
仿射传播聚类在室内定位指纹库中的应用研究
2014-07-02 00:21张俪文汪云甲王行风
测绘通报 2014年12期
张俪文,汪云甲,王行风
(中国矿业大学环境与测绘学院,江苏 徐州 221116)
仿射传播聚类在室内定位指纹库中的应用研究
张俪文,汪云甲,王行风
(中国矿业大学环境与测绘学院,江苏 徐州 221116)
基于位置指纹的室内定位,指纹数据结构复杂、信号时变性强等原因影响了定位的时效性。K-means聚类算法虽可以有效地减少数据遍历的工作量,但该方法仅仅考虑了采样点在信号域的相关性,导致定位精度下降,同样难以满足室内定位的实时性要求。本文基于位置指纹方法,借鉴K-means聚类算法的思路,研究了指纹的样本点位置域和信号域特征的融合方法,并将融合后的特征引入了仿射传播聚类算法。试验测试表明,该方法在保证精度的前提下,可使时间消耗平均减少40%,有效地提高了系统的实时性,可以满足室内定位的基本要求。
室内定位;位置指纹;仿射传播聚类;特征融合
一、引 言
目前,室内指纹定位系统的研究主要集中在提高系统的定位精度和系统实时性上[1]。提高精度的途径主要有两种:一是改进定位算法[2-3];二是加密定位中使用的指纹库[4-5]。如果参与计算的点较多,无论是直接插值定位[6-7],还是基于概率分布定位[8-9],在时间消耗上都会增加。其中基于概率分布的算法会有更多的时间消耗[10];而加密指纹库可以得到较高精度的结果,但也会增加搜索时间。因此,减少匹配的数据量对于增强系统的时效性和提高系统精度十分重要。
对定位指纹库进行聚类处理可以很好地降低系统搜索样本点的数据规模[11-12]。在聚类特征选取上,有使用最强接入点(access point,AP)作为特征的[12],也有使用样本点(respective point,RP)信号之间的距离作为特征的[13]。使用最强AP作为特征的聚类处理并不能明显减少定位计算量,这是由于无线信号在室内强反射环境中阴影衰落效应较为显著[14];利用信号之间的距离作为特征可以很好地避免这种情况[13],但是定位算法的最终目的是确定未知点的位置,仅使用信号之间的距离并不能很好地反映位置之间的关系,因此造成定位结果的精度不高。
本文将指纹库中样本点的信号特征与位置特征进行融合,引入仿射传播聚类(affinity propagation clustering,APC)方法进行聚类,从而实现指纹库的分块处理。试验场测试表明,本文使用的聚类算法在保证精度的前提下,可使平均时间消耗减少40%。
二、原 理
指纹定位区域中的AP点组成集合B={b1,b2,…,bn},在该区域中还有人为规划的采样点RP组成的集合L={l1,l2,…,lm}。每一个 L中的元素 li(1≤i≤m)都记录两部分数据,一部分是该点的位置向量 Gi=(xi,yi),另一部分是在该点接收到的AP点的信号强度向量 Vi=(vi,1,vi,2,…,vi,n),其中vi,j(1≤j≤n)表示在li点接收到来自bj的信号强度。S={s1,s2,…,sn}表示在区域中的某个未知位置接收到的信号强度集合,其中sk(1≤k≤n)表示未知位置接收到来自bk的信号强度。
