
基于随机蕨的实时车辆匹配
2014-08-06 11:26杨晨晖刘守达王子明郭义凡
厦门大学学报(自然科学版) 2014年2期
杨晨晖,刘守达,王子明,郭义凡,李 辉
(厦门大学信息科学与技术学院,福建 厦门 361005)
车辆匹配是智能交通系统的重要组成部分,其在停车场智能管理、道路监控、高速路自动收费等方面有着广泛的应用前景.
基于特征的匹配算法按照描述方式的不同,目前主要分为两大类,一类是用于处理边缘、角点等局部特征的强特征描述,目前使用最广泛的是尺度不变特征(SIFT)算法,其主要思想最初是由David Lowe提出[1].目前已经有很多研究人员在SIFT算法的基础之上对算法进行了改进和完善.主要有2004年Ke等[2]提出的PCA-SIFT算法[2];2006年Bay等[3]提出快速SIFT(SURF)算法.2009年Yu提出仿射尺度不变特征变换(ASIFT)算法[4];另一类是以提取自然特征点的方式将特征的匹配转化为多类别分类问题.其中最具代表的是Lepetit等[5]提出的随机树特征匹配算法,将宽基线特征匹配问题转化为分类问题.随机树特征匹配算子不需要强特征描述.将计算量大的工作转移到训练阶段,利用基准图像上以稳定特征点为中心的邻域块作为训练样本,并用随机树分类器对其进行分类.在线阶段则用训练好的分类器对待匹配图像上检测到的特征点邻域块进行分类,从而达到匹配的目的.该类算法需要离线训练,因此限制了其应用场景,但是在条件允许其进行离线训练的情形下,该类算法在在线运行阶段能够快速准确甚至实时地进行匹配,因此其也得到了广泛的应用.
本文在前人研究的基础上,将随机蕨引入到车脸匹配领域中.随机蕨算法由Lepetit等[6]最早提出,是对基于随机树算法的进一步改进.将随机树的层次结构特征改为了非层次结构特征.随机蕨将宽基线图像匹配转化为机器学习技术问题,将运算量较大的特征匹配部分转移到分类器训练中.本文研究基于随机蕨的车辆匹配方法,并克服传统匹配速度慢的特点,从而实现对车辆准确、实时的匹配.
1 快速车脸定位
车辆大部分显著特征的“车脸”的概念,即车辆在多尺度、多视角下具有特征不变性的区域.在交通场景中相对于复杂的背景,车辆上的特征点显得较少,背景上的特征点将很大程度上的干扰到车辆匹配效果,并且使匹配过程更加费时.本章首先对车辆可疑区域以及车牌区域的定位,并在此基础上,结合先验知识,很好地对“车脸”进行定位;最后给出了“车脸”的实验结果,并对其进行了分析.
1.1 车辆可疑区域确定
要进行车辆区域确定,可以先通过背景差分将所有非背景的前景目标分割出来,然后进行阈值化处理,获得二值化的差分图,并通过Canny算子获得车辆的边缘,最后通有效性分析确定车辆可疑区域(如图1).

图1 车辆可疑区域定位流程图Fig.1 Interest region of vehicle extraction
1.2 快速车牌定位
首先对图像进行预处理,主要包括彩色图像灰度化和图像局部增强以及竖直边缘提取和背景曲线与噪声滤除.本文采用Zheng等[7]提出的三次扫描法滤除背景曲线和噪声.然后,利用滑动窗口法对车牌进行初定位.最后利用水平扫描法[8]对候选车牌图像区域进行逐行扫描进行细定位.

图中,车牌定位结果用红色小矩形标出,车辆可疑区域用绿色矩形标出.结合车牌定位和车辆可疑区域定位结果,得到车辆位置,使用红色矩形标出.图2 车脸定位结果Fig.2 Cars face location
1.3 车脸定位
设检测到的车辆区域的左右边界离车牌的左右边界的距离分别为l1和l2,则取车脸的左右边界分别为min(l1,l2)加上车牌的左右边界.同时考虑到车辆可疑区域提取时在边缘提取时可能会使车辆的真实区域内缩,因此将获取的车脸的左右边界向两边扩展1/4个车牌宽度(如图2).
