
基于随机森林的中药寒、热药性代谢组学判别方法研究*
2015-02-25 00:49聂斌第一作者聂斌97江西峡江人研究方向中医药信息学数据挖掘人工智能mailncunbcom郝竹林桂宝王卓杜建强通信作者杜建强教授硕士生导师mailjianqiangducom王国龙张鑫江西中医药大学计算机学院南昌0004江西省公安厅科技信息化总队南昌0006南昌大学软件学院南昌0047
江西中医药大学学报 2015年2期
★ 聂斌第一作者:聂斌(97—),男,江西峡江人。研究方向:中医药信息学、数据挖掘、人工智能。 E-mail:ncunb@6.com。 郝竹林 桂宝 王卓 杜建强通信作者:杜建强,男,教授,硕士生导师。E-mail: jianqiang_du@6.com。 王国龙 张鑫 (.江西中医药大学计算机学院 南昌 0004; .江西省公安厅科技信息化总队 南昌 0006; .南昌大学软件学院 南昌 0047)
基于随机森林的中药寒、热药性代谢组学判别方法研究*
★聂斌1*第一作者:聂斌(1972—),男,江西峡江人。研究方向:中医药信息学、数据挖掘、人工智能。 E-mail:ncunb@163.com。郝竹林1桂宝2王卓3杜建强1*通信作者:杜建强,男,教授,硕士生导师。E-mail: jianqiang_du@163.com。王国龙1张鑫1(1.江西中医药大学计算机学院南昌 330004; 2.江西省公安厅科技信息化总队南昌 330006; 3.南昌大学软件学院南昌 330047)
摘要:目的:建立中药寒、热药性判别模型与方法。方法:利用中药寒、热药动物实验,获取代谢组学数据;再采用随机森林算法构建中药寒、热药性分类判别模型。结果:基于随机森林构建的中药寒、热药性代谢组学分类判别模型,能够很好地实现分类判别,总体准确率超过90%;用前30个最重要的M/Z值构建的分类判别模型,同样有很高的分类准确率;经7∶3测试,准确率也超过90%。结论:基于随机森林的中药寒、热药性代谢组学分类判别模型,经实验数据建模验证表明其可行有效。
关键词:随机森林;中药药性;代谢组学;分类
代谢组学[1-4]是继基因组学和蛋白组学后一种新的定性定量分析方法,此法作为一个科学分支,专注于临床诊断、药学、系统生物学等领域的研究和应用。代谢组学常用核磁共振波谱法,高效液相色谱法,质谱法,气相色谱法等获取多样复杂的数据。
Breiman提出的随机森林[5]方法,利用随机重采样技术 bootstrap 和节点随机分裂技术构建多棵决策树,通过投票得到最终分类结果[6]。随机森林[7-10]采用随机选择样本和随机选择特征,具有许多优点:比单棵的决策树更稳健,泛化性能好;具有很好的抗噪声能力,抗异常值,自动处理缺失值以及能对付不平衡数据;对规模参数不敏感,对于不相关和冗余特征不敏感,能对付特征比分类少的情况;对于很多种资料,可以产生高准确度的分类器;不必担心过度拟合;能够估计哪个特征在分类中更重要,也可侦测偏离者;在训练过程中,能够检测到特征间的互相影响;袋外数据K折交叉验证可提供高度可靠的评估模型;算法容易理解,快速。
目前,在代谢组学基础上,实现对中药寒、热药性判别的方法有偏最小二乘判别法[11-14],正交信号校正的偏最小二乘判别法[15],小波压缩的偏最小二乘判别法[16],分层聚类法[17]等。
1随机森林理论
1.1随机森林分类理论简介随机森林[5,18]采用随机选择样本和随机选择特征,生成多个决策树{h(x,θk)}组成的分类器,其中{θk}是相互独立且同分布的随机向量。最终由所有决策树投票综合决定输入向量x的最终类标签。
为了构造k棵树,需要先产生k个随机向量θ1,θ2,L,θk,这些随机向量θi是相互独立的,并且是同分布的。随机向量θi用于构造决策分类树h(x,θi),简化为hi(x)。构造树的过程中,按照节点不纯度最小的原则从特征中随机选取一个特征进行分支生长。
1.2随机森林算法随机森林算法原理如下及图1所示:
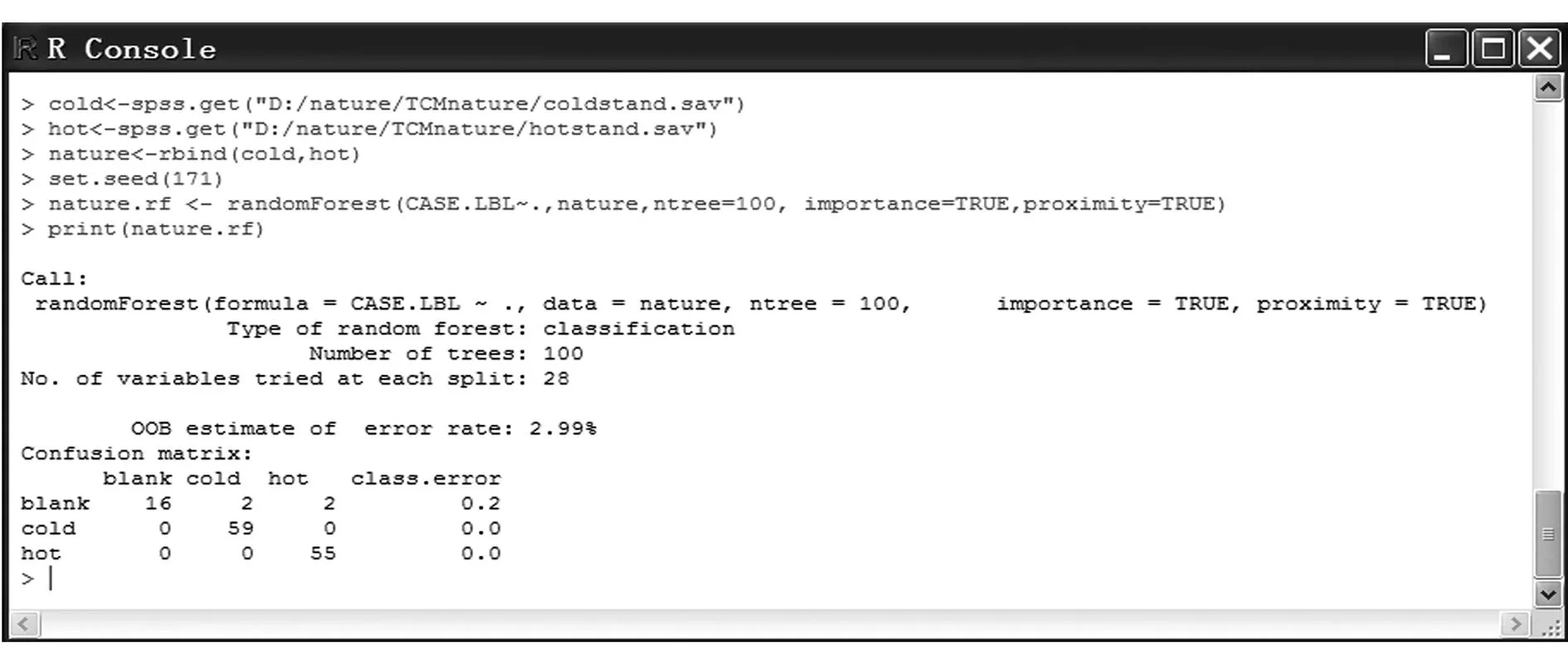
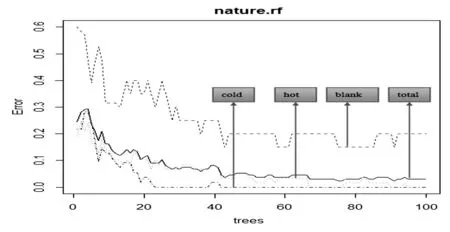