1.融合距离与信号信息的特征提取
在提取聚类特征的过程中,需要使用采样点在位置域和信号域的距离。信号域距离与位置距离类似,文献[13]中将两组信号之间的欧式距离定义为信号距离SigDisdd,如下
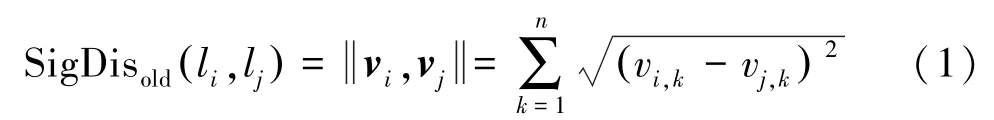
空间距离较近的样本点,搜索的相同AP信号数目多;空间距离较远的样本点,搜索到的相同AP信号数目少。相同AP数目可以在一定程度上反映样本点之间的空间距离关系。因此,在计算信号距离时,引入相同AP数目,可以扩大远距离点之间的数值,缩小近距离点之间的数值。本文改进的信号距离SigDisnew为

式中,m为(li,lj)点之间的相同AP数目。
两采样点之间的位置域距离GeoDis为

信号域距离与位置域距离的量纲不同,为了融合特征,试验中使用的距离是归一化之后的结果。两种距离在数值分布的趋势上大体相似,但是由于信号的不稳定性,信号域距离中噪声更多。为了排除噪声的影响,融合特征MixDis利用位置域距离对信号域距离进行限制。融合特征MixDis的定义为
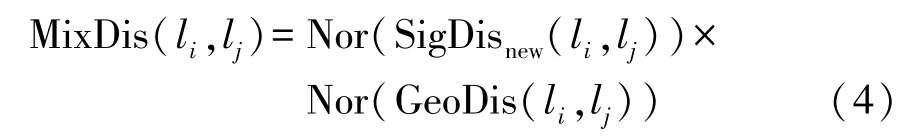
式中,Nor为归一化函数。
使用地理位置对信号距离进行修正,得到的融合特征可以更好地反映采样点之间的地理关系。本文第3部分的试验中显示,使用融合特征进行聚类,得到的类分布更加均匀,更加接近空间结构划分。
2.仿射传播聚类
通常的聚类算法是在多次迭代中选出一个聚类中心,使该类其他成员与聚类中心的距离平方和最小。以经典的K-means算法为例,算法启动时需要提供一系列的类中心初始值,并且算法对系统的初始值依赖性较大,容易陷入局部极值[15]。而 APC是将所有的点连接成网络,每个节点都是潜在的聚类中心,通过迭代,点之间不断发射和接收吸引度和归属度消息,从而不断扩大中心点和附属点之间的差距,最终确定中心点[16]。与K-means方法相比,APC的收敛速度更快,得到的绝对平均误差和平均方差要比K-means的结果低[16-17]。
APC的输入信息为n个点之间的相似度矩阵Sn×n,本文使用的就是融合后的特征MixDis。对于s(k,k),需要设置一个合理的值来表示,通常选择Sn×n中的中值,试验中选择S的第k行的中值作为s(k,k)的初始值。之后为算法的核心,计算两两参考点间的消息传递:吸引度消息r(i,j)和归属度消息a(i,j)。其中吸引度消息r(i,j)是从i点传到j点,表明j作为i的聚类中心的可靠度;归属度消息a(i,j)是从j点传到i点,表明i选择j作为聚类中心的可行度。
(1)吸引度消息r(i,j)
由样本点li传到样本点lj,表明了在除lj点之外的样本点的作用下lj作为聚类中心对li的吸引度的积累,公式如下式中,s(i,j)是MixDis(i,j);a(i,j)是下面要定义的归属度消息。
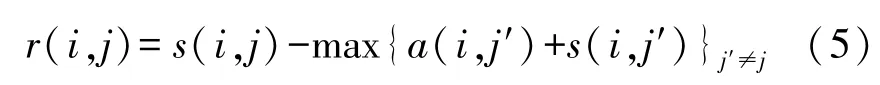
(2)归属度消息a(i,j)
由样本点lj传到样本点li,表明了在除lj点之外的样本点的作用下li认为lj为聚类中心的归属度的积累,公式如下
