
云计算模型中关联规则增量更新方法
2014-12-23 01:25杨泽民
计算机工程与设计 2014年2期
杨泽民
(山西大同大学 数学与计算机科学学院,山西 大同037009)
0 引 言
关联规则挖掘可以发现大量数据中项集之间有趣的关联或相关联系,挖掘关联规则的核心是通过统计数据项获得频繁项集,传统的算法大部分是基于单结点的,主要包括Apriori算法、Partition、FP2growth 及抽样算法等。但是随着数据集的不断增长,数据量级别已经到达TB 级甚至PB级,传统的单结点串行算法已经无法满足数据量急剧增长的需要,与此同时,随着数据集的动态增长,隐藏的关联规则也会随之发生变化,这就对关联规则挖掘算法提出了更高要求,即要能准确挖掘频繁项集,又要能实时更新已有的频繁项集,主要包括当新的数据集添加到旧的数据集时,如何产生新的频繁项集,当从旧的数据集删除一个数据集时,如何更新频繁项集,以及当最小支持度与最小置信度发生变化时,如何生成新的频繁项集等,这些都已成为热点研究方向。
目前,专家学者们已对关联规则与其相关的算法进行了大量的研究,并提出很多效率较高的算法。大部分关联规则增量式更新算法是在Apriori[1]算法的基础上进行改进的,其中张恺提出一种基于云计算的Apriori算法[2],提高传统关联规则挖掘算法的效率。唐璐等提出一种改进的关联规则增量式更新算法IFU[3],用于解决数据库和最小支持度均发生改变时关联规则的增量式更新问题。朱晓峰等提出了一种基于MapReduce的关联规则增量更新算法MRFUP[4],算法只需要扫描一次数据库,利用云计算强大的存储和并行计算能力来解决海量数据挖掘的问题。
本文将改进串行方式关联规则挖掘效率较低、海量数据增量更新挖掘等问题,提出一种基于云计算模式的关联规则增量更新算法,主要贡献如下:
(1)提出一种单节点环境下的关联规则增量更新算法(IUM),可以有效地解决规模较小的关联规则增量挖掘问题。
(2)采用MapReduce函数对的设计方法,将IUM 算法并行化,提出基于云计算的关联规则增量更新算法(CIUM)。
(3)提出一种关联规则增量更新的云计算框架,并且可以扩展到其它数据类型的挖掘应用中。
1 云计算模型
云计算[5]是并行计算、网格计算、效用计算、分布式计算、虚拟化、网络存储等先进计算机技术和网络技术整合的产物,具有高效性与普遍适用性,图1给出了以上相关概念之间的层次关系。云计算技术与海量数据处理紧密相关,利用云计算来解决大规模树数据挖掘是一个具有发展潜力的方向。在存储能力方面,云计算平台提供的树数据存储与维护能力是传统数据库无法比拟的,海量树数据容量可能达几百GB甚至TB级别,如果用传统数据库进行存储维护成本会较大,而云计算平台则提供了分布式的存储模式,可以将大量普通计算机的存储能力和计算能力汇聚在一起,为海量数据提供足够空间,同时云计算环境还提供了数据备份、并发控制、一致性维护和可靠性等策略,可以为海量数据提供可靠保障。在处理能力方面,云计算平台提供了分布式处理能力,利用该特点,可以对数据挖掘过程进行并行处理,可以显著提高海量数据挖掘的能力。在灵活性与可伸缩性方面,云计算平台具备良好的灵活性与可伸缩性,非常适合对数据量弹性变化较大的海量树数据进行处理。云计算平台提供了向现有云中扩充节点的功能,以提高计算资源与存储容量。
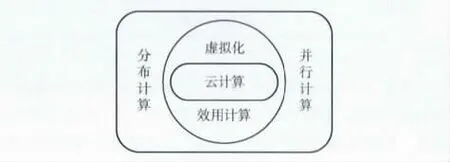
图1 云计算相关概念关系
