
基于多属性的海量Web数据关联存储及检索系统
2014-09-15 01:23李春花黄永峰廖正霜
计算机工程与科学 2014年3期
罗 芳,李春花,周 可,黄永峰,廖正霜
(1.华中科技大学计算机科学与技术学院,湖北 武汉 430074;2.清华大学电子工程系,北京 100084)
基于多属性的海量Web数据关联存储及检索系统
罗 芳1,李春花1,周 可1,黄永峰2,廖正霜1
(1.华中科技大学计算机科学与技术学院,湖北 武汉 430074;2.清华大学电子工程系,北京 100084)
传统的Web数据检索一般采用全文检索方法,该方法具有很好的灵活性,但舆情分析往往需要获得相关的网页属性及统计信息。针对传统的Web检索方法无法满足上述需求,基于Hadoop平台设计并实现了一种基于多属性的海量Web数据的关联存储及检索系统,为舆情分析提供基础检索与统计服务。主要实现HDFS上基于属性的网页数据的分类和聚类存储,解决小文件存储同时提高数据访问吞吐量;建立原始网页数据与属性数据之间的关联映射;基于HBase的已有索引机制,结合分布式本地索引机制解决基于HBase的动态属性多条件选择查询的辅助索引问题。
分类存储;多条件选择查询;关联映射;辅助索引
1 引言
海量Web数据具有非结构化、更新速度快、数据类型多样化等特点,对数据管理系统提出了新的挑战。分布式存储计算环境可以有效地利用集群的资源为海量数据提供分布式存储和计算支持,同时也带来了许多技术上的挑战。
Hadoop是典型的分布式存储计算平台,其中HDFS(Hadoop Distributed File System)[1]是分布式文件系统,能够提供高吞吐量的数据访问,具有良好的扩展性和数据容错性,满足大规模数据处理需求,可用于海量Web数据的存储。由于HDFS适合于存储超大数据文件(几百MB、GB甚至TB),不适合将单个的Web网页数据直接保存到单个文件,因此需要对Web网页数据进行合并存储。为提高相关性网页数据读取的吞吐量,可以利用Web网页数据之间的属性相关性,对Web网页进行分类归并存储。然而,由于HDFS不支持随机写操作,故只能采用追加写方式,保证单个文件的数据整体相关性。
HBase[2]是Hadoop的一个面向列的分布式存储系统,适合于海量结构化数据的存储,也支持非结构化数据的存储,也具有很好的可扩展性和容错性。原始的网页文件中一般存储大量的属性描述数据,在舆情分析系统中,如何有效地获取、组织、管理和检索这些属性数据是舆情分析研究的基础。为方便属性数据的存储和扩展,我们采用HBase作为属性数据的存储支持。由于异构源(如门户网站、BBS、博客、微博)的网页信息具有不同的属性数据,属性数据的值域又分为离散型数据域(如新闻来源)和连续型数据域(如评论数),因此需要设计满足不同需求的属性数据的存储模型,实现属性数据和原始网页数据的关联存储映射。该映射机制能够对异构数据进行双向定位访问,同时减少分布式环境下的网络开销。
由于HBase仅支持主索引结构,无法满足多条件选择查询需求。为此需要设计满足该查询需求的索引机制,该索引应具有较好的动态扩展性、可维护性和较高的检索性能。由于HBase的数据存储模型的改变,传统的关系型数据管理系统中的辅助索引技术无法被简单地迁移过来,因此,基于HBase属性数据管理系统需解决以下几个方面的问题:辅助索引应充分利用分布式计算环境的并行计算能力来提高数据分布式检索效率;分布式环境下属性数据的添加、删除、修改、迁移等可以较方便地进行索引维护;保证高并发查询效率的同时需要尽量减少网络查询开销;针对舆情分析需求,该索引机制应该具有较高的数据统计能力。
本文的第2节将介绍相关的研究工作;第3节详细描述Hadoop平台下实现Web属性数据关联存储与检索的相关技术,包括Web数据的分类聚类存储算法,属性数据和原始网页数据的关联映射和定位技术,HBase辅助索引机制的构建、维护和检索算法,以及整个系统实现的主要流程;第4节中给出了相关的实验结果;最后对本文进行归纳总结。
2 相关工作
2.1 小文件合并存储和定位技术
对于小文件问题,Hadoop自身提供了三种解决方案[1]:Hadoop Archive、Sequence File和CombineFileInputFormat。这三种方法不能自动删除原始小文件,且不能将动态增加的数据合并到已归类的文件。WebGIS[3]结合数据的相关特征,将相邻地理位置的小文件合并成大文件,把小于16 MB的文件作为小文件进行合并处理,将其合并成64 MB的数据块并构建索引。BlueSky[4]主要基于HDFS存放教学PPT文件、视频文件及一些文件快照,此方法的合并准则十分简单,要求合并的文件具有明确相关性和本地性。但是,考虑网页数据具有海量且关联不确定性特点,不应将合并后的文件的大小限制在较小范围;同时,需要采用相关的聚类算法来确定网页之间的关联性,实现合并存储。