①从原始训练样本中采用Bootstrap抽样随机抽出k个样本,k ②从解释变量中随机抽出m个特征(变量),从抽中变量中选择最能有效分割数据的变量,使分割后的子集内部变异性最小,对于连续数据通常是采用均方误作为判断指标,对于离散数据则多采用基尼值; ③依据步骤②得到的变量将数据分割为两个纯度较高的子集; ④对子集重复步骤③直到分割停止。这就完成了单棵树的建模; ⑤重复步骤①到步骤④X次,就构建了有X棵树的随机森林模型。 这里在使用Bootstrap方法进行抽样时,未选中的数据称为OOB(out-of-bag)袋外数据,OOB数据可以用来检验模型的外推预测精度。 1.3变量重要性评估及变量选择变量重要性评估是随机森林算法的一个重要特点。随机森林程序通常提供4种变量重要性度量。文中采用基于袋外数据分类准确率的变量重要性度量,对变量重要性评分及变量选择。 随机森林变量删选的基本思想是采用启发式算法,通过对一个相关变量(即对预测准确率可能起重要作用的变量)加入噪声后的预测准确性差异来判断变量的重要性,其具体算法过程如下及图1所示: ①用自助样本形成每一棵分类树的同时,对相应的OOB数据进行投票,得到k个自助样本OOB中每一个样本的投票分数,记为vote1,vote2L,votek; ②将变量xi的数值在k个OOB样本中的顺序随机改变,形成新的OOB测试样本,然后用已建立的随机森林对新的OOB进行投票,根据判别正确的样品数得到每一个样本的投票分数,所得结果可以表示为: ③用vote1,vote2L,votek与公式(1)对应的和i行向量相减,求和平均后得变量xi的重要性评分,即: 图1 随机森林算法原理和变量重要性度量 2数据来源及算法实现平台 R语言,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。R的源代码可自由下载使用,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux)、Windows和MacOS。参阅网址http://www.r-project.org/。 3基于随机森林算法的中药寒、热药性代谢组学判别模型 基于随机森林算法构建中药寒、热药性代谢组学判别模型,其中分类变量CASE.LBL有三类:空白组blank,寒性药组cold,热性药组hot,ZK.代表M/Z值。 图2 随机森林模型的OOB数据估计(全模型) 图3 随机森林决策树大小与OOB数据估计(全模型) 3.1全部M/Z值构建判别模型(全模型)通过随机森林算法对中药寒、热药性代谢组学数据构建分类判别模型。(1)在生成100棵决策树时,结果趋于稳定;经袋外数据OOB估计,得到相应的结果如图2-3显示,其中空白组blank分类准确率为80%(错误率为20%),寒药组cold分类准确率100%,热药组hot分类准确率为100%,总体total分类准确率为97.01%(错误率为2.99%)。(2)基于随机森林的中药寒、热药性代谢组学分类判别二维效果如图4,三类样本相对独立,空白组中有2个样本靠近热药组群、2个样本靠近寒药组群。这些结果表明,基于随机森林算法构建的中药寒、热药性代谢组学分类判别模型能够实现很好的分类。另外,提取前30个最重要(VIP)的M/Z值如图5和表1。主要代码如下: >cold<-spss.get("D:/nature/TCMnature/coldstand.sav") >hot<-spss.get("D:/nature/TCMnature/hotstand.sav") >nature<-rbind(cold,hot) >set.seed(171) >nature.rf<-randomForest(CASE.LBL~.,nature,ntree=100,importance=TRUE,proximity=TRUE) 据介绍,目前可用于项目或可供参考的已有水利行业标准规范主要有55个,国家及其他行业相关标准主要有79项。在这些标准规范中尽管已包含水文、水资源、水利信息监控等众多相关内容,但由于项目涉及的信息和业务量十分庞大,许多信息和业务还没有相应的标准规范可循,而且国家水资源监控能力的建设和管理也需要有系统的标准规范支撑。因此,亟需在已有的相关标准规范基础上,根据项目建设运行的需要,建立更为完整的项目标准规范体系。 >print(nature.rf) >plot(nature.rf) >MDSplot(nature.rf,nature$CASE.LBL, main="TCM classification") >varImpPlot(nature.rf,type=1,sort=T,n.var=min(30,nrow(nature.rf$importance)),pch=19, main="Variable Importance Plot") 图4 分类判别效果(全模型) 图5 最重要的前30个M/Z值 前30个最重要的M/Z值813.8675.6228.2415.4362.4388.5289.1106.1768.8887.1116.2846.2124.1871.9802.2416.3436.5615.3506.4180.2880.0338.5409.3717.7349.3452.3578.3173.2680.7679.7 3.2前30个最重要的M/Z值构建判别模型(VIP模型)随机森林对变量评分后,获取前30个最重要的M/Z值,通过随机森林算法重新构建分类判别模型。