在云计算平台下进行海量数据处理主要包括MapReduce和BSP 两 种 模 型[6]。谷 歌 的Pregel[7]与 雅 虎 的Giraph[8]就是基于BSP模型,但BSP 模型存在着消息通信效率瓶颈。MapReduce模型主要包括Hadoop[9]与HOP[10]系统,本文将利用MapReduce模型来处理海量树数据。在Hadoop平台中执行MapReduce操作的各阶段的工作流程如下[5]:
(1)输入文件:MapReduce库将输入的大数据文件分成若干独立的数据,并在不同的机器上进行程序数据的备份。
(2)分配任务:MapReduce中Master节点分配子任务,并将子任务递交给空闲的worker节点中。
(3)生成键值对:被分配的子任务的工作节点读取输入的的文件,从中解析出key/value键值对,并调用用户编写的Map函数处理键值对,并生成中间键值对。
(4)发送消息:分区函数将这些中间数据分成若干区,将各个区在磁盘中位置信息发送给Master,然后转发给Reduce子任务节点。
(5)调用中间数据:Reduce子任务节点获取由Master转发的子任务后,根据位置信息调用磁盘上中间数据,并对这些中间按key值进行排序,相同key值进行合并操作。
(6)执行Reduce函数:Reduce子任务节点遍历排序后的中间数据,并将数据传递给用户定义的Reduce函数。其执行结果将被输出到最终的输出文件中。
(7)输出结果:等所有Reduce子任务完成后,Master节点将所有数据返回给用户程序,用户程序合并数据并输出最终数据。
综上所述,基于Hadoop平台的MapReduce算法工作流程简单可行,在设计时只需考虑任务的分配策略与MapReduce函数对的设计,而对于其它并行计算中的复杂问题,如工作调度、容错处理、分布式存储、网络通信等则交给Hadoop平台进行处理。因此,本文将基于Hadoop平台设计出一种关联规则增量更新算法以改善海量数据的更新挖掘效率,实验结果表明,算法具有可行性以及良好的运行效率。
2 云计算模型下关联规则增量更新算法
传统的Apriori算法通过逐层搜索的迭代方式来挖掘频繁项集,主要包括两个步骤:连接与删除。通过对频繁k-1项集进行两两连接产生候选k项集,连接步骤可以标记为Lk-1Lk-1=Ck,Ck为候选k项集。Ck中包含所有的频繁k 项集Lk与非频繁k 项集,即LkCk,循环扫描数据库可以得到每个候选项集的支持度,并根据最小支持度阈值来筛选出所有的频繁k项集。然而在循环扫描过程中需要进行大量的I/O 操作,特别是在大数据量的情况下,算法效率较低。为提高算法的执行效率,利用频繁项集的所有非空子集也是频繁的这一性质,可以对候选k项集进行剪枝操作,以提高算法运行效率。然而当数据集发生增量更新时,传统的Apriori算法已经满足新的需求,只能重新扫描数据库挖掘频繁项集,这样会极大地增加挖掘时间与消耗系统资源。因此本文首先提出在单计算结点下的关联规则增量更新算法IUM (incremental updating mining),算法描述如下:
算法1:IUM
输入:原数据库TDB,频繁项集Lk,新增数据库tdb,最小支持度s
输出:新的频繁项集L*k
(1)对所有的X∈Lk,扫描新增数据集tdb,得到X 在TDB∪tdb中的支持数s(TDB∪tdb),若s(TDB∪tdb)<s×(TDB+tdb),则该项集为非频繁的,并将X 从Lk中进行删除。
(2)在tdb中找出所有的候选频繁k项集Ck,对所有的X∈Ck,扫描tdb 并计算每个候选项集的支持数,若支持数小于s×tdb,则该候选项集是非频繁的,可以将X 从Ck中剪掉,以此得到一个更加精简的候选项集的集合C′k。