2.2 网页数据的分类聚类算法
由于舆情分析[5]中网页的主题和时间是非常重要的查询属性,本文实现了对网页数据进行基于主题和时间的分类。在文件合并的过程中考虑文件的相关性,采用相关的聚类算法对网页文件进行分类合并存储,可以有效提高网页数据访问的吞吐量。
在对网页数据进行基于属性的归并存储过程中,需要对网页进行预处理,获得网页的文本向量表示。常用的文本表示方法有:布尔模型、向量空间模型、语义模型和生成模型LDA(Latent Dirichlet Allocation)。实现主题分类的过程中,主要采用经典的SVM(Support Vector Machine)模型[6]。利用聚类算法对文本进行聚类存储。有许多经典的聚类算法[6],如划分聚类、层次聚类、密度聚类等。考虑Web数据海量、动态等特点,本文采用聚类算法实现海量Web数据的合并存储,并基于MapReduce框架实现并行化。
2.3 云数据管理的辅助索引机制
云环境下辅助索引机制主要分为集中式和分布式两种方案[7]。集中式方案中,被索引字段上的所有值被全局排序并集中管理。检索过程中首先在全局排序的索引结构中找到符合的索引项;然后定位到对应的数据节点;再根据该节点的聚集索引定位到完整记录。该方案没有充分利用集群的整体计算能力,限制了查询的性能。分布式索引方案在各数据节点独立建立各自管理的局部数据索引,但对于任何一个检索请求,都会分别发送到各个数据节点进行并发查询,在高并发查询环境下显然增加了无用的数据节点。基于分片位图的索引方案[8]为数据检索提供了较好的支持,但针对不断更新的海量数据,该索引机制具有一定的使用限制。
3 基于属性的Web数据关联存储
3.1 原始网页数据的归并存储
3.1.1 网页原始数据的关联存储过程
首先基于主题和时间等属性对原始网页数据进行分类存储,下面以如表1所示的新浪新闻信息网页为例进行说明。

Table 1 Partial Sina-news instances
以时间和主题为划分标准,对原始网页数据进行分类,其中主题列表基于《中文新闻信息分类标准及代码》[5]构建,得到如图1所示的网页数据存储结构。其中InfoWebSet是基于网页的其他属性(网页来源、发布媒体、评论数、信息关键字),通过基于MapReduce的聚类算法对同一分类下的网页数据进行聚类存储。聚类属性的选择主要是为了满足舆情统计需求[9]。
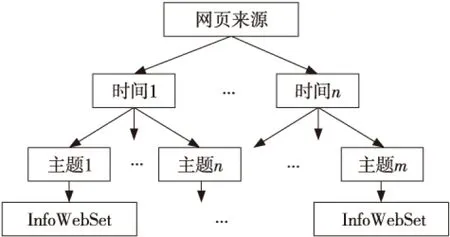
Figure 1 Organization structure of webpage based on HDFS图1 网页数据在HDFS中的组织结构
3.1.2 网页数据归并存储算法
(1)基于主题的网页数据分类算法。
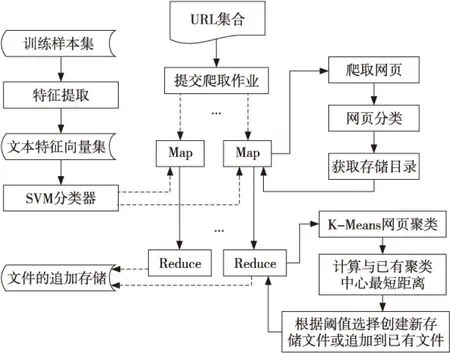
Figure 2 Parallelization of web page associated-storage based on MapReduce model图2 网页归并存储的MapReduce并行化实现
由于网页数据源的异构性,需要采用相关的分类算法对网页进行主题分类。本文主要利用基于贝叶斯理论的SVM模型对网页数据进行分类,实现过程中针对不同的异构源(新闻网站、博客、BBS、微博),首先选取新浪新闻网站、新浪博客、天涯论坛和新浪微博已确定分类的数据作为训练集,获取SVM分类器;以其他动态增长的网页数据作为样本,采用SVM模型对样本数据进行分类,从而确定网页数据的存储路径。该过程主要通过Map函数完成。Map函数实现的主要工作如下:
① 根据待爬的URL获取原始网页Page(i)。
② 对原始网页进行预处理获得特征向量。
③ 利用SVM训练模型得到网页分类,获取存储目录Dir_path(j)。
④ 以Dir_path(j)为key,Page(i)作为value输出给Reduce函数进行聚类,完成网页数据归并存储。
(2)基于多属性的网页数据聚类算法。
