
水下视频图像文字识别
2015-01-29 02:58马林冲王佳希
电子设计工程 2015年14期
马林冲,王佳希
(河海大学 计算机与信息学院,江苏 南京 210098)
近年来,由于图像处理、模式识别等计算机技术取得了飞速的发展,使得基于图像处理的文字识别领域得到广泛应用,随着 OCR(Optical Character Recognition,光学字符识别)技术研究的深入,文字识别领域引入一种基于复杂背景下的视频图像文字信息提取方法。其基本思想是通过对图像的形态学预处理、文字区域的定位与提取实现字符的识别。
以往常规的字符识别算法,适合于背景简单,字符与背景之间的对比度和分辨率都很明显,字体清晰的文本。实际情况中,水下拍摄的视频有复杂的背景、复杂的背景文理以及模糊的对比度都对字符的识别带来很大的干扰,对于有复杂背景下的文本往往识别的效率很低。
要想对复杂背景下视频图像中的文本进行识别,首先需要定位出有文本的区域,再对其中的字符进行识别。现有的文字定位方法分有以下几类[1]:基于连通元的方法(Connected Component-based Methods)、 基于边缘的方法 (Edge-based Methods)和基于纹理的方法(Texture-based Methods)。
基于连通元的方法[2]从像素级开始,通过将小的成分合并成较大的成分,直至图像中所有的区域都被确认,该方法能够准确定位文本区域的边界,实现相对简单;基于边缘的方法[3]主要是利用图像中文本与背景之间总是呈现出较强的对比度这一特性,利用某种边缘检测算子(如Canny、Sobel、Robert算子)检测出图像中的边缘信息,然后将文本边界处的边缘合并,最后用试探法来滤除非文本区域;基于纹理的方法将文本看作是一种特殊纹理,这种方法能比较有效地克服复杂背景的问题,一般使用快速傅里叶变换、离散余弦(Discrete Cosine Transform, DCT)变换、小波(Wavelet)分解和Gabor滤波等方法来提取特征。
接着要对获得的图像进行二值化处理,二值化算法主要分为两种类型,全局阈值法和局部阈值法[4]。全局阈值法是最为简单的处理方法,它采用单一的阈值对图像中所有像素点进行判定。最为著名的全局阈值法是 Otsu(大律法)算法[5],它的核心是找到一个合适的门限,使两类之间的距离最大;局部阈值法对每个像素点都动态得计算阈值,这样的阈值都是根据像素点的邻域信息计算得出,因此具有很高的准确性,二值化的效果也更好。
1 文字区域的提取
1.1 图像的预处理
根据形态学图像处理原理对图像进行预处理[6],水下拍摄到的视频图像是RGB彩色图像,首先对得到的彩色图像进行预处理后,得到的是可靠的待处理图像。首先进行图像的灰度化,公式如下:

为了避免浮点运算,提高计算速度,可以对公式(1)进行改进得到公式(2)。

然后进行图像的边缘检测[7],本文采用Robert算子识别强度图像中的边界。公式如下:
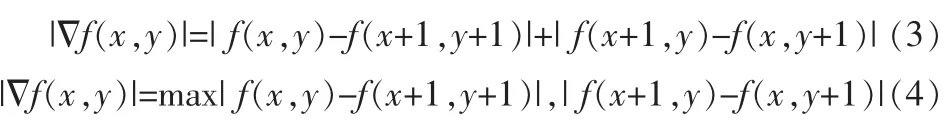
公式(3)(4)表示成模板的形式如下:
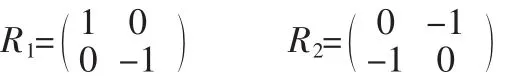
Roberts算子采用对角线方向上相邻两个像素之差近似梯度幅值检测边缘,这种算法检测水平边缘和垂直边缘的效果要好于斜向边缘,定位精度高,如图1所示。

