类正确率越高则聚类质量越高,适应度函数如式(2)所示。为了保证实验结果的客观性,三种算法各运行30次,并进行归一化处理,实验结果如表1所示。
从实验结果看出,QPSO-FCM算法与另外两种算法相比,不仅正确率高于后者5%到15%,且适应性函数值更小,聚类质量更好,陷入局部最优的可能性更小。因此该算法具有一定的优越性。
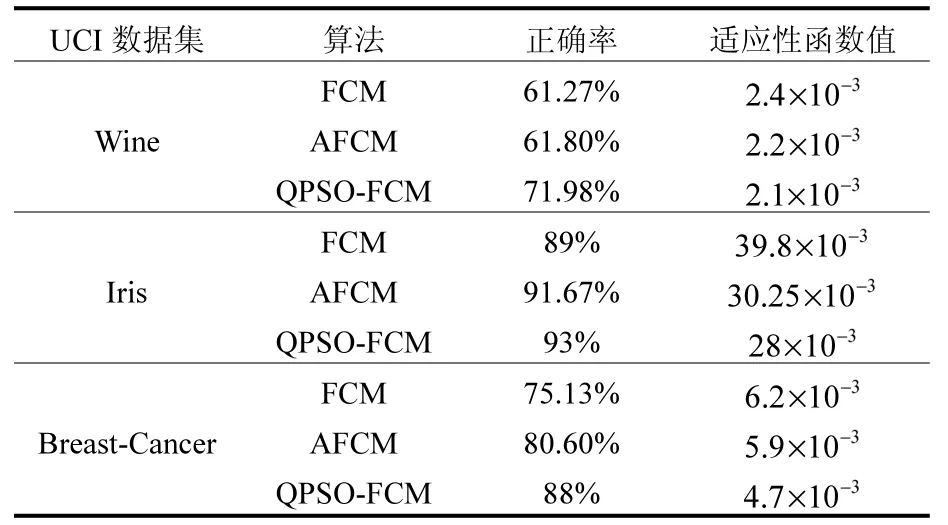
表1 FCM算法、AFCM算法与P-QPSO-FCM算法聚类质量对比Table 1 Comparison of the clustering quality of the algorithm FCM, AFCM and P-QPSO-FCM
3.4 算例分析
3.4.1 目标函数值变化情况
在电力负荷样本数据分别运行FCM算法和QPSO-FCM算法获取每次迭代的目标函数值,30次实验取其平均值作为最终实验结果。目标函数值与迭代次数变化关系如图2所示。

图2 目标函数值与迭代次数变化关系Fig.2 Objective function value and the number of iterations
从实验结果看出,FCM算法运行时随着迭代数的增加,目标函数值逐渐平滑减小,没有出现反复情形,这说明FCM算法在样本数据集上执行聚类操作有可能陷入局部最优,影响最终聚类效果,而QPSO-FCM算法在聚类过程中的目标函数值虽然总体趋势是减小,但随着聚类迭代次数的增加,其目标函数值也在不断变化,不是梯度下降的,说明该算法不易陷入局部最优,保证了最终的聚类质量。
本文提出的改进算法正是利用了量子粒子群算法的全局搜索能力,结合FCM的较强的局部搜索能力,且人工设定参数较少,来提高算法聚类质量。
3.4.2 P-QPSO-FCM并行性能
采用加速比(speedup)来测试P-QPSO-FCM算法的并行化性能。加速比是衡量并行系统或程序并行化的性能和效果的指标,如式(14)所示。

因EUNITE组织提供的两年730条48维电力负荷数据量过小,无法表现出P-QPSO-FCM算法并行性能。故本实验首先将EUNITE组织所提供的真实电力负荷数据集人工扩充为0.5 G、1 G、2 G等3个不同大小的数据集,分别在集群节点个数为1、3、5、9的云集群上运行算法,分别记录算法执行时间,以计算加速比,实验结果如图3所示。

图3 加速比与集群节点数关系图Fig.3 Speedup in different sizes of datasets
云集群的节点数为9,当云集群节点数量达到一定数量时,因算法执行时间相当多的消耗在了节点间的网络传输等额外消耗上,所以加速比将随着云集群节点的增加而变差。但是从有限的节点上可以看出,随着数据量的增加,P-QPSO-FCM聚类算法的加速比依然几乎线性增加,且与较小数据集的加速比折线相差不大,说明算法的并行性能较好,且HBase的读写性能没有成为算法的性能瓶颈。
3.4.3 提取日负荷特征曲线
目前,许多文献[11]采用相似日法作为辅助策略来改善负荷预测精度。为了验证提出的算法的有效性,本文将其应用于负荷预测样本数据的预处理。
利用文献[12]中的分离系数、分离熵以及有效性评价系数来评价FCM算法与本文提出的聚类算法在真实电力负荷的聚类效果,并确定样本的聚类个数取值为10。实验结果表2所示。