在生成100棵决策树时,结果趋于稳定,经袋外数据OOB估计,得到相应的结果如图6-7显示,其中空白组分类准确率为90%(错误率为10%),寒药组分类准确率98.31%(错误率为1.69%),热药组分类准确率为100%,总体分类准确率为97.76%(错误率为2.24%);此时,中药寒、热药性代谢组学分类判别的二维效果如图8,三类样本相对独立,也有少部分样本点比较靠近。这些结果表明,提取的部分重要M/Z值后,重新构建的中药寒、热药性代谢组学分类判别模型能够实现很好的分类。再对M/Z值重要性重新排序如图9。主要代码如下: >coldvip<-spss.get("D:/nature/TCMnature/coldstandvip.sav") >hotvip<-spss.get("D:/nature/TCMnature/hotstandvip.sav") naturevip<-rbind(coldvip,hotvip) >set.seed(171) >naturevip.rf<- randomForest(CASE.LBL~.,naturevip,ntree=100, importance=TRUE,proximity=TRUE) >print(naturevip.rf) > plot(naturevip.rf) >MDSplot(naturevip.rf, nature $ CASE.LBL,main="Vip M/Z for TCM Classification") >varImpPlot(naturevip.rf,type=1) 图6 随机森林模型的OOB数据估计(VIP模型) 图7 随机森林决策树大小与OOB数据估计 (VIP模型) 3.3样本集7∶3法测试(7∶3模型)将样本集按比例7∶3随机分成两部分:一部分占总样本的70%,作为训练集;另一部分点样本的30%,作为测试集。 通过随机森林算法对训练集样本构建分类判别模型。在生成100棵决策树时,结果趋于稳定,经袋外数据OOB估计,得到相应的结果如图10-11显示:空白组分类准确率为94.12%(错误率为5.88%),寒药组分类准确率100%,热药组分类准确率为100%,总体分类准确率为98.96%;此训练集生成的随机森林分类判别模型对测试集的分类结果如图12显示,即所有样本中,只有16例热药组样本中2例分类错误。这些结果表明,70%样本构建的中药寒、热药性代谢组学分类判别模型能够实现很好的分类。主要代码如下: >naturecs<- nature > ind <- sample(2, nrow(naturecs), replace = TRUE, prob=c(0.7, 0.3)) >set.seed(171) >naturecs.rf<-randomForest(CASE.LBL~.,data=naturecs[ind==1,],ntree=100,importance=T,proximity=T) > naturecs.rf >plot(naturecs.rf) > naturecs.pred <- predict(naturecs.rf, naturecs[ind == 2,]) >table(naturecs.pred,observed=naturecs[ind==2, "CASE.LBL"]) 图8 分类判别效果(VIP模型) 图9 变量重要性排序(VIP模型) 图10 随机森林算法部分代码及OOB数据估计(7∶3模型训练集) 3.4讨论表2为随机森林分类判别模型结果比较,包括全模型、VIP模型、7∶3模型训练集的袋外数据估计、7∶3模型测试为70%样本生成的随机森林对30%样本的预测。blank为空白组,cold为寒药组,hot为热药组,total对应模型中以上三类样本的总和。 图11 随机森林决策树大小与OOB数据估计(7∶3模型训练集) 图12 随机森林判别模型测试效果(测试集) % (1)随机森林构建的中药寒、热药性代谢组学数据分类判别模型,采用多种方法测试表明,能够很好地实现分类判别,准确率总体都超过90%;(2)用最重要的前30个M/Z值构建的分类判别模型,同样有很高的分类准确率;(3)这30个变量在全模型和VIP模型中的重要性稍有不同;(4)经7∶3测试,准确率超过90%;(5)结果显示:三类样本相对独立,也有少部分样本点比较靠近,为什么出现这种情况,是由于实验误差还是其它原因,这少部分样本是不是刚好被误分类等,值得研究和分析。 4结论 对中药寒、热药性动物实验,获取代谢组学数据,包括5种寒药59例样本、5种热药55例样本、空白组20例样本,M/Z值837个。随机森林对实验中所有中药寒、热药性代谢组学数据,构建的分类判别模型,具有很高的分类准确率。