
基于单边通信协议的片上网络传输接口设计*
2014-07-05 16:17刘传波
舰船电子工程 2014年11期
刘传波
(武汉藏龙北路1号 武汉 430205)
基于单边通信协议的片上网络传输接口设计*
刘传波
(武汉藏龙北路1号 武汉 430205)
为了提升处理单元与片上网络之间的数据交互能力,基于单边通信协议设计了一款片上网络传输接口。该接口通过直接存储访问实现了存储器与网络接口间的高效数据搬移,降低了数据包的发送和接收延时,同时减少了CPU的干预。16核片上多处理器环境下的实验结果表明,对比CPU干预型的片上网络传输接口,论文设计的网络接口能有效提升片上多核处理器的并行计算性能。
片上网络; 网络接口; 单边通信; 直接存储访问
Class Number TP302
1 引言
在多核处理器时代,随着集成电路工艺技术的进一步发展,芯片集成度仍在不断提高。为了向芯片内的多核甚至众核处理器提供高效可扩展的通信互连手段,片上网络(Network on-Chip,NoC)[1]技术已成为热点问题被广泛研究。路由器和网络接口是片上网络的重要组成:路由器通过数据链路相互连接组成特定的网络,并按照一定的路由算法和交换策略实现数据包的转发;网络接口则负责处理单元与路由器之间的数据交互,根据通信协议完成数据包的打包和解包工作。路由器决定了片上网络的通信能力,而网络接口则决定了处理单元与片上网络的交互能力。在实际应用中,网络接口往往更加容易成为通信瓶颈而限制整个片上多处理器的性能,因此值得进一步对其开展优化设计。
目前,Radulescu[2]针对A thereal片上网络设计了一款网络接口,能为处理单元提供保证服务质量和尽力服务两种QoS策略,且兼容AXI、OCP等事务级总线协议。Daneshtalab[3]以优化访存带宽为目标设计了一种自适应网络接口,除了能提供QoS策略之外,还具有对数据包进行重排序的功能。此外,Saponara[4]设计了一款片上网络接口,集成了QoS策略、数据包重排序、错误处理及功耗管理等功能,具有较好的通用性。
本文从减少处理器干预、提高数据搬移效率的角度出发,设计了一款片上网络传输接口,通过定制网络单边通信协议和直接存储访问(DMA)手段对网络接口的数据包传输能力进行了优化。实验结果表明,对比不具备DMA传输功能的网络接口,本文设计的网络接口能有效提升片上多核处理器的并行计算性能。
2 片上网络概述
片上网络借鉴了大规模并行计算机的网络互连结构,以数据包的形式进行处理器核间通信,图1以3×3的mesh网络为例示意了其基本结构,主要包括如下组件:
1) 处理单元(Process Element,PE):处理单元负责具体的计算及数据包的发起和接收,其中可包含处理器核(Core),协处理器(CP),存储器(Mem)及I/O等资源;
2) 路由器(Router,R):路由器通过数据链路相互连接组成特定的网络,并按照一定的路由算法和交换策略实现数据包的转发;
3) 网络接口(Network Interface,NI):网络接口负责处理单元和路由器之间的数据交互,根据双方的协议完成数据包的打包和解包工作;
4) 数据链路(Link):数据链路连接相邻的路由器,是信号传输的载体。
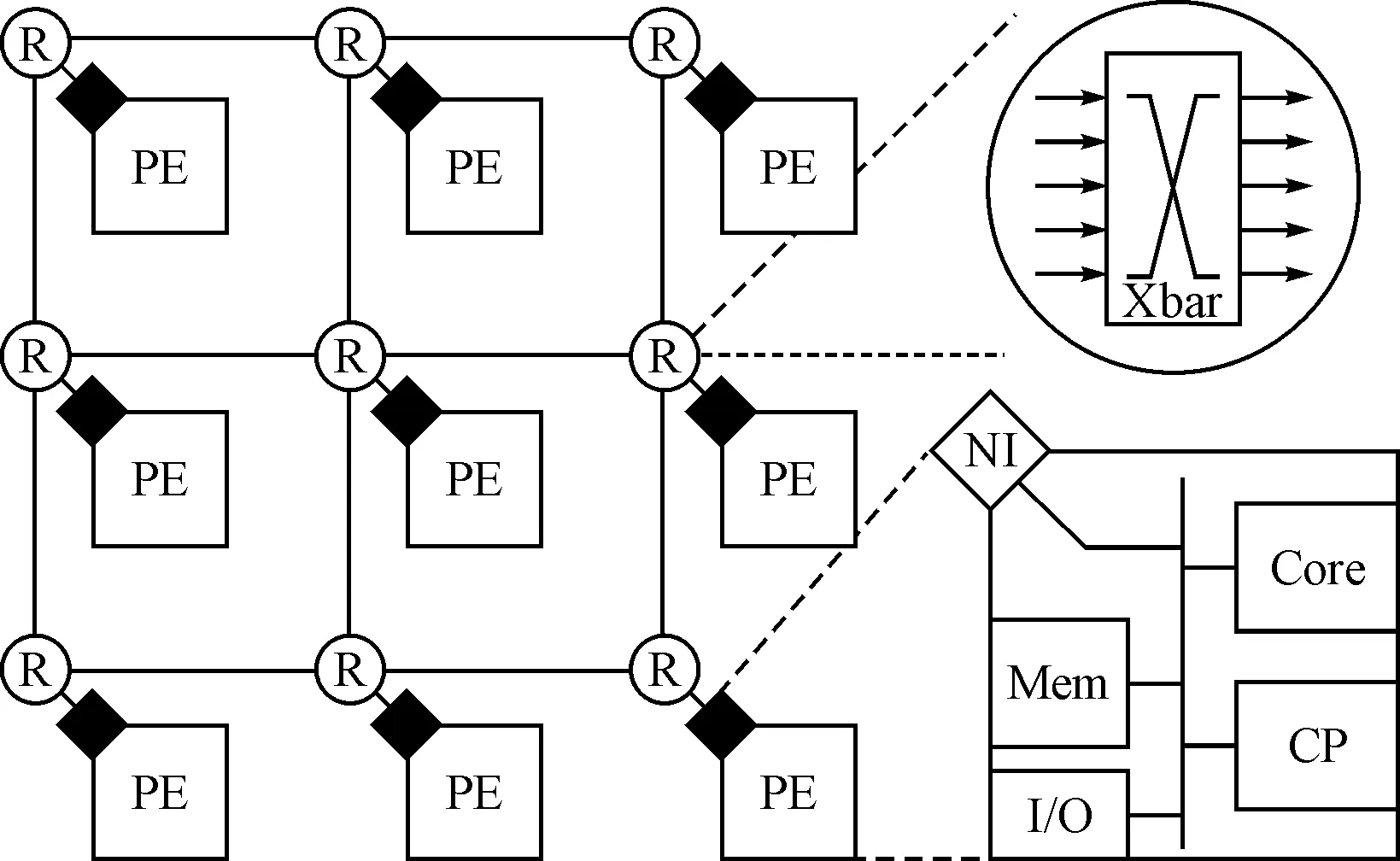
图1 片上网络结构示意图
当处理器间需要进行通信时,数据包首先通过源节点的网络接口进入路由器的输入队列,路由器再根据数据包中的路由信息计算其输出方向,并将其转发到相邻的路由器,然后重复该过程直到数据包到达其目的节点。最后,数据包被目的节点的网络接口接收,经过解析之后,其数据被存放到处理单元的存储器中供计算使用。
3 单边通信协议
根据虫孔(Wormhole)交换策略[5],一个数据包被划分为若干个微片(flit),其中位于数据包最前端和最尾端的微片分别被称为头微片(head flit,HF)和尾微片(tail flit,TF),中间部分的微片则被称为体微片(body flit,BF),这三种微片可进一步通过微片类型编码进行区分。数据包的头微片主要包含相关的路由信息,如源节点坐标(src_x和src_y)、目的节点坐标(dst_x和dst_y),以及数据包长度、冗余校验码等信息,尾微片和体微片则包含了具体待传输的数据。此外,在具有多个虚通道的片上网络中,微片中还包含了其所属的虚通道号(vcid),以使不同数据包的微片可以在数据链路上混合传输,从而提高数据链路的带宽利用率。
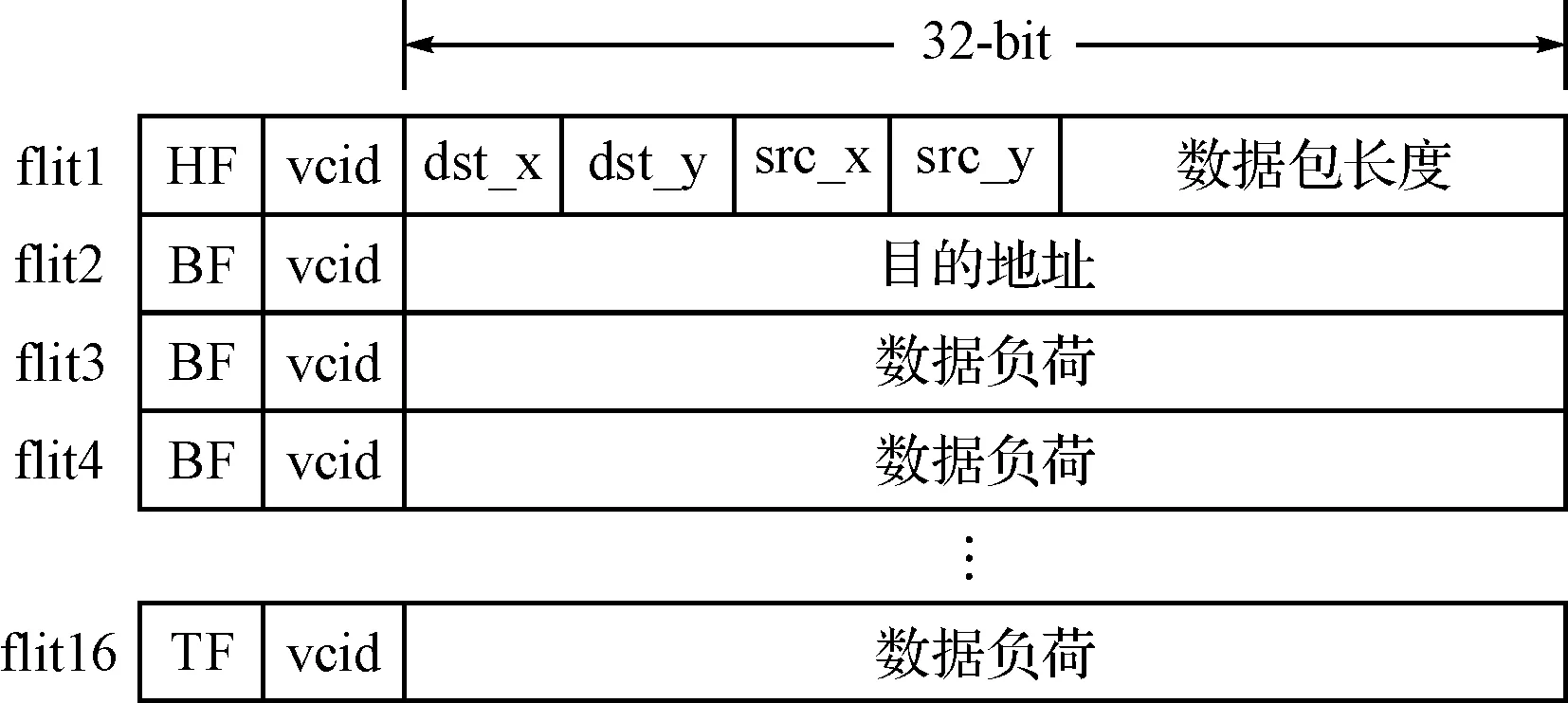
图2 数据包格式
为了减少处理器的干预、提高数据传输效率,本文对片上网络采用单边通信协议,其主要思想是在数据包中显式地包含数据的目的地址。图2示意了本文使用的数据包格式:一个数据包由至多16个微片组成,每个微片的数据负荷为32位;第一个微片为头微片,包含了路由信息及数据包长度信息;第二个微片包含了一个32位的目的地址,该地址指定了后续数据在目的节点中应被存放的位置;后续微片则包含了具体传输的数据。这种将目的地址包含在数据包中的单边通信方式使网络接口能直接将接收到的数据存入存储器,而无需处理器进行干预,因此有助于提升网络接口的数据接收能力。