2 基于随机蕨的实时车辆匹配
为了能对提取特征点进行快速匹配,采用同随机树特征匹配算法[6]类似的基于随机蕨的特征匹配算法,将宽基线图像匹配转化为机器学习技术问题将运算量较大的特征匹配部分转移到分类器训练中.离线阶段,建立并训练随机蕨分类器,在线阶段,将检测到的特征点进行分类,获取粗匹配结果,然后用改进的顺序抽样一致性(PROSAC)算法去除误匹配.并通过实验说明,本文的算法能够很好地进行实时车辆匹配.
2.1 快速多尺度特征点提取
车辆图片平坦部分较多,导致特征点数目较少,同时为了使检测到的特征点具有尺度不变性,建立多尺度金字塔,分别对每个尺度寻找其显著特征点.这样即能使检测到的特征点满足尺度不变的特性,又能解决车辆区域较平坦、检测到的特征点较少的缺点.同时其算法运行时间也不会提升很大,还是能够很好地满足实时的要求.对不同尺寸的多幅图片进行实验,得到实验结果如表1.
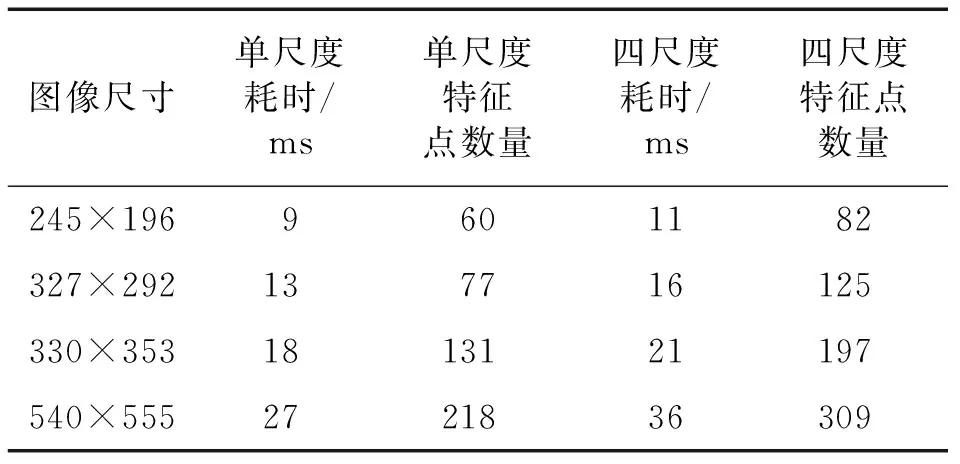
表1 多尺度耗时分析Tab.1 Multi-scale time-consuming analysis
2.2 随机蕨算法
随机蕨算法由Lepetit等[6]最早提出,是对基于随机树算法的进一步改进.将随机树的层次结构特征改为非层次结构特征,如图3所示,将随机树的每层结点选取相同的决策,则树结构可以转化为结构相对单一的蕨结构.

图3 随机蕨结构Fig.3 The structure of random ferns
基于随机蕨的朴素贝叶斯分类器的基本思想和基于随机树的特征识别匹配类似,可以把基准图像描述为H个显著特征点,并为这H个显著的特征点建立一个数据集K={k1,…,kH},同时将每个特征点k及以其为中心的邻域块p(k)可能出现的各种形式作为一类ci,i=1,…,H.在运行阶段,对输入图像每个特征点kinput及以其为中心的邻域块p(kinput),判断它是否属于H个特征点中的一个类ci.