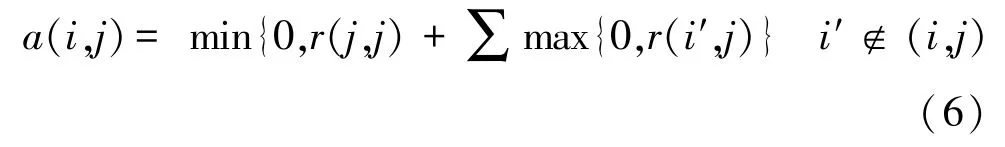

(3)自归属度消息通过以上两种消息在样本点之间的传递,实现了中心和归属点的划分。具体来说,如果j′=i,则参考点li为中心;否则lj′点为中心。
三、试验与结果分析
1.试验条件
选取中国矿业大学南湖校区的环测学院楼4层A区和C区的走廊作为试验场,面积约为350 m2,定位中使用的泛在信号为日常传输数据的WiFi信号,共99个,并未加设新的设备。图 1是试验场的WiFi信号强度分布图。
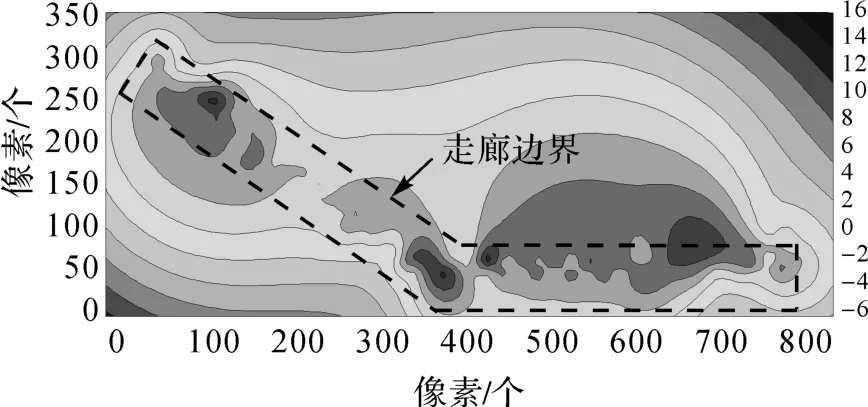
图1 试验场WiFi强度分布
试验分为采样过程、离线处理和定位3个步骤。使用三星GalaxyⅢ (Android 4.0平台)进行采样和定位,采样率为100 Hz,接收信号强度为-110~15的整数,采样过程需要对东西南北4个方向采集可接收AP点的Mac地址和平均信号强度,共采集有效点93个,平均采样间隔3.5 m;离线处理即指纹库的聚类处理;定位与采样阶段类似,但定位方向不一定,且定位时间较短。
2.聚类试验
通过提取融合特征,采用APC算法对样本库中的样本点进行聚类处理。APC是一种非监督分类方法,因此不必设定分类数目。分类结果如图2所示。
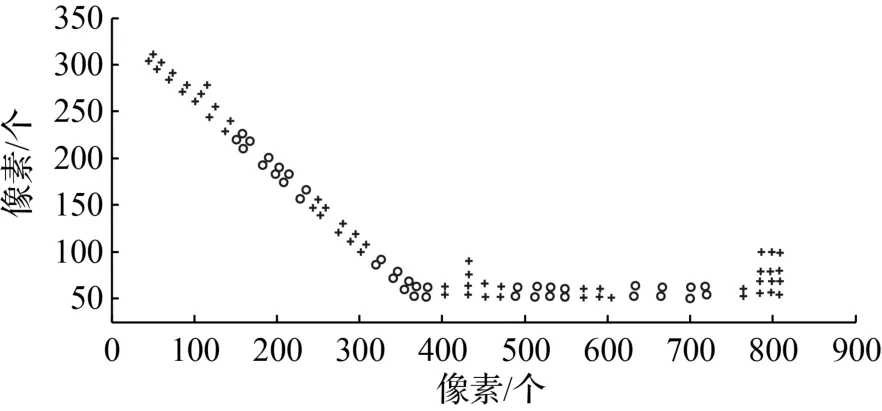
图2 APC分类结果
同时与文献[12]使用的K-means算法进行对比,K-means需要设定分类数目,这里将仿射传播分类的分类数代入,以进行测试。分类结果如图3所示。圈出的是分类不合理的位置,1为类成员过少,2为边界模糊,3为走廊拐弯处没有划分。

图3 K-means分类结果
本文使用3种指标对分类结果的均匀性进行分析和评定,分别是类成员数目方差、类平均中心距方差和类覆盖面积方差。类成员数目是指各类中的采样点的数目;类平均中心距是指类中各采样点到聚类中心的距离的平均值,这里为了统计采样点的空间分布,选用空间距离;类覆盖面积是指类中成员覆盖的空间范围,由于采样点是沿走廊两侧分布的,可以使用各类采样点的最小凸包代表类的空间覆盖空间。这3种数据的方差值用于衡量分类的均匀性,见表1。

表1 分类均匀性指标
从3项指标来看,APC的数值要小于K-means。其中类成员数目是从数量上衡量类划分的均匀程度,数目差别较大会对邻域计算产生影响,当类中点的数目少于邻域计算数目时需要增加其他类的成员点参与计算,这就需要额外添加类之间的关联关系。类平均中心距方差和类覆盖面积方差反映了类在空间覆盖上的均匀性,空间分布均匀有利于控制定位的精度在一定范围内变动。
同时,从图2和图3中可以看出,APC方法除了类划分较为均匀之外,走廊的拐弯处也都是类划分的边界。这种处理方法有利于提高定位的精度,在拐弯处定位,若不进行拐弯划分,容易将位置定在走廊之外,形成逻辑错误。
3.定位试验
试验选用 K近邻法(K nearest neighborhood, KNN)作为定位算法。未知位置的计算公式[13]为