本文基于K-means算法[10]对同主题下的网页数据进行基于属性的聚类。选择K-means算法实现网页数据聚类存储具有以下优点:K-means算法复杂度低,速度快,实现简单,满足海量数据的聚类需求,能保证聚类效率;根据聚类目的和聚类结果将网页数据存储到对应的文件中,故需要使用排他型聚类算法,K-means算法满足这种需求;可以简单地满足动态网页数据的聚类需求。
聚类过程主要在Reduce函数中实现,输入的key为文档所属目录的绝对路径,value为该路径下的所有文档。主要完成以下工作:
① 对每个路径下的所有文档进行聚类。
② 计算每个聚类中心New_center(i)与已有的K个聚类中心的距离。
③获得与New_center(i)距离最近的聚类Old_center(j):若距离小于阈值t1,读取Old_center(j)的存储路径Path(j),将New_center(i)的所有网页数据追加到Path(j);否则,为该聚类在该目录下创建新的存储文件Path(m),将new_center(i)的所有网页数据追加到Path(m)中。
(3)算法实现。
上面主要阐述了采用Map/Reduce框架实现网页数据合并存储的主要工作。其中Map函数主要完成了对网页数据的分类,获得其存储的目录;Reduce函数主要对同分类下的网页数据聚类,根据聚类结果将网页数据追加存储到对应的HDFS文件中。Map过程的伪代码如下:
voidmap(ImmutableBytesWritableibw, Resultresult, Contextcontext)
{
Stringurl=getUrl(ibw);/*get url from HBase*
Pagepage=getWebPage(url);//download webpage
DocVectordocVector=getVector(page);
SVMersvm=getSVM();//get svm classifier
Clscid=SVM(docVecto,svm);//training by SVM
PathdirPath=getPath(cid); /*get storage path with cid*/
Context.write(new Text(dirPath), new Text(page));
}
Reduce过程的伪代码如下:
voidreduce(TextdirPath, Iterator〈Text〉pages, Contextcontext)
{//clustering new Pages
intk=Configuration.get(“cluster_num”); /*get k number*/
intt1=Configuration.get(“cluster_distance”);
List〈Center〉centers=get_k_center(pages,k);
List〈Cluster〉clusters=kmeans_training(pages,k,centers); //get clusters byk-means
List〈ClusterCenter〉old_centers=get_oldcenter(dirPath);
FOR (Clustercluster:clusters)
{//compute cluster distance to old clusters
Centercenter=getCenter(cluster);
Centermincenter=getMin(center,old_centers);
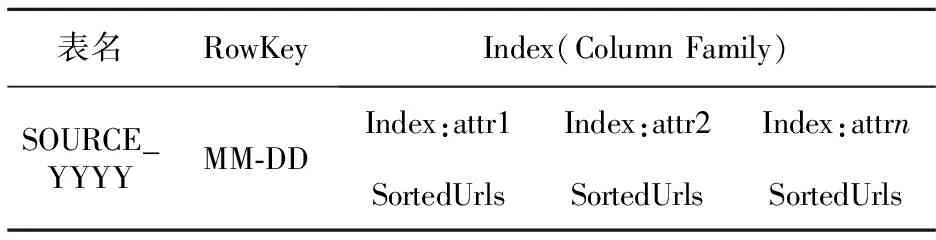
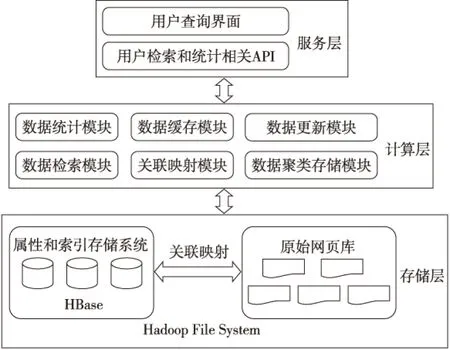
IF (distance(center,mincenter) {/*ifdistance TextPathtextPath=getTextPath(mincenter,dirPath); append(textPath,cluster); } ELSE {//create new cluster file and append data into it TextPathtextPath=newTextPath(++k,dirPath); append(textPath,cluster);/*append data to file*/} }//endFor /*output cluster path info to database for further retrieval*/ } 3.2 属性数据的存储 3.2.1 属性数据的类型 (1)从网页中解析获得的属性数据:URL、标题、发布时间、媒体来源、评论人数、参与人数、网页正文的关键字(主要通过对正文、标题进行分词、过滤无效词等获得); (2)原始网页数据分类聚类获得的属性:主题,原始网页在HDFS中的存储路径,原始网页在聚类文件中的偏移量。 