
单向链表快速排序算法*
2014-08-04 03:27郭显娥
计算机工程与科学 2014年1期
白 宇,郭显娥
(山西大同大学数学与计算机科学学院,山西 大同037009)
1 引言
单向链表是一种典型的链式存储结构[1],目前多使用 Two-way MergeSort算法[2]对单向链表进行排序,虽然Two-way MergeSort算法时间复杂度为 O (n log2n)[1~4],但 其 空 间 复 杂 度 高 达O(n)[1~4],在一些嵌入式系统研发中,由于对存储空间的使用数量有较严格的限制,故并不普遍适用。
排序算法中适应性最强且应用最广的是基于关键字比较的排序算法[1~4],因为排序的本质就是按照一定规则相互比较关键字以确定其顺序,即关键字可比较是排序算法的充要条件[3]。而其它诸如基于哈希表的排序算法或基于对关键字运算的排序算法,由于对关键字有一些特殊要求,其应用相对较窄[4~6]。
在基于关键字比较的排序算法中,已证明时间复杂度最小可达O(nlog2n)[4~6],其中应用最广泛的有QuickSort和HeapSort,HeapSort算法的常量因子较高[5,6],QuickSort算法的实测平均性能最优[5,6]。但是,QuickSort算法最大不足之处在于,由于其基于可索引存储结构设计(一般为数组或索引表),因而无法用于链式存储结构[4],而链式存储结构的实际应用非常广泛,例如动态存储管理、动态优先级调度等等。本文针对上述问题,以QuickSort的分治策略[1~6]为基础,提出一种可用于单向链表的QuickSort算法,其平均时间复杂度(包含最优及最差情况)为O(nlog2n),辅助空间复杂度为O(0),平均递归栈空间复杂度为O(log2n),从而实现了对链式存储结构高效排序的同时不增大空间复杂度。
2 算法分析
2.1 分治策略
QuickSort算法需要从线性表两端逐一选取元素与枢轴元素进行比较[1~6],而单向链表只能从一个方向顺序访问,故无法做到;即使是双向链表,QuickSort算法也要求可以任意交换两个元素,单向或双向链表也因不能随机访问而无法做到。因此,若要对单向链表实施分治策略,只能将单向链表的首节点作为枢轴节点,然后从单向链表首部的第二个节点开始,逐一遍历所有后续节点,并将这些已遍历节点的key与枢轴节点的key进行比较,根据比较结果,重新将这些节点链接为两个单向链表,其中之一所包含节点的key均小于枢轴节点的key;另一个所包含节点的key均大于或等于枢轴节点的key。这样,便得到两个规模更小的单向链表,然后对其递归执行同样的操作,并将其分别链接到枢轴节点的前部和后部。当在某一层递归中,单向链表的节点数量小于或等于1时,则为递归出口。
为了能在每次划分后将规模更小的两个单向链表链接到枢轴节点上,必须记录各自的尾节点位置,即需要设置两个指向尾节点的指针。本文所述算法中将由key小于枢轴节点key构成的单向链表定义为less;由key大于或等于枢轴节点key构成的单向链表定义为more。这样,less单向链表的首节点指针设定为lessHead,尾节点指针设定为lessTail;more单向链表的首节点指针设定为moreHead,尾节点指针设定为moreTail;当前正在遍历的节点指针设定为current;由于枢轴节点就是未排序的单向链表的首节点,故枢轴节点指针设定为listHead。
