
针对监控视频场景的压缩域运动对象分割方法
2014-09-18 00:15王小龙梁久祯
电视技术 2014年15期
王小龙,梁久祯
(江南大学物联网工程学院,江苏无锡214122)
视频监控的应用遍布全球,监控人员对于能提供快速、准确的智能视频分析解决方案的需求越来越强。智能视频监控系统实现的第一步就是以最低的误差对运动对象进行分割。
随着监控视频的体积和分辨率的不断增加,如何对视频灵活高效的处理在实际应用中显得尤为重要。相对于主流的像素域方法,压缩域视频分析平衡了智能视频监控系统的处理效率与视觉感知,更适合于实际应用需要。鉴于实际监控视频场景中的大多数视频序列已经压缩,为了最大化利用编码端的工作,直接在压缩域内进行运动对象分割,可免除对压缩视频进行完全解码。从压缩码流中提取相关信息直接用作运动对象分割所需要的特征,这些在宏块(macroblock)或块(block)级别上提取的特征使得所需要处理的数据量远少于像素域,从而显著降低了分割算法的计算量。因此,从压缩域分割运动对象具有快速高效的特点,可解决像素域对象分割难以满足的高效处理要求。Babu等人[1]先对运动矢量(MV)做累积来增强运动信息,并以空间插值算法来得到稠密的运动矢量,然后使用EM算法对稠密的运动矢量场进行分割,最后提出了一种基于边缘细化的方法。Wang和Zhung[2]首先结合空间、时间和纹理来获得具有鲁棒性的运动信息,接着通过检测运动信息来提取运动块。Zen[3]用运动矢量的幅度和相位来分割对象,利用前后帧的DCT系数匹配关系来跟踪对象。Zeng等人[4]首先将运动矢量分成4类,然后使用马尔科夫随机场模型提取运动对象,文献[5-7]也使用了基于 MRF的对象分割技术。Wang等人[8]在H.264压缩域基于MV-LBP特征背景建模提取粗糙对象,通过最大后验概率提取轮廓集细化进一步运动对象。目前,在H.264的压缩域进行对象分割的技术大多是依赖于运动矢量场。然而,运动矢量本质上以编码为导向,其建立是为了更好地压缩视频,它并不代表视频序列中真实的运动。另外,视频压缩域的运动矢量场格外嘈杂,若基于MV进行压缩域运动对象分割则需要额外的复杂度来处理噪声MV。
基于上述研究背景,本文改进了一种Vibe背景建模算法并成功应用于压缩域背景建模,通过引入最大熵自适应阈值精确分割出运动对象。
1 压缩域运动对象分割方法
监控视频的背景一般比较单一,迄今为止像素域对象分割领域已经提出了很多背景建模的方法。在H.264编码框架中,残差数据为当前编码块与其最佳匹配块的差值,残差系数基于4×4块变换、量化,通过Zig-Zag扫描、熵编码呈现在视频压缩码流中。对于背景相对单一的监控视频场景,背景块在相邻帧之间一般差别不大,编码过程中容易搜索到与其匹配的较佳的块,所以在运动补偿的时候背景块的残差数据会非常小,该残差数据经过DCT变化、量化、熵编码之后反映到视频压缩码流中占据的比特数也较少;对于运动对象区域块在运动搜索的时候很难找到与其匹配很精确的块,运动补偿时对应残差数据较大,在视频压缩码流中所占据的比特数也越多。因此,通过块在压缩码流里面占据比特数的不同可以对运动对象进行分割。
基于上述分析,将背景建模的思想引入到视频压缩域。根据视频压缩编码理论,每个宏块在视频压缩码流里占据的大小(即宏块比特数MBbits)可以看成一个离散的信号,那么对一帧图像就可以比拟成一个MBbits场。本文试图在H.264压缩域建立MBbits背景模型,改进了一种Vibe算法提取前景运动对象宏块,并基于最大信息熵选取自适应阈值进行对象边缘细化。本文提出的背景建模和运动对象分割方法的流程如图1所示。该算法包括以下几个过程:1)压缩码流中MBbits以及DCT残差系数的提取;2)Vibe背景模型初始化及更新机制;3)基于最大熵原理的自适应阈值选取;4)运动对象分割;5)I帧对象区域预测。本文实验中采用只有首帧是I帧,其余帧为P帧的帧结构。