4 网络接口设计
网络接口(NI)负责数据包的发送和接收工作,是处理单元与片上网络通信的接口。一方面,NI监听从网络到达该节点的微片,组装成完整的数据包,然后通知DMA控制器根据接收到的目的地址将数据存放到存储器中;另一方面,NI从处理器接收数据,将数据进行打包后传入片上网络。因此,NI的处理器端和网络端需分别满足嵌入式总线协议(本文采用AHB总线[6])和基于信用量(credit)的流控协议。
以具有两个虚通道(分别用VC0和VC1表示)的片上网络为例,图3示意了本文设计的网络接口结构,其中上半部为网络接收部分,下半部为网络发送部分。在网络接收部分,每个虚通道都对应了一个接收队列、数据包队列、目的地址寄存器和DMA写控制器(wDMA)。数据包的解析和接收是由接收控制状态机和wDMA控制器协同实现的,图4示意了两者的状态转换关系与协同工作方式。一方面,接收控制状态机对接收队列中的微片进行解析,剥离vcid和微片类型等信息后,将有效数据存入数据包队列;接收控制状态机检测到一个完整的数据包后,就通知相关的wDMA控制器直接将接收到的数据搬移到存储器中。另一方面,DMA写控制器(wDMA)接收到DMA传输请求之后,首先从数据包队列中读取出第一个微片,并将其记录为后续数据的目的地址;然后,wDMA控制器向AHB仲裁器发送总线请求信号,申请对总线的所有权;接下来,wDMA控制器发起AHB总线传输操作,将数据包队列中的数据按照先前记录的目的地址连续地存入存储器中;等到数据包队列为空之后,接收控制状态机和wDMA控制器均返回空闲状态。

图3 网络接口结构
在网络发送部分,处理器将待发送数据的起始地址(针对发送节点而言)和数据长度写入相关的DMA读控制器(rDMA)中,再由rDMA将数据从存储器搬移到发送端的数据包队列。发送控制状态机再将数据包的目的地址(针对目的节点而言)与数据包队列中的数据进行打包后传入网络。另外,由于VC0和VC1可能同时发送数据包,因此在发送控制状态机中还进行了虚通道间的仲裁,仲裁的结果用于选择相应的数据进入网络。

图4 接收控制状态机及wDMA控制器状态转换图
为了简化接收控制状态机对完整数据包的探测过程,规定网络中数据包的长度不能大于NI中数据包队列的深度,以使数据包队列可以存放一个完整的数据包。在本文中,NI接收部分和发送部分的数据包队列深度均被设置为16,因此网络中的数据包最长不能超过16个微片。