图1 原始图像与边缘检测图像对比Fig.1 Contrast of original image and edge detection image
1.2 文字区域的定位与提取
根据预处理结果对图像文字区域进行分割,本文采用基于边缘特征的定位方法,并采用基于连通元的方法进行进一步定位。此类方法就是根据水下视频区域局部对比度明显,利用各种边缘检测算子(如Robert算子),进行边缘检测后再运用数学形态学及连通区元分析定位。
先进行水平方向的像素统计,根据水平方向的像素点确定一个水平带,即文本区域的高度;然后统计垂直方向的像素点,根据垂直方向的像素点确定文本区域的宽度;再根据文本区域的长宽比例去掉一些不符合规则的文本矩形区域,这样便得到了视频图像的文本区域,如图2所示。

图2 视频图像信息区域分割Fig.2 Image segmentation of information region
2 OCR识别
2.1 预处理
水下拍摄的实际图像有比较复杂的背景信息,文字的字体,大小有自身的特点。这样就对二值化算法提出了更高的要求。本文提出的这种全局阈值与局部阈值相结合的图像二值化方法,可以将全局阈值法和局部阈值法的优点相结合,既保留了全局阈值法对噪声的抑制作用,又保留了局部阈值法对图像细节的二值化效果突出的优点。
本文采用选择简单、快速、常用的二值化方法-0tsu作为全局阀值二值化方法,Otsu是一种使类间方差达到最大的自适应阈值化,基本原理是:灰度级t为图像的闭值,它将图像的像素分为 C0(前景)和 C1(背景)两类,设:前景点像素个数占图像比例为C0,平均灰度为U0,而背景点像素个数占图像比例为 C1,平均灰度为 U1,遍历 t,当 t使得 g=C0*(U0-U)2+C1*(U0-U)2最大时,t为分割的最大阀值。
本文采用的局部二值化方法是寻找到一个阈值t,根据其值使灰度范围分割成背景和目标:小于t的像素区域与大于t的像素区域。 假设t∈G为这个阈值,A={a0,a1}为一对对比度大的灰度级,a0,a1∈G。使用t这个灰度级作为阈值从而来对图像函数f(x,y)作二值化处理得到一个如下的二值图像函数:

选择阈值的原则是对图像信息尽可能多的去保存下来,而对噪声、背景的干扰则越少引入越好,使得经过二值化处理后的图像对原字符尽可能的再现。具体在文字识别方面的要求是对原文字特征保存基本完整、不出现断裂的情况。 本文使用迭代算法来进行阈值的选择。具体过程如下:
1)取初始阈值g0

其中gmax是文本图像最大灰度值,gmin是文本图像最小灰度值;
2)根据g0值,将图像像素分成大于g0部分和小于g0部分;
3)分别求2)步骤中两部分的期望值,取它们期望的平均值g1;
4)反复迭代,当|gn-gn-1|的值足够小时,则取T=gn得到的T为阈值。
通过预处理后得到的图像如图3所示。

图3 视频信息区域二值化图像Fig.3 Binary image of information region
2.2 字符分割
本文采用基于图像特征的字符分割方法,通过对图像中字符的特征以及字符与字符之间的特征进行分析,取得字符边界,并将字符串图像分割为单个字符。字符在水平方向上均匀分布,因此对于二值图像进行垂直方向上的投影,投影穿过字符笔画数较小的行或列被认为是两个字符的分割线。同时对可能出现的字符粘连的情况进行先验校正,若连续文字块的长度大于某阀值,则认为该快有两个字符组成,需要分割。具体方法如下:
1)行切分
文字的行与行之间通常有一定的空白间隙,文中就是利用这个空白间隙进行行切分。首先,设置图像中的第i行,第j列的像素值为 f(i,j)。 则:

规则一:将待切分的文字图像进行从上向下的顺序进行搜索,当搜索到第—个满足下列两个条件的像素行i时,则第i行为文本行的上界。
①(F(i)>Averagen/α)∩(F(i+1)>Average/α)∩…∩(F(i+n-1)>average/α)
②从第 i行到第 i+n-1行中至少有一行满足:F(k)>Average/β,其中 i≤k≤i+n-1。
规则二:对待切分的文字图像进行从上向下的顺序进行搜索,当搜索到第—个满足下列两个条件的像素行i时,则第i行为文本行的下界。
①有连续 m 行满足:(F(i)<δ)∩(F(i+1)<δ)∩…∩(F(i+m-1)<δ)。
②从第i行到第 i+m-1行中至少有一行满足:F(k)<δ,其中 i≤k≤i+m-1。
2)字分割
采用与行分割相同的算法实现字分割,水下视频文字在水平方向上均匀分布,因此对于二值图像进行垂直方向上的投影(即统计每一列上白色像素点的个数,白色像素点代表字符笔画区域)。投影穿过字符笔画数较小的行或列被认为是两个字符的分割线。同时对可能出现的字符粘连的情况进行先验校正,若连续文字块的长度大于某阀值,则认为该快有两个字符组成,需要分割。
再将分割得到的字符进行归一化,字符图像的归一化是指无论输入的字符图像尺寸(大小)为多少,都通过处理,将其变为尺寸一致的标准大小的字符图像。本文将分割后的图像统一转换成15×25大小的图像,与模板库中的图像保持一致。便于接下来的字符识别,如图4所示。

图4 字符分割结果Fig.4 Result of character segmentation
3 字符识别
根据水下视频文字的特点进行模板库设计,将分割出的字符与模板库中的字符进行匹配。本文针对特定的水下视频图像文字的识别,由于水下视频文字在字体大小、风格等有自己的特点,为了更好的实现字符识别,本文采用对多幅水下图像文字提取,通过对比、去噪、修正等方法,生成字符库。
基于模板匹配的基本过程是:首先对待识别字符进行二值化并将其尺寸大小缩放为字符数据库中模板的大小,然后与所有的模板进行匹配,最后选最佳匹配作为结果。模板匹配的主要特点是实现简单,当字符较规整时对字符图像的缺损、污迹干扰适应力强且识别率相当高。根据匹配结果,实现字符识别并保存到文档中。如图5所示。

图5 字符识别结果Fig.5 Result of character recognition
4 结 论
本文基于实用的角度,在参阅大量文献并总结回顾现有方法的基础之上,提出一种全局阈值与局部阈值相结合的二值化方法。本方法是针对现有方法在检测分辨率较小的文字以及含有复杂背景文字时效果不理想这一问题而提出的,实验表明该方法可以快速而有效的检测出视频图像中分辨率较小的文字所在的区域。全局阈值与局部阈值相结合的二值化方法则是对现有二值化方法的一种改进,将全局阈值二值化方法和局部阈值二值化方法的优点相结合,既保留了全局阈值二值化方法对噪声的抑制作用,又保留了局部阈值二值化方法对图像细节的二值化效果好的特点,本文在以上方法的基础之上实现了水下视频文字提取的原型系统。
[1]Shivakumara P,Phan T Q,Tan C L.A laplacian approach to multi-oriented text detection in video[J].IEEE Transactionson Pattern Analysis and Machine Intelligence,2011,33(2):412-419.
[2]Yi C,Tian Y.Text string detection from natural scenes by structure-based partition and grouping[J].IEEE Transactions on Image Processing,2011,20(9):2594-2605.
[3]SHAO Yun-xue,WANG Chun-heng,XIAO Bai-hua,et al.Text detection in natural images based on character classification, in Advances in Multimedia Information Processing-PCM 2010[M].G Qiu, et al, Editors Springer Berlin/Heidelberg,2011.
[4]朱虹.数字图像处理基础[M].北京:科学出版社,2005.
[5]N.Otsu.A threshold selection method from gray-scale histogram[J].IEEE Trans.on System, Man, and Cybernetics,1978(8):62-66.
[6]冈萨雷斯.数字图像处理[M].3版.阮秋琦,译.北京:电子工业出版社,2011.
[7]Chunmei Liu,Chunheng Wang,Ruwei Dai.Text detection in images based on unsupervised classification of edge-based features[C]//In Proceedings of International Conference on Document Analysis and Recognition,2005:610-614.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
现代电子技术(2021年1期)2021-01-17
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
红领巾·萌芽(2019年8期)2019-08-27
数字通信世界(2019年3期)2019-04-19
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
中国与非洲(法文版)(2017年10期)2017-11-23