表2 评价指标Table 2 Evaluation result
从表4可以看出,本文的算法在三项指标均优于FCM算法。在云平台上执行P-QPSO-FCM算法,即按照平均负荷变化规律相似进行聚类,形成K条负荷水平趋势相似日曲线,实验结果如图4所示。
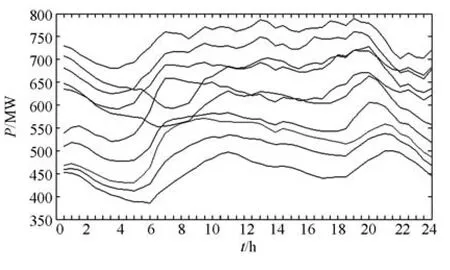
图4 日负荷特征曲线Fig.4 Load characteristic curve
本文集群节点数为9个,并行性能测试采用的数据量最高是2 G。在实际应用中,针对实际的存储运算数据量,云计算集群节点数可达到数以千计、万计,完全可以应对海量、高维数据运算时对资源的要求。基于云计算的P-QPSO-FCM聚类算法,不仅能满足当电力负荷数据量达到TB、PB级别时数据的存储、运算要求;而且经过上述实验以及多种评价指标对比表明:相对基于FCM聚类算法的选取相似日的预测方式,本文提出的聚类算法在一定程度上提高了聚类准确度,进而提高了负荷预测精度。
4 结语
本文提出了基于云计算的电力负荷曲线聚类的并行量子粒子群优化模糊C均值聚类算法,通过电力负荷样本数据的算例分析和相关测试,表明该算法显著提高了聚类质量和效率,且并行化性能良好。
[1] 袁铁江, 袁建党, 晁勤, 等.电力系统中长期负荷预测综合模型研究[J].电力系统保护与控制, 2012, 40(14):143-146, 151.
YUAN Tie-jiang, YUAN Jian-dang, CHAO Qin, et al.Study on the comprehensive model of mid-long term load forecasting[J].Power System Protection and Control,2012, 40(14):143-146, 151.
[2] BUYYA R, YEO C S, VENUGOPAL S.Market-oriented cloud computing: vision, hype, and reality for delivering IT services as computing utilities[J].High Performance Computing and Communications, 2009: 25-27.
[3] 王振树, 李林川, 牛丽.基于贝叶斯证据框架的支持向量机负荷建模[J].电工技术学报, 2009, 24(8):127-134, 140.
WANG Zhen-shu, LI Lin-chuan, NIU Li.Load modeling based on support vector machine based on Bayesian evidence framework[J].Transactions of China Electrotechnical Society, 2009, 24(8): 127-134, 140.
[4] 陈小平, 顾雪平.基于遗传模拟退火算法的负荷恢复计划制定[J].电工技术学报, 2009, 24(1): 171-175, 182.
CHEN Xiao-ping, GU Xue-ping.Determination of the load restoration plans based on genetic simulated annealing algorithms[J].Transactions of China Electrotechnical Society, 2009, 24(1): 171-175, 182.
[5] 张志明, 金敏.基于灰关联分段优选组合模型的短期电力负荷预测研究[J].电工技术学报, 2009, 24(6):115-120.
ZHANG Zhi-ming, JIN Min.Research on short-term electrical load forecasting based on optimized combination model of grey correlation segmentation[J].Transactions of China Electrotechnical Society, 2009,24(6): 115-120.
[6] PRAHASTONO I, KING D J, OZVEREN C S, et al.Electricity load profile classification using fuzzy C-means method[C] // 43rd International Universities Power Engineering Conference, 2008, 9: 1-5.
[7] 何晓峰, 王钢, 李海锋.电力系统粒子群优化模糊聚类算法及其应用[J].继电器, 2007, 35(22): 40-44.
HE Xiao-feng, WANG Gang, LI Hai-feng.Power system clustering algorithm combining particle swarm optimization with fuzzy C means and its application[J].Relay, 2007, 35(22): 40-44.
[8] 李培强, 李欣然, 陈辉华, 等.基于模糊聚类的电力负荷特性的分类与综合[J].中国电机工程学报, 2005,25(24): 73-78.
LI Pei-qiang, LI Xin-ran, CHEN Hui-hua, et al.The characteristics classification and synthesis of power load based on fuzzy clustering[J].Proceedings of the CSEE,2005, 25(24): 73-78.
[9] http://archive.ics.uci.edu/ml/index.html
[10] 唐成龙, 王石刚.基于数据间内在关联性的自适应模糊聚类模型[J].自动化学报, 2010, 36(11): 1544-1556.
TANG Cheng-long, WANG Shi-gang.Adaptive fuzzy clustering model based on internal connectivity of all data points[J].Acta Automatica Sinica, 2010, 36(11):1544-1556.
[11] 莫维仁, 张伯明, 孙宏斌, 等.短期负荷预测中选择相似日的探讨[J].清华大学学报: 自然科学版, 2004,44(1): 106-109.
MO Wei-ren, ZHANG Bo-ming, SUN Hong-bin, et al.Method to select similar days for short-term load forecasting[J].Journal of Tsinghua University: Sci &Tech, 2004, 44(1): 106-109.
[12] 刘莉, 王刚, 翟登辉.k-means聚类算法在负荷曲线分类中的应用[J].电力系统保护与控制, 2011, 39(23):65-68, 73.
LIU Li, WANG Gang, ZHAI Deng-hui.Application of k-means clustering algorithm in load curve classification[J].Power System Protection and Control,2011, 39(23): 65-68, 73.
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
测控技术(2018年10期)2018-11-25
浙江工业大学学报(2017年5期)2018-01-22
雷达学报(2017年6期)2017-03-26
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
核科学与工程(2015年2期)2015-09-26