5 验证及性能分析
5.1 验证及测试环境
为了对设计的片上网络传输接口进行验证及性能测试,本文将网络接口集成到了一个4×4 mesh片上多处理器验证环境中,图5示意了该多处理器的结构:每个节点均为一个基于AHB总线的小型系统,其中包含了一个小型RISC处理器(μP)、私有SRAM存储器、片上网络路由器及网络接口。

图5 4×4 mesh片上多处理器验证环境
为了对网络接口的性能进行对比分析,本文选取了并行FFT计算[7~10]作为应用案例来对该16核系统进行性能测试。其中,测试组采用本文设计的网络接口,数据在存储器和网络接口间的搬移采用DMA方式实现;而对比组采用非DMA操作的网络接口,数据的搬移是以中断的方式通知处理器μP干预实现。
5.2 案例测试
图6给出了在16核系统中进行单精度浮点FFT计算的结果,其中横轴表示输入序列长度的对数,纵轴为计算过程所消耗的时钟周期。从图5可以看出,对比采用CPU干预型网络接口的16核系统,采用DMA传输型网络接口的16核系统具备了更高的并行计算性能。当FFT序列长度为1024时,本文设计的网络接口使FFT计算耗时降低了20%左右,且随着FFT序列长度的增加,DMA传输型网络接口对16核系统并行计算性能的提升更加明显。
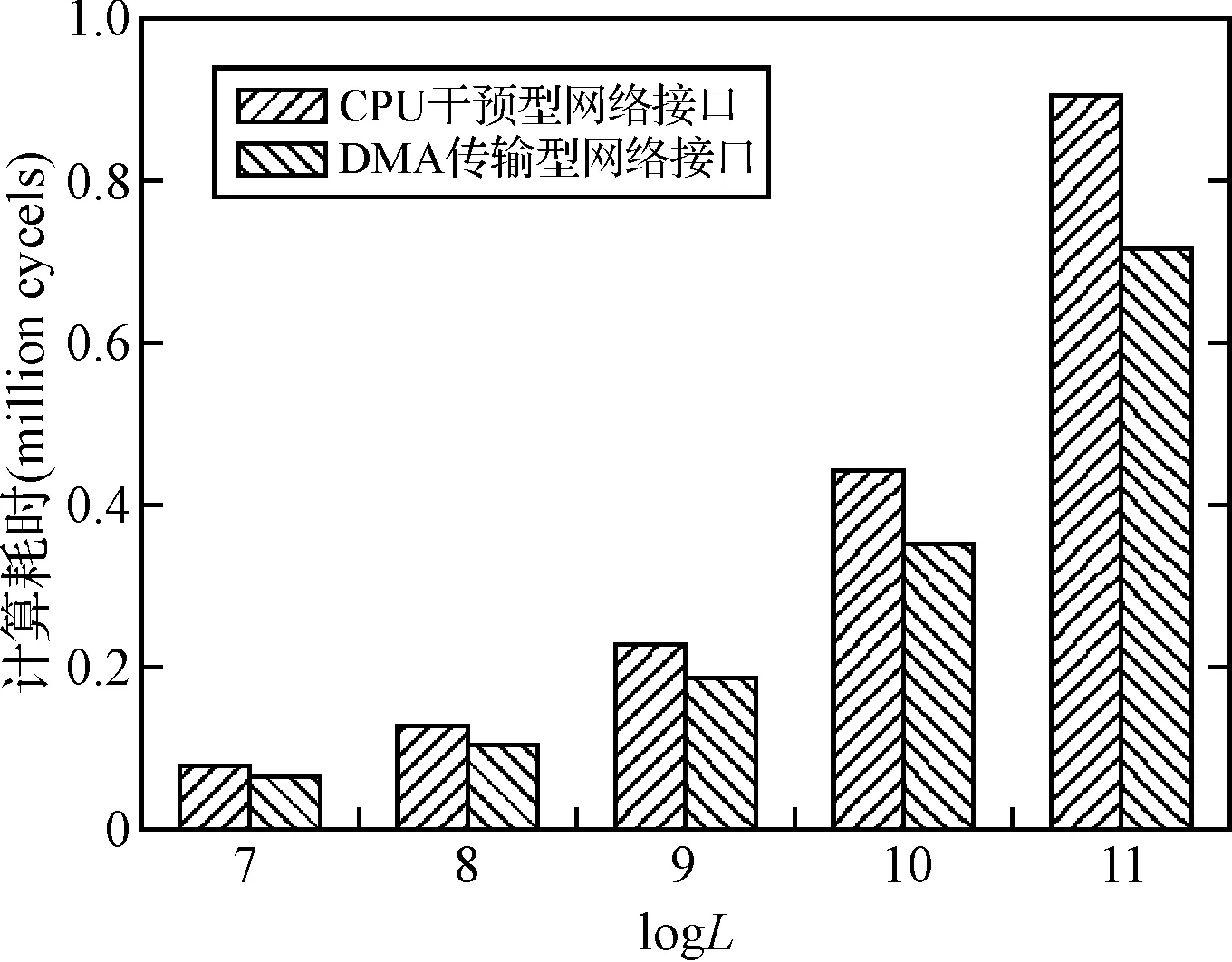
图6 16核片上多处理器环境下的FFT并行计算耗时
导致FFT计算性能提升的原因主要有两点。1) 由于本文设计的网络接口通过DMA方式实现数据负荷的搬移,而非通过CPU进行显式的搬移,因此缩减了数据包的发送和接收延时,减低了处理器核间通信带来的性能损耗; 2) 网络接口采用的DMA传输方式减少了CPU对数据包的干预,使得CPU能更加专注地进行数据运算,因此应用程序的并行计算性能得到了提升。
6 结语
本文设计了一款片上网络传输接口,实现了处理单元与片上网络间的高效数据通信。通过定制单边通信协议和直接存储访问,降低了数据包传输延时并减少了处理器的干预。16核片上多处理器环境下的并行FFT计算结果表明,对比CPU干预型的片上网络传输接口,本文设计的网络接口能将并行计算性能提升16%~20%。
[1] Dally W J, Towles B. Route packets, not wires: on-chip interconnection networks[C]//Proc.of Design Automation Conference. Las Vegas, USA: ACM Press,2001:684-689.
