
数字图书馆个性化信息服务隐私保护技术研究
2014-12-25 02:15薄怀霞
图书馆学刊 2014年2期
薄怀霞
(曲阜师范大学信息技术与传播学院,山东 日照 276826)
数字图书馆个性化信息服务是以信息用户的信息使用行为、习惯、偏好、特点及用户特定的需求为基础,向用户提供满足其个性化信息需求的相关内容和系统功能的一种服务。个性化信息服务是数字图书馆信息服务的发展方向。与此同时,数字图书馆的个性化信息服务也带来诸如版权、信息安全和隐私保护等一系列问题,如何有效保护图书馆用户的隐私,更好地实现数字图书馆与用户之间的双赢已受到专家学者越来越广泛的关注。
笔者以“隐私保护技术”为主题词在CNKI全文数据库中对相关学术论文进行检索,得到检索结果160条,通过分析发现,研究内容主要集中于数据和网络应用,研究领域则主要分布在计算机、经济、金融和医疗等方面;以“隐私保护”和“数字图书馆”为检索主题检索到相关文献30篇,此数字表明国内进行数字图书馆隐私保护问题的研究还非常少,简单分析所得文献还发现数字图书馆领域对隐私保护的研究角度和思路各异,研究层次也深浅不一,总体上缺乏系统性,而且对于数字图书馆中隐私保护技术的研究更是少之又少;之后又以“隐私保护技术”和“数字图书馆”为主题检索到的文献只有两篇,更加印证了上述分析结果。但是,随着社会信息化的进一步发展,以及各种统计、分析和挖掘工具在数字图书馆中的应用,数字图书馆的用户隐私问题更多地需要采用隐私保护技术加以解决。笔者主要概述了若干隐私保护技术,并初步探索了隐私保护技术在数字图书馆领域的一些应用。
1 数字图书馆的隐私保护问题
数字图书馆在按照用户个体需求提供信息服务的同时,要对用户个人的具体特点和使用信息的习惯做出细致分析,并以此挖掘用户的隐形需求,也由此才能提供针对性强的信息服务。在提供个性化信息服务时,除保证服务能真正符合用户的需求外,保护用户的个人隐私不受侵犯成为数字图书馆发展不能回避的问题,因为只有有效保护用户的隐私,才能提升用户的信任度和关注度,从而更好地实现数字图书馆的个性化服务。
数字图书馆用户在利用图书馆个性化服务的过程中,往往会被要求进行身份认证,如填写用户的姓名、年龄、性别、身份证号、职业、学历、联系电话等个人信息,另一方面网站的日志程序还会自动保存用户的IP、登录时间、登录时长、访问的内容等,这些无疑都涉及了用户的隐私信息。
图书馆采用先进的技术手段收集用户信息是其提供个性化信息服务的前提,通过对个人数据信息进行收集、挖掘与分析,获得用户的潜在需求,才能提供有针对性的内容和服务,进而更好地实现数字图书馆服务的个性化,这对数字图书馆来说是顺应网络时代发展的结果,也是Lib2.0在数字图书馆中的应用体现[1]。
目前对数字图书馆个性化服务隐私保护的研究主要集中在法律、法规、行业自律、保护技术等方面,其中对于加强隐私保护技术的研究都比较简单,仅仅列举一些现有的其他领域的隐私保护技术,并没有结合数字图书馆的特定环境和数字图书馆用户的特殊要求而展开。
数字图书馆的个性化服务系统每天都会生成大量的应用数据,这些数据可以分为个人基本资料和行为数据,个人基本资料即用户注册登记的年龄、性别、证件号、联系方式等的数据信息,而行为数据是指因用户借阅、访问等被无意识获取的数据信息。隐私保护技术的应用一方面有效限制了用户隐私信息的泄露,另一方面能够提高用户对图书馆的信任,它有利于图书馆对用户信息的收集管理,从而提高数据分析的准确性,进一步推动数字图书馆个性化服务的开展。