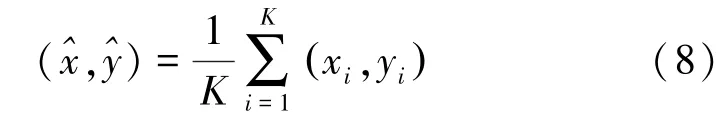
式中, (xi,yi)为第i个被选取点对应的坐标;K为选取邻近点的数目,试验中 K=6,采样的平均间隔3.5 m。定位数据的搜集方法为:在试验场标定26个待定位点,使用相同设备采样2 s,记录WiFi信号数据。试验分别从时间效率和定位精度两个方面分析对比APC和K-means的定位效果。
聚类处理作为数据的预处理,是通过减少定位时的数据检索量,从而降低定位使用的时间。在手机平台定位测试,单点定位时间如图 4所示,K-means和APC聚类处理相对全局搜索在时间效率上有较大提升,全局搜索定位平均用时127 ms,K-means和APC分别是76 ms和70 ms,提速程度相当;其中K-means的最大降幅为88.2%,最小降幅仅为0.2%,而APC的最大降幅为87.2%,最小降幅也达到16.8%。APC的数据检索平均减少75%,最多减少80%,其平均减少率与K-means相当,这就使两种聚类处理方法的平均定位时间相近;但K-means的降幅变化较大,这是由于聚类结果不均匀,导致各个定位点搜索的采样点数目相差较大,见表 2,K-means最大最小搜索数目之间相差20,而APC仅为10。

图4 单点定位时间对比
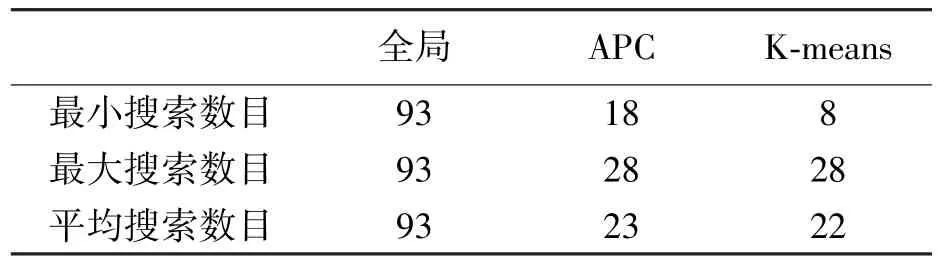
表2 点搜索数目对比 个
定位精度如图5所示,经过聚类处理的定位要比全局搜索定位的结果更加精确,全局搜索平均定位精度为2.6 m,K-means和APC的平均定位精度分别为1.6 m和1.5 m;K-means的最大定位误差为5.6 m,最小为0.1 m,APC的最大定位误差为2.8 m,最小为0.2 m。在平均误差上 APC的结果要稍好于 K-means,而且误差波动较小。这是由于K-means中存在成员数目很少的类,该类的信号均值不能反映该类区域信号特点,容易造成误匹配,从而使得精度下降。

图5 单点定位精度对比
四、结 论
本文通过APC对室内定位指纹库的位置指纹数据进行聚类处理,以减少定位时遍历数据量,提高定位精度。针对仅使用信号域的相关度衡量采样点之间的关系造成的定位结果偏差的现象,本文将采样点的位置域与信号域的相关度进行组合,得到融合特征,将融合特征作为聚类特征代入APC算法,通过试验场测试得到以下结论:
1)本文使用的聚类算法和特征得到的聚类结果与K-means的结果相比,类划分更接近空间结构划分,类分布更加均匀,更有利于提高定位精度。
2)以APC结果为基础进行KNN插值定位,定位结果精度高于K-means方法,遍历点平均减少75%,时间较全局搜索平均减少40%。
因此使用APC对采样点位置域和信号域进行聚类分析,可以有效地减少系统的遍历数据量,并且提高室内定位的精度。
[1] KUO S P,TSENG Y C.Discriminant Minimization Search for Large-Scale RF-based Localization Systems[J].Mobile Computing,2011,10(2):291-304.