设fj,j=1,…,N为特征点邻域块p(kinput)产生的二元特征集,令p(kinput)的尺寸为L×L(一般取L=32),则fj取决于邻域块p(kinput)中在随机生成的两像素位置dj1和dj2的灰度值Idj1和Idj2的大小,这些随机位置在分类器训练时生成,并用在离线训练与在线运行阶段,即
(1)
p(kinput)所属的类别可以定义为
(2)
式中C表示类别,式(2)可由贝叶斯公式转化为
P(C=ci|f1,f2,…,fN)=
(3)
因为先验概率P(C)为均匀分布,且公式(3)分母部分与类别无关,所以式(2)可以化为
(4)
由于fj之间的独立性,
(5)
为了降低存储量并保证fj之间的相关性,用半朴素贝叶斯分类器来代替朴素贝叶斯分类器.将fj分为M组,每组包含S=N/M个二元特征,在半朴素贝叶斯模型下,可以认为不同组的二元特征之间相互独立,而同组内二元特征之间具有相关性,同时可以将这些组定义为蕨特征.则公式(3)中可以转化为
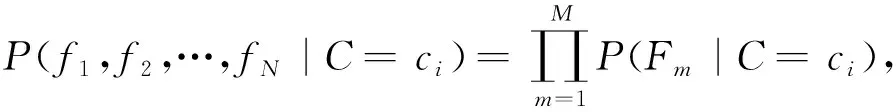
(6)
式中Fm=[fσ(m,1),fσ(m,2),…,fσ(m,S)],m=1,…,M表示第m个蕨,fσ(m,j)表示范围为1,…,N的随机数.由此可知p(kinput)的所属类别为
(7)
2.3 训 练
对基准图像进行一系列的操作来合成虚拟的特征图像样本集合.可以在基准图像I0上提取特征点及其周围(32×32)像素的邻域块,对其进行仿射变换获得训练集Btrain.
随机产生Ntotal幅虚拟图像,并将这些图像Ii中检测到的特征点对应到基准图像I0中,并记录特征点k在虚拟图像中被检测到的次数,即可求得特征点k的被检测概率为
(8)
式中Ndetected为特征点k在虚拟图像中被检测到的次数.因此,可以取概率P(k)最高的H个特征点作为基准图像的稳定特征点,并将其作为分类器的初始类进行分类训练,即各特征点及其邻域块所属的类为ci,i=1,…,H,实验中取H=400.
由以上两步,可以求得训练图像Btrain和分类器的初始类ci之后,对每个训练图像在L×L(取L=32)范围内,按照随机选取M×S(M=30,S=12)对像素位置dj1和dj2.对每个初始类ci根据这M×S对随机位置上像素点的灰度值由式(1)计算类ci的M个随机蕨中S个二元特征fi的值,并根据这个值计算出式(7)中的每个随机蕨Fm和类ci的类条件概率P(Fm|C=ci).
2.4 在线特征点检测与匹配
在线检测阶段我们首先用快速多尺度特征点提取的方法提取前景车辆的特征点.由于检测到的特征点不再用在分类器的建立上,非车辆上的特征点也可以快速的用分类器进行分类匹配.因此在线检测阶段不用进行车脸定位,而只要对背景差分提取的前景车辆进行检测即可.

2.5 改进的PROSAC误匹配特征对的剔除
确定了要配准的2幅图像的对应点后,利用这些对应点对,以1幅图像为参考,求解出2幅图像之间的几何变换矩阵H的参数,并由此来去除误匹配.为此可以采用随机抽样一致性(RANSAC)算法来去除误匹配.然而,当误匹配特征对的数目在总的匹配特征对中所占的比例过大时,RANSAC算法不能很好地处理这种情况.由于随机蕨的图像匹配算法没有直接对误匹配对去除的策略,在2幅图像间差距较大时,误匹配对占总匹配对的比例可能会较大,所以在此时会失效.
可以采用PROSAC算法来进行模型拟合,剔除误匹配特征对,PROSAC算法由Chum等[9]于2005年提出,该方法优先从高品质方程的数据子集中抽取样本,即选取那些属于正确匹配概率高的样本,有利于迭代过程的快速收敛,能够很好地应对误匹配所占总匹配比例较大时的情形.