2 隐私保护技术
在我国数字图书馆建设的过程中,许多专家学者都认识到针对用户的隐私保护是数字图书馆建设的一项重要内容,并且指出用户隐私的泄露隐患存在于图书馆对读者个人数据信息收集、整理、贮存和利用的全过程中。数字图书馆建设应该从宏观和微观两个方面进行探讨,宏观方面主要指通过国家立法确立图书馆用户隐私权的法律地位,使对用户隐私权的保护有法可依;微观方面指有关行业采取自律措施以及通过技术手段来加强对用户隐私的保护。同时由于目前联机分析处理、数据挖掘等信息工具的广泛应用,针对隐私保护技术的研究引起越来越多专家学者的关注。
目前,关于各领域隐私保护的主要研究方向有通用的隐私保护技术、面向数据挖掘的隐私保护技术、面向数据发布的隐私保护技术和隐私保护算法[3],通用的隐私保护技术致力于较低应用层次上数据隐私的保护,一般通过引入统计模型和概率模型实现;面向数据挖掘的隐私保护技术则主要解决高层数据应用中对数据挖掘操作的隐私保护;面向数据发布的隐私保护技术是想通过提供一种在各类应用中通用的隐私保护方法,从而使得在此基础上设计的隐私保护算法具有通用性。
隐私保护的研究由实际应用中不同的隐私保护需求决定,隐私保护必须最大化技术方面的作用[2]。然而没有一种隐私保护技术是普遍适用于所有领域的,笔者根据对目前国内隐私保护技术的研究分析,将隐私保护技术分为3大类:
①基于数据失真的隐私保护技术。该方法是通过扰动(perturbation)使原始敏感数据失真来实现隐私保护,同时又能保持某些数据或数据的属性不变。这种方法一般应用在如关联规则挖掘、决策树分类器构建等各种数据挖掘操作中而数据发布者又不希望发布真实数据时。如采用添加噪声、交换等技术对原始数据信息进行扰动处理,但要求处理后的数据仍然可以保持某些统计性质以便于进行数据挖掘。
②基于数据加密的隐私保护技术。该方法是采用数据加密技术在数据挖掘过程中隐藏敏感数据信息,实现分布式环境下的数据安全通信。多应用于诸如分布式关联规则挖掘、分布式数据发布、分布式安全计算等的分布式环境下的应用操作,如安全多方计算。
③基于数据匿名化的隐私保护技术。该方法可根据具体情况有条件地发布原始数据、不发布或者发布精度较低的匿名化数据来实现隐私保护,发布的数据可进行关联规则挖掘、决策树分类器构建、聚类挖掘等的各类数据分析操作。如不发布数据的某些阈值、数据泛化等。
对于隐私保护的多种技术方法,在具有各自优势的同时也存在一系列的缺陷,因此,隐私保护技术本身无论从理论还是应用上都可以作为进一步研究的对象。
目前我国数字图书馆个性化信息服务可以借助隐私保护技术体系中的部分技术来实现对用户隐私的保护。
3 个性化信息服务中的隐私保护技术
数字图书馆用户通过网络使用图书馆服务和利用图书馆的信息资源,数字图书馆则通过数据库、网络日志等手段管理和记录用户的各种信息资料,并且会利用各种数据分析和数据挖掘工具来收集用户信息以提高其服务质量,因此数字图书馆用户的隐私保护需要从网络、数据库和数据分析、数据挖掘等角度全面有效地进行[1]。
3.1 隐私保护层次模型
为方便数字图书馆用户能更清晰地认识和把握其个人信息数据在数字图书馆个性化信息服务系统中的流动情况,并了解各环节中都有哪些隐私保护技术来保障自己的个人信息安全,作者参照网络层次模型给出了一个隐私保护层次模型(如图1所示),该模型是从个人数据收集、信息存取和数据传输3个环节将隐私保护进行分层,根据数据的流通环境分别称作网络层、访问层和通讯层,模型中分类列出了目前数字图书馆应用的几种隐私保护方法和技术。