设节点包含两个域:key表示用于比较的关键字(图中的k1,k2,…,kn等),next表示指向下一节点的指针(图中节点的空白区域)。初始化状态如图1所示,此时current为listHead的next域。
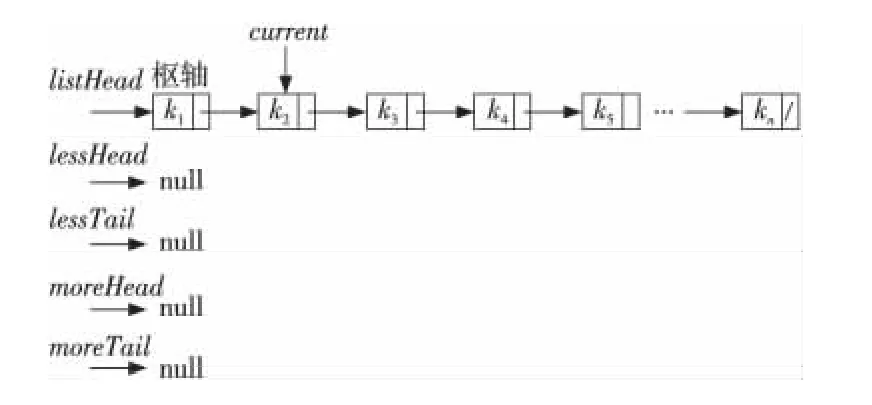
Figure 1 Initializaton state图1 初始化状态
当遍历单向链表的两个节点后,状态如图2所示,设k2<k1,k3≥k1。

Figure 2 State of traversing two nodes图2 遍历两个节点后的状态
当继续遍历单向链表的k4和k5节点后,状态如图3所示,设k4<k1,k5≥k1。
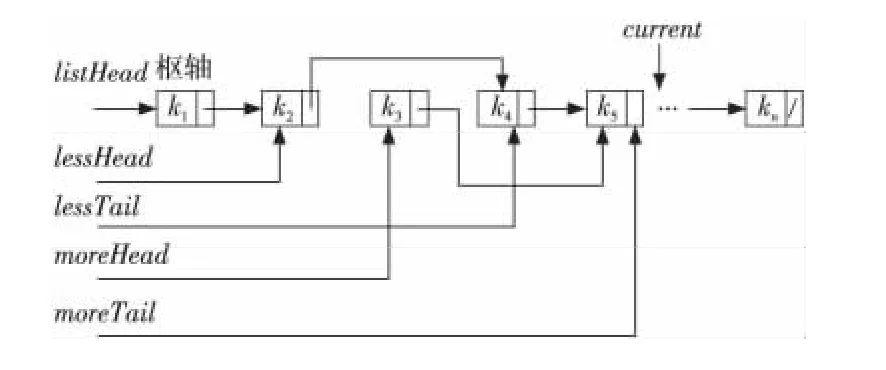
Figure 3 State of traversing four nodes图3 遍历四个节点后的状态
当单向链表遍历结束后,与可索引表的QuickSort算法相类似[1~6],亦即完成了一趟划分,如此递归进行,便可完成整个单向链表的排序。之所以需要设定两个指向单向链表尾节点的指针lessTail和moreTail,一是如前文所述,简化将less和more单向链表链接到枢轴节点前、后部的过程;二是简化向less和more单向链表中添加节点的过程,否则需逐一遍历节点,以寻找该单向链表的尾节点,将耗费时间复杂度为O(n)的操作。
2.2 算法正确性分析
算法正确性需要从两个方面进行分析,其一,当以枢轴节点为中心进行一趟划分后,枢轴节点前后两个单向链表中节点的key是否相对于枢轴节点有序;其二,递归过程是否一定有出口,即递归过程是否一定可以在有限步骤后结束。
针对第一个问题,通过遍历并重新链接原单向链表为两个新的子单向链表进行解决。在一趟划分过程中,从枢轴节点listHead的下一个节点开始依次遍历单向链表中的每个节点,如果该节点的key小于枢轴节点listHead的key,则将该节点链接到新的子单向链表lessHead中;否则将该节点链接到新的子单向链表moreHead中。当遍历结束时,所得的子单向链表lessHead中的所有节点的key一定小于枢轴节点listHead的key。不失一般性,如图3,设节点k2<k1,k4<k1,则由k2,k4…构成的子单向链表lessHead中的所有节点的key均小于枢轴节点listHead的key;同理,由k3,k5…构成的子单向链表moreHead中的所有节点的key均大于或等于枢轴节点listHead的key。根据2.1节的描述,此时将枢轴节点listHead链接到lessTail后,再将moreHead链接到listHead后,不失一般性,如图3,枢轴节点k1成为两个子单向链表的分割点。因此,以枢轴节点为中心进行一趟划分后,枢轴节点前后两个单向链表中节点的key相对于枢轴节点是有序的。