采用前30个最重要的M/Z值,构建的分类判别模型,同样具有很高的分类准确率。这表明,随机森林构建的中药寒、热药性代谢组学分类判别模型,是一种较好的中药寒、热药性分类判别方法。 参考文献 [1]Holmes E "Metabonomics": understanding the metabolic responses of living systems to path physiological stimul via multivariate statistical analysis of biological NMR spectroscopic data[J].xenobiotica,1999.29:1 181-1 189. [2]Nicholson JK,Holmes E,Lindon JC,Wilson ID.The challenges of modeling mammalian biocomplexity[J].Nature Biotechnology,2004,22(10):1 268-1 274. [3]Pognan,F.Genomics,proteomics and metabonomics in toxicology:Hopefully not 'fashionomics' [J].Pharmacogenomics,2004,5(7):879-893. [4]Yin PY, Zhao X J, Ki Q R,et al. Metabonomics study of intestinal fistulas based on ultraperformance liquid chromatography coupled with Q-TOF mass spectrometry (UPLC/Q-TOF MS) [J].Journal of Proteome Research, 2006, (5):2 135-2 143. [5]Breiman L.Random forests[J].Machine learning.2001,45(1):5-32. [6]姚登举,杨静,詹晓娟.基于随机森林的特征选择算法[J].吉林大学学报(工学版),2014,44(1):137-141. [7]雷震. 随机森林及其在遥感影像处理中应用研究[D].上海交通大学,2012. [8]http://www.salford-systems.com/en/products/randomforests/faqs/item/134-what-are-the-advantages-of-randomforests? [9]Miao Liu,Mingjun Wang,Jun Wang,et al. Comparison of random forest, support vector machine and back propagation neural network for electronic tongue data classification: Application to the recognition of orange beverage and Chinese vinegar[J].Sensors and Actuators B: Chemical. 2013, 177:970-980. [10]方匡南,吴见彬,朱建平,等.随机森林方法综述[J].统计与信息论坛,2011,26(3):32-38. [11]王韵.中药寒、热药性代谢组学判别模式的建立研究[D].复旦大学,2010. [12]刘文慧,李雨,纪玉佳,等. 偏最小二乘在中药药性判别中的应用[J].山东大学学报(医学版),2012,01:151-154. [13]周正礼.基于初生物质成分的寒、热药性识别和偏最小二乘路径模型的建立[D].山东中医药大学,2012. [14]Bin Nie,Jianqiang Du,Guoliang Xu,etal.Classification and Discrimination for Traditional Chinese Medicine' Nature Based on PLS-DA[C].2010 International Forum on Information Technology and Applications. 