
基于特征关联性的人脸高层特征研究
2015-03-07 09:24陈雁翔
合肥工业大学学报(自然科学版) 2015年8期
陈雁翔, 刘 磊
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
0 引 言
人脸识别,即利用人脸视觉特征信息通过分析比较进行身份鉴别的计算机技术,属于生物特征识别技术。在现有的生物特征识别技术中,人脸识别技术具有传统的识别技术无法比拟的优点,如直接、友好、对用户干扰少及更易于被接受等优点。它具有广泛和巨大的应用前景,可用于身份鉴别、身份确认等。现有的多种人脸识别算法均是在假定注册者提供了丰富训练样本的情况下进行研究的,这些算法中比较有代表性的方法有主成分分析[1](principal component analysis,PCA)、隐马尔可夫模型[2](hidden Markow models,HMM)、贝叶斯算法[3]、线性判别分析[4](linear discriminant analysis,LDA)及支持向量机[5](support vector machine,SVM)等。但在门禁系统、VIP追踪系统等一些特殊的场合,对于单训练样本的人脸识别要求比较高。由于单训练样本包含的注册者信息少,对光照、姿态、表情甚至相机焦距等图片条件的鲁棒性较差,给人脸识别带来很大的限制。
通过先验知识尽量丰富注册者的信息是解决单训练样本问题的主要方法。即事先用大量数据训练一个3D模型[6-7],当输入单样本时,可以通过重建3维人脸来解决数据量不够的问题。同理光照、表情等因素也可以通过事先训练模型来模拟。
对于3D重建而言,其复杂程度较高,模型固然可以用大量的图片来训练,但进行纹理映射时人脸的对齐难度是很大的。当输入2D图片时,事先选取好的每一个关键点都必须与模型中的关键点匹配,为了获得更好的映射纹理,则必须选取较多的关键点,而更多的关键点又将增加对齐的难度。因此以上因素均增加了该方法在实际应用中的困难。
针对单样本问题[8]的人脸识别方法,主流算法可大致划分为全局方法、局部方法及混合方法3类。本文结合可变光照、姿态,探讨了单样本限制下的全局方法和局部方法的人脸识别问题。
基于上述分析,以寻找单训练样本条件下[9-10]对人脸识别中的各种限制有一定容忍能力的方法为出发点,本文提出了依据参考集(reference set)的先验知识,计算注册者和测试者与参考集之间的余弦距离,以该距离作为一种对姿态、光照等因素不敏感的高层(high-level)特征,简称特征关联性(feature correlation,FC)算法,具体流程如图1所示。同时为了减少类内之间的相关度,引入类内协方差归一化[11](within class covariance normalization,WCCN)来提高识别效果。与3D重建方法相比,该算法不需要选取很多的关键点,减少了难度,从而提高了算法的可行性,只通过参考集的合理选取,就可以获得较好的识别结果,文中实验结果也证明了这一点。

图1 高层特征生成算法
1 人脸识别系统的整体框架
识别系统的数据库包含参考集、训练集、测试集3部分,其中参考集主要用来提供先验知识,训练集为注册者人脸信息,测试集是用来评估系统性能的测试人脸。基于特征关联性的人脸高层特征识别系统的整体框架如图2所示。

图2 基于FC的人脸高层特征研究系统的整体框架
为了准确地提取人脸特征,首先进行关键点检测和人脸定位[12],获得人脸后,对于每张图片采 取 分 层 高 斯[13](hierarchical Gaussianization,HG)方法对人脸提取HG特征。提取所得HG特征通过特征降维,利用FC算法获取新的识别特征。对于FC算法,首先对参考集中每个人的所有图片特征求出均值,分别计算出训练集(测试集)的每个人脸数据与参考集中每个人脸数据的距离。把对应训练集(测试集)中的每个人脸的距离依次组合构成一个向量,该向量作为这个人脸的高层特征。该新的特征将具备对姿态、光照等因素的鲁棒性。最后得到概率评分进行人脸识别或确认,并以此评价本文提出的系统性能。
2 基于FC算法的人脸识别
2.1 底层特征的提取
为了准确提取人脸特征,首先进行关键点的检测和人脸定位,获得人脸后,对于每张图片i,采取HG方法对人脸提取HG特征F(I),如图3所示。传统的直方图表示和空间金字塔匹配是分层高斯的特殊情况[13]。本文为了减少运算量,利用主成分分析(principal components analysis,PCA)将HG特征简化为200维。