图1 背景建模和运动对象分割算法流程图
1.1 码流预处理
在H.264/AVC编码策略中,一个视频图像可编码成一个或更多个片(slice),每个片包含整数个宏块(MB)。片的句法结构如图2所示,其中片头规定了片的类型,该片属于哪个图像,有关的参考图像等,片的数据包含一系列的编码宏块和/或跳编码(不编码)数据[9]。每个宏块包含头单元和残差数据。由于每个宏块的mb_type、mb_pred等宏块头单元数据差别不大,因此忽略宏块头信息,只统计每个宏块编码残差。如图3所示为测试序列Hall Monitor第68帧的MBbits场。实际MBbits场和理论相符合,运动对象前景宏块MBbits相对较大,周围由于出现室内光照等噪声因子会出现噪声区域。

图3 Hall Monitor第68帧对应的MBbits场(截图)
在H.264压缩码流中,非正常的块比特数不能反映出对象移动的强度。所以在进行背景建模之前,首先要对MBbits预处理得到能反映对象运动区域信息的MBbits场。通过大量实验观察发现,当帧内预测块大面积出现时,一般是由光照变化或场景切换等背景变化引起的非运动区域变化;当帧内预测块小面积出现时,这些被帧间预测块所包围的分散的帧内预测块通常运动相对平缓,一般是运动对象的内部区域(如图3所示Hall Monitor第68帧第163个宏块为帧内预测块,MBbits163=20对应着运动对象的内部区域块)。采用均值滤波计算MBbits值,当出现极个别突变的MBbits时,采用中值滤波将其剔除。
1.2 改进的Vibe背景建模
像素域Vibe背景建模的方法首次采用随机选择机制和邻域传播机制来建立和更新背景模型,从而有效提高了准确度,增加了抗噪能力并减少了计算负载。Vibe背景模型的基本思想:通过建立一个具有N帧样本的背景模型,当前帧与背景模型比较,根据一定的分割准则区分前景目标。
第一步,引入一个帧数为N的背景模型,用第一帧的MBbits场来初始化背景模型。对于N帧背景模型中,每个样本中每个宏块对应的样本值记为Pn(x)(x代表宏块号,n代表背景模型样本号)。如图4所示,图4a是视频序列第一帧,图4b是所构建的背景模型N帧中的某一帧,模型初始化策略就是在图4a宏块F位置随机选取其八邻域中任意一个宏块的F(m)(m=1,2,…,8)来初始化背景模型对应位置宏块Pn(x),图4将用F(3)来初始化对应第n帧背景模型宏块Pn(x)。这样的初始化工作将执行N帧。用第1帧初始化N个样本的背景模型后,从视频序列的第2帧开始对前景背景进行分类。定义标记函数s(x),判断新进一帧位置MBi处是否为前景目标,本文引入判别准则为

式中:n=1,2,…,N;Pt(x)表示t时刻视频帧中宏块x位置处的MBbits值,Pn(x)为背景样本模型,每个宏块对应的背 景 模 型 样 本 集 合 Q(x)={P1(x),P2(x),…,PN(x)},那么有Pn(x)∈Q(x)。当前宏块MBbits与N帧背景模型依次进行比较,执行N次式(1)后,设定阈值ε,若s(x)=0的总数满足Sum(s(x)=0)>ε,将该位置MBi判断为背景宏块并用它来对背景模型进行更新;否则为前景,对该宏块不作为背景模型更新的候选。

图4 Vibe背景模型初始化
背景模型建立以后,需要对背景模型进行更新。Vibe存在光照突变、背景切换等方面处理的欠缺,本文针对监控视频场景提出了“场景波动因子”来检测整个场景的波动,从宏块级—帧级更新背景模型解决光照和场景切换、相机抖动等场景波动较大的问题。
宏块级,在时域随机抽取背景模型中1个样本进行更新,若当前帧中MBi判断为背景,用它来更新背景模型中随机帧的同一位置的宏块,这就是时域随机。鉴于相邻宏块的空间相关性较强,当某宏块被判定为背景宏块时,其邻域宏块成为背景的概率比较大,因此使用背景宏块MBbits值来随机更新背景模型中对应位置八邻域的某一宏块,这就是空域随机。
帧级,通过统计每个MBbits的波动幅度,引入“场景波动因子”来确定是否进行帧级背景模型的更新。ft表示t时刻某一宏块对应的MBbits值。定义f^t为已知测量变量时t时刻的后验状态估计
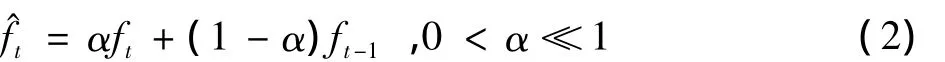
采用一种递归推算,将上一次计算得到的后验估计作为下一次计算的先验估计。由此t时刻先验状态估计