2010:362-364. [15]Bin Nie,Jianqiang Du,Guoliang Xu,etal.Classification and Discrimination for Traditional Chinese medicine' Nature Based on OSC-OPLS/O2PLS-DA[C].2010 International Forum on Information Technology and Applications, 2010:354-357. [16]Zhuo Wang,Bin Nie,Jianfeng Xu,etal. A New Federation Approach in Analysis of Pharmaceuticals[J].Applied Mechanics and Materials Vols. 2012, (236-237):775-778. [17]聂斌,杜建强,刘红宁,等.改进型分层聚类方法对中药分类研究[J].江西中医院学院学报. 2010,22(2):94-96. [18]郭颖婕,刘晓燕,郭茂祖,等. 植物抗性基因识别中的随机森林分类方法[J].计算机科学与探索,2012,1:67-77. The Research for Metabolomics Discriminant Method for Cold and Hot Property of Traditional Chinese Medicine Based on Random Forest NIE Bin1, HAO Zhu-lin1, GUI Bao2, WANG Zhuo3, DU Jian-qiang1, WANG Guo-long1, ZHANG Xin1 1.SchoolofComputer,JiangxiUniversityofTraditionalChineseMedicine,Nanchang330004,China; 2.ScienceandTechnologyInformationTeamofJiangxiProvincialPublicSecurityDepartment,Nanchang330006,China; 3.SchoolofSoftware,NanchangUniversity,Nanchang330047,China. Abstract:Objective: To establish discriminant method for cold and hot property of traditional Chinese medicine.Mthod:Obtained metabolomics data from experiments on animals. Built model for discriminant cold or hot property of traditional Chinese medicine based on random forest. Results: The model could well realized its' classification, the overall accuracy was more than 90%. The same high level accuracy use the top 30 M/Z values to build model. The same high level accuracy used 7∶3 test.Conlusion: The metabolomics discriminant method for cold or hot property of traditional Chinese medicine based on random forest, which is proved to be feasible and effective after tested with the experiments data. Key words:Random Forest; Property of Traditional Chinese Medicine; Metabolomics; Classification 收稿日期:(2014-06-07)编辑:曾文雪 中图分类号:TP391.4 文献标识码:A 基金项目:*国家自然科学 (61363042);江西省教育厅科技计划项目(GJJ13014);江西省卫生厅中医药科研计划项目(2013A023、2013A065);江西中医药大学校级课题(2013ZR0068)。













猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国中药杂志(2016年21期)2017-02-16
中国中药杂志(2016年21期)2017-02-16
安徽农学通报(2017年1期)2017-02-15
中国中药杂志(2016年22期)2017-02-13
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