3.2.2 属性数据的存储模型 为充分利用分布式并行计算能力,采用HBase作为属性数据的存储支持[11]。在基于HBase固有索引机制的基础上构建良好的分布式辅助索引机制,需要设计良好的属性数据存储模型[12]。表2是属性数据在HBase中的存储模型。 Table 2 A storage model of attributes data based on HBase 根据Web数据更新速度快和舆情分析需求,在设计属性数据存储模型时优先考虑时间属性,同时考虑到异构网页源的属性特征不同,因此将HBase中的表名设计为SOURCE_YYYY属性。同时,为保证索引和被索引数据的操作具有事务性,每个索引以RowKey索引单元,基于HBase存储,且使用相同的RowKey作为其存储的行关键字,保证索引与被索引的数据在同一个RegionServer上。由于网页数据具有更新的特点,我们可充分利用HBase的时间戳机制来存储更新。 同时,我们在数据库中采用相关字段来存储对应原始网页数据的位置信息,使得该系统能够在获得属性数据的同时支持查看完整的原始网页数据。 3.3 HBase辅助索引的构建 基于HBase原有的主索引方式设计分布式本地索引。索引以RowKey为主键,对相同的RowKey中的属性数据建立本地索引,构建的索引数据基于HBase存储,且与被索引的数据共享相同的RowKey,保证在分布式环境下,当属性数据发生迁移时,对应的索引数据也能始终迁移到相同的节点上,可减少检索过程中的网络开销。同时,为了充分利用分布式节点的计算能力,我们在各个RegionServer上构建本地检索模块,利用本地索引,对局部时间域的数据进行并行检索,最后将各节点返回的数据求并即得到了整体时间域的数据检索。 表3是本文设计的属性索引存储模型。从中可以看出,将属性索引和属性数据采用无差别存储,属性数据采用Url列族名,属性索引采用Index列族存储,对相同表中相同RowKey下的属性数据进行索引。这样就可以利用分布式节点的计算能力对被检索的属性进行分布式检索然后归并。 Table 3 Storage model of attributes’ indexing 为了提高多条件检索的效率,实际系统中一般采用联合索引机制存储索引,再采用对应的决策树查询算法进行本地数据检索。针对舆情需求,被索引的属性数据主要包括:媒体来源和检索网页的关键字。下面给出基于HBase的多属性条件选择查询算法: 输入:用户需要查询的属性域{Attr1,Attr2, …,Attrn}; 输出:满足查询条件的网页属性数据对象集合。 步骤1 接收用户输入的属性参数。 步骤2 根据用户选择的网页源和年阈值(默认是有时间范围的)确定所需检索的数据表;根据时间的月/日来确定RowKey的startRowKey和endRowKey,获取需要检索的RegionServer,将其他查询参数进行连接封装到查询请求中并发送到对应RegionServer。 步骤3 采用RegionServer自带的类对请求进行反序列化,生成需要的请求对象,解析请求对象中包含的查询参数。 步骤4 针对各查询参数循环构造查询条件,再调用Get()方法返回查询结果。 步骤5 在RegionServer上对返回的数据进行布尔运算求交集,为了加快处理速度,存储时对数据进行排序存储以提高效率。 步骤6 利用交集数据循环构造查询条件进行Get()查询,返回最终数据给客户端。 步骤7 客户端对不同时间域的数据进行求交并返回、显示对应的属性数。 3.4 Web数据关联存储及检索系统框架图 前面主要介绍了本系统实现的关键技术,系统的整体框架图如图3所示。 Figure 3 Associated storage and retrival system framework of massive web data based on attributes图3 基于属性的海量Web数据关联存储和检索系统框架 系统从功能上分为:存储层、计算层和服务层。其中,存储层主要分为对原始非结构化信息的存储、结构化属性信息的存储及索引数据的存储。