图3 用于识别的HG特征生成顺序图
2.2 FC算法
在参考集中,每个人脸数据包含随机选取的200张该人面部图片,涵盖各种光照和姿态。对训练的图片求其与参考集各个图片的距离,将该距离作为训练集的新特征。若测试集中含有训练图片,则利用该张测试集中的人脸图片计算所得的新特征应与训练集的新特征相类似,且其相似度最大。基于这种思想,本文提出了FC算法,该算法是将注册者和测试者与参考集的距离作为对姿态、光照等因素不敏感的高层特征的一种算法,其优点在于把低维的特征转换到高维去求解。因此采用FC算法的效果会有所提高。
在获取新特征过程中,对参考集中每个人的所有图片特征求均值,并将均值作为参考集中对应人的特征,本文将其称为global;若依据光照将每个人的200张图片分为13类,对每一类的所有图片特征求均值,把均值作为参考集中对应类的特征,从而形成了13个中心。同理,按照姿态也可以将其分为5个中心,这种情况下称为local。
本算法采用余弦距离求相似度进行距离测度。例如有图像A和图像B,分别计算为HistA和HistB 2幅图像的直方图,再计算这2个直方图的归一化相关系数(欧氏距离和直方图相交距离)。该思想基于简单的数学上的向量之间的差异对图像相似程度进行度量,这种方法目前应用较多,其优势在于直方图能够很好地归一化,2幅分辨率不同的图像可直接通过计算直方图来计算相似度,且计算量较小。2幅图像之间的相似度可以用其对应的向量之间的夹角余弦来表示,即图像di、dj的相似度可以表示为:

设训练集底层特征为Fg(I)、测试集底层特征为Fp(I),则有:

(2)式、(3)式规定Fg(1)为第1个注册人的特征。规定Hr(I)为参考集底层特征,则Hr(1)为参考集中的第1个人的所有图片特征集合,即
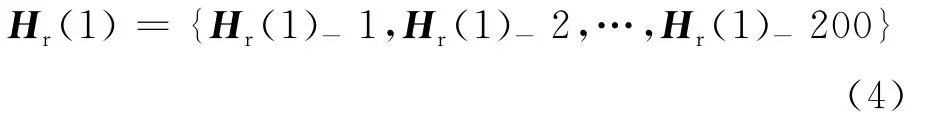
对于高层特征的提取分为全局、依据光照的局部和依据姿态的局部3种情况。全局情况下的高层特征提取方法首先求参考集中每个人的所有图片特征的均值,记为Hr(I)-g。

由(5)式、(6)式计算出训练集中的第j个人与参考集中每个人的距离,记为Fgg(j)。把对应训练集的每个人的距离依次组合构成一个向量,该向量作为高层特征,即

其中,Ng为注册者的人数。
为了得到更精细的特征,对于局部情况下的高层特征进行提取,本文依据光照和姿态对局部情况进行了分类。由于选取的照片有13种不同的光照条件,将参考集中每个人的200张图片按照光照分为13个中心。本算法中参考集图片随机选取,每类图片并不是固定的。对于第i个人的 第j个中心,记为Hl(i,j),即

其中,N为各个local对应的图片数目。
对每个人的每个中心的图片特征求均值,计算公式为:

训练集中的第k个人与参考集中每个人的每个中心的距离计算公式为:

把对应训练集的每个人的距离依次组合构成一个向量作为新的高层特征。
由于选取的图片有5种不同的姿态,将参考集中每个人的200张图片按照姿态分为5个中心。同样每类图片并不是固定的,对于第i个人的第j个中心,记为Hp(i,j),即

每个人的每个中心的图片特征的均值为:

训练集中的第k个人与参考集中每个人的每个中心的距离计算公式为:

把对应训练集的每个人的距离依次组合构成一个向量作为新的高层特征。同理,测试集中的每个人的高层特征也可以得到。
2.3 类内协方差归一化
通过以上分析可得Fg(I)、Fp(I)新特征,本文通过归一化求余弦得到距离,进而得到实验的结果,为了提高本算法的整体识别率,引入 WCCN来降低参考集中每个人脸之间的相关性。实验中,本文用选取的参考集来训练WCCN。
WCCN是一种应用于SVM核空间的特征规整方法,文献[11]研究了SVM应用于说话人识别的核方法的选择,并首先从通用的核函数形式k(x1,x2)=2(R为半正定矩阵)中,构造一系列在给定得分门限下的虚警和漏警概率的上限函数,理论和实验结果均验证了当R=W-1(W为类内协方差矩阵的期望值)时,各种情况下分类错误的上限达到最小值[11,14]。类内协方差矩阵的期望值W表示如下:

其中,xi为类别i中的任意样本点;M为总类别数,在语音识别系统中实际上为训练数据中包含的总人数;为xi的均值;Ci和p(i)分别代表类别i的协方差矩阵和类别出现的先验概率。
在实际应用中,W的经验估计值均会含有一些“噪声点”,本文一般在W上引入适当的平滑来使得WCCN规整的效果更好。