后验状态估计式(2)反映了MBbits状态分布的均值。用t-1时刻的先验估计误差Δf^t-1与t时刻的先验估计误差Δf^t来计算信号的方差
则先验状态估计误差
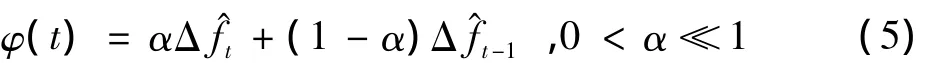
式中:φ(t)反映了t时刻某一宏块MBbits信号波动大小。设单帧视频的宏块总数为Ω,则t时刻单帧视频的“场景波动因子”为

对于一般监控视频场景,当受到光照突变、场景切换等因素影响时,场景会出现剧烈的波动。当场景波动因子满足式(7)经验公式时,说明场景波动较大,重新初始化背景模型,从而达到帧级背景模型更新。
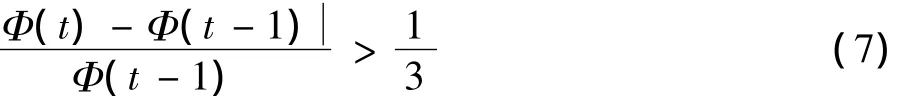
1.3 基于最大熵原理[10]的边缘细化
通过建立改进的Vibe背景模型,能够在压缩域分割宏块级对象区域,为了得到更精确的运动对象分割结果,本文将信息熵的概念引入到压缩域对象分割中。H.264基于4×4块整数DCT变换对宏块的预测残差进行变换,一个4×4残差信息大说明其难于压缩,每个宏块的残差比特MBbits是其16个4×4子块残差信息之和。因此,对运动对象区域进行4×4块边缘细化工作。用h(x)表示每4×4子块的DCT残差系数大小。则一帧图像中,最小信息量为h(x)0(等级为0),最大信息量为h(x)l-1(等级为l-1),W={0,1,2,…,l-1}表示4×4子块残差等级的集合。设M为一帧视频4×4块总数,Nμ(μ∈W)为残差等级μ时的4×4块数量,残差等级μ出现的概率为pμ,则


式中:信息熵H(N)是当前残差等级μ的无组织程度的度量。H(N)的大小和概率分布函数有关,熵值越大,每个残差等级μ对应的4×4块数分布越均匀。本文的算法在考虑残差信息分配关系的基础上保留全部信息熵模型,选取最大熵自适应选择最佳分割阈值,将阈值设定风险降到最小。对于阈值t∈W,低于阈值的信息熵、高于阈值的信息熵分别表示为
对应信息熵为
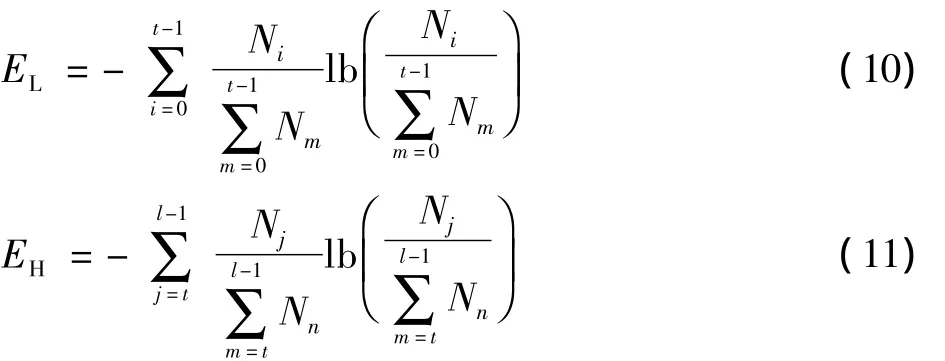
当(EL+EH)最大时即意味着目标区域和背景区域内各自4×4子块残差分布具有最大的同一性,如式(12)所示设定自适应最佳阈值T,表示分割4×4前景块和背景块的阈值

R
由式(12)可以得到前景4×4边缘块与背景块的分界阈值。式(13)定义了标记函数c(x),对于监控视频场景当h(x)大于阈值T,本文认为是该4×4块为运动对象边缘块。