计算层主要包括数据的聚类存储模块,属性数据和原始网页数据之间的关联映射模块,数据的检索、结果的缓存和统计模块,由于Web数据具有更新特点,故还建立了对应的更新模块,主要针对更新数据进行处理。最上层则是服务层,主要对下面相关的处理模块进行封装。给供分析人员提供执行相关检索和统计的API,为后期的舆情分析提供基础服务,同时构建了一个用户查询界面提供功能展示服务。 按照以上设计思想,本文实现了基于多属性检索的Web信息查询系统。由于我们的数据关联存储和检索系统主要是为舆情分析提供基础服务,主要提供了相关查询统计和网页获取的API接口。图4给出了对新浪某类新闻在2010~2012年的新闻发布数的统计结果。 Figure 4 A trend statistics of certain SinaNews topic图4 新浪某分类新闻的走势统计 本文还搭建了一个功能演示界面,如图5所示。图5中查询设定的参数有:时间范围参数是2010年7月1日到2013年4月1日,信息来源为新浪新闻,查询的主题为军事,检索的关键词为“钓鱼岛”,返回了相关的查询结果,点击可以在下方查看某新闻的内容和相关的属性信息,右图还给出了以时间为维度的频率统计图,另外下方的url还支持查看原始网页来源。 Figure 5 Web data retrieval demo based on multi-attributes图5 基于多属性的Web数据检索系统 本文基于Hadoop和HBase平台,设计并实现了一种基于属性的海量Web数据的关联存储和检索系统。主要做了如下工作:对爬取的原始网页数据采用分类聚类算法实现归并存储,使用HDFS作为原始网页存储库。该方法使得基于属性检索的结果数据在原始网页存储库中也具有位置相关性,能够提高原始数据读取的吞吐量;从原始信息网页中抽取出属性数据,以时间为阈值进行基于HBase的存储,设计了相关的属性数据存储模型;在属性数据和原始网页数据之间建立关联映射;基于属性数据的存储模型设计了属性数据的索引模型,并使用分布式节点中的本地计算能力实现对多属性的选择查询。最终实现了对海量Web数据的基于属性的关联存储和检索系统。该系统的相关算法设计和索引效率有待改进,结合全文检索能力可以进一步完善整体系统的功能,这将是我们后期需要展开的工作。 [1] Apache Hadoop project[EB/OL].[2012-09-10]. http://hadoop.apache.org. [2] Apache HBase project [EB/OL].[2012-11-25]. http://hb- ase.apache.org. [3] Liu Xu-hui, Han Ji-zhong, Zhong Yun-qin, et al. Implementing WebGIS on Hadoop:A case study of improving small file I/O performance on HDFS[C]∥Proc of CLUSTER, 2009:1-8. [4] Dong Bo, Qiu Jie, Zheng Qing-hua, et al. A novel approach to improving the efficiency of storing and accessing small files on Hadoop:A case study by PowerPoint files[C]∥Proc of the 2010 IEEE International Conference on Services Computing, 2010:65-72. [5] Qian Ai-bing. A model for analyzing public opinion under the web and its implementation[J]. Information Analysis and Research, 2008(4):49-55.(in Chinese) [6] Zhang Xue-gong. Pattern recognition[M]. 3rd ed. Beijing:Tsinghua University Press, 2010.(in Chinese) [7] Hbase-transactional-tableindexed[EB/OL].