针对第二个问题,通过划分后所形成的两个子单向链表的规模不断减小,并且当子单向链表节点数量小于或等于1时通过终止递归调用来解决。一趟划分后无论划分结果如何,枢轴节点的位置已经固定,即到达了枢轴节点在排序后所应处于的最终位置上,因此,枢轴节点将不再参与下一轮递归调用的划分过程。因此,在一趟划分后对两个子单向链表递归调用划分算法时,其规模(节点数量)总是在不断减小的。当在某一层递归调用划分算法时,如果lessHead等于null,或lessHead等于lessTail,则说明该子单向链表中的节点数量小于或等于1,显然,可以认为该子单向链表已经有序,故而可以终止递归调用;同理,如果moreHead等于null,或moreHead等于moreTail,同样可以终止递归调用,即此时便是递归出口。
通过上述两个方法,可以保证本文所述算法的正确性。
2.3 算法复杂度
2.3.1 时间复杂度
通过2.1节的分析容易得出,一趟划分后,枢轴节点对less和more单向链表的最优情况是均分(即节点数量之差不大于1);最差情况是其中之一为空;平均而言,枢轴节点可能出现在1到n的某个位置,显然包括最优及最差情况。现就三种情况分别分析如下:
第一种情况,每次划分都将less和more单向链表均分,则递归栈深度为 log2n+1,即需递归log2n次[7,8],设需要时间T(n)。第一次划分需对key做n次比较;第二次划分,两个单向链表各自需要时间T(n/2);然后不断划分,可得不等式推断如式(1):

由式(1)可知,本文所述算法在最优情况下的时间复杂度为O(nlog2n)。
第二种情况,每次划分后,less或more单向链表中有且仅有一个为空,则共需进行n-1次划分,可得:
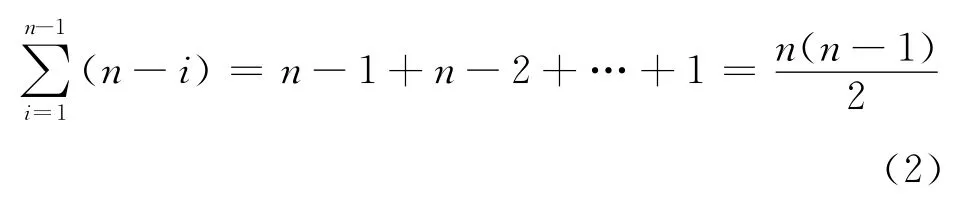
由式(2)可知,本文所述算法在最差情况下的时间复杂度为O(n2)。
第三种情况,平均而言,设枢轴节点在划分后处于第k个位置(1≤k≤n),可得:
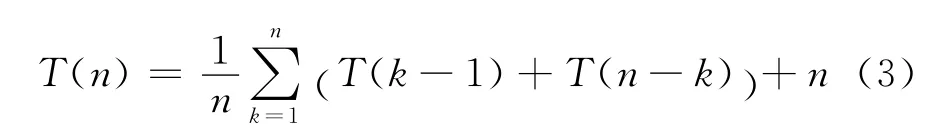
式(3)等价:
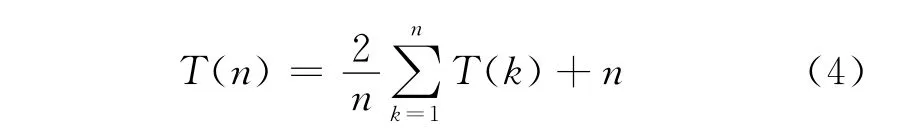
式(4)两边同乘n,得:
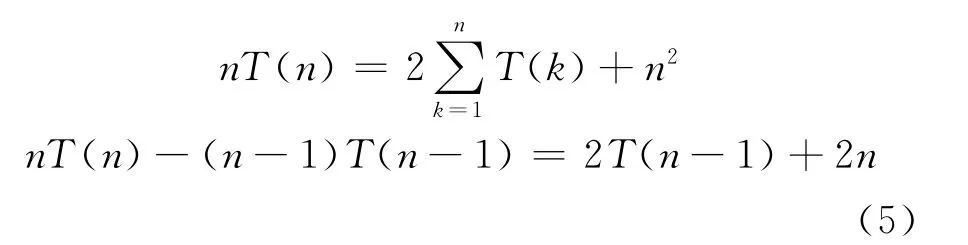
式(5)整理得:
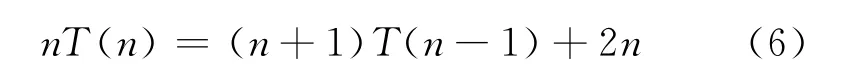
式(6)两边同时除以n(n+1),得:
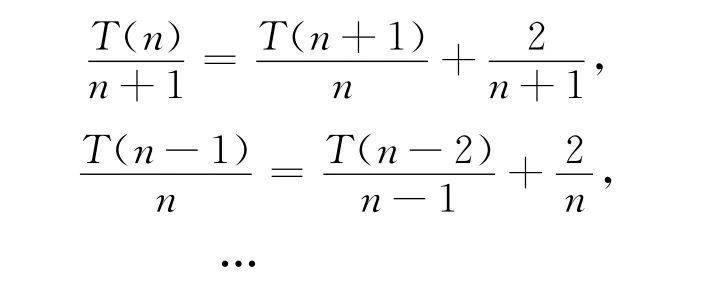
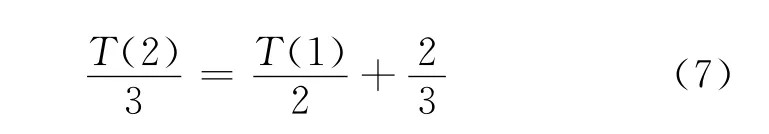
将式(7)中的等式相加,并使用公式:
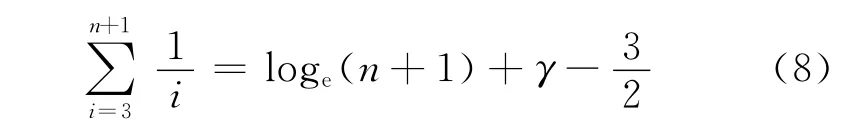
式(8)中γ≈0.5772,即欧拉常数,可得:
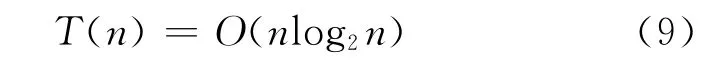
由式(9)可知,本文所述算法在平均情况下(包含最优及最差情况),时间复杂度为O(nlog2n),且递归栈平均深度为Θlog2n(Θ为常数)。
2.3.2 空间复杂度
由于本文所述算法采用递归结构,因此空间复杂度需从两个方面进行分析:
(1)用于排序的辅助空间。从2.1节的分析可知,由于算法在排序过程中仅仅重新链接原单向链表的节点,并不需要任何辅助空间存储节点。完全不同于针对可索引存储结构的排序算法,需要辅助空间进行元素交换[1~5]。因此,辅助空间复杂度为O(0)。
(2)递归栈空间。从2.3.1节的分析可知,算法的递归栈平均深度为Θlog2n(Θ为常数),因此平均递归栈空间复杂度为O(log2n)。
3 算法描述
单向链表快速排序算法描述如下,具体实现代码不再赘述:
步骤1 算法接收两个指针,其中listHead指向单向链表首节点,listTail为空指针,划分过程中,listTail将指向单向链表的尾节点,划分后用于链接less单向链表到枢轴节点前。
步骤2 如果单向链表listHead仅有一个节点,则说明已有序,本层递归结束,返回listHead。
步骤3 令lessHead、lessTail、moreHead和moreTail为空,令current为listHead的next域,即单向链表的第二个节点。
步骤4 如果current节点为空,则转入步骤13。
步骤5 如果current节点的key小于枢轴节点(即listHead)的key,则current节点应链接到less单向链表,转入步骤6;否则,current节点应链接到more单向链表,转入步骤9。
步骤6 修改lessTail指针使其指向current节点。如果lessHead为空,则转入步骤7;否则转入步骤8。
步骤7 将current节点链接为less单向链表的首节点。
步骤8 将current节点链接为less单向链表的尾节点。
步骤9 修改moreTail指针使其指向current节点。如果moreHead为空,则转入步骤10;否则转入步骤11。
步骤10 将currnet节点链接为more单向链表的首节点。
步骤11 将currnet节点链接为more单向链表的尾节点。
步骤12 将current节点移动到单向链表的下一个节点。
步骤13 如果more单向链表不为空,则转入步骤14;否则转入步骤18。
步骤14 标记more单向链表的结束位置,即置moreTail的next域为空。
步骤15 递归调用本算法,继续划分more单向链表,传入moreHead和moreTail。
步骤16 将经过递归排序的more单向链表链接到枢轴节点后。
步骤17 修改listTail指针使其指向more-Tail,以便本层递归结束后供上层递归过程使用。
步骤18 由于more单向链表为空,则枢轴节点便是尾节点,即置listHead的next域为空。
步骤19 修改listTail指针使其指向listHead。
步骤20 如果less单向链表不为空,则转入步骤21;否则转入步骤24。