而在内点集合的应用上,由于PROSAC算法在初期就能迅速找到全部由内点组成的样本,所以我们可以对PROSAC算法进行改进,交替从内点集中和有序的样本集中选择样本点.改进的PROSAC算法如下:
t=0,n=m,n*=N重复,直到找到解:
1) 选择假定的集合
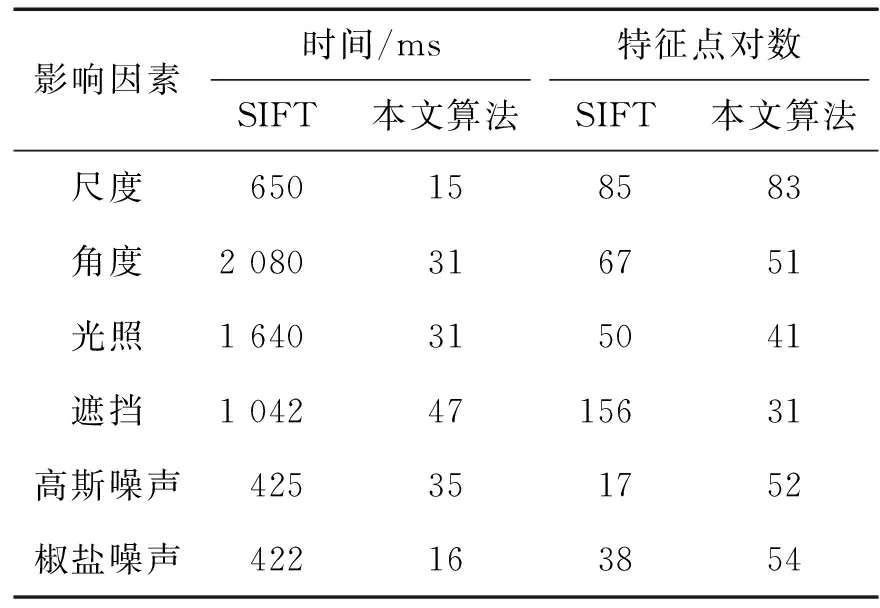
如果n 2) 大小为m的半随机样本Mt 交替进行(i),(ii): (i)a从Bik(当前内点集合)中随机选择大小为m的随机样本, (ii)b随机从Un中选取m个点; 3) 模型参数估计 从样本Mt中计算模型参数pt; 4) 模型验证 找到参数为pt的模型的支持(例如一致的数据点),如果支持数目大于当前最大支持数,则更新当前所得内点集合Bik. 对下面2幅图进行匹配并比较结果,其中实验时最大迭代次数为1 500次,并且当内点集中的个数大于50时则退出循环,实验结果如图4所示. 图4 粗匹配结果Fig.4 Initial match result 与RANSAC和PROSAC对比,结果如表2和表3所示. 表2 误匹配较多时,各算法比较Tab.2 More mismatch situation,comparison of the algorithm 注:运行程序100次取平均值. 由实验可知,改进后的PROSAC能够很好的处理误匹配点较多,和较少时的情形,能够减少迭代次数,从而减少运行时间. 表3 误匹配较少时,各算法比较Tab.3 Less mismatch situation, comparison of the algorithms 注:运行程序100次取平均值. 首先对一段含有339帧的视频进行测试,每帧图片的大小为600×800像素,匹配结果为264帧匹配成功,75帧匹配失败.在DEBUG模式下耗时26 487 ms,平均每次匹配耗时78.13 ms,其中每帧检测特征点耗时平均为34.56 ms,匹配时间为43.57 ms;在RELEASE模式下耗时10 698 ms,平均每次匹配耗时31.56 ms,其中每帧检测特征点耗时平均为18.23 ms,匹配时间为13.33 ms.分析可知,我们的匹配可以达到实时的要求.接着在尺寸、角度、光照、遮挡、噪声等干扰情况下对本文的算法与SIFT进行比较.为了公平,在SIFT算法进行匹配时将“车脸”区域提前截取出来,作为基准图像,同时将算法总耗时减去基准图像检测特征点的时间作为SIFT的匹配时间,实验结果如图5和表4所示. 左边图像是使用SIFT匹配的结果,右边是使用本文算法匹配结果.从上到下,分别是在不同的尺度、角度、光照、遮挡、高斯噪声、椒盐噪声条件下的比较.图5 匹配结果对比Fig.5 Comparison of matches 通过以上实验说明,本文算法在保证实时处理车辆匹配的同时,能够很好地处理尺寸、角度、亮度变化,以及遮挡、噪声等影响.在检测到的匹配对和SIFT差不多的同时,误匹配较少,匹配正确率接近100%.在时间上、性能上都比SIFT算法有大幅度提高. 本文结合车辆区域定位与车牌快速定位来对包含车辆大部分显著特征的“车脸”区域进行定位.用随机蕨思想将车辆匹配问题转化为分类问题,将运算量大的部分转移到分类器训练过程中.同时结合车辆图片的特征,引入多尺度的概念,提出了一种快速多尺度特征点检测算法.离线训练阶段,产生大量的虚拟图对分类器进行训练,在线运行阶段检测特征点并将这些特征点所在的区域块放到分类器中进行快速分类,产生初始匹配.对误匹配的特征点进行精确匹配时,分析了RANSAC策略的不足,应用改进的PROSAC对随机蕨匹配算法获取的匹配对进行精确匹配. 表4 本文算法与SIFT算法对比结果Tab.4 Comparison between SIFT and the algorithm of this paper 实验结果表明,基于随机蕨的车辆匹配能够快速实时地进行匹配,同时能够很好地应对车辆尺度变化、角度变化、亮度变化、遮挡、镜头畸变以及复杂的交通环境等挑战. 本文旨在实现车辆的实时匹配,结合车辆区域定位与车牌定位来实现“车脸”定位,同时引入随机蕨的思想将车辆匹配问题转化为特征点所在区域的分类问题,虽然能够对车辆进行实时匹配,但仍然存在着一些不足和需要改进的地方,需要进一步的完善和提高: 1) 本文的随机蕨分类器是建立在“车脸”特征点之上的,提取的“车脸”区域的准确性,将直接影响着后面的匹配效果.因此如何快速准确的提取“车脸”区域,还需要进一步的研究. 