
主分量分析和线性判别分析在分类问题中的应用
2015-01-01 03:19马冯艳
科技视界 2015年13期
马冯艳
(重庆师范大学涉外商贸学院数学与计算机学院,中国 重庆401520)
0 引言
在生产﹑科研和日常生活中我们经常会遇到判别分类问题,在这些问题中,已经知道研究对象可以分为几个类,而且对这些类别也已经作了一些观测,取得了一批样本数据.我们需要对这些数据进行处理,找到不同类别之间的显著性区别和判别方法.
主分量分析和线性判别分析是我们最常用的两种方法[1].主分量分析又称主成分分析,也有称经验正交函数分解或特征向量分析.判别分析又称“分辨法”,是在分类确定的条件下,根据某一研究对象的各种特征值,判别其类型归属问题的一种多变量统计分析方法.线性判别分析是判别分析的一种,它是运用线性方程进行判别.Fisher线性判别为线性判别中最重要的判别方法之一[2].
1 主分量分析和线性判别分析的原理
主分量分析的基本原理:把原来多个变量划为少数几个综合指标的一种统计分析方法,是一降维处理技术.主分量分析的基本思想:主分量分析是设法将原来众多具有一定相关性的指标(比如p个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标.通常数学上的处理就是将原来p个指标作线性组合,作为新的综合指标[3].
Fisher线性判别分析的基本原理:将高维空间中的类映射到低维空间,并且要求在低维空间类与类之间较好区分,是一降维处理技术.Fisher线性判别分析的基本思想:对于多个类来讲,我们希望类内离散度越小越好,类间离散度越大越好.对于原始的类,我们想通过将其投影到低维空间,并且要求经过投影后达到类内离散度最小,类间离散度最大.在投影的过程中,如果投影到一维空间效果不是很好,我们可以将其维数增多[4].
2 实例
现对三类品种的鸢尾属(Iris)植物进行研究,希望通过研究鸢尾属植物的几个主要指标,可以将一个未知样本进行归类.对鸢尾属植物的四个指标进行了统计.对统计数据作如下变换:
①对所有样本数据X进行中心化标准化.
②对处理后的数据求解相关系数矩阵R得

③求解R的特征值λi和特征向量ei.

表1 特征值,及其贡献率﹑累计贡献率表

由上表可以看出,前三个特征值的累积贡献率已达到99.485%,所以我们选取前三个特征值所对应的特征向量为主成分,这样我们就将四维空间降到三维空间.原始数据经过主分量分析,位数降低,得到变换Y=X*E.
经过主分量分析,原始数据已经降到三维,我们将对得到的三维空间里的数据再次进行降维处理.我们选取各类中的前40个样本代表该类进行研究.
④分别计算出各类的样本均值mk和所有样本的均值m

⑤计算类内离散度矩阵Sw和类间离散度矩阵Sb

⑥计算Sb和Sw的广义特征值和特征向量

由于η2比η1小很多,并且η2接近于0,所以我们只选取特征值η1所对应的特征向量组成最优投影矩阵
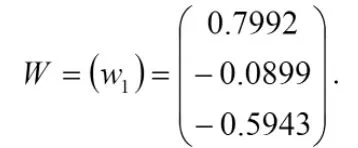
⑦对Y进行Fisher线性判别,得到变换Z=Y*W.
⑧计算经过变换后所得到的类的均值

通过主分量分析和Fisher线性判别,我们将样本由四维空间降到一维空间.由上面的计算,我们可以得到公式Z=X*E*W.
随机选取45个样本得到样本组x,在选取样本时,前15个样本是从第一类中抽取的,中间15个样本是从第二类中抽取的,最后15个样本是从第三类中抽取的.我们首先对需要判别的样本进行变换,然后分别计算这45个样本到三类均值的距离