[2002-10-26]. h-ttps://github.com/hbase-trx/hbase-transactional-tableindexed. [8] Meng Bi-ping, Wang Teng-jiao, Li Hong-yan, et al. Regional bitmap index:A secondary index for data management in could computing environment[J]. Chinese Journal of Computers,2012,35(11):2306-2316.(in Chinese) [9] Wang Ming-yan. Keyword and key concept extraction technique based on web page[D]. Beijing:Beijing University of Technology,2003.(in Chinese) [10] Jiang Xiao-ping, Li Cheng-hua, Xiang Wen, et al. Parallel implementingk-means clustering algorithm using MapReduce programming mode[J]. Journal of Huazhong University of Science and Technology(Natural Science Edition),2011,39( Sup Ⅰ):120-124.(in Chinese) [11] Yu Ge, Gu Yu, Bao Yu-bin, et al. Large scale graph data processing on cloud computing environments[J]. Chinese Journal of Computers,2011,34(10):1753-1767.(in Chinese) [12] He Yun-feng, Yu Jun-qing, Tang Jiu-fei, et al. Video data organization and management based on MPEG-7[J]. Journal of Wuhan University(Natural Science Edition),2010, 56(6):711-716.(in Chinese) 附中文参考文献: [5] 钱爱兵.基于主题的网络舆情分析模型及其实现[J]. 情报分析与研究, 2008(4):49-55. [6] 张学工.模式识别[M].第3版. 北京:清华大学出版社,2010. [8] 孟必平,王腾蛟,李红燕,等. 分片位图索引:一种使用于云数据管理的辅助索引机制[J]. 计算机学报, 2012,35(11):2306-2316. [9] 王明燕,基于WEB页面的关键词与关键概念提取技术[D]. 北京:北京工业大学, 2003. [10] 江小平,李成华,向文,等.k-means聚类算法的MapReduce并行化实现[J]. 华中科技大学学报(自然科学版),2011,(Sup Ⅰ)39:120-124. [11] 于戈,谷峪,鲍玉斌,等. 云计算环境下的大规模图数据处理技术[J].计算机学报,2011,34(10):1753-1767. [12] 何云峰,于俊清,唐九飞,等. 基于MPEG-7的视频数据组织与管理[J]. 武汉大学学报(理学版) ,2010,56(6):711-716. LUO Fang,born in 1989,MS candidate,her research interests include cloud storage, and big data. An associated storage and retrieval system of massive Web data based on multi-attributes LUO Fang1,LI Chun-hua1,ZHOU Ke1,HUANG Yong-feng2,LIAO Zheng-shuang1 Traditional Web Retrievals commonly use the full-text search method which has good flexibility. However, as the analysis of public opinion usually needs relative information of web attributes and statistics, the traditional