其中,Ws为平滑后的类内协方差矩阵的经验期望;I为N×N的单位矩阵;N为特征空间的维数;α为平滑因子。
给定满秩矩阵Ws,R=W-1可以通过在特征域进行特征映射变换来实现。设x通过变换后的特征为Φ(x),则有:

其中,A为的乔莱斯基分解(Cholesky fac-torization)。在大数据量任务中,为了降低运算量,文献[14]通过PCA核方法求解A。
训练完WCCN后,提取好的参考集的特征即变换为新的特征,记为M(w),即(16)式中的Φ(x),最后的距离计算公式为:

为了减少算法的偶然误差,本文对每种数据的选取都是随机的,并且最终的实验结果都是设定5个随机种子得到结果的均值,且通过身份确认和身份辨认的实验系统的性能得以评估。
3 实验与结果分析
本文分别在Multi-PIE人脸识别数据库和扩展的YaleB人脸库上进行实验。Multi-PIE人脸识别数据库含有超过750 000张图片,共337个人,每人15种姿态、19种光照。扩展的YaleB人脸库包含有28个人,每人9种姿势、65种光照。
3.1 Multi-PIE数据库上的实验结果分析
本文选取人脸识别数据库Multi-PIE 4个部分中的5种不同的姿态(13-0、14-0、05-1、05-0、19-0)和13种不同的光照(4、5、…、9、10、14、15、…、19),正常表情的337个人的图片,共105 187张图。实验时随机选取不同的参考集人数,最多取200人,每人随机选取200张图,发现337个人中的每人图片张数不相同。为了实验的准确性,规定张数不少于250张的为有效集,可得有效集的实验人数为239人,参考集从有效集中选取。为了不减少实验数据量,从337人中去除已经被选为参考集的人,剩余的随机选取用于训练和测试。实验中所用数据的参数设置如下:
(1)参考集。实验中参考集人数依次选取[60 100 160 200],每人200张图片,总张数是参考集人数与每人的图片数量的乘积,参考集底层特征记为Hr(I)。
(2)WCCN set:=reference set(训练参考集的人数跟训练类内协方差矩阵的人数是相同的,且每个人的图片张数也相同)。总张数为人数和每人图片数目的乘积,训练获得WCCN矩阵记为M(w)。
(3)训练集。训练集人数依次选取[30 60 90 120],由于是单训练样本研究,因此设置每人的图片个数为1,训练集底层特征记为Fg(I)。
(4)测试集。将选入训练集的人去除注册的1张图片后,剩余的图片作为测试集,测试集底层特征记为Fp(I)。
文中所有的实验均采用识别率和确认率这2个标准来评估表现,实验1在Multi-PIE上验证了FC算法对普通方法的优越性。实验2分析了参考集的人数变化时,global和local对FC算法效果的影响。
3.1.1 FC算法的优越性
本文设计了WCCN实验,获得了WCCN的参数,其中 WCCN的维数为100,惩罚因子r取0.1,随机选择了5个随机种子来保证实验的准确性,随机种子为 [3 205 605 4 050 4 005 20 131 105]。由于本实验是针对单训练样本条件下的人脸识别问题,所以每个注册人的张数Mg设置为1。实验时规定参考集的人数为200人,注册者人数为30人,通过比较FC算法(global和local)和余弦距离分类算法的结果可知,FC方法的正确率提高5%~6%,其中,local的效果最好,global次之,余弦距离分类算法最差,同时随机数对结果有一定的影响。
当随机种子为4 005时,与其他种子数相比识别率较低,通过对参考集中的图片进行分析可知,随机分配到参考集中的人脸图片,佩戴眼镜,人脸有遮挡的较多,人脸的遮挡对其识别造成了一定的影响。通过消除遮挡的影响,可以使识别效果得到进一步的提高。
3.1.2 参考集人数变化下的算法结果比较
在参考集人数为200的条件下,FC算法和余弦距离算法在识别上的对比结果见表1所列。
由表1可以看出,local情况下的识别率比global的略有提高,因此由本文分析结果可知,当参考集人数变化时,local情况下的识别率优于global。
实验中规定了注册者人数Ng=30,reference set中的人数为 [60 100 160 200]。
依据姿态和光照的local和global的实验结果对比见表2所列,从表2可以看出,local的识别率比global情况有一定提高,同时确认率也说明了这一点,如图4、图5所示。