[2] Radulescu A, Dielissen J, Pestana S G, et al. An efficient on-chip NI offering guaranteed services, shared-memory abstraction, and flexible network configuration[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2005,24(1):4-17.
[3] Daneshtalab M, Ebrahimi M, Lilieberg P, et al. Memory-efficient on-chip network with adaptive interfaces[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2012,31(1):146-159.
[4] Saponara S, Bacchillone T, Petrle E, et al. Design of a NoC interface macrocell with hardware support of advanced networking functionalities[J]. IEEE Transactions on Computers,2014,63(3):609-621.
[5] Dally W J, Towles B P. Principles and practices of interconnection networks[M]. San Francisco, USA: Morgan Kaufmann,2004:237-244.
[6] AMBA Specification[EB/OL]. http://www.arm.com/.
[7] 张林波,迟学斌,莫则尧,等.并行计算导论[M].北京:清华大学出版社出版,2006:164-268.
[8] 朱晓静.片上网络的结构设计与性能分析[D].合肥:中国科学技术大学,2008.
[9] 付方发.基于片上网络的MPSoC关键技术研究[D].哈尔滨:哈尔滨工业大学,2012.
[10] 胡哲琨.面向片上多处理器的互连网络路由技术研究[D].北京:中国科学院大学,2013.
A NoC Network Interface Based on One-Side-Communicating Protocol
LIU Chuanbo
(No.1 Canglong North Road, Wuhan 430205)
In order to improve the data exchanging capability between Process Elements(PE) and Network on-Chip(NoC), a NoC Network Interface(NI) is designed based on the one-side-communicating protocol. Through Direct Memory Accessing(DMA), an efficient data movement between NI and memory is achieved. Also, the packet sending and receiving latency is reduced and the CPU interference is cut down. Experimental results in a 16-core Chip Multi-Processor(CMP) environment show that, compared with a NI that needs the CPU to interfere, the designed NI can efficiently improve the parallel computation performance of CMPs.
network on-chip, network interface, one-side-communication, direct memory access
2014年5月10日,
2014年6月15日 作者简介: 刘传波,男,博士,研究方向:系统工程。
TP302
10.3969/j.issn1672-9730.2014.11.031
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
净水技术(2022年1期)2022-01-13
科技资讯(2021年10期)2021-07-28
民用飞机设计与研究(2020年4期)2021-01-21
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
物联网技术(2018年8期)2018-12-06
汽车实用技术(2016年10期)2016-11-21