retrieval method can not satisfy it well. An associated storage and retrieval system based on the Hadoop platform is designed and implemented, which can offer good basic service for the analysis of public opinion. Firstly, the associated storage of web data based on HDFS is realized by machine learning. Secondly, the problem of small files storage together with the access efficiency of associated data is solved. Thirdly, the mapping between original web data and the extracted attributes is established. Finally, the retrieval of dynamic multiple attributes based on the existed indexing on HBase and the distributed local indexing are realized. category storage;multi-conditions selectable query;associated mapping;secondary indexing 2013-06-08; 2013-10-20 国家863计划资助项目(2012AA011004);清华大学自主科研项目基金(20111081023) 1007-130X(2014)03-0404-07 TP391.3 A 10.3969/j.issn.1007-130X.2014.03.005 罗芳(1989-),女,安徽郎溪人,硕士生,研究方向为云存储和大数据。E-mail:fsailuo@gmail.com 通信地址:430074 湖北省武汉市华中科技大学计算机科学与技术学院 Address:School of Computer Science and Technology,Huazhong University of Science and Technology,Wuhan 430074,Hubei,P.R.China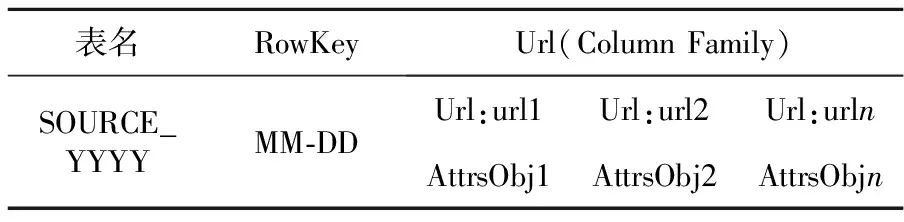
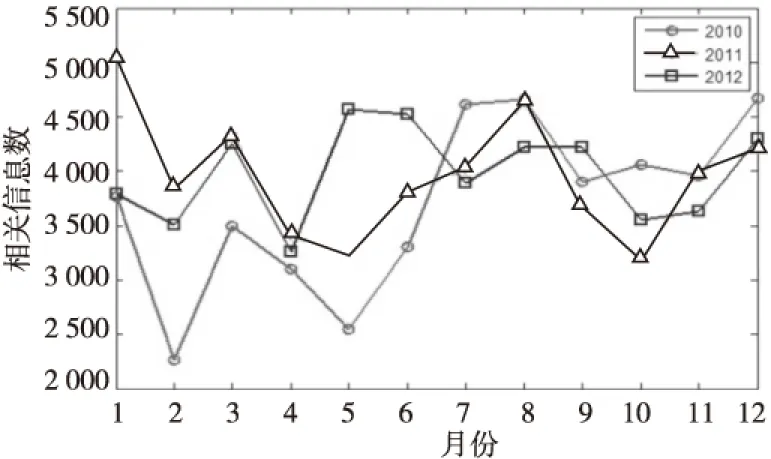
4 实验
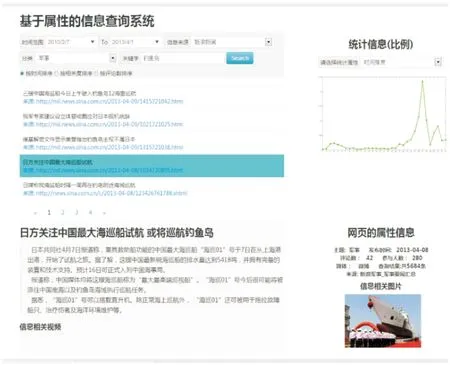
5 结束语
(1.School of Computer Science and Technology,Huazhong University of Science and Technology,Wuhan 430074;2.Department of Electronic Engineering,Tsinghua University,Beijing 100084,China) 猜你喜欢
科技资讯(2019年18期)2019-09-17中国科技纵横(2019年15期)2019-08-27教育界·下旬(2019年1期)2019-04-26电子制作(2018年10期)2018-08-04能源(2017年10期)2017-12-20能源(2017年5期)2017-07-06电子制作(2017年2期)2017-05-17电子测试(2015年18期)2016-01-14雷达与对抗(2015年3期)2015-12-09计算机与网络(2014年7期)2014-03-25
猜你喜欢
科技资讯(2019年18期)2019-09-17中国科技纵横(2019年15期)2019-08-27教育界·下旬(2019年1期)2019-04-26电子制作(2018年10期)2018-08-04能源(2017年10期)2017-12-20能源(2017年5期)2017-07-06电子制作(2017年2期)2017-05-17电子测试(2015年18期)2016-01-14雷达与对抗(2015年3期)2015-12-09计算机与网络(2014年7期)2014-03-25