表1 FC算法和余弦距离算法的识别率 %

表2 Ng=30时依据姿态和光照情况下的识别率 %

图4 根据光照将参考集分为13个中心和全局中心的对比

图5 根据姿态将参考集分为5个中心和全局中心的对比
另外通过表2可以得出,依据13种光照的local实验要比依据5种姿态的结果略好,说明当分类越详细时,效果越好,并存在临界值。
3.2 扩展的YaleB人脸库上的实验结果分析
本文对扩展的YaleB人脸库中的每个人选取了9种姿态,13种光照。由于每人张数较少,所以参考集选取的人数为20人,每人90张图片,剩余的图片用来测试和训练。通过实验可得余弦距离分类算法的识别率为74.85%,FC算法的识别率为77.84%。
显然,与Multi-PIE数据库上的结果相比,扩展的YaleB人脸库的识别率有明显的下降,但是由于该人脸库选取的图片张数较少,所以参考集中的图片张数也很少,从而导致最后的识别率降低,说明参考集的人数对于实验结果的影响很大。
3.3 FC算法和SRC算法的实验结果对比
为了更好地说明本算法的优越性,将本文算法与基于稀疏表示的人脸识别分类算法进行了比较,结果见表3所列。

表3 不同算法在不同数据库上的识别率 %
如果每类图片都有足够的训练样本,则SRC算法的实验结果很好,在Multi-PIE数据库和扩展的YaleB人脸库上的识别率分别为96.57%和90.28%,但是随着每类的图片张数减少时,识别效果会越来越低。当训练样本为单样本时,在不重构的条件下,实验结果很低,最高只能达到23.71%。而FC算法受训练样本的条件影响不大,其主要影响因素是参考集的参数设置,因此在单样本条件下,FC算法在2个数据库上的识别率分别为92.28%和77.84%。在时间复杂度上,SRC的时间复杂度为O(n2),而FC算法的时间复杂度为O(n)。因此,本文提出的算法具有改善单样本条件下人脸识别系统的性能。
4 结束语
本文提出了一种新的解决单训练样本的方法,依据该方法识别率提高了5%~6%;并研究了影响单训练样本的识别问题,参考集的有效设置也可以很好地提高FC方法的效果,实验结果表明该方法是有效的。进一步提高实验的识别效率可通过以下方法:① 对参考集中的图片进行有效的选取,剔除其中冗余的图片;② 对每个人的图片进行分类时选择合适的分类方法(例如可以将每个人的图片按照姿态和光照同时进行分类)。
[1] 孙 强,叶玉堂,邢同举,等.基于主成分分析法的人脸识别的探讨与研究[J].电子设计工程,2011,19(20):101-104,109.
[2] 陈倩倩,赵杰煜.基于嵌入式 HMM 的脸部表情识别[J].计算机工程与应用,2006,42(27):187-190.
[3] 胡学钢,郭亚光.一种基于粗糙集的朴素贝叶斯分类算法[J].合 肥 工 业 大 学 学 报:自 然 科 学 版,2006,29(2):169-172.
[4] Kim T K,Kittler J.Locally linear discriminant analysis for multimodally distributed classes for face recognition with a single model image[J].IEEE Transactions on Pattern A-nalysis and Machine Intelligence,2005,27(3):318-327.
[5] 徐立祥,李 旭.基于混合核函数支持向量机的回归模型[J].合肥学院学报:自然科学版,2013,23(2):4-8.
[6] Kemelmacher S I,Basri R.3dface reconstruction from a single image using a single reference face shape[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(2):394-405.
[7] 柴秀娟,山世光,卿来云,等.基于3D人脸重建的光照、姿态不变人脸识别[J].软件学报,2006,17(3):525-534.
[8] 胡峰松,张茂军,邹北骥,等.基于 HMM 的单样本可变光照、姿 态 人 脸 识 别 [J].计 算 机 学 报,2009,32(7):1424-1433.
[9] 王科俊,邹国锋.基于子模式的Gabor特征融合的单样本人脸识别[J].模式识别与人工智能,2013,26(1):51-56.
[10] 李 欣,王科俊,贲晛烨.基于MW(2D)2PCA的单训练样本人脸识别[J].模式识别与人工智能,2010,23(1):77-83.
[11] Hatch A O,Kajarekar S S,Stolcke A.Within-class covariance normalization for SVM-based speaker recognition[C]//Proc of ICSLP,2006:1471-1474.
[12] 章 玲,蒋建国,齐美彬.一种微分与积分投影相结合的眼睛定位方法[J].合肥工业大学学报:自然科学版,2006,29(2):182-185.
[13] Zhou X,Cui N,Li Z,et al.Hierarchical gaussianization for image classification[C]//2009IEEE 12th International Conference on Computer Vision,2009:1971-1977.
[14] Hatch A O,Stolcke A.Generalized linear kernels for oneversus-all classification:application to speaker recognition[C]//Proc IEEE ICASSP,Vol 5,2006:585-588.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