2) 离线训练阶段需要生产大量的虚拟图像进行稳定特征点查找和分类器的建立,因此需要大量的计算.然而由于虚拟图像之间、随机蕨之间的相互独立,可以利用多核编程来降低离线训练时间,提高运算效率. 3) 本文的车辆匹配不能很好地处理同品牌同型号的车辆.当两辆车是同一品牌同一型号时,单靠本文匹配方法不能很好地进行区分,需要车牌识别进行辅助. 4) 匹配依赖于分类器的分类结果,缺少误匹配去除机制,在误匹配很多时,可能会产生匹配失败的情形.因此如何快速有效地去除误匹配将是今后研究工作的重点. [1] Lowe D G.Object recognition from local scale-invariant features[C]∥Computer Vision,1999.The Proceedings of the Seventh IEEE International Conference on.Kerkyra:IEEE,1999:1150-1157. [2] Ke Y,Sukthankar R.PCA-SIFT:a more distinctive representation for local image descriptors[C]∥Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition.Washington:IEEE,2004:511-517. [3] Bay H,Tuytelaars T,Gool L V.SURF:speeded up robust features[C]∥Computer Vision-ECCV 2006.Berlin:Springer-Verlag,2006:404-417. [4] Morel J M,Yu G S.ASIFT:a new framework for fully affine invariant image comparison[J].Society for Industrial and Applied Mathematics Journal on Image Sciences,2009,2(2):438-469. [5] Lepetit V,Fua P.Keypoint recognition using randomized tree[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(9):1465-1479. [6] Ozuysal M,Calonder M,Lepeti V.Fast keypoint recognition using random ferns [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(3):448-461. [7] Zheng D N,Zhao Y N,Wang J X.An efficient method of license plate location[J].Pattern Recognition Letters,2005,26(15):2431-2438. [8] Parisi R,Di Claudio E D,Lucarelli G,et al.Car plate recognition by neural networks and image processing[C]∥Proceedings of the 1998 IEEE International Symposium on Circuits and Systems.Monterey,CA:IEEE,1998:195-198. [9] Chum O,Matas J.Matching with PROSAC-progressive sample consensus[C]∥Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Diego,CA:IEEE,2005:220-226.


3 实验结果与分析

4 结 论
猜你喜欢
导航定位与授时(2020年5期)2020-09-23
铁道通信信号(2020年9期)2020-02-06
电子制作(2019年12期)2019-07-16
知识经济·中国直销(2018年3期)2018-04-12
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
学习月刊(2015年1期)2015-07-11
航天返回与遥感(2014年5期)2014-07-31