[3] LI K.Location Estimation in Large Indoor Multi-floor Buildings Using Hybrid Networks[C]∥Wireless Communications and Networking Conference.[S.l.]:IEEE,2013:2137-2142.
[4] ZHE X,ZHANG H,HUANG J,et al.A Hidden Environment Model for Constructing Indoor Radio Maps[C]∥World of Wireless Mobile and Multimedia Networks.[S. l.]:IEEE,2005:395-400.
[5] ZDRUBA G V,HUBER M,KARNANGAR F A,et al. Monte Carlo Sampling Based In-home Location Tracking with Minimal RF Infrastructure Requirements[C]∥Global Telecommunications Conference.[S.l.]:IEEE,2004:3624-3629.
[6] CHAI X Y,YANG Q.Reducing the Calibration Effort for Probabilistic Indoor Location Estimation[J].Mobile Computing,2007,6(6):649-662.
[7] KRISHNAN P,KRISHNAKUMAR A S.A System for LEASE:Location Estimation Assisted by Stationary Emitters for Indoor RF Wireless Networks[C]∥INFOCOM:Twentythird Annual Joint Conference of the IEEE Computer and Communications Societies.[S.l.]:IEEE,2004:1001-1011.
[8] WYMEERSCH H,JAIME L.Cooperative Localization in Wireless Networks[J].Proceedings of the IEEE,2009,97(2):427-450.
[9] YOUSSEF M,AGRAWAL A.Handling Samples Correlation in the Horus System[C]∥INFOCOM.[S.l.]:IEEE,2004:1023-1031.
[10] YOUSSEFF M,AGRAWALA A.On the Optimality of WLAN Location Determination Systems[J].UM Computer Science Department,2004,4(4):1-6.
[11] YOUSSEFF M,AGRAWALA A.WLAN Location Determination via Clustering and Probability Distributions[C]∥Pervasive Computingand Communications.[S.l.]:IEEE,2003:143-150.
[12] KUO S P.Cluster-enhanced Techniques for Pattern-Matching Localization Systems[C]∥Mobile Adhoc and Sensor Systems.[S.l.]:IEEE,2007:1-9.
[13] BAHL P,PADMANABHAN V N.RADAR:An In-building RF-based User Location and Tracking System[C]∥INFOCOM.[S.l.]:IEEE,2000:775-784.
[14] 贾明华.地铁隧道环境毫米波传播特性的研究[D].上海:上海大学,2010.
[15] 王开军,张军英,李丹,等.自适应仿射传播聚类[J].自动化学报,2007,33(12):1242-1246.
[16] FREY B J,DUECK D.Clustering by Passing Messages Between Data Points[J].Science,2007,315(5814):972-976.
[17] 冯辰.基于压缩感知的RSS室内定位系统研究与实现[D].北京:北京交通大学,2010.
Affinity Propagation Clustering for Fingerprinting Database in Indoor Localization
ZHANG Liwen,WANG Yunjia,WANG Xingfeng
RUNGSI K.Distribution of WLAN
Signal Strength Indication for Indoor Location Determination[C]∥Wireless Pervasive Computing.[S.l.]:IEEE,2006.
P237
B
0494-0911(2014)12-0036-04
张俪文,汪云甲,王行风.仿射传播聚类在室内定位指纹库中的应用研究[J].测绘通报,2014(12):36-39.
10.13474/j.cnki.11-2246.2014.0392
2013-10-24
国家863计划(2013AA12A201);地理空间信息工程国家测绘地理信息局重点实验室资助项目(201321)
张俪文(1990—),女,陕西渭南人,硕士生,研究方向为室内定位、模式识别。
汪云甲
猜你喜欢
小猕猴智力画刊(2021年6期)2021-08-05
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
测控技术(2018年4期)2018-11-25
雷达学报(2017年1期)2017-05-17
中国民族医药杂志(2016年5期)2016-05-09
自动化学报(2016年8期)2016-04-16
作文大王·低年级(2016年3期)2016-03-11