dij表示第i个样本到第j类的距离.
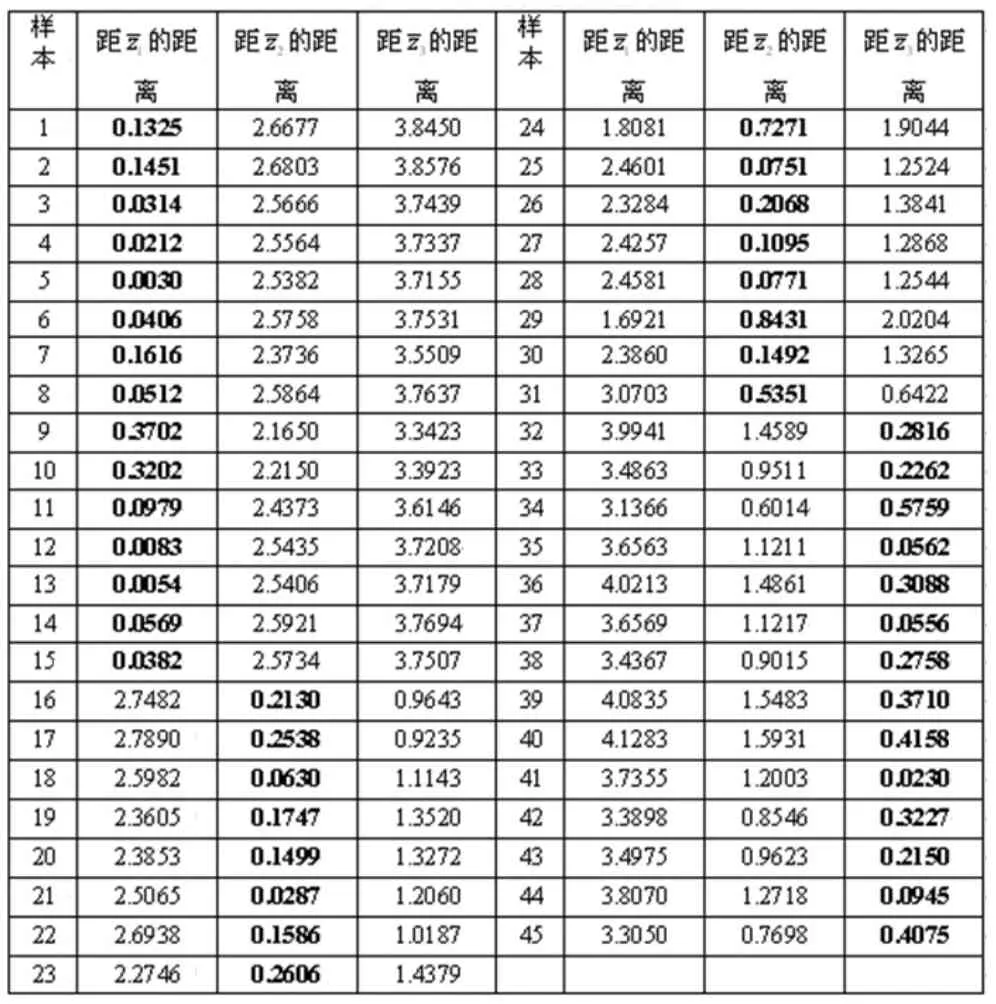
表2 样本到各类的距离表
表2中加粗的数字表示该样本距离某类均值距离最小,也就是样本属于这个类.判别结果为前15个样本判为第一类,中间16个样本判为第二类,最后14个样本判为第三类.其中第31个样本通过距离判别判为第二类,而这个样本是从第三类中抽取的;其他样本判别均正确.在这次判别中,错误率为1/45,我们认为判别是比较合理的.对所有的样本都进行分类判别,其错误率为4/150,我们认为对数据的处理以及距离判别的方法是比较合理的.
3 小结
我们在研究鸢尾属植物的三个品种时,首先运用主分量分析,在这个过程中维数降低了一维,但我们保留了99.485%的原有信息,可以说这一数据变换很有意义.在主分量分析之后,我们再运用Fisher线性判别分析,将数据进行投影,投影到一维空间.然后我们选取了45个样本进行分类判别时,判别结果比较理想,从而验证了两次降维处理的有效性和距离判别的可行性.
[1]陆元鸿.数理统计方法[M].上海:华东理工大学出版社,2005,8.
[2]吴翊,李永乐,胡庆军,等.应用数理统计[M].长沙:国防科技大学出版社,2005.
[3]朱永生.实验数据多元统计分析[M].北京:科学出版社,2009.
[4]杨淑莹.模式识别与智能计算Matlab技术实现[M].北京:电子工业出版社,2008.
[5]李弼程,邵美珍,黄洁.模式识原理与应用[M].西安:西安电子科技大学出版社,2008.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
空间科学学报(2020年5期)2020-04-16
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
大众科学(2016年11期)2016-11-30
东北电力大学学报(2015年1期)2015-11-13
四川轻化工大学学报(自然科学版)(2014年3期)2014-04-16