图5 不同算法分割结果
2 实验结果
采用2个标准测试序列对本文所提出的算法进行性能评估:Hall Monitor(300帧/352×288像素),PetsD2TeC2序列(1 000帧/768×576像素)。根据实验需要,拍摄了测试序列F-Building(YUV格式,1 000帧/320×280像素)也用来评价本文算法。本文所有的编码和解码工作均在官方参考模型JM12.4版本上进行,帧结构为IPPP…(只有第一帧是I帧),量化参数(QP)为30,帧率为30 f/s,1个参考帧,运动估计的搜索范围为[-32,32]。所有的实验都是在一台配置为Intel Core i5,CPU 2.4 GHz,装有微软XP系统的台式机上进行。
图5给出了文献[4-6]的算法实验结果和本文算法视觉效果比较图。本文用精确度和召回率用来客观地评估实验结果,将这两个度量值融合成一个F度量(F-measure)衡量本文系统精度。
如表1所示,文献[4]的算法容易受噪声运动矢量的影响,其召回率低于本文算法,易出现分割目标部分缺失的情况。文献[5]为未使用基于DCT残差的边缘细化,其召回率和本文相当,但分割精确度小于本文算法。文献[6]较好地平衡了精确度和召回率,对于目标较大的物体(测试序列Hall Monitor)能获得非常满意的分割效果,但是对于柔性小运动目标(测试序列PetsD2TeC2、F-Building)极易出现分割漏洞。本文算法不依赖于MV,在宏块级迅速锁定运动目标,确保下一步分割的目标完整性,进一步根据应用需求进行空域边缘精细化。对于偶尔的光照突变场景变化较大的环境,本文算法能很快检测出来并立即初始化背景模型,防止了运动对象分割的误差漂移,因此本文算法一般适用于室外监控视频场景。
以上结果分析得出,本文算法在运动对象提取精确度影响不大的情况下,提高了召回率,获得了较完整的运动目标分割结果。一般基于MV的压缩域运动对象分割方法,首先需要进行运动矢量场的预处理,获得更为可靠的运动矢量场,进一步提取相关特征通过建立复杂的背景模型得到分割效果。本文算法大大降低预处理环节的复杂度,从宏块级能直接提取特征MBbits,采用改进的Vibe建立背景模型,系统运行效率提高了约5% ~15%,因此具有一定的实用性。

表1 运动对象提取的客观数据分析
3 小结
本文提出一种背景建模和运动对象分割方法。引入了Vibe背景模型在H.264压缩域分割出宏块级运动对象,进一步根据提取的DCT残差系数,通过最大熵自适应阈值精细化运动对象边缘。实验结果显示,本文提出的算法具有良好的分割效果,适用于处理性能要求较高的应用领域,具有一定的实用价值。新一代视频压缩编码标准HEVC已经发布,下一步研究任务将结合HEVC、动态背景下的压缩域运动对象分割、像素域的运动对象分割技术三点展开,进一步完善算法以顺应高清监控视频市场。
:
[1] BABU R,RAMAKRISHNAN K,SRINIVASAN S.Video object segmentation:a compressed domain approach[J].IEEE Trans.Circuits and Systems for Video Technology,2004,14(4):462-474.
[2] WANG R,ZHANG H,ZHANG Y.A confidence measure based moving object extraction system built for compressed domain[C]//Proc.ISCAS 2000.Geneva:IEEE Press,2000:21-24.
[3] ZEN H,HASEGA T,OZAWA S.Moving object detection from MPEG coded picture[C]//Proc.ICIP 1999.Kobe:IEEE Press,1999:25-29.
[4] ZENG W,DU J,GAO W,et al.Robust moving object segmentation on H.264/AVC compressed video using the block-based MRF model[J].Real-Time Imaging,2005,11(4):290-299.
[5] CHEN Y,BAJIC I.A joint approach to global motion estimation and motion segmentation from a coarsely sampled motion vector field[J].IEEE Trans.Circuits and Systems for Video Technology,2011,21(9):1316-1328.
[6] CHEN Y,BAJIC I,SAEEDI P.Moving region segmentation from compressed video using global motion estimation and markov random fields[J].IEEE Trans.Multimedia,2011,13(3):421-431.
[7] CHEN Y,BAJIC I,SAEEDI P.Motion segmentation in compressed video using markov random fields[C]//Proc.IEEE ICME 2010.[S.l.]:Press,2010:760-765.
[8] WANG T,LIANG J,WANG X,et al.Background modeling using local binary patterns of motion vector[C]//Proc.VCIP 2012.San Diego,CA:IEEE Press,2012:1-5.
[9]毕厚杰,王健.新一代视频压缩编码标准—H.264/AVC[M].2版.北京:人民邮电出版社,2009.
[10] LIN C,YU C.Image segmentation based on maximum entropy and kernel self-organizing map[C]//Proc.S-CET 2012.Xi’an:IEEE Press,2012:1-4.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
汽车工程师(2021年12期)2022-01-17
当代陕西(2020年14期)2021-01-08
北京航空航天大学学报(2020年10期)2020-11-14
计算机与数字工程(2020年3期)2020-06-09
自动化学报(2019年6期)2019-07-23
贵州师范学院学报(2016年4期)2016-12-01
电子设计工程(2015年24期)2015-08-26
河南科技(2015年8期)2015-03-11
卷宗(2013年3期)2013-05-14