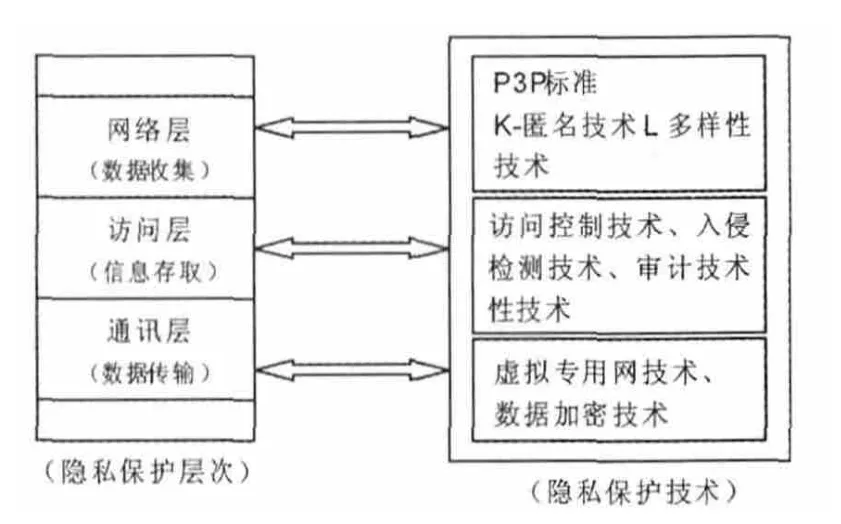
图1 隐私保护层次模型
该层次模型是基于用户数据信息在数字图书馆中的流通提出的,目的是提供给图书馆用户以直观形象的展示,使用户清楚自己的个人信息在数字图书馆个性化信息服务中是有保护有保障的,因此该模型可以作为隐私保护标准置于数字图书馆的隐私声明中。用户不仅仅想要知道自己的何种信息被图书馆服务系统收集、被收集的信息用于何种目的等基本情况,往往更关注其隐私信息能不能获得安全保障,以确保其个人隐私不被不法分子非法窃取。因此,该隐私保护层次模型的提出可以解决用户的顾虑,使用户对数字图书馆产生更大的信任,进而可以放心地使用数字图书馆提供的各种个性化信息服务,实现数字图书馆和用户之间的双赢。另外对于从事数字图书馆隐私保护技术的研究者来说,可以针对不同层次数据流通特点和各层的隐私保护技术应用成果探讨更适合于数字图书馆用户的隐私保护技术。
3.2 模型中各层应用的隐私保护技术
①网络层应用的隐私保护技术,即用户收集信息并建立信息模型的隐私保护技术。图书馆应该对如何收集用户数据、收集的用户数据类型、收集的用户数据如何使用等情况有个明确的标准,并设定一定说明,告知用户个人数据将被如何处理。万维网联盟(W3C)公布的一项隐私保护推荐标准P3P(Platform for Privacy Preferences)正是可以提供这种个人隐私保护策略的技术,用户在这种技术策略下,能够清晰地明白数字图书馆网站对自己的隐私信息做何种处理,并且P3P向用户提供了个人隐私信息在保护性上的可操作性,用户可以自主选择适合自己的隐私保护参数,决定自己的隐私数据是否被收集或者选择个人隐私数据的哪些方面可以被收集,P3P提高了用户对个人隐私信息的控制权。
为防止非法的数据挖掘操作获取用户隐私信息,目前网络层还采用了K-匿名技术、L多样性技术等来实现对用户隐私数据的保护。
K-匿名(K-anonymization)技术是普通匿名技术的扩展,它是多站点共享用户数据情况下保护用户隐私的一种重要方法,该技术模型的基本思想是数据中每个元组都存在一定数量(至少为k个)的、在准标志属性上取值相同的元组,这样即使攻击者通过其他数据链接也仅能以不超过1/k的概率来标识元组所属个体的身份,并不能唯一标识出各元组所有者的身份,从而降低链接攻击造成的隐私泄露风险。
但是不加控制的K-匿名算法容易受一致性攻击和背景知识攻击,因此,Machanavajjhala等人在K-匿名基础上又提出了L-多样性模型,该模型要求每个等价类中的敏感值满足多样性需求,以提高敏感值与其所属个体的链接难度。
②访问层的隐私保护技术,即用户信息存取访问的隐私保护技术。用户兴趣模型建立之后形成用户描述性文件并存储起来,数字图书馆需要对用户提供安全的信息存取技术,以保证用户隐私数据不被木马、黑客等利用从而造成安全威胁。此环节目前采用的安全存取访问保障技术有访问控制技术、入侵检测技术和审计技术。
访问控制技术(Access Control Technology)是控制信息安全最常用的技术手段,它允许被授予一定权限的用户对信息数据库的特定资源、程序或数据进行访问,限制其随意删除、修改或拷贝信息文件,还可限定一些数据资源的读写范围,保障授权用户获取资源的同时又拒绝非授权用户的访问。访问控制的实现首先考虑对合法用户进行验证,然后对控制策略进行选用与管理,最后要对非法用户或是越权操作进行管理。其目的就是保证用户信息不被非法访问和使用。