步骤21 标记less单向链表的结束位置,即置lessTail的next域为空。
步骤22 递归调用本算法,继续划分less单向链表,传入lessHead和lessTail。
步骤23 将经过递归排序的less单向链表链接到枢轴节点前。
步骤24 由于less单向链表为空,则枢轴节点便是首节点,即置lessHead为listHead。
步骤25 本层递归结束,返回lessHead。
4 实验测试
4.1 与单向链表排序算法实测比较
当前广泛用于单向链表且时间复杂度为O(nlog2n)的排序算法仅有 Two-way MergeSort一种[5],因此在实验测试中,选择该算法作横向比较,无序数据量分别取25 k、50 k、75 k、100 k和500 k,数据呈均匀随机分布,范围为[0,数据量*2)的正整数[9~12]。使用 C#2010编译,在Intel i5 750(2.66 GHz)上运行。取5个不同的随机数据集,每个数据集测试10次,计算算术平均值,结果如表1所示。
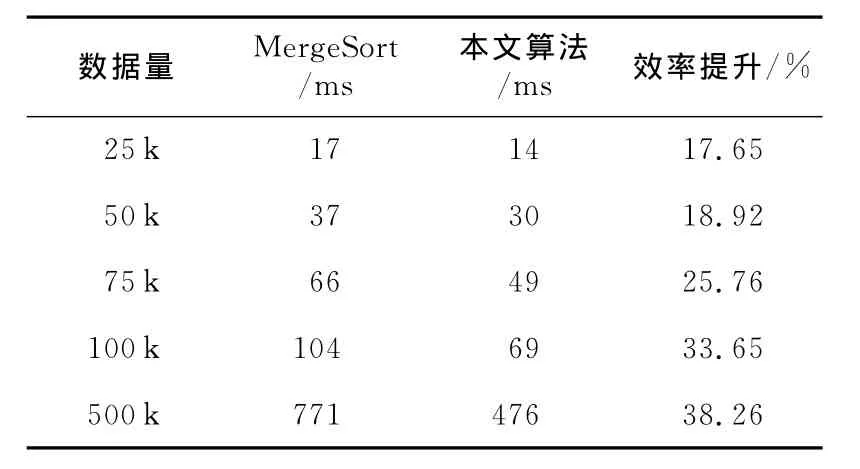
Table 1 Test data 1表1 实测数据一
由表1可知,针对单向链表排序,本文所述算法比Two-way MergeSort算法效率平均提升约26.85%。
4.2 与线性表QuickSort算法实测比较
由于线性表QuickSort算法枢轴节点的选取有多种方式[4~6],为了避免由于枢轴节点选取的不同而导致排序效率的差异[4~6],需要一致的比较基础,故本文选择了使用首节点作为枢轴节点的线性表QuickSort算法作为对比算法,测试数据量、分布、范围以及测试方法均与4.1节相同,结果如表2所示。
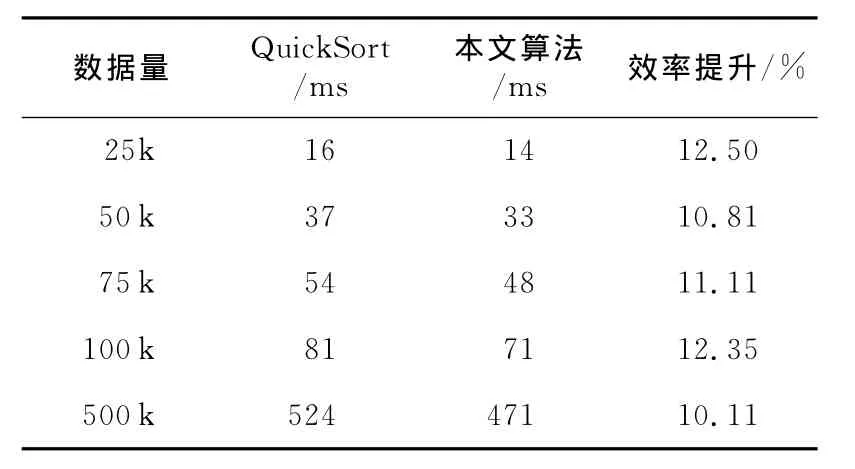
Table 2 Test data 2表2 实测数据二
由表2可知,针对相同数据,本文所述算法比基于线性表的QuickSort算法效率平均提升约11.38%。
5 结束语
综上所述,本文所述算法的平均时间复杂度(包含最优及最差情况)为O(nlog2n),已达到基于比较的排序算法的时间复杂度的理论极限;其辅助空间复杂度为O(0),即无任何辅助空间开销;平均递归栈空间复杂度为O(log2n),达到了除尾递归[7~8,13,14]以外的最小递归栈空间复杂 度。因此,本文所述算法的优势是高效率、低开销,各项指标较为均衡,是当前时间复杂度等于或接近O(nlog2n)排序算法中为数不多的可应用于单向链表的排序算法之一。不足之处是由于单向链表不可索引,故划分算法中不能像基于线性表的QuickSort算法那样选取中值节点[4~6]作为枢轴节点。根据文献[5]的实验结果,基于线性表的QuickSort算法使用中值节点作为枢轴节点后,在均匀和高斯随机数据分布状态下,实测有2%~4%的效率提升。
[1] Joseph B.Data structure programming[M].New York:Springer Verlag,2005.