(3)扫描原始数据库TDB,更新Ck中所有候选项集的支持数,并发现TDB∪tdb中新的频繁项集,这些新的频繁项集与上述更新后的Lk共同组成了新数据库中的频繁项集Lk*。
在IUM 算法的执行过程中,每次迭代只需要扫描整个数据库一次,对于新产生的频繁项集,首先根据候选项集在新增数据库tdb 中的支持数进行修剪,然后再判断在总数据库中是否频繁,这样可以大大减少扫描数据库的次数,因此IUM 算法在增量更新发生时的执行效率要比使用Apriori算法要好,但是当数据库较大或频繁更新时,IUM算法会因为计算量的急剧增加而导致运行效率的降低。因此,设计一个基于云计算模型的关联规则增量更新算法CIUM (cloud incremental updating mining)来 解 决 海 量 数据挖掘的问题。
设计一个主控程序Driver[11],首先由Driver对新增数据库tdb 进行频繁项集的挖掘,得到tdb中所有的频繁项集L(tdb),将原有的频繁项集L(TDB)与L(tdb)进行对比,找出其公共部分并放入最终的频繁项集L*中,剩余的频繁项集L(TDB)与L(tdb)记为CR。然后进行MapReduce操作,算法描述如下:
算法2:CIUM
Map操作:并行扫描原始数据库与新增数据库,根据原有的频繁项集与CR,对数据进行格式化操作形成键值对<Tnum,Lk>,并将所有键值对作为中间数据传递给Reduce操作。
Reduce操作:扫描中间结果集,将中间键值对进行升序排序,依次扫描数据库并判断X∈Lk,若条件成立则删除该键值对,否则遍历tdb,计算候选项集在tdb中的支持度,如果满足条件s(TDB∪tdb)<s×(TDB+tdb),则该项集在新数据库中就是非频繁的,因此可将其删除。最后对TDB+tdb进行遍历,计算各个项集的支持度,再根据公式判断是否频繁,那么新数据库中频繁k项集由原Lk中剩下的项集和新产生的频繁项集共同组成L*k= (Lk-Ldelete)∪Lnew。
云计算模型下关联规则增量更新挖掘框架图如图2所示。
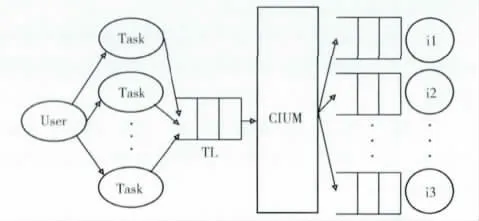
图2 云计算框架
3 实验设计与分析
本次实验主要考察关联规则增量更新算法是否具备可行性、良好的加速比与扩展率,在实验中心搭建实验所需的软硬件平台,实验所需的硬件平台见表1。
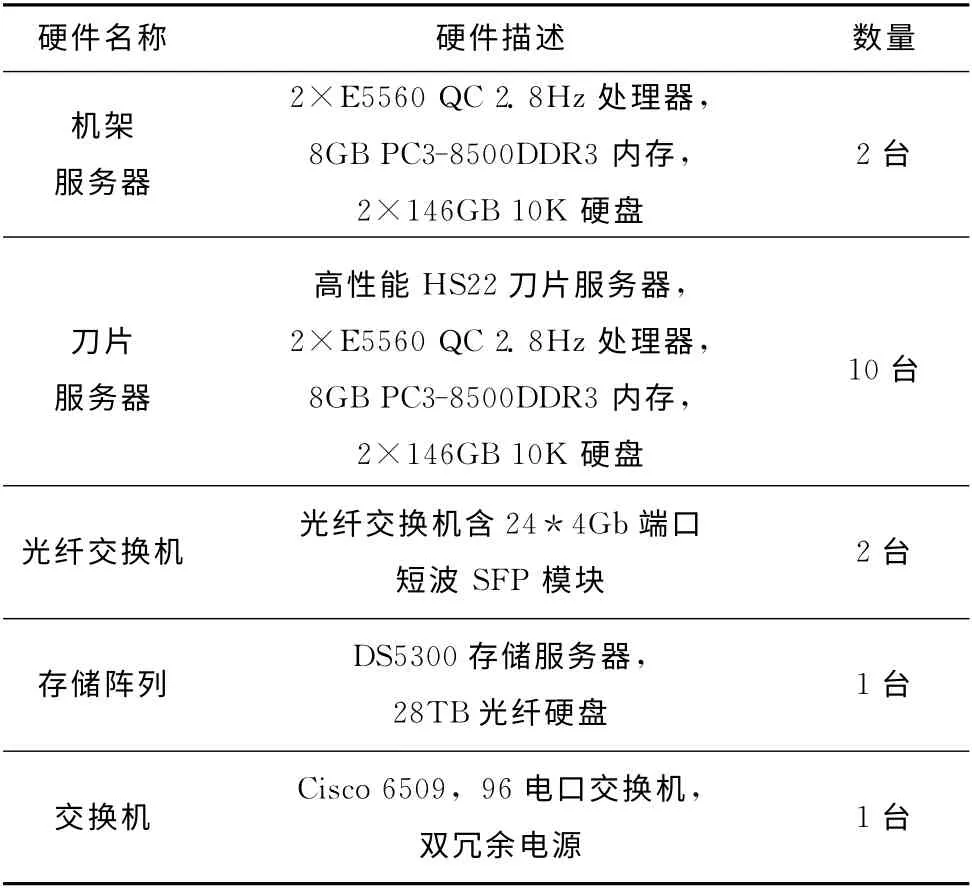
表1 硬件设施
选取了11台计算机结点作为实验设备,安装并调试好Hadoop环境,其中计算机结点的分配如下:1台作为Driver结点,控制所有程序的运行,剩余10如作为计算结点与存储设备,在计算机结点之间使用高速网卡与光纤进行连接。实验操作系统为Ubuntu Linux,用C++实现并行算法,并设计一个随机数据生成程序生成实验所需的模拟数据,随机数据生成程序还可以通过调整相应的参数来控制数据的规模与复杂程度。
实验共分为3组,第一组实验随机生成包含500000条记录的数据库,最小支持度s设置为0.02-0.1之间,最小置信度c设置为0.6,在不同的新增数据集tdb 下进行实验,具体的参数设置见表2。
实验结果如图3所示。
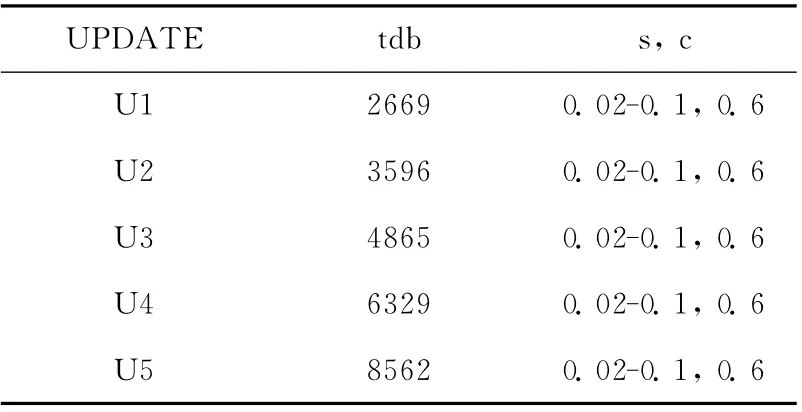
表2 参数设置
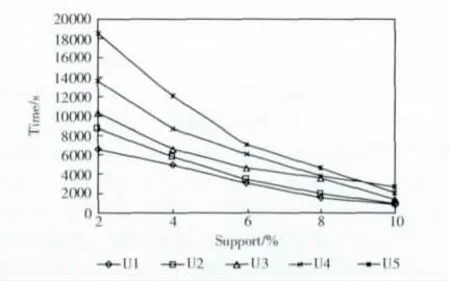
图3 不同支持度下运行结果
从图3可以发现,随着数据库的增大,算法所需的时间也就越大,这是因为数据库越大,算法产生的频繁项集也就越多,所需的计算量也就越大。同时,随着支持度的增加,算法所需的时间也就越小,因为支持度越大,产生的频繁项集也就越少,所需的运算时间也就越小。