入侵检测是隐私保护系统不可或缺的部分。入侵检测(Intrusion Detection)是通过对信息系统的运行状态进行监视,从计算机网络和计算机系统的关键点收集信息并进行分析,从中发现网络或系统中是否有违反安全策略的行为和被攻击迹象,目的是发现攻击企图、攻击行为或攻击结果,以保证个性化信息服务系统资源的机密性、完整性和可用性。
安全审计技术(Security Audit Technology)是通过对用户关心的事件进行记录并进行独立的审查与估计,该技术包括3种类型:①系统级审计,主要包括登录情况、登录识别号、每次登录的日期和具体时间、每次退出的日期和时间、所使用的设备、登录后运行的内容等;②应用级审计,包括打开和关闭数据文件,读取、编辑和删除记录或字段的特定操作及打印报告之类的用户活动等;③用户级审计,包括用户直接启动的所有命令、用户所有的鉴别和认证尝试、用户所访问的文件和资源等。审计技术可以对潜在的信息攻击者起到威慑和警告作用,帮助个性化信息服务系统管理员及时发现系统入侵行为或潜在的系统漏洞,以便更好地保护用户隐私。
③通讯层的隐私保护技术,即用户信息通讯过程的隐私保护技术。为保护用户隐私数据不被非法截获,图书馆就需要采用安全的数据通讯技术。目前部分数字图书馆采用虚拟专用网(Virtual Private Network)技术来实现用户隐私数据在网络上的安全传输,另外还有图书馆通过将待传输数据进行加密的方式来保障数据传输的安全性。
虚拟专用网(VPN)技术是在公共网络中建立“专用网络”,数据通过安全的“加密管道”在公共网络中传播,即在公用开放的网络中附加上层协议,向用户提供类似专用网性能的网络服务技术。VPN在建立安全数据通道过程中能够提供强有力的加密手段,使偷听者不能破解拦截到的通道数据,因此保证了通道数据的机密性。建立数字图书馆专用网络可以有效保障用户信息的安全传输。
数据加密技术(Data Encryption Technology)是指将明文信息经过添加密匙及进行加密函数转换,变成无意义的密文,而接受方将此密文经过解密函数、解密密钥还原成明文的技术。数据加密系统至少要由明文、密文、密钥与加密算法4个基本要素构成,这就要求只能在指定的用户或网络下才能解除密码获得原数据,通过密码机制实现了对原始数据的不可见性和数据的无损失性,实现对用户隐私数据信息的保护。目前加密算法已具备相当高的安全性。
上述3个层次的隐私保护技术虽都有其适应性和有效性,但在数据隐私保护上并不完善,都存在一定的缺陷,因此,数字图书馆应加以研究扩展找出能够更好地保护隐私的新方法。
4 总结与展望
隐私保护技术在各个领域都有广泛的应用,针对不同领域的特点,隐私保护技术种类也非常多,笔者主要以数字图书馆用户隐私保护为研究对象,在总结目前隐私保护技术大类的前提下,针对数字图书馆用户数据信息流通环境特点,提出适用于数字图书馆的用户隐私保护层次模型,并且按照所分层次依次对目前有所应用的隐私保护技术做了简要分析。该模型符合数字图书馆用户的认识水平,可以帮助用户了解个人隐私信息在数字图书馆中的保护策略,可以作为数字图书馆网站隐私保护声明的一部分,缓解用户对图书馆的信任危机,从而实现数字图书馆和用户之间的双赢。