[2] Main M,Savitch W.Data structure and other objects using C++[M].Boston:Addison-Wesley,2004.
[3] Kleinberg J,Tardos E.Algorithm design[M].Boston:Addison-Wesley,2005.
[4] Thomas H C,Charles E L,Roonald L R,et al.Introduction to algorithms[M].Massachusetts:Mit Pr,2005.
[5] Sedgewick R,Wayne K.Algorithms[M].4th edition.New Jersey:Pearson Education,2012.
[6] Hagerup T.Algorithm theory—Swat 2004[M].New York:Springer Verlag,2004.
[7] Cai Jing-qiu.Note of on recursive program transformation[J].Microelectronics & Computer,1995,12(6):45-46.(in Chinese)
[8] Davies J,Schneider S.Recursion induction for real-time processe[J].Formal Aspects of Computing.2010,19(2):119-127.
[9] Wang Xin-cheng,Sun Hong.Research&design on high-performance pseudo-random number generator[J].Computer Engineering and Applications,2004,40(11):20-23.(in Chinese)
[10] Qian Hong-bing.The automatic generation of test data[J].Computer Engineering,1996,22(2):13-14.(in Chinese)
[11] Ye Shao-kang,Li Zheng.True random number generator based on mixed-signal circuit[J].Computer Engineering and Design,2012,33(4):1602-1606.(in Chinese)
[12] Ma Xin-sheng,Hu Bin.Research on derivative estimation of periodic random data with hidden periodical model[J].Journal of Nanchang University(Engineering & Technology),2011,33(2):200-204.(in Chinese)
[13] Pitts A M.Structural recursion with locally scoped names[J].Journal of Functional Programming,2011,21(3):235-286.
[14] Jaime A,Bohórquez V.An elementary and unified approach to program correctness[J].Formal Aspects of Computing,2010,7(9):38-43.
附中文参考文献:
[7] 蔡经球.关于递归程序变换的注记[J].微电子学与计算机,1995,12(6):45-46.
[9] 王新成,孙宏.高速伪随机数发生器的设计与实现[J].计算机工程与应用,2004,40(11):20-23.
[10] 钱红兵.测试数据的自动生成[J].计算机工程,1996,22(2):13-14.
[11] 叶少康,李峥.基于数模混合的真随机数发生器[J].计算机工程与设计,2012,33(4):1602-1606.
[12] 马新生,胡斌.潜周期模型在周期性随机数据的数值微分中的应用研究[J].南昌大学学报(工科版),2011,33(2):200-204.
猜你喜欢
计算机工程与应用(2022年16期)2022-08-19
唐山师范学院学报(2022年3期)2022-07-28
露天采矿技术(2021年1期)2021-12-30
纺织科学研究(2021年6期)2021-12-02
数学小灵通(1-2年级)(2021年9期)2021-10-12
成都信息工程大学学报(2019年2期)2019-08-28
第二课堂(课外活动版)(2019年12期)2019-02-10
江西社会科学(2018年8期)2018-08-29
成都信息工程大学学报(2018年1期)2018-05-31
电网与清洁能源(2015年5期)2015-12-29