第二组实验主要验证并行算法在不同数据规模下的加速效果,生成不同规模的数据库,设置新增数据库集tdb为8000,最小支持度阈值为0.05,实验结果如图4所示。

图4 加速比性能测试结果
从图4可知,随着数据库规模的增大,算法的加速性能会越好,数据库规模越大,运行所需代价减少比例越高,因此加速性能更好。
第三组实验主要验证并行算法的扩展率,随机选取4个计算结点,采用5 组数据集进行实验,数据集设置见表3。
设置tdb为9000,根据表3的设置运行算法,选择其中几组实验结果,如图5所示。

表3 参数设置
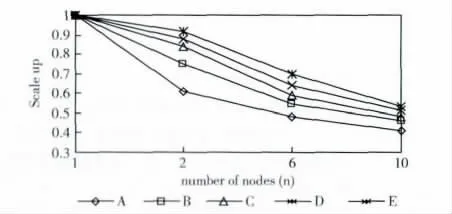
图5 扩展率测试结果
通过实验结果可以看出,随着计算结点的增多,结点之间的通讯代价也就增加,算法的运行时间也会随之增加,算法扩展率就会随之减小。同时不同的数据集对算法扩展率也有影响,数据规模越大,算法的扩展率越好,这是因为在云计算环境下,大数据集能充分发挥计算结点的计算性能,可以充分利用系统的资源与潜能,最大程度地发挥计算性能。
综上,本文提出的云计算模式下关联规则增量更新算法具有可行性,算法适合在海量数据库中进行关联规则的增量挖掘,并且具有一定的扩展率。
4 结束语
本文通过将云计算与关联规则挖掘相结合的方式,提出一种基于云计算模型的关联规则增量更新算法,改进现有单结点算法的串行执行方式,提高了算法的执行效率与关联规则增量更新的效率,特别是在海量数据集的情况下效果尤为明显。大量实验结果可以表明,本文的算法具有可行性,以及良好的加速性能与可扩展率,并且可以将算法应用于实际的项目当中。
未来我们将继续更新算法并将算法应用于其它数据类型的挖掘当中,譬如结构化数据的挖掘、社会关系网络分析等。
[1]YE Y B,CHIANG C C.A parallel apriori algorithm for frequent item sets mining [C]//Proceedings of the Fourth International Conference on Software Engineering Research Mannagement and Applications,2006:87-94.
[2]ZHANG Kai,ZHENG Jing.An improved Apriori based on cloud computing[J].Journal of Gansu Lianhe University (Natural Science Edition),2012,26 (6):61-64(in Chinese)[张恺,郑晶.一种基于云计算的新的关联规则Apriori算法 [J].甘肃联合大学学报(自然科学版),2012,26 (6):61-64.]
[3]TANG Lu,JIANG Hong,SHANGGUAN Qiuzi.An improved incremental updating algorithm for association rules[J].Computer Applications and Softwars,2012,29 (4):246-248(in Chinese).[唐璐,江红,上官秋子.一种改进的关联规则的增量式更新算法 [J].计算机应用与软件,2012,29 (4):246-248.]