除传统意义上采用的隐私保护方法和技术外,一些新技术的应用对数字图书馆个性化信息服务隐私保护也具有非常重要的意义。
①结合本体论、数据挖掘为代表的信息处理技术,将数字图书馆个性化信息服务隐私保护策略进行知识化表示,并采用一定语义推理机制增加策略的推理能力,不仅可以增强隐私保护的智能化程度,提高隐私安全性,还可以增加隐私保护策略的灵活性。
②在数字图书馆个性化服务系统中增加人工智能模块,实现个性化信息服务系统智能化的隐私保护,对用户有隐私要求的信息进行隐藏或修改,自主检测企图非法进入系统的行为并进行拦截,并对用户信息传输通道进行监控检测,使用户的每一条隐私信息都配备专门的数字保镖,从而实现数字图书馆对个性化信息服务用户隐私的全面保护。
[1] 骆永成,陈惠兰,乐嘉锦.隐私保护技术在数字图书馆的应用[J].现代情报,2008(6):95-97.
[2]骆永成.数字图书馆敏感数据匿名发布若干关键技术研究[D].上海:东华大学,2011.
[3] 周水庚,等.面向数据库应用的隐私保护研究综述[J].计算机学报,2009(5):847-861.
[4] 潘浩,张幸.一种基于自主计算的数字图书馆个性化服务隐私保护框架[J].图书情报工作,2009(21):75-77.
[5] 王国霞,王丽君,刘贺平.个性化推荐系统隐私保护策略研究进展[J].计算机应用研究,2012(6):2001-2008.
[6] 曹玉平.数字图书馆个性化服务中的隐私权保护问题[J].图书馆学刊,2010(11):51-53.
[7] 周波.数字图书馆个性化信息服务中的用户隐私保护[J].图书馆论坛,2008(5):126-128.
[8] 尹凯华,熊璋.个性化服务中隐私保护技术综述[J].计算机应用研究,2008(7):1932-1939.
[9] 郭明珠,魏来,魏佳坤.个性化信息服务中用户隐私保护对策探究[J].图书馆学研究:理论版,2010(8):62-66.
[10] 刘颖.论个性化信息服务中的隐私保护[J].情报科学,2007(12):1795-1798.
[11] 戢渼钧.关于个性化信息服务的隐私保护[J].图书情报工作,2006(2):49-51.
[12] 顾朝晖,卢振波.图书馆个性化服务中的用户个人信息隐私权保护[J].图书馆论坛,2011(5):141-143.
[13] 韩建民,于娟,贾泂.面向数值型敏感属性的分级l-多样性模型[J].计算机研究与发展,2011(1):147-158.
[14] 兰丽辉,鞠时光,金华.数据发布中的隐私保护研究综述[J].计算机应用研究,2010(8):2822-2826.
[15] 王珏.高校图书馆个性化智能服务中的隐私保护[J].图书馆学刊,2009(10):26-28.
[16] 皮俊波.个性化搜索中的隐私安全保护框架[D].杭州:浙江大学,2010.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
文苑(2020年4期)2020-05-30
小太阳画报(2018年1期)2018-05-14
汽车与新动力(2016年6期)2017-01-04
小天使·四年级语数英综合(2015年7期)2015-07-06
中国卫生(2015年1期)2015-01-22
小天使·一年级语数英综合(2014年8期)2014-06-26
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