[4]ZHU Xiaofeng,LI Lingjuan,XU Xiaolong,et al.MapReduce based association rule incremental updating algorithm [J].Computer Technology and Development,2012,22 (4):115-118 (in Chinese).[朱晓峰,李玲娟,徐晓龙,等.基于MapReduce的关联规则增量更新算法 [J].计算机技术与发展,2012,22 (4):115-118.]
[5]LIU Peng.Cloud computing [M].Beijing:Publishing House of Electronics Industry,2010 (in Chinese).[刘 鹏.云计算[M].北京:电子工业出版社,2010.]
[6]Dean Jeffrey,Ghemawat Sanjay.MapReduce:Simplified data processing on large clusters[J].Communications of the ACM,2008,51 (1):107-113.
[7]Malewicz Grzegorz,Austern Matthew H,Bik Art J C,et al.Pregel:A system for large-scale graph processing [C]//Proceedings of the SIGMOD,2010:135-145.
[8]Ching Avery.Giraph:Large-scale graph processing infrastruction on Hadoop [C]//Proceedings of the Hadoop Summit,2011.
[9]Son J,Choi H,Chung Y D.Skew-tolerant key distribution for load balancing in MapReduce[J].IEICE Transaction on Information and Systems,2012,95 (2):677-680.
[10]Condie Tyson,Conway Neil,Alvaro Peter,et al.MapReduce online[C]//Proceedings of the NSDI,2010:33-48.
[11]CHEN Guangpeng,YANG Yubin,GAO Yang,et al.Closed frequent itemset mining base on MapReduce[J].Pattern Recognition and Artificial Intelligence,2012,25 (2):220-224 (in Chinese).[陈光鹏,杨育彬,高阳,等.一种基于MapReduce的频繁闭项集挖掘算法 [J].模式识别与人工智能,2012,25 (2):220-224.]
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电脑爱好者(2020年18期)2020-09-26
当代陕西(2019年14期)2019-08-26
天津科技大学学报(2018年4期)2018-08-22
电脑爱好者(2017年9期)2017-06-01
中学数学杂志(初中版)(2016年5期)2016-11-01
测绘科学与工程(2014年2期)2014-02-27
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
网络与信息(2009年9期)2009-